ENTERPRISE COMPUTE ARCHITECTURE
The placement decision that determines everything downstream.
Enterprise compute architecture is not a capacity decision. It is a commitment decision — and most organizations make it at procurement time without understanding what they are actually committing to. The tier you choose at provisioning determines your cost model, your performance ceiling, your scheduling authority, and your exit path simultaneously. None of those are cleanly reversible after the fact.
The standard vendor framing encourages you to think of compute as an abstracted commodity layer. The hypervisor handles the hardware. The cloud console handles the provisioning. The reserved instance pricing page frames commitment as a discount mechanism. None of that framing is wrong exactly — it is just incomplete in a way that costs money and creates architectural debt that compounds quietly until something breaks.
Most teams discover the gap between the abstraction and the reality in one of three ways: a performance degradation that capacity additions don’t fix, a cost visibility problem that reveals reserved commitments were never actually utilized, or a migration that forces a full inventory of what the compute layer actually owns and what it surrendered. By that point, the commitment has hardened.
This page covers the decision logic that should happen before any of that. The Compute Commodity Illusion — the false beliefs that make poor commitment decisions feel reasonable at the time. The Rack2Cloud Compute Commitment Model — the framework that maps workload characteristics to the correct commitment tier. The four tiers themselves, decomposed through the lens of what each one actually requires you to own and surrender. The hypervisor tax. The Bare Metal Threshold Test. The failure modes that show up in production before they show up in planning. And the decision framework for getting the commitment right the first time.
The context in 2026 makes this more consequential than it has been in a decade. Broadcom’s post-acquisition VMware pricing forced a generation of enterprise architects to ask, for the first time in years, what they were actually paying for and whether the abstraction was still worth the cost. Bare metal is back in serious architectural conversations. GPU-adjacent compute changed the density calculus for workloads that sit near inference pipelines. Hybrid estates are now the default operating model, and workload placement decisions that used to happen in a single environment now span three or four. The compute layer is no longer background noise.

The Compute Commodity Illusion
The reason enterprise compute decisions go wrong is not usually technical ignorance. It is a set of beliefs — reasonable on the surface, wrong in practice — that make poor commitment decisions feel like sound ones at the time. These beliefs are reinforced by vendor framing, console UX design, and procurement processes that abstract away the architectural consequences of each choice.
The table below names the five most common illusions and what they actually mean for the architecture.
| What Teams Believe | What It Actually Means |
|---|---|
| Compute is commodity | Compute is a commitment decision with downstream cost and performance lock-in |
| Reserved is cheaper than on-demand | Reserved is prepaid utilization risk — underutilization is a sunk cost, not a discount |
| Dedicated is just isolation | Dedicated is a tenancy and scheduling tradeoff with specific operational implications |
| Bare metal is just faster | Bare metal is operational overhead purchased for deterministic behavior |
| Virtualization is abstracted away | Hypervisor behavior becomes application behavior under load |
Each of these beliefs survives as long as utilization is moderate, workloads are predictable, and nobody is looking closely at per-workload economics. They collapse under three conditions: load increases, a migration forces inventory, or a pricing event like Broadcom’s VMware acquisition forces a reclassification of what the abstraction is actually worth.
The first illusion — that compute is commodity — is the most structurally damaging because it licenses the others. If compute is interchangeable, then tier selection is just a cost optimization exercise. Reserved instances are just discounts. Dedicated hosts are just compliance checkboxes. Bare metal is just for performance-sensitive edge cases. None of that is accurate, but it holds together as a belief system as long as it is never seriously tested.
The second illusion — that reserved capacity is cheaper — obscures the actual financial mechanic. A one-year or three-year reserved instance is not a discount on compute. It is a prepaid commitment to utilization that may or may not materialize. If the workload it was purchased for is decommissioned, resized, or migrated, the reservation continues to bill. Finance normalizes the overcharge as an infrastructure line item. The architectural debt becomes invisible.
The hypervisor abstraction illusion is the most technically consequential. Virtualization genuinely does abstract away hardware management for the majority of workloads, the majority of the time. But under load — specifically under conditions of CPU contention, NUMA boundary crossing, memory pressure, and storage I/O saturation — the hypervisor stops being an abstraction and starts being a constraint. Application teams experience this as performance instability that doesn’t correlate with any obvious capacity metric. The hypervisor layer is not surfacing what it is doing in the default monitoring stack.
Understanding these illusions is not an argument against virtualization, reserved pricing, or hyperscale compute. It is the prerequisite for making a defensible commitment decision.

