AI INFRASTRUCTURE ARCHITECTURE LEARNING PATH
Accelerated compute, distributed fabrics, and inference systems engineered for production survivability.

AI infrastructure is a distributed systems execution discipline — seven maturity stages from accelerated compute foundations to system survivability architecture and execution assurance.
>_ AI Infrastructure Is Not a Procurement Decision. It Is an Execution Architecture Problem.
Most AI infrastructure programs begin with GPU acquisition and end with a cluster that cannot sustain production inference workloads at the throughput the business requires. The procurement decision is the easy part. The architectural decisions — fabric topology, storage pipeline design, scheduling authority, operational observability, governance architecture, and inference survivability — are where AI infrastructure programs succeed or fail. This path sequences those decisions in the order they actually compound.
This AI infrastructure architecture learning path sequences the architectural decisions required to build, operate, and sustain distributed AI systems at production scale. The question is never whether GPU compute is available — it is whether the execution stack beneath it is designed for the workload physics AI actually produces. Most organizations acquire compute and then discover the hard way that the fabric, storage pipeline, scheduling model, and operational observability layer are the constraints that determine whether the GPU investment produces usable throughput or idle residency.
AI infrastructure is not a model hosting problem. It is a distributed systems architecture discipline — where fabric latency determines training throughput, storage pipeline design determines inference concurrency, GPU scheduling authority determines whether utilization metrics reflect business value or mask latency collapse, and inference serving architecture determines whether the system is operationally permanent or permanently fragile. The teams that understand this early design for execution integrity from the first GPU rack. The teams that understand it late spend their operational capacity debugging performance problems that were architectural decisions made twelve months prior.
This path traces two arcs. The first three stages build the execution foundation: accelerated compute mechanics, AI fabric and distributed networking design, and data gravity and storage pipeline architecture. The final four stages cover operational intelligence and governance: GPU scheduling governance and residency economics, LLMOps and AI operations architecture, runtime authority governance, and finally system survivability architecture — the terminal maturity state where inference runs reliably, economically, and observably under continuous production demand.
The posts in this path are written for senior infrastructure architects, platform engineers, and AI infrastructure practitioners who have moved past model selection and framework configuration and are working through the harder execution architecture questions. The path does not explain what a GPU is. It explains why GPU utilization metrics lie to you about business throughput, why your AI fabric topology is the constraint you cannot retrofit, and why the inference cost problem cannot be solved by the team that created it.
>_ Why AI Infrastructure Programs Collapse After the Pilot
Most AI infrastructure environments perform adequately during experimentation and fail during productionization. The failure modes are predictable: compute purchased before workload characterization, fabrics deployed without latency modeling, storage pipelines that cannot sustain inference concurrency, and scheduling systems that optimize utilization while destroying execution consistency.
The architectural problem is not getting models to run once. It is sustaining distributed inference reliably, economically, and observably under continuous production demand.
>_ Why AI Infrastructure Programs Collapse After the Pilot
Most AI infrastructure environments perform adequately during experimentation and fail during productionization. The failure modes are predictable: compute purchased before workload characterization, fabrics deployed without latency modeling, storage pipelines that cannot sustain inference concurrency, and scheduling systems that optimize utilization while destroying execution consistency.
The architectural problem is not getting models to run once. It is sustaining distributed inference reliably, economically, and observably under continuous production demand.
What This Path Is Not
- Not certification prep — no exam objectives, no flashcard sequences
- Not vendor training — no preferred platforms, no product tutorials
- Not beginner tutorials — foundational mechanics are covered, not hand-held
- Not feature documentation — the focus is tradeoffs, failure domains, and operational consequence
>_ Estimated Reading Depth
| Scope | Coverage | Estimated Time |
|---|---|---|
| Core Execution Sequence | Accelerated compute, AI fabric, and storage pipeline foundations — Stages 1, 2, and 3 | ~4–5 hr |
| Full Domain Path | All seven stages in sequence — from accelerated compute through system survivability architecture | ~12–15 hr |
| Full Path + AI Infrastructure Lab | Full path including hands-on validation exercises from the AI Infrastructure Lab | ~15–18 hr |
>_ Where to Enter This Path
Not every reader starts at Foundation. Start at the stage that matches your current operational context.
