FIELD JOURNAL.
SYSTEM LOGS.
ENGINEERING NOTES FROM THE COMPLEXITY GAP.
STRATEGIC ENGINEERING MANDATE
The journey from legacy infrastructure to modern cloud-native platforms is often obstructed by marketing-driven abstraction and tool-centric noise. Most technical journals focus on the “Day-1” installation—the easy path. Rack2Cloud documents the Day-2 production reality. We analyze how systems actually behave under load, at the boundaries of integration, and within the constraints of sovereign requirements.
Our field notes serve as a deterministic guide for the architect navigating the complexity gap. We prioritize the physics of data and the logic of high availability over vendor checklists. This is a technical repository designed for those who build, break, and scale complex estates.
“In production, complexity is the default state; architecture is the only defense.”
-
VMware Licensing Pressure Created a Dependency Audit Problem
The VMware dependency audit problem didn’t start with the Broadcom renewal. Most organizations could answer what ran on VMware. Very few could answer what depended on VMware — behaviorally, operationally, and at the recovery layer. The difference became expensive the moment the renewal conversation started. >_ Architect’s Brief Architecture overview before you dive in Generating…
-
Disaster Recovery Authority: The Missing Layer in Most Recovery Plans
Most disaster recovery programs are built around three questions: what systems need to recover, in what order, and within what timeframe. Those are legitimate questions. They produce dependency maps, runbooks, RTO targets, and recovery priority tiers. What they don’t produce is an answer to the question that precedes all of them: who still has the…
-
MCP, Tool Use, and the New Attack Surface Nobody Is Mapping
The agent wasn’t compromised. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The model wasn’t compromised. The tool wasn’t compromised. Every component did exactly what it was designed to do. The system still executed an action nobody authorized. That is not a vulnerability in the traditional sense. There was no implementation flaw…
-
The Hypervisor Is Not the Migration Target — The Operating Model Is
The post-migration incident report almost never blames the hypervisor. Workloads came up clean. Networking was verified. Storage performed. The technical migration, by every measure logged during the project, was a success. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Ninety days later, the first real incident runs into runbooks that reference vCenter…
-
Your AI Vendor Became Critical Infrastructure Before The Contract Did
On June 11, 2026, Microsoft 365 Copilot went down for seven hours. The cause was a misconfigured authentication deployment that cascaded through Microsoft Graph, taking Copilot Chat and the Office portal with it. It was the second major Copilot disruption in eleven days. Microsoft 365 posted 99.526% uptime in Q1 2026 — the lowest quarterly…
-
Infrastructure Remembers Configuration. It Forgets Intent.
Infrastructure can reconstruct its configuration state. It cannot reconstruct why that state exists. This is Framework #129 — the Operational Memory Boundary — and the series closer for the Authority Layer.
-
The CPU Is Back in the Stack — and Nobody Budgeted for It
The CPU never left the stack. It was reclassified — quietly, and incorrectly — as support compute. Something that fed the GPU, scheduled around the GPU, and otherwise stayed out of the way while the GPU did the “real” work. That classification held for exactly as long as AI workloads were big, monolithic training and…
-
Your DR Test Passed. The Assumptions Didn’t.
DR plan failure rarely happens where you tested. It happens at the assumptions the exercise never reached — the dependencies that weren’t in scope, the runbook written for last year’s architecture, the authority chain nobody tested at 2am.
-
Configuration Drift Is the Symptom. Ownership Is the Problem.