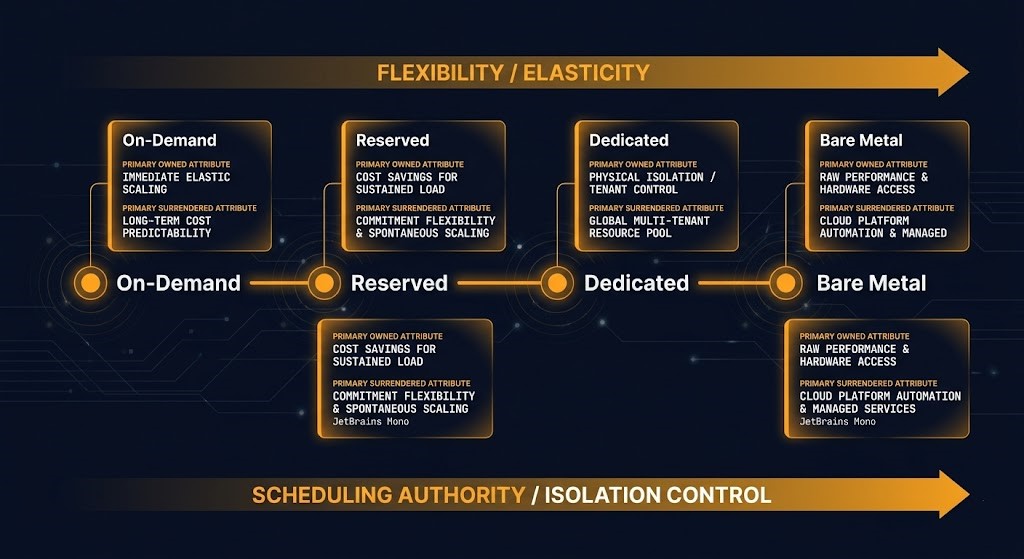
The Rack2Cloud Compute Commitment Model
Every compute tier decision involves four architectural variables: demand shape, isolation requirement, exit sensitivity, and burst profile. The tier you choose determines how each of those variables resolves — what you own, what you surrender, and what failure mode you inherit. The Rack2Cloud Compute Commitment Model maps these variables against the four commitment tiers to make the tradeoff explicit before the commitment hardens.
This is the model.
| Commitment Tier | Demand Shape | Isolation Requirement | Exit Sensitivity | Burst Profile |
|---|---|---|---|---|
| On-Demand | Variable / unpredictable | Shared tenancy acceptable | Low — no term commitment | Immediate burst, full elasticity |
| Reserved | Stable and predictable | Shared tenancy acceptable | High — term locks cost structure | Burst requires supplemental on-demand |
| Dedicated | Stable with isolation constraints | Physical host isolation required | High — dedicated pricing premium | Limited burst within dedicated capacity |
| Bare Metal | Deterministic — high throughput or latency-sensitive | Full physical isolation required | Very high — operational model change | No burst — capacity is fixed |
The model is not a decision tree. It is a forcing function. Before any compute commitment is made, each of the four variables should be answerable with specificity. If demand shape is described as “we expect steady state but we’re not sure,” that is an on-demand workload masquerading as a reserved candidate. If isolation requirement is described as “we prefer dedicated for security,” that requires interrogation — is the isolation requirement regulatory, architectural, or a preference? Preference-driven dedicated hosting is one of the most consistent sources of reserved capacity waste on enterprise estates.
The model also surfaces the exit sensitivity variable explicitly, which most procurement conversations omit entirely. On-demand workloads have low exit sensitivity — you can terminate, resize, or migrate without financial penalty. Reserved and dedicated workloads carry term commitments that make the exit cost non-trivial. Bare metal carries an operational model change as its exit cost — not just financial, but organizational. Teams running bare metal at scale need to be resourced differently than teams running hypervisor-managed fleets. That cost appears when the bare metal decision is reversed.
Two additional dimensions sit beneath the model and inform it: scheduling authority and cost visibility. On-demand and reserved tiers surrender scheduling authority to the platform — the cloud provider or hypervisor decides where the workload physically runs, subject to the constraints you specify. Dedicated and bare metal return scheduling authority to the operator. Cost visibility degrades in the opposite direction — on-demand costs are granular and workload-attributable; reserved costs are sunk and distributed; dedicated and bare metal costs require internal chargeback models to attribute accurately.
Use the Compute Commitment Model at the architecture stage, not the procurement stage. By procurement, the commitment has already been shaped by capacity estimates and finance approval cycles. The model belongs in the design conversation, before the workload profile is handed to a vendor.
What Enterprise Compute Actually Is
With the illusion named and the model introduced, the corrected definition of enterprise compute can be stated precisely. Enterprise compute is not a server tier, a cloud service category, or a pricing model. It is the combination of three architectural primitives: placement tier, resource isolation model, and scheduling authority. Every compute decision resolves all three simultaneously, whether or not the decision-maker is aware of it.
Placement tier determines where the workload runs physically — shared multi-tenant hardware, dedicated physical hosts, or bare metal. The platform abstracts this to varying degrees depending on the tier, but the physical placement has real consequences for performance predictability, regulatory compliance, and data residency.
Resource isolation model determines what the workload shares and with whom. In a shared-tenancy environment, CPU cycles, memory bandwidth, network I/O, and storage I/O are all contested resources. The hypervisor schedules access to them. Under nominal load, contention is minimal and the abstraction holds. Under load — specifically during the periods when performance matters most — contention becomes the dominant variable.
Scheduling authority determines who decides where and when the workload runs. On-demand and reserved cloud instances surrender scheduling authority to the provider. The provider schedules migrations, live migrations, host maintenance, and resource rebalancing. For most workloads, this is acceptable. For workloads with strict latency requirements, mixed NUMA sensitivity, or GPU affinity constraints, surrendered scheduling authority is the difference between predictable and unpredictable performance.
Most enterprise organizations have implicit answers to all three primitives across their estate. The problem is that the answers were never made explicit and are therefore not consistently applied. A workload running on a shared cloud instance with surrendered scheduling authority and no isolation guarantee is a different architectural object than a workload running on a dedicated host with controlled placement. Both are “virtual machines.” The compute tier label obscures the difference.