| Audience | Recommended Entry | Reason |
|---|---|---|
| Engineers new to AI infrastructure or GPU compute architecture | Stage 1 — Foundation | Accelerated compute mechanics — CUDA execution model, memory bandwidth physics, interconnect topology — are the prerequisites every fabric and scheduling decision above depends on |
| Platform engineers deploying AI networking or evaluating fabric topology | Stage 2 — Operational | AI fabric design — RoCE vs InfiniBand, fat-tree vs dragonfly topology, RDMA mechanics — is the first architectural gap most production AI deployments encounter after compute provisioning |
| Architects sizing AI storage or designing data pipeline architecture | Stage 3 — Operational | Data gravity and storage pipeline design determine inference concurrency limits — the constraint that cannot be addressed at the compute or scheduling layer |
| Architects managing GPU clusters, utilization, or multi-tenant scheduling | Stage 4 — Strategic | Scheduling authority and residency economics determine whether GPU investment produces business throughput or idle capacity — the point where infrastructure becomes a cost governance problem |
| MLOps and LLMOps practitioners managing model serving and deployment pipelines | Stage 5 — Strategic | AI operations and LLMOps architecture cover the cost observability, deployment consistency, and operational governance gaps that emerge when inference runs at production scale |
| Architects designing or evaluating AI governance and runtime control architecture | Stage 6 — Strategic | Runtime authority governance addresses who possesses the architectural authority to govern execution — the control plane ownership, policy translation, and enforcement gaps that precede survivability design |
| Architects designing for production inference survivability and execution assurance | Stage 7 — Resilient | System survivability architecture is the terminal problem class — where degradation ladders, failure-state envelopes, and distributed inference continuity must be designed before failure makes the absence visible |
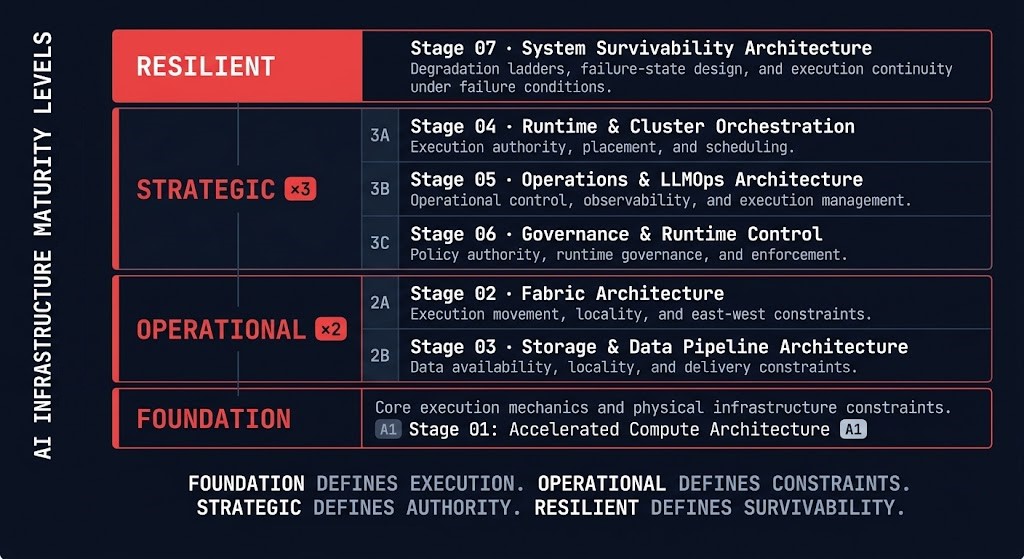
>_ The Architecture Maturity Spine
This Domain Path uses four of the five Architecture Maturity Levels. Sovereign level is not used — the terminal maturity state for AI infrastructure is distributed inference survivability and execution assurance, not control plane independence. Two stages run at Operational because the execution foundation splits cleanly between fabric architecture and storage pipeline design — distinct constraint classes that compound independently. Two stages run at Strategic because scheduling governance and LLMOps architecture represent separate economic optimization surfaces that warrant dedicated treatment.