Configuration drift is treated as a visibility problem solved by tooling. It isn’t. Configuration drift ownership is the real breakdown — accountability over declared infrastructure state — and no detection pipeline closes that gap. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The industry built a full tooling category around drift: scanners,…
-
The AI Observability Layer Is Becoming a Governance System
Most enterprises have observability. Almost none have built the governance architecture that observability is quietly becoming. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The AI observability layer started as a debugging tool — latency traces, token counts, error rates. It is becoming something structurally different: the enforcement layer for cost gates,…
-
Most Cloud Exit Strategies Start Too Late
Every cloud exit strategy starts with the same problem: the exit window doesn’t close when you decide to leave. It closes years before — quietly, incrementally, one managed service at a time. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Most cloud exit strategies fail not because the migration plan is wrong,…
-
Most AI Control Planes Have a Single-Region Failure Domain
The cloud spent fifteen years teaching architects to think in availability zones, regional redundancy, and distributed failure domains. The assumption embedded in that training is that compute is fungible — that a workload running in us-east-1 can shift to us-west-2 without architectural consequence. For stateless web tiers, that assumption holds. For AI control plane architecture,…
-
Your Backup System Is Part of the Blast Radius
The call came in at 02:00. Production encrypted. By 02:10, recovery had been declared. By 02:15, the backup console was unreachable. By 02:20, the identity provider was down — same AD domain as production. By 02:30, the repository had been located. By 02:35, nobody could authenticate to it. By 02:40, the team understood what had…
-
The SaaS Control Plane Problem
Most organizations do not have a SaaS governance problem. They have a SaaS authority problem — and the distinction matters because governance problems have vendors selling solutions to them. Authority problems do not surface until an audit, a contract renewal, or an incident reveals that a set of workflow tools your infrastructure team approved individually…
-
Your AI Infrastructure Is Probably Solving the Wrong Problem
Most AI infrastructure programs are producing exactly the results they were funded to produce: higher GPU utilization, lower inference latency, and better model performance. The problem is that none of those metrics measure whether the organization actually controls its AI infrastructure. >_ Architect’s Brief Architecture overview before you dive in Generating brief… AI infrastructure governance…
-
The Hypervisor Is Becoming a Policy Enforcement Point
The hypervisor is no longer just deciding where workloads run. It’s deciding what they’re allowed to do. Most organizations are still operating it like it didn’t change.
Parent: none (top-level post)
Publish date: Sunday June 7, 2026
Field Notes series tag: apply FN series tag at staging. -
Nobody Meant to Build an AI Control Plane
Most organizations think they have an AI tool inventory problem. What they actually have is the early stages of an AI control plane. The tools arrived one at a time. The platform emerged accidentally.
Parent: none (top-level post)
Publish date: Saturday June 7, 2026
Field Notes series tag: apply FN series tag at staging -
Autonomous Operations Require Infrastructure Most Enterprises Don’t Have
Autonomous operations infrastructure is the conversation the industry is having. The infrastructure maturity required to support it safely is not. Microsoft is shipping autonomous remediation. AWS is building self-healing infrastructure into every operations layer. Every major infrastructure vendor is converging on the same vision: AI agents that operate your environment at machine speed, without waiting…
-
Multi-Cloud Failover Is Mostly Theater
Most multi-cloud architectures are designed to survive a cloud outage. Very few are designed to survive a failover. The Failover Plausibility Gap explains why — and what closing it actually requires.
Parent: none (top-level post)
Publish date: Friday June 5, 2026 -
The Network Is Becoming the AI Control Plane
The industry thinks AI infrastructure is a GPU problem. It is actually an AI control plane problem — and the control plane is relocating into the network fabric. The more scheduling intelligence moves into that fabric layer, the less important the individual compute node becomes — and the more important the layer that determines where…
-
The Infrastructure Control Plane Is Consolidating
On Monday, Cisco unveiled Cloud Control at Cisco Live. One login. Networking, security, compute, observability, and collaboration unified into a single operational surface with a shared data layer and a shared automation model. Cisco called it the foundation for their AgenticOps operating model. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The…
-
Cross-Region Replication Is Not Resilience
Every disaster recovery review eventually reaches the same sentence: “We have cross-region replication, so we’re covered.” It is said with confidence, because by every metric the team watches, it is true. The replica is current. Lag is measured in seconds. The dashboard is green. And that confidence is precisely the problem. >_ Architect’s Brief Architecture…
-
vSphere Lifecycle Management Is a Governance Problem, Not a Patching Problem
Most vSphere environments treat lifecycle management as a patching workflow. The architectural problem is that lifecycle management governs upgrade eligibility, migration readiness, and exit optionality — and when those decisions accumulate without a governance owner, the Lifecycle Governance Horizon quietly collapses.