The architecture conversation should name all three primitives for every significant workload class. That naming exercise is where the Compute Commitment Model does its work.
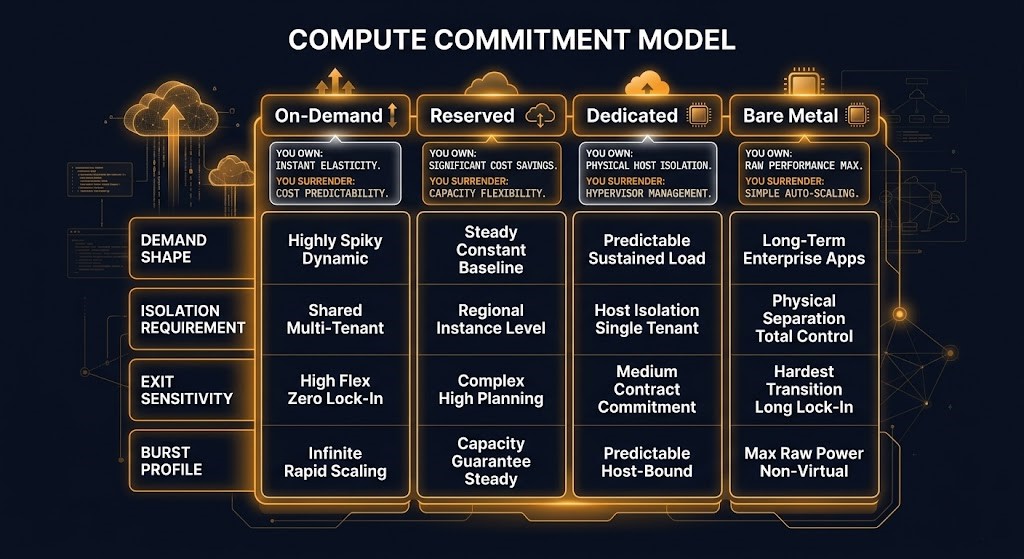
The Four Compute Tiers — What Each One Actually Commits You To
The four tiers are not pricing options. They are distinct architectural commitments with different implications for isolation, scheduling, cost structure, and operational model. Each tier is described here in terms of what you own, what you surrender, the failure mode you inherit, and the workload profile it actually fits.
| Tier | You Own | You Surrender | Primary Failure Mode | Fits When |
|---|---|---|---|---|
| On-Demand | Workload definition, sizing | Scheduling authority, placement control, pricing predictability | Cost visibility at scale — granular billing obscures aggregate inefficiency | Demand is variable, unpredictable, or development/test |
| Reserved | Predictable cost floor, capacity guarantee | Flexibility — commitment is financial and term-bound | Reserved Capacity Trap — unused commitments become invisible sunk cost | Demand is stable and measurable for 12+ months |
| Dedicated | Physical host isolation, tenant separation | Cost efficiency — dedicated pricing is a premium over shared | Bare Metal Overreach — dedicated cost without the operational control of bare metal | Regulatory isolation required, or mixed tenancy is explicitly prohibited |
| Bare Metal | Full physical isolation, scheduling authority, deterministic performance | Operational simplicity — bare metal requires management tooling the hypervisor provided | Bare Metal Overreach + scheduler blindness — operational overhead applied to workloads that didn’t need it | Latency-sensitive, GPU-adjacent, sovereign compute, or high-density throughput workloads |
On-demand is the correct default for any workload with variable or unpredictable demand. It is also the correct tier for workloads in active development, workloads undergoing architectural change, and any workload where the utilization profile has not been measured over a sufficient baseline. The mistake is treating on-demand as a transitional tier rather than a legitimate permanent choice for volatile workloads. On-demand becomes expensive at scale not because it is wrong, but because it is applied to workloads that should have been reserved once the demand profile stabilized.
Reserved capacity is the correct choice when demand is stable, measurable, and predictable over the commitment term. The critical discipline is the measurement requirement. Reserved commitments purchased on projected utilization rather than observed utilization create the Reserved Capacity Trap — a shadow cost layer where commitments are billing at full rate against underutilized capacity. The correction is to baseline demand before committing, not after. Reserved pricing is not a discount — it is a bet on your own utilization forecast.
Dedicated hosts sit between reserved and bare metal in isolation level and between shared and bare metal in operational complexity. The isolation guarantee is physical host separation — your workloads do not share a physical server with another tenant. The scheduling model is still hypervisor-managed within your dedicated pool. The cost premium is real and substantial. Dedicated is the correct choice when physical isolation is a hard compliance requirement, not a preference. When the isolation requirement is regulatory, dedicated is defensible. When it is preference-driven, it is expensive discipline that bare metal would serve better if the workload actually requires deterministic behavior.
Bare metal is the correct architectural choice for a specific and limited set of workload profiles. It is not a premium tier for performance-conscious teams. It is an operational commitment to managing the compute layer without the abstraction the hypervisor provides. Everything the hypervisor did — live migration, resource scheduling, failure recovery, capacity balancing — becomes your responsibility or your tooling’s responsibility. That is not a problem if the workload requires it. It is a significant operational overhead if the workload would have performed adequately on a well-sized dedicated host.
The Hypervisor Tax
The hypervisor tax is not a theoretical concern. It is a measurable overhead that manifests differently depending on workload type, utilization level, and the specific hypervisor implementation. Understanding where the tax is negligible and where it is load-bearing is the difference between appropriate tier selection and tier decisions driven by ideology rather than measurement.