| Level | Positioning | Architectural Goal |
|---|---|---|
| Foundation | Core principles and architectural mechanics | Understand accelerated compute physics, CUDA execution model, memory hierarchy, and interconnect topology — the mechanics every execution decision above depends on |
| Operational | Day-2 operations and scalable execution | Design AI fabric topology and storage pipeline architecture — the two constraint layers that determine whether the compute investment delivers usable throughput at scale |
| Strategic | Optimization, governance, and economics | Govern GPU scheduling residency, AI operations economics, and runtime execution authority — the three stages where infrastructure decisions become cost, control, and governance decisions simultaneously |
| Resilient | Failure-domain reduction and survivability | Engineer system survivability architecture — degradation ladders, failure-state envelopes, and distributed inference continuity under failure conditions that governance alone cannot resolve |
This Domain Path uses four levels: Foundation → Operational (×2) → Strategic (×3) → Resilient. Sovereign level not used — the terminal maturity state is Resilient for AI infrastructure.
>_ AI Infrastructure Architecture Learning Path — Reading Sequence
The reading sequence follows the maturity spine — each stage builds on the execution architecture established before it. The path traces a single continuous argument: compute defines the ceiling, fabric determines whether that ceiling is reachable, storage sets the concurrency floor, scheduling governs whether capacity produces value, operations makes that value observable and accountable, and survivability makes it permanent. Every stage is a prerequisite for the one above it. No layer can be retrofitted without addressing the layer beneath it.
Accelerated Compute Architecture
GPU architecture is not a hardware specification — it is an execution model with physics that determine the ceiling on every decision above it. This stage covers the CUDA execution model, memory hierarchy and bandwidth constraints, interconnect topology, and the gap between theoretical and sustained throughput that most AI infrastructure programs treat as a vendor problem rather than an architecture problem. The decisions made here set the execution ceiling every subsequent stage operates within.
AI Fabric & Distributed Networking
The fabric is the constraint you cannot retrofit. Once the topology is deployed, the latency floor, bisection bandwidth ceiling, and failure domain structure are fixed. This stage covers AI network topology design — fat-tree vs dragonfly, RoCE vs InfiniBand, RDMA mechanics, and the east-west traffic patterns that AI workloads produce at scale. The fabric decision is not a networking decision — it is the execution architecture decision that determines whether multi-node training completes in hours or days and whether distributed inference meets latency SLOs under load.
AI Data Gravity & Storage Pipeline Architecture
Data gravity determines where inference must run — not where it is convenient to run. Storage pipeline architecture determines whether the GPU can be fed fast enough to sustain the concurrency the serving layer requires. This stage covers AI storage architecture — NVMe-oF, Ceph for AI workloads, storage throughput sizing for inference concurrency, and the vector database and RAG pipeline design that determines how retrieval-augmented workloads interact with the storage layer. The data gravity problem is not resolved at the compute or scheduling layer — it is fixed at the storage and pipeline design layer, which is why it belongs here.

>_ The Execution Foundation → Operational Intelligence Transition
Early-stage AI infrastructure programs optimize for workload completion. Mature AI systems eventually discover the harder problem: governing compute residency, scheduling authority, and operational cost across a distributed execution environment where the business model depends on inference throughput that nobody designed the infrastructure to sustain. GPU scheduling is ultimately an economic governance system disguised as a compute orchestration layer.
>_ The AI Execution Failure Patterns
GPU Scheduling, Residency & Cluster Governance
GPU infrastructure becomes an architecture problem the moment scheduling authority determines business throughput more than raw compute capacity does. This stage covers GPU scheduling governance — multi-tenant cluster design, residency isolation, utilization economics, and the scheduling authority decisions that determine whether the GPU investment produces business value or idle cost. The economics framing is explicit: GPU scheduling is ultimately an economic governance system disguised as a compute orchestration layer. Teams that treat it as a configuration problem discover the economic consequences during the first budget review after production inference launches.