-
Why Most Disaster Recovery Tests Don’t Test Recovery
Most DR tests are designed to pass. The controlled environment, pre-staged dependencies, and assumed declaration point produce rehearsal fidelity — not recovery evidence. Here is where the test boundary sits and why crossing it matters.
-
Private Cloud Is Back — Because Governance Never Left
The private cloud narrative was declared dead by cloud-first doctrine for the better part of a decade. Cost comparisons, operational overhead, capital expenditure cycles — all of it pointed toward public cloud as the inevitable destination. The private cloud operating model was framed as legacy thinking, a failure to move forward, the choice of organizations…
-
Most Sovereignty Strategies Fail Before Architecture Begins
Sovereignty strategy control plane failures follow a pattern that most organizations never diagnose correctly. The infrastructure appears sovereign. The compliance posture is confirmed. The certifications are in place. The gap is not in the architecture. It is in the scope definition that preceded it — and by the time engineering teams evaluate runtime authority, the…
-
AI Placement Decisions Are Architecture, Not Optimization
AI placement latency is not the problem most teams think they are managing. The default framing treats it as an optimization variable — pick the cheapest compute that meets the SLA, centralize inference, optimize for utilization, revisit locality later when the architecture matures. >_ Architect’s Brief Architecture overview before you dive in Generating brief… That…
-
Nutanix AHV Operations: What Changes After VMware Migration
The operational friction begins after the migration succeeds. Workloads are running. Clusters are stable. Teams declare victory — then discover that platform relocation and operational normalization are two different problems. This post begins where migration stabilization ends. If you are still in the cutover phase, start with the VMware to Nutanix migration Day-2 operations guide,…
-
The AI Control Plane Is Becoming the New Shadow IT
Shadow IT used to mean a SaaS subscription purchased outside the approval process. The fix was a procurement policy and a software catalog. It was an application-layer problem with a governance-layer solution. What is happening now with AI tools is not that problem. It is not a procurement problem at all. The AI control plane…
-
The Platform Team Became a Finance Team
Platform team sprint planning in 2026 begins with budget allocation, not architecture review. The first question is no longer “what do we need to build?” — it’s “what can we afford to run?” >_ Architect’s Brief Architecture overview before you dive in Generating brief… This is not FinOps adoption. This is authority displacement. The platform…
-
Sovereign AI Requires a Sovereign Control Plane
For most enterprise infrastructure teams, AI sovereignty has been treated as a data residency problem. Get the data on-premises, in a compliant region, or behind a jurisdictional boundary — and sovereignty is achieved. That framing is wrong in a way that is becoming increasingly expensive to ignore. >_ Architect’s Brief Architecture overview before you dive…
-
The Degradation Ladder
THE RECOVERY ENGINEERING SERIES >_ Architect’s Brief Architecture overview before you dive in Generating brief… PART 01 The Retry Storm Is a Self-Inflicted DDoS LIVE PART 02 Incident Recovery Process: Why the Incident Isn’t Over After Restore LIVE PART 03 Recovery Ends the Outage. It Doesn’t End the Incident. LIVE PART 04 The Degradation Ladder:…
-
IaC Drift Detection: Design for Detection, Not Prevention
Drift is not a tooling failure. It is evidence that multiple control planes still exist. >_ Architect’s Brief Architecture overview before you dive in Generating brief… That reframe matters more than any detection tool you deploy. IaC drift detection is typically treated as an operational hygiene problem — a gap in your automation coverage, a…
-
Inference Is Becoming the New Steady-State Cost Center
Training was a bounded investment event. Inference is an unbounded operational residency problem. >_ Architect’s Brief Architecture overview before you dive in Generating brief… That distinction is the one most AI cost conversations refuse to make. The infrastructure budget conversation for AI has moved — not from “cheap” to “expensive,” but from “event” to “permanent.”…
-
The Dashboard Said the Migration Succeeded
Migration dashboard failure has a consistent pattern: the tooling reports 100% complete, health checks pass, services respond — and production discovers a different set of facts three weeks later. The dashboard wasn’t wrong. It measured exactly what it was designed to measure. Task completion against a pre-defined scope. Operational continuity was never in that scope….