CPU overhead in modern hypervisors (KVM, ESXi, Hyper-V) ranges from 2–8% under nominal load for well-tuned configurations. That is negligible for most general-purpose workloads. The non-negligible element is CPU ready time — the time a virtual CPU spends waiting for a physical CPU to become available. In a lightly loaded environment, CPU ready time is near zero. In an overcommitted environment, or during peak periods on shared hosts, CPU ready time accumulates and manifests as application-level latency that has no obvious correlation to CPU utilization metrics in the monitoring stack. The workload looks fine on the dashboard. The users notice something is wrong.
NUMA boundary crossing is the most consequential and least monitored form of hypervisor tax for latency-sensitive workloads. Non-Uniform Memory Access architecture means that memory access times are not uniform across physical CPU sockets. When a virtual machine’s vCPUs are scheduled across multiple NUMA nodes — either because the VM is sized larger than a single NUMA node, or because the hypervisor scheduler makes cross-node placement decisions — memory access latency increases materially. For in-memory databases, high-frequency processing, and anything with tight latency budgets, NUMA crossing is a performance cliff that capacity additions cannot fix. The correct solution is NUMA-aware VM sizing and explicit scheduler affinity rules, not more RAM.
Memory balloon drivers are a feature, not a bug — but they interact poorly with workloads that hold large in-memory datasets. Ballooning reclaims memory from VMs under host memory pressure by asking the guest OS to inflate a balloon driver, forcing the guest to swap. For a workload that holds an in-memory cache, a search index, or an active dataset, guest swapping is catastrophic to response time. The monitoring signal is memory pressure at the host level, not the guest level. The guest reports adequate memory because it has not been notified that the balloon is inflating.
Storage I/O overhead through the virtual storage stack — particularly through software-defined storage layers — adds latency that is predictable under low load and unpredictable under contention. For workloads with sequential throughput requirements, the overhead is usually acceptable. For workloads with mixed random I/O patterns, the hypervisor storage stack can become the bottleneck before CPU or memory saturate.
None of this is an argument against virtualization. It is an argument for knowing where the tax applies and sizing, placing, and configuring workloads accordingly. The teams that run into hypervisor tax problems are the teams that assumed the abstraction was complete. It is not. The hypervisor is a layer in your application stack during peak load conditions. Treat it as one.
The network fabric architecture underneath the compute layer — topology class, east-west enforcement mechanism, and control plane model — directly affects the I/O overhead profile the hypervisor operates within. The Modern Networking Logic strategy guide covers how topology class selection determines the network constraints that compute placement decisions have to account for.
Bare Metal in 2026 — The Bare Metal Threshold Test
Bare metal has re-entered serious architectural conversations for three specific reasons: GPU workloads require physical access to accelerator hardware that virtualization layers cannot expose without overhead, Broadcom’s VMware pricing has forced a TCO reclassification across enterprise estates, and sovereign compute requirements in regulated industries have created demand for compute that sits entirely within organizational control.
None of those reasons make bare metal the correct answer for general-purpose workloads. The operational overhead of running without a hypervisor — managing hardware failure, capacity rebalancing, workload scheduling, and live migration manually or through tooling — is real and often underestimated in the architectural conversation. The teams that regret bare metal decisions are almost always the teams that provisioned it for workloads that would have performed adequately on well-configured dedicated instances at significantly lower operational cost.
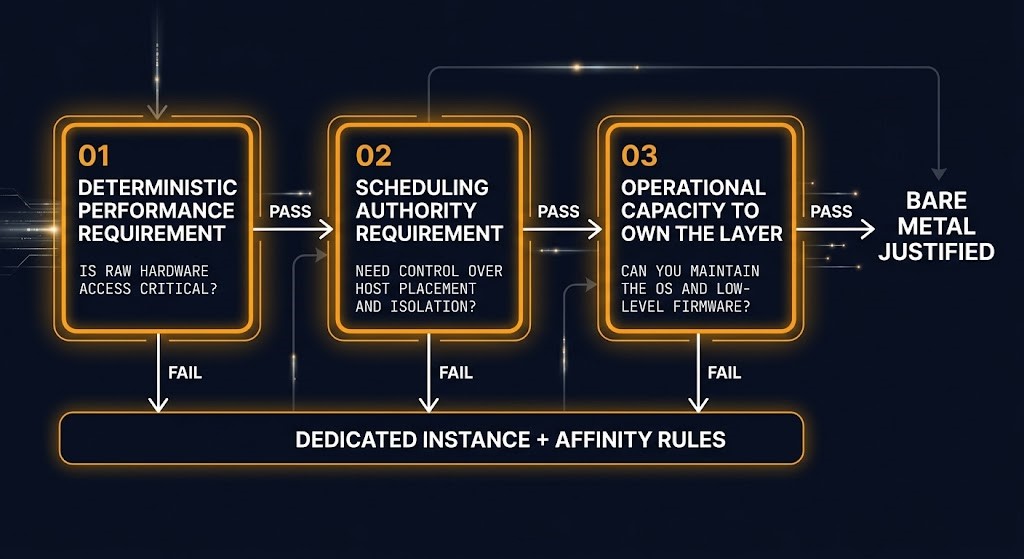
The Bare Metal Threshold Test is a three-condition gate. All three conditions must be true before bare metal justifies its operational overhead.