AI Operations & LLMOps Architecture
LLMOps is where AI operations economics become visible — and where most teams discover that deployment consistency and cost accountability are not the same problem. This stage covers AI operations architecture: model serving design, deployment pipeline governance, inference cost routing, and the observability architecture required to know whether the system is operating within its economic and latency envelopes. The economics framing is explicit here: inference cost is not an accounting problem — it is an operational governance problem that requires the same design discipline as the compute and fabric layers beneath it.
>_ The Inference Problem Is Not Deployment. It Is Residency.
Early-stage AI programs optimize for deployment success. Mature AI systems eventually discover the harder problem: sustaining inference residency where data gravity, latency budgets, throughput economics, and placement authority remain aligned under continuous demand.
Production inference survivability is ultimately a distributed systems architecture discipline — not a model hosting exercise.
System Survivability Architecture
Governance decides who may act. Survivability determines what happens when nobody can.
System survivability architecture is the terminal maturity state of this path — the point where every architectural decision from Stage 1 through Stage 6 either holds under failure conditions or collapses in ways that were designed in months earlier. This stage covers the Survivability Boundary (#125), degradation ladder design, failure-state envelope definition, observability under failure, blast radius boundaries, and the governance-to-survivability handoff that A6’s authority model must be built to survive. Survivability is not a monitoring problem — it is the cumulative consequence of every upstream architectural decision being made with failure conditions as the design constraint.
>_ Deterministic Infrastructure Tools
>_ Where Do You Go From Here
>_ Continue Your Architecture Reading Sequence
Five Domains. One Maturity Framework.
The AI Infrastructure Architecture learning path is one of five structured reading sequences across the Rack2Cloud platform. Each path follows the same maturity spine — applied to the operational realities of its domain.
>_ Frequently Asked Questions
Q: What is the AI Infrastructure Architecture Learning Path?
A: The AI infrastructure architecture learning path is a maturity-guided reading sequence for senior infrastructure architects, platform engineers, and AI infrastructure practitioners — from accelerated compute foundations through AI fabric design, GPU scheduling governance, LLMOps architecture, and distributed inference survivability. It sequences published architecture analysis by execution complexity and operational consequence, not by AI framework, model type, or certification objective. The path uses four Architecture Maturity Levels: Foundation, Operational, Strategic, and Resilient.
Q: How is this different from an MLOps or cloud AI certification track?
A: Certification tracks sequence content to cover exam objectives and tool mechanics. This path sequences content to cover the architectural decisions that determine whether AI infrastructure actually sustains production workloads — fabric topology, storage pipeline concurrency, GPU scheduling residency economics, inference cost governance, and distributed failure-domain design. The path does not explain what a GPU is or how to fine-tune a model. It explains why GPU utilization metrics lie about business throughput, why your fabric topology is the constraint you cannot retrofit, and why the inference cost problem cannot be solved by the team that created it.
Q: Do I need GPU hardware experience before starting this path?
A: Stage 1 assumes familiarity with data center infrastructure concepts but not deep GPU hardware expertise. It covers the CUDA execution model, memory hierarchy, and interconnect topology from an architecture perspective — the constraints that matter for infrastructure decisions, not the low-level programming model. If you are new to accelerated compute, Stage 1 is the correct entry point. If you are already operating GPU clusters and are dealing with scheduling, utilization, or inference cost problems, Stage 4 or Stage 5 is a more productive entry.
Q: What is the difference between AI fabric architecture and standard data center networking?
A: Standard data center networking is designed around north-south traffic — client to server, user to application. AI workloads produce predominantly east-west traffic — GPU to GPU, node to node, across collective communication patterns like all-reduce that saturate bisection bandwidth in ways standard three-tier topologies were not designed to handle. AI fabric architecture is specifically about the east-west bandwidth, latency floor, and congestion behavior that collective communication operations require. The wrong fabric topology does not just reduce performance — it determines whether multi-node training completes at all and whether distributed inference can meet latency SLOs under load.
Q: When does GPU scheduling become a governance problem rather than a configuration problem?
A: GPU scheduling becomes a governance problem the moment scheduling authority determines business throughput more than raw compute capacity does. In practice, the signals are: utilization metrics are high but inference latency is degrading; multiple teams are competing for GPU capacity with no residency isolation; AI cost reviews are producing observations but no decisions because nobody owns the combined optimization surface; and scheduling changes require coordination across platform, ML, and application teams who each optimize for different physics. Configuration can set resource limits. Governance determines who has authority over the combined optimization surface — and in most organizations, nobody does.