-
GPU Utilization Is Becoming the New Cloud Waste Crisis
Enterprises are now paying premium-market prices for infrastructure that spends most of its life waiting. The number that frames this era: average GPU utilization across enterprise Kubernetes clusters sits at 5%, according to Cast AI’s 2026 State of Kubernetes Optimization Report — drawn from measured production telemetry across 23,000 clusters, not a survey. That figure…
-
Idle Cost Is the New Egress Cost
Idle cloud cost is now the bill surprise egress used to be — except it’s structurally worse. Egress escaped the architecture. Idle cost is required by it. The entire optimization playbook built around idle assumes you can eliminate it by correcting a provisioning decision. Increasingly, you can’t. >_ Architect’s Brief Architecture overview before you dive…
-
The Infrastructure Team Is the Real Single Point of Failure
Every serious infrastructure investment goes into redundant hardware, distributed systems, and multi-region failover. Almost none goes into the one dependency that sits above all of it — the small number of engineers whose departure, unavailability, or burnout makes the environment unrecoverable. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The infrastructure bus…
-
The VMware Exit Has Entered the Coexistence Era
Somewhere around 2025, the enterprise conversation about VMware quietly rewrote its own objective. “Replace VMware” became “reduce VMware dependency” — not in any formal announcement, not in a strategy document, but in the actual architecture decisions organizations were making as migration programs ran longer than planned and the complexity of what they were replacing became…
-
Inference Routing Is Becoming an Infrastructure Placement Problem
The request arrives. The model answers. For most teams, everything in between is invisible — a gateway rule, a load balancer entry, maybe a classifier someone wrote three months ago. That worked when inference meant one cluster and one model family. The execution environment was fixed, so the routing decision was trivial. >_ Architect’s Brief…
-
The Console Is the Shadow Control Plane
Most organizations believe they have one infrastructure control plane. They have two. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The declared control plane has policy gates, approval workflows, branch protections, and an audit trail that connects change to intent. The operational control plane has a browser and a credential. Both mutate…
-
Egress Audit Framework: How to Find Unbounded Movement Paths
Every unbounded egress path is an architectural permission boundary that was never intentionally designed. >_ Architect’s Brief Architecture overview before you dive in Generating brief… That framing matters because it changes what you’re actually looking for. The conventional approach treats egress as a billing problem — costs go up, FinOps investigates, the dashboard shows a…
-
The Day 2 Operations Debt You Inherited From Terraform
Terraform codebases outlive the teams that wrote them. That is the first thing to understand before you inherit one. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The provisioning worked. The deployment velocity was real. The infrastructure exists, it runs, and the state file says it matches reality. What accumulated silently over…
-
The VM That Survived the Migration But Lost Its Identity
The most expensive vmware migration issues don’t happen at cutover. They happen three days later, when something that passed every checklist starts failing in ways nobody can trace back to the migration. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The migration ran clean. The VM came up on AHV within the…
-
The Model Answered. Nobody Asked Who Authorized That.
The ticket came in on a Tuesday. The AI assistant connected to Jira, Confluence, and Slack — the standard enterprise productivity stack. A product manager asked it for “incident history on the payment service.” The model returned a thorough summary: timeline, root cause, contributing factors, and a section pulled from a postmortem written by a…
-
Recovery Ends the Outage. It Doesn’t End the Incident.