Condition 1 — Deterministic Performance Requirement. The workload has a documented latency or throughput requirement that cannot be satisfied under hypervisor overhead or shared tenancy conditions. This requirement must be measured, not estimated. If the performance target has never been tested against a well-tuned dedicated instance, the bare metal decision is premature.
Condition 2 — Scheduling Authority Requirement. The workload requires control over CPU affinity, NUMA placement, interrupt routing, or GPU assignment that the hypervisor cannot expose cleanly. GPU workloads are the clearest case — CUDA requires direct access to PCIe-attached accelerators, and while GPU passthrough exists, it introduces its own overhead and management complexity that bare metal eliminates. High-frequency workloads with strict interrupt latency budgets are the other clear case.
Condition 3 — Operational Capacity to Own the Layer. The team has the tooling and operational model to manage compute without the abstraction the hypervisor provided. This means hardware failure handling, capacity planning at the physical layer, firmware management, and either a bare metal orchestration platform (covered in the Bare Metal Orchestration sub-page) or a manual operational model with the staffing to support it.
If all three conditions are true, bare metal is architecturally defensible. If any one of them is not true, the correct answer is dedicated instances with explicit NUMA affinity rules and scheduler constraints — not bare metal.
The Broadcom pricing inflection point deserves specific acknowledgment. Many organizations currently running VMware vSphere are in the process of a forced TCO reclassification. Bare metal is appearing in that conversation as an alternative. It is a legitimate alternative for the workloads that pass the Bare Metal Threshold Test. For the remainder — which is the majority of enterprise compute estates — KVM-based alternatives, Nutanix AHV, or hyperscale dedicated instances are the more operationally sustainable path. The Lift-and-Shift to KVM Fallacy post covers the migration decision logic in detail.
Compute Failure Modes
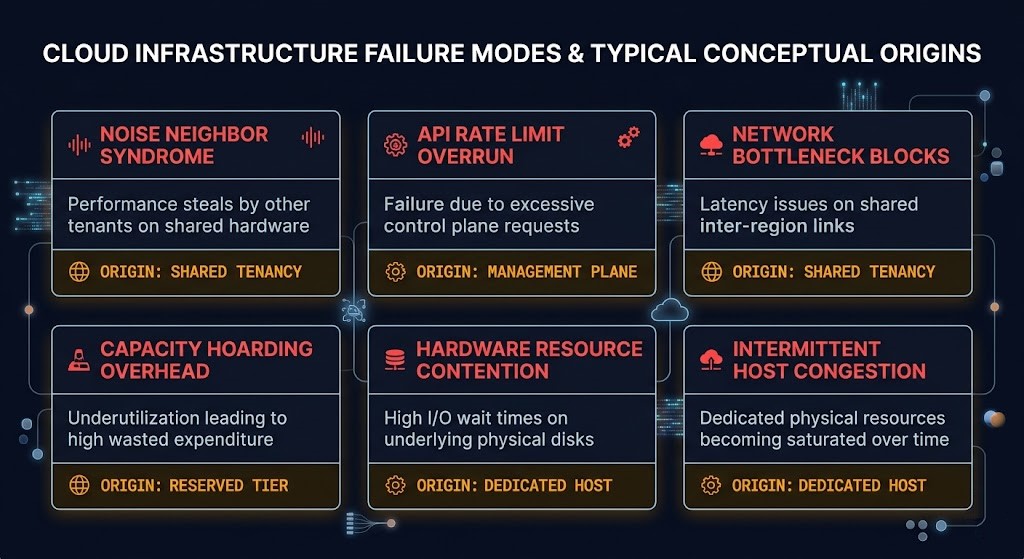
Compute architecture failures are not dramatic. They are slow accumulations of invisible technical debt that manifest as performance instability, cost overruns, and migration complexity — usually at the worst possible time. The six failure modes below represent the most common patterns observed across enterprise compute estates. Each one has a distinct trigger, a monitoring blind spot, and an impact that compounds over time.
What Breaks First
Compute architecture failures don’t announce themselves in planning documents. They surface in production, usually under load, always at inconvenient times. The sequence below describes how compute commitment mistakes propagate — which signal appears first, which appears second, and what the root cause turns out to be when someone finally traces it back.
The scheduler lies first. The platform reports healthy utilization. CPU is at 60%. Memory is comfortable. The application team is receiving latency complaints that don’t correlate with any visible metric. What the dashboard is not showing: CPU ready time accumulation on overcommitted hosts, NUMA boundary crossings on workloads that outgrew a single node, and hypervisor scheduler decisions that moved workloads during peak periods without workload-aware logic. The monitoring stack tells you capacity is fine. The users know it isn’t. The gap between those two signals is scheduler behavior that the default observability layer doesn’t surface.
Cost visibility fails second. Once reserved commitments are in place, the cost model changes character. On-demand billing is granular and workload-attributable. Reserved billing is sunk and distributed. The finance team sees a stable infrastructure line item. The engineering team sees a utilization report they stopped reviewing once the commitment was made. The actual per-workload cost is invisible unless someone builds internal chargeback tooling and maintains it. Most organizations don’t. The waste accumulates. Flexera’s 29% figure is not a surprise to anyone who has audited an enterprise cloud estate — it is a measurement of what happens when cost visibility is treated as a reporting problem rather than an architectural one.