Q: What does LLMOps cover that standard MLOps doesn’t?
A: MLOps covers the machine learning lifecycle — data pipelines, model training, experiment tracking, and deployment automation. LLMOps extends this to the specific operational challenges of large language model serving at scale: prompt engineering governance, context window management, token economics, KV cache architecture, model versioning under continuous fine-tuning, canary deployment for inference endpoints with latency SLOs, and the cost observability required to know whether the serving stack is operating within its economic envelope. The distinction matters architecturally because LLM inference has different scaling physics than traditional ML model serving — the residency model, concurrency constraints, and cost attribution challenges are categorically different.
Q: Why does inference survivability require its own maturity stage?
A: Inference survivability is the point where every upstream architectural decision either holds under continuous production demand or fails in ways that were designed in months earlier. It requires its own stage because the failure modes — inference residency creep, cost authority fragmentation, latency degradation under load, failure-domain collapse — are not addressable at the compute, fabric, storage, or scheduling layers individually. They are emergent properties of the full execution stack operating under production demand. Execution assurance is not a monitoring problem. It is the consequence of every upstream architectural decision being made with production survivability as the design constraint from the beginning.
Q: How does this path connect to cloud cost governance and FinOps?
A: The path connects to cloud cost governance at Stage 4 and Stage 5, where GPU scheduling economics and inference cost observability become the primary architectural concerns. The core argument is that traditional FinOps tooling — built around elastic, usage-priced compute — does not transfer to AI infrastructure, where warm capacity is intentional, elasticity is constrained by cold start physics, and cost authority is fragmented across platform, ML, application, and finance teams who optimize for different objectives. The path treats AI cost governance as an architecture discipline, not an accounting function. Stage 4 covers scheduling residency economics. Stage 5 covers LLMOps cost observability. Stage 6 covers execution assurance as the governance instrument that makes cost accountability durable.
Q: What is the relationship between AI infrastructure architecture and sovereign infrastructure?
A: Sovereign infrastructure — owning the control plane completely, without dependency on external provider decisions — is a relevant concern for AI infrastructure specifically because AI workloads are unusually sensitive to data residency, regulatory jurisdiction, and inference latency constraints that cloud provider geography introduces. The data gravity argument in Stage 3 is where sovereignty enters the AI infrastructure path: when training data cannot leave a jurisdiction, or when inference latency requirements preclude cloud round-trips, the placement decision is made by architecture and regulation, not by convenience. Stage 5 and Stage 6 cover the inference placement and execution assurance architecture that makes sovereign AI infrastructure operationally viable rather than aspirational.
Q: Why do most AI infrastructure deployments fail after proof-of-concept?
A: Proof-of-concept environments are optimized for model performance, not execution sustainability. The failure modes that surface during productionization are architectural, not algorithmic: compute was provisioned for peak theoretical throughput rather than sustained inference concurrency; the fabric topology was selected for convenience rather than the east-west traffic patterns AI workloads actually produce; the storage pipeline cannot feed GPUs at the concurrency the serving layer requires; and the scheduling system optimizes utilization while destroying the latency consistency the application layer depends on. The model that worked in the pilot is the same model. The infrastructure that fails in production was never designed for the execution physics production actually requires.
Q: What is the relationship between GPU utilization and inference latency?
A: GPU utilization and inference latency have an inverse relationship that most GPU cost optimization programs ignore. High utilization means the GPU is busy processing requests — which sounds desirable until you realize that high occupancy reduces the headroom available to absorb latency spikes, increases queuing delays for incoming requests, and degrades P99 latency before average latency shows any visible change. The teams that optimize GPU utilization toward 80-90% for cost efficiency often discover that P99 latency has collapsed at exactly that utilization level. The right utilization target for a latency-sensitive inference endpoint is whatever level produces acceptable P99 under peak load — which may be 40-50% average utilization for a system designed to handle 3x traffic spikes within SLA. Utilization and latency are not independently optimizable. They are the same constraint expressed from two different perspectives.