THE RECOVERY ENGINEERING SERIES >_ Architect’s Brief Architecture overview before you dive in Generating brief… PART 01 The Retry Storm Is a Self-Inflicted DDoS LIVE PART 02 Incident Recovery Process: Why the Incident Isn’t Over After Restore LIVE PART 03 Recovery Ends the Outage. It Doesn’t End the Incident. YOU ARE HERE PART 04 The…
-
The Control Plane Problem In VMware Alternatives
Most VMware migration plans inventory VMs, clusters, storage, and licensing. Very few inventory the operational assumptions attached to vCenter itself. The result is predictable: the hypervisor migration succeeds in staging, but production operations degrade because the virtualization control plane functions the organization depended on were never modeled as architecture. >_ Architect’s Brief Architecture overview before…
-
Why Most “Cheaper Cloud” Strategies Fail
The organization runs the program. Reserved instances purchased, rightsizing applied, maybe a workload consolidation push across three regions. Spend drops 18%. Leadership calls it a win. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Six months later, inter-region data transfer climbs again. Kubernetes clusters proliferate across environments that were supposed to consolidate….
-
AI Workloads Break Traditional FinOps Models
The GPU cluster is idle. The inference bill doubled anyway. Nobody can explain which architectural decision caused it. >_ Architect’s Brief Architecture overview before you dive in Generating brief… That moment — the bill that arrives without a traceable utilization event — is where traditional ai finops loses the thread. Not because FinOps teams aren’t…
-
The Cloud Bill Is Your Real Org Chart
The meeting starts the same way every quarter. Someone pulls up the cloud bill. The number is higher than last quarter. Six teams are in the room, and somewhere in the line items — usually buried between data transfer charges and a cluster of snapshot storage entries — there is a resource nobody can explain….
-
The Configuration Drift Discovery During a Drill
Quarterly recovery drill. Backup job green for four months. Restore executes cleanly — data intact, VM boots, database service starts. The application fails on the first transaction. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Three hours disappear into backup triage before anyone checks the environment. The backup was not the problem….
-
Why Your DNS Failover Didn’t Actually Fail Over
The failover was declared at 02:14. The runbook was followed. DNS records updated. Health checks passing on secondary. The on-call engineer closed the incident bridge call at 02:31 with a single line in the ticket: failover complete. At 02:32, a monitoring alert fired. Traffic was still hitting the dead primary. >_ Architect’s Brief Architecture overview…
-
The Skills Gap Is the Real VMware Exit Risk
The vmware skills gap that stalls migrations is not a certification problem. It is not a headcount problem. It is an operating model problem — and most VMware exit plans never model it. >_ Architect’s Brief Architecture overview before you dive in Generating brief… When an organization exits VMware, the platform changes. The operating model…
-
Rubrik vs Cohesity: The Enterprise Decision Framework
Most enterprise backup evaluations do not stall because one platform fails technically. The rubrik vs cohesity decision stalls because both pass — and then the evaluation committee realizes it has been asking the wrong question. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Both platforms cleared restore testing. Both cleared immutability review….
-
Your CI-CD Pipeline Is Your Real Infrastructure Control Plane
Terraform defines desired state. Kubernetes reconciles workload state. Cloud consoles expose state. None of those systems decides whether infrastructure state is allowed to change. The ci-cd control plane does — or more precisely, the CI-CD pipeline is the only system in most environments that can hold that authority. That distinction — between storing state and…
-
The Connected Air Gap: Why Most Backup Isolation Fails
Most backup architectures marketed as air-gapped are not isolated. They are reachable systems with better storage controls. Shared identity, shared control plane, scheduled connectivity, and immutable-but-addressable storage all produce the same outcome: production compromise can still destroy recovery without touching backup data. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Data protection…
-
The “Lift-and-Shift to KVM” Fallacy
The VM conversion completed without errors. Every workload made it across. The migration dashboard showed green, the project lead closed the ticket, and the consultants left the building. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Three weeks later, backup verification jobs are silently failing. Monitoring dashboards are dark. The on-call team…
-
How to Read a Cloud Bill Like an Architect
Cloud bill analysis is one of the most underused diagnostic tools in infrastructure architecture. Most engineers avoid it because it looks like finance. Most architects cannot afford to — because buried in the noise are five recurring signals that expose design decisions, not usage accidents. >_ Architect’s Brief Architecture overview before you dive in Generating…
-