Performance degrades before capacity saturates. This is the most counterintuitive pattern for teams that have been taught to treat performance problems as capacity problems. In a hypervisor-managed environment with NUMA constraints, storage contention, or scheduler pressure, adding compute capacity does not fix the underlying problem. Adding more VMs to an overcommitted host increases contention. Adding more vCPUs to a NUMA-crossing workload increases the crossing penalty. The capacity metric looks like the right lever because it is the most visible one. It is almost never the right lever for performance problems that have a placement or scheduling root cause.
Isolation assumptions collapse under mixed tenancy. The “dedicated” tier that shares a physical host boundary you didn’t know about. The “isolated” environment that turns out to share storage fabric with other tenants under high I/O load. The security team’s assumption that dedicated instances mean physical separation, when the actual isolation boundary is at the hypervisor scheduling level. These assumptions hold until an audit, a compliance review, or an incident exposes them. The architectural mistake was treating the tier label as a specification rather than a starting point for an explicit isolation review.
Exit cost appears only after commitment hardens. Reserved terms, dedicated host contracts, bare metal hardware amortization — the exit cost was always present in the commitment. It simply wasn’t modeled explicitly because the compute decision was made as a capacity or cost optimization exercise rather than an architectural commitment with a lifecycle. When the workload needs to move — because demand shifted, because a migration is required, because a pricing event like Broadcom’s VMware acquisition forced a reclassification — the exit cost surfaces as a constraint that wasn’t in the original decision. The Compute Commitment Model exists to surface that cost before it hardens.
These five patterns share a common root: the commitment was made without modeling what would need to remain true for it to hold. The decision framework in the next section is structured around that requirement.
Decision Framework — When Each Tier Is the Right Call
The decision framework below operationalizes the Compute Commitment Model. For each commitment tier, the positive fit conditions describe when the tier is architecturally correct. The negative fit conditions describe when a different tier would serve better. The decision table at the end maps workload profiles to recommended tiers with explicit reasoning.
Demand is variable, bursty, or not yet baselined over a meaningful observation window. Development, test, and staging workloads. Any workload where the utilization profile will change materially within 12 months.
Demand has been baselined over 90+ days of observed production utilization. Workload will not be materially resized or migrated within the commitment term. Finance has modeled the utilization risk of the commitment, not just the list price discount.
Physical isolation is a hard compliance requirement — regulatory, contractual, or security-driven. Shared-tenancy exclusion is documented and auditable. The isolation requirement has been validated against the specific compliance framework, not assumed.
All three conditions of the Bare Metal Threshold Test are met: deterministic performance requirement is documented and measured, scheduling authority requirement is genuine (GPU affinity, interrupt routing, NUMA control), and operational capacity to own the physical layer exists.
Utilization has not been baselined in production. The workload is under active architectural change. Demand is projected rather than observed. The commitment term exceeds the expected workload lifecycle.
The isolation requirement is a preference, not a compliance mandate. The cost premium is not justified by a specific documented requirement. If true deterministic behavior is needed, bare metal is the correct answer — not dedicated.
The Bare Metal Threshold Test fails on any one of its three conditions. The workload has not been tested against a well-tuned dedicated instance. The team does not have the tooling and operational model to manage the physical compute layer without hypervisor abstraction.
Decision table — workload profile to recommended tier:
| Workload Profile | Recommended Tier | Key Signal | Avoid When |
|---|---|---|---|
| Variable web / API workload | On-Demand | Demand shape is unpredictable | Reserved if utilization hasn’t been baselined |
| Stable production database (baselined 90+ days) | Reserved | Consistent utilization, known term | On-demand if utilization varies >30% month-over-month |
| Regulated financial workload, PCI/HIPAA scope | Dedicated | Compliance mandate requires physical isolation | Reserved shared-tenancy if regulation specifies physical separation |
| GPU inference pipeline | Bare Metal or Dedicated GPU | PCIe passthrough or CUDA direct access required | Shared GPU instances if latency SLA is strict |
| In-memory database (Redis, VoltDB, SAP HANA) | Dedicated with NUMA affinity rules | Memory access latency is deterministic requirement | Shared tenancy with default scheduler placement |
| Development / test / staging | On-Demand | Utilization is unpredictable, lifecycle is short | Reserved — dev workloads don’t have stable demand profiles |
| Broadcom VMware migration candidate | Assess against model | Depends on workload profile and isolation requirement | Defaulting all workloads to same tier during migration |
| Sovereign compute requirement | Bare Metal or Private Dedicated | Full physical control, audit trail to hardware | Any shared-tenancy tier where physical isolation cannot be verified |
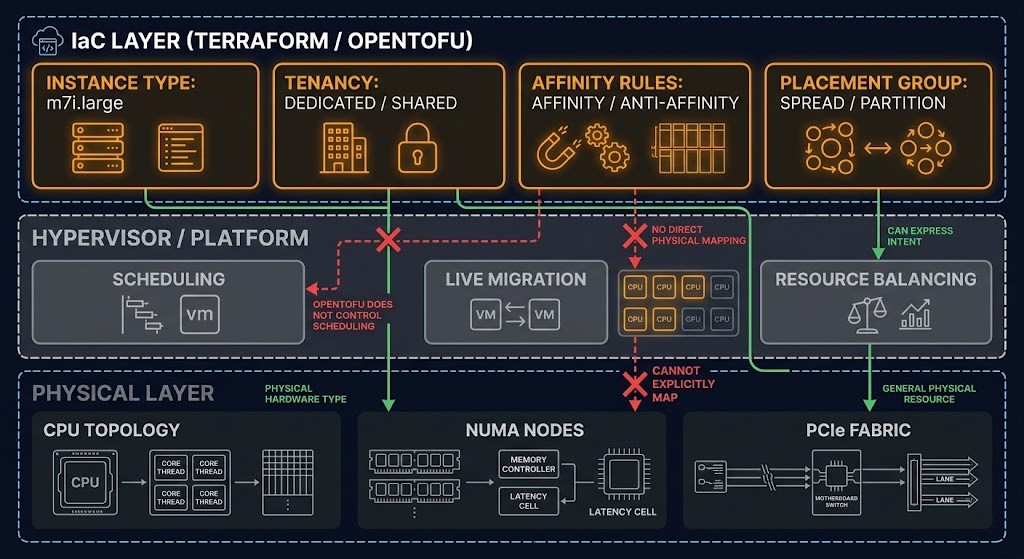
Compute Architecture and IaC — Where the Commitment Lives in Code
Compute tier decisions do not stay in architecture documents. They have to be expressed in infrastructure code, and the way they are expressed determines whether the commitment logic is enforced, visible, and maintainable over time — or whether it drifts silently as the estate evolves.
In Terraform and OpenTofu, compute tier decisions surface primarily in resource definitions for instance types, placement groups, tenancy models, and affinity rules. The common failure is specifying the instance type without specifying the placement constraints that justify the tier choice. A dedicated tenancy flag on a cloud instance is one line of HCL. The NUMA affinity rules, CPU isolation constraints, and scheduler placement policies that make a dedicated instance behave as intended are several more — and they are the lines most likely to be omitted in an initial provisioning pass and never added later.
The Terraform & IaC sub-page covers IaC architecture patterns in depth. For compute specifically, three rules apply.
First: placement logic belongs in IaC from day one, not as a post-provisioning optimization. Affinity rules, anti-affinity rules, NUMA topology hints, and placement group configurations should be defined in the same commit that provisions the compute resource. Retrofitting them after the workload is in production requires a migration or a restart — both of which carry risk and are usually deferred indefinitely.
Second: compute tier selection should be a variable, not a hardcoded value. Instance types change. Tier options evolve. A var.compute_tier pattern with defined values and validation rules makes the commitment logic explicit in the codebase and reviewable in pull requests. Hardcoded instance types in resource definitions make tier decisions invisible to reviewers who aren’t already familiar with the specific instance family’s characteristics.
Third: reserved capacity commitments should be tracked in IaC state, not just in the cloud provider’s billing console. The disconnect between reserved commitments purchased in the billing console and compute resources defined in Terraform is one of the most consistent sources of reserved capacity waste on well-managed estates. The commitment is invisible to the IaC layer. The IaC layer provisions and decommissions workloads without visibility into which commitments are active. The correction is a commitment tracking module — whether custom-built or using an existing FinOps tooling integration — that surfaces active commitments as inputs to provisioning decisions.
The Control Plane Shift capstone frames the broader architectural argument: compute placement decisions are infrastructure control plane decisions, and control plane decisions belong in code. That applies to instance type selection, tenancy model, placement constraints, and capacity commitment management equally.
Compute architecture doesn’t exist in isolation. The placement decision connects directly to networking constraints, storage I/O requirements, and IaC enforcement patterns. The pages below cover each adjacent layer.
YOU’VE READ THE ARCHITECTURE.
NOW TEST WHETHER YOUR ENVIRONMENT HOLDS.
Your compute tier decisions may have been made without modeling the commitment constraints — demand shape, isolation requirement, exit sensitivity, or burst profile. A Compute Architecture Assessment maps your current estate against the Compute Commitment Model and surfaces the tier mismatches before a migration, reclassification, or failure event forces them.
Compute Architecture Assessment
A vendor-neutral review of your compute estate against the Rack2Cloud Compute Commitment Model — tier by tier, workload by workload, before a pricing event or migration forces the decision.
- > Compute tier audit against workload profiles
- > Reserved capacity utilization and waste review
- > Hypervisor overhead and NUMA placement analysis
- > Bare Metal Threshold Test applied to your estate
Architecture Playbooks. Every Week.
Field-tested compute and infrastructure blueprints delivered weekly — placement logic, IaC patterns, hypervisor migration frameworks, and the commitment decisions that determine cost and performance over a three-to-five year horizon.
- > Compute commitment decision frameworks
- > IaC placement patterns that hold at scale
- > Hypervisor architecture and migration playbooks
- > Bare metal orchestration field notes
Zero spam. Unsubscribe anytime.
Architect’s Verdict
Enterprise compute architecture is a commitment architecture. The tier you choose at provisioning time is not a capacity decision that can be revisited cheaply — it is a simultaneous commitment to a cost model, a performance envelope, a scheduling model, and an exit path. Most organizations make that commitment implicitly, driven by procurement cycles and vendor pricing conversations, without modeling what would need to remain true for it to hold.
The Compute Commodity Illusion is what makes poor commitment decisions feel reasonable. If compute is interchangeable, tier selection is just optimization. Reserved instances are just discounts. Dedicated hosts are just compliance checkboxes. The illusion survives until load tests it — specifically until CPU ready time accumulates on overcommitted hosts, reserved utilization drops below the commitment threshold after a workload migration, or a compliance audit reveals that “dedicated” instances don’t mean what the security team assumed. The failure is always architectural. The root cause is always a commitment made without explicit modeling of its constraints.