PersistentVolumes vs StorageClasses: When You Actually Need Each
The PersistentVolume vs StorageClass confusion is not a syntax problem. It is an architectural model problem. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Teams get confused because they compare the factory to the disk and forget the claim is what the workload actually touches. PersistentVolume and StorageClass are not alternatives. They…
-
Google Just Moved the Control Plane Boundary
The control plane boundary just moved. Most platform architectures were not built for that assumption — and most teams have not noticed yet. >_ Architect’s Brief Architecture overview before you dive in Generating brief… For a decade, the Kubernetes scaling playbook had one move: add another cluster. Need more capacity? Add a cluster. Need workload…
-
GPU Scheduling in Kubernetes: Start Before the Scheduler
Most teams think gpu scheduling starts with the scheduler. >_ Architect’s Brief Architecture overview before you dive in Generating brief… It starts with demand modeling. By the time Volcano, Kueue, or KEDA enters the conversation, the expensive mistake has usually already been made. The cluster was provisioned against a theoretical peak that rarely materializes. The…
-
Cost Visibility Is Not Cost Control
Cost visibility tells you what your architecture costs. Cost control determines whether that architecture should have existed in the first place. >_ Architect’s Brief Architecture overview before you dive in Generating brief… These are not the same discipline. Most organizations treat them as if they are — and the FinOps data proves they have been…
-
Your AI Cluster Is Idle 95% of the Time
Your gpu utilization dashboard reads 40%. The cluster is healthy. The GPUs are loaded. Work is happening. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Except it isn’t. That 40% gpu utilization figure is a peak average across a monitoring window. What it doesn’t show is the seven minutes before that spike…
-
What Breaks First After You Leave VMware
On Day 32, the storage team escalates. Veeam SureBackup verifications are silently failing on a subset of workloads that migrated cleanly out of VMware four weeks earlier. The jobs report success. The backups complete. But the verification phase — the part that actually proves the data is recoverable — quietly stopped working somewhere between cutover…
-
The Retry Storm Is a Self-Inflicted DDoS
THE RECOVERY ENGINEERING SERIES >_ Architect’s Brief Architecture overview before you dive in Generating brief… PART 01 The Retry Storm Is a Self-Inflicted DDoS YOU ARE HERE PART 02 Incident Recovery Process: Why the Incident Isn’t Over After Restore LIVE PART 03 Recovery Ends the Outage. It Doesn’t End the Incident. LIVE PART 04 The…
-
etcd Is Your Kubernetes Database: What It Does, What Breaks, and What to Watch
etcd kubernetes is the only component in your control plane that holds state — and most teams don’t think about that until the cluster starts behaving in ways they can’t explain. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Kubernetes doesn’t store state in your pods. It doesn’t store state in your…
-
Incident Recovery Process: Why the Incident Isn’t Over After Restore
THE RECOVERY ENGINEERING SERIES >_ Architect’s Brief Architecture overview before you dive in Generating brief… PART 01 The Retry Storm Is a Self-Inflicted DDoS LIVE PART 02 Incident Recovery Process: Why the Incident Isn’t Over After Restore YOU ARE HERE PART 03 Recovery Ends the Outage. It Doesn’t End the Incident. LIVE PART 04 The…
-
Operating Gateway API in Production: What the Migration Guides Don’t Cover
>_ Kubernetes Ingress Architecture Series >_ Architect’s Brief Architecture overview before you dive in Generating brief… >_ Part 0 The Decision Layer: Four Paths, Four Failure Modes How to evaluate the ingress-nginx retirement before picking a direction >_ Part 1 Gateway API Is the Direction. Your Controller Choice Is the Risk. The architectural shift and…
-
Kubernetes Is Not an LLM Security Boundary
The LLM security boundary problem isn’t a Kubernetes misconfiguration. It’s a category error. >_ Architect’s Brief Architecture overview before you dive in Generating brief… You’re applying infrastructure isolation to a system whose failure mode is behavioral. Kubernetes was designed to answer one question: is the workload running correctly? It answers that question well. But when…
-
Azure VMware Solution vs Native Azure: Architecture Trade-offs, Costs, and Exit Risk
Azure VMware Solution looks like the safe path out of a Broadcom licensing conversation. Your team already knows vSphere. Your tooling already maps to VMware constructs. AVS lets you move workloads to Azure without retraining anyone or rearchitecting anything. On paper, the risk profile looks low. >_ Architect’s Brief Architecture overview before you dive in…
-
Exit Cost as a First-Class Metric: The Architecture Constraint Nobody Models
Most architectures assume mobility. Multi-cloud, failover, workload portability — these are modeled as design goals, written into strategy documents, and presented to leadership as evidence of vendor independence. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Then the bill arrives. The ability to move a system is not determined at migration time….