The Rack2Cloud Compute Commitment Model is the correction. It maps the four variables — demand shape, isolation requirement, exit sensitivity, and burst profile — against the four commitment tiers to make the tradeoff explicit before the commitment hardens. It is not a complex framework. Most architects will recognize the logic immediately. The value is in forcing the conversation at the design stage, before procurement, before term commitments are signed, and before the workload is in production on the wrong tier.
The IaC dimension matters because compute decisions that aren’t expressed in infrastructure code don’t stay decisions — they become assumptions. Placement constraints omitted from the initial Terraform module get inherited by every workload deployed from that module. Reserved commitments purchased outside the IaC layer become invisible to the provisioning toolchain. The commitment logic has to live in the code to survive the team turnover, the architectural drift, and the estate growth that will happen over the commitment term.
The compute tier you choose is an architectural contract. Model the terms before you sign it.
Frequently Asked Questions
Q1: What is the difference between dedicated hosts and bare metal in enterprise compute?
A: Dedicated hosts provide physical host isolation within a hypervisor-managed environment — your workloads occupy the entire physical server, but the hypervisor still manages scheduling, resource allocation, and live migration. Bare metal removes the hypervisor entirely, giving you direct access to the physical hardware, full scheduling authority, and deterministic resource access. Dedicated is the correct choice when physical isolation is a compliance requirement. Bare metal is the correct choice when deterministic performance, GPU affinity, or scheduling authority over the hardware layer is a genuine architectural requirement — not just a preference.
Q2: Does hypervisor overhead still matter at modern efficiency levels?
A: For general-purpose workloads running at moderate utilization, modern hypervisor overhead (2–8% CPU, sub-millisecond memory access penalty) is negligible. It matters materially for three specific workload classes: latency-sensitive applications where CPU ready time and NUMA boundary crossing create unpredictable latency spikes, in-memory databases where memory balloon driver behavior under host pressure degrades guest performance, and GPU-adjacent workloads where PCIe passthrough overhead affects transfer latency. If your workload doesn’t fall into one of those three classes, hypervisor overhead is not your performance constraint.
Q3: When does reserved capacity become a liability rather than a cost optimization?
A: Reserved capacity becomes a liability the moment utilization drops consistently below the break-even threshold — typically around 60–70% utilization for most reserved pricing models. The four triggers: workload migration that leaves commitments orphaned, architectural change that reduces instance size requirements, demand contraction that was not anticipated in the commitment forecast, and over-reservation against projected rather than observed utilization. The correction is to baseline demand over 90+ days before committing, treat reserved pricing as a utilization bet rather than a discount, and build a commitment review cadence into quarterly infrastructure planning.
Q4: How should compute tier decisions be expressed in Terraform?
A: Three rules: placement constraints belong in the same commit that provisions the compute resource, not as a post-provisioning optimization. Instance type and tenancy model should be variables with defined allowed values and validation rules, not hardcoded strings. Reserved capacity commitments purchased outside Terraform should be surfaced as data sources or tracked in a companion module so the IaC layer has visibility into active commitments during provisioning decisions. The goal is making the commitment logic reviewable in pull requests and enforceable through CI/CD, not just documented in a spreadsheet that drifts from the actual estate.
Q5: Is bare metal viable in a cloud-native architecture?
A: Yes, but only for specific workload profiles that pass the Bare Metal Threshold Test. Cloud-native architectures built on Kubernetes can run on bare metal worker nodes — this is common for GPU inference pipelines, high-frequency data processing, and sovereign compute requirements. The operational model changes: cluster node provisioning, failure recovery, and hardware management all require tooling that the hypervisor previously handled. Bare metal orchestration platforms (Tinkerbell, Ironic, Equinix Metal) exist specifically to address this. The architectural question is whether the workload’s performance or isolation requirements justify that operational overhead.
Q6: How does compute placement interact with GPU workload scheduling?
A: GPU workloads require co-location of the compute workload with the physical GPU — either through PCIe passthrough on a dedicated or bare metal host, or through a cloud provider’s GPU instance types. The placement constraint is hard: the scheduler must place the workload on a node with attached GPU fabric. In Kubernetes, this is expressed through device plugin resource requests and node affinity rules. The compute tier decision for GPU workloads flows directly from the GPU scheduling requirements — if the workload requires direct PCIe access without passthrough overhead, bare metal is the correct tier. If managed GPU instances with acceptable overhead are sufficient, dedicated GPU instances are the operationally simpler choice. The GPU Scheduling in Kubernetes post covers the Kubernetes scheduling layer in detail.
Q7: When does enterprise compute architecture justify a full reassessment?
A: Four triggers: a pricing event that materially changes the TCO of the current tier (Broadcom’s VMware acquisition is the clearest recent example), a migration or replatforming initiative that forces workload inventory, a performance investigation that traces back to placement or scheduling root causes rather than capacity, and a compliance review that surfaces isolation assumption mismatches. The Migration Readiness Assessment is structured around the first three triggers. If you are in the middle of a VMware exit, a cloud cost optimization initiative, or a bare metal evaluation, the assessment maps your current estate against the Compute Commitment Model and surfaces the tier mismatches before they become migration blockers.