-
The Restore Path Is the Most Neglected Part of Backup Design
The restore path is where backup architectures fail — not the backup job, not the retention policy, not the storage tier. The path from a completed backup to a verified, production-usable state is the part of data protection design that most teams never model, never test, and discover only under incident conditions. >_ Architect’s Brief…
-
The CLI Was Always the Control Plane. Now It’s Being Handed to Machines.
The CLI control plane is the most powerful — and least governed — layer in most enterprise infrastructure stacks. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Most infrastructure changes don’t happen in dashboards. They happen in terminals. The UI is where you observe. The CLI is where you commit. A console…
-
Agentic AI Has a Control Plane Problem — Because It Became the Control Plane
Agentic AI control plane governance is the architecture problem most teams are not modeling — and the one that will produce the most expensive failures in 2026. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The control plane became the most sensitive layer in modern infrastructure. So we locked it down. Kubernetes…
-
Ransomware Recovery Time Is an Architecture Problem, Not a Backup Problem
Ransomware recovery architecture is where most enterprise resilience programs break down — not because organizations lack backups, but because they never designed systems that could be rebuilt under pressure. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Most organizations have backups. Most have runbooks. Many have incident response plans on file and…
-
Kubernetes Ingress to Gateway API Migration: How to Move Without Breaking Production
>_ Kubernetes Ingress Architecture Series >_ Architect’s Brief Architecture overview before you dive in Generating brief… >_ Part 0 The Decision Layer: Four Paths, Four Failure Modes How to evaluate the ingress-nginx retirement before picking a direction >_ Part 1 Gateway API Is the Direction. Your Controller Choice Is the Risk. The architectural shift and…
-
AWS vs Azure vs GCP: The Decision Framework Most Teams Skip
A cloud provider decision framework should answer one question: not which cloud is best, but which set of tradeoffs your organization can actually absorb. Most teams never ask it. They choose based on pricing sheets, discount conversations, and whoever gave the best demo — then spend the next three years engineering around the decision they…
-
AI Infrastructure | Cloud Architecture | Kubernetes | Modern Infrastructure | Virtualization Architecture
The Control Plane Shift: Every Infrastructure Decision Now Looks the Same
The control plane shift is the most important infrastructure concept of 2026 — and most teams are experiencing it three or four times simultaneously without recognizing it as the same decision each time. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Your VMware renewal lands on the desk. The number is larger…
-
Rubrik vs Cohesity: Which Architecture Holds Under Ransomware Pressure?
Rubrik vs Cohesity ransomware protection looks identical on paper — until you simulate an attack. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The marketing story for both Rubrik and Cohesity reads well: immutable snapshots, air-gapped vaults, threat detection, rapid recovery. On paper the gap between them is marginal. Under attack pressure,…
-
containerd vs CRI-O: Memory Overhead at Scale (Real Node Density Limits)
When evaluating containerd vs CRI-O, the decision rarely comes down to features — it comes down to what happens at node density limits. >_ Architect’s Brief Architecture overview before you dive in Generating brief… At low pod counts, every container runtime looks efficient. At scale, memory overhead becomes the limit you didn’t plan for. This…
-
Velero Going CNCF Isn’t About Backup. It’s About Control.
The Velero CNCF backup announcement at KubeCon EU 2026 in Amsterdam was framed as an open source governance story. Broadcom had contributed Velero — its Kubernetes-native backup, restore, and migration tool — to the CNCF Sandbox, where it was accepted by the CNCF Technical Oversight Committee. The Sandbox application was originally filed in February 2026….
-
Terraform vs OpenTofu: Cost, Control, and the Post-BSL Decision (2026)
The question isn’t “Terraform vs OpenTofu.” >_ Architect’s Brief Architecture overview before you dive in Generating brief… The real question is whether your infrastructure control plane is owned by a vendor — or governed as open infrastructure. The BSL change in 2023 was the forcing function. But the architectural consequences are only fully visible now….
-
Nutanix vs VMware: The Post-Broadcom Decision Framework (2026)
Nutanix vs VMware used to be a hypervisor evaluation. It isn’t anymore. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Pre-Broadcom, the VMware vs. Nutanix conversation was an architecture conversation. You weighed feature sets, performance characteristics, ecosystem depth, and operational fit. The hypervisor was a technical decision. Post-Broadcom, the unit of decision…
-
Gateway API Is the Direction. Your Controller Choice Is the Risk.
>_ Kubernetes Ingress Architecture Series >_ Architect’s Brief Architecture overview before you dive in Generating brief… >_ Part 0 The Decision Layer: Four Paths, Four Failure Modes How to evaluate the ingress-nginx retirement before picking a direction ▶ Part 1 — You Are Here Gateway API Is the Direction. Your Controller Choice Is the Risk….
-
Veeam vs Commvault: How Enterprise Backup Platforms Fail Differently
Veeam vs Commvault is not a feature comparison. I’ve seen both of these platforms fail in production — not in the way vendor docs describe, but in the way systems actually break at scale, under pressure, at 2 AM when recovery is the only thing that matters. >_ Architect’s Brief Architecture overview before you dive…
-
Your Monitoring Didn’t Miss the Incident. It Was Never Designed to See It.
I’ve watched observability vs monitoring play out as a live incident more times than I can count. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The dashboard was green. The on-call engineer was not paged. The monitoring system did exactly what it was designed to do — it watched for thresholds, waited…
-
Ingress-NGINX Deprecation: What to Do Next (Four Paths, Four Failure Modes)
>_ Kubernetes Ingress Architecture Series ▶ Part 0 — You Are Here The Decision Layer: Four Paths, Four Failure Modes How to evaluate the ingress-nginx retirement before picking a direction >_ Architect’s Brief Architecture overview before you dive in Generating brief… >_ Part 1 Gateway API Is the Direction. Your Controller Choice Is the Risk….
-
VMware Licensing Costs: Why Most Estimates Are Wrong (And How to Fix Them)
You didn’t underestimate VMware licensing. >_ Architect’s Brief Architecture overview before you dive in Generating brief… You underestimated how it’s calculated. That distinction matters more than it sounds. The teams that get surprised by VMware renewal numbers aren’t making arithmetic errors. They’re modeling the wrong thing entirely — counting virtual machines when the invoice is…
-
AI Didn’t Reduce Engineering Complexity. It Moved It
The pitch for AI in engineering was straightforward: automate the repetitive, accelerate the cognitive, and let engineers focus on higher-order problems. Less time writing boilerplate. Less time provisioning infrastructure. Faster feedback loops. Lower operational overhead. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Some of that happened. But something else happened too…
-
Kubernetes Requests vs Limits: The Scheduler Guarantees One Thing. The Kernel Enforces Another.
You set requests. You set limits. The pod still gets throttled — or killed. Not because Kubernetes is broken. Because most teams have the wrong mental model of what these two fields actually do. >_ Architect’s Brief Architecture overview before you dive in Generating brief… When you configure kubernetes resource requests vs limits, the assumption…
-
Inference Observability: Why You Don’t See the Cost Spike Until It’s Too Late
The bill arrives before the alert does. Because the system that creates the cost isn’t the system you’re monitoring. Inference observability isn’t a tooling problem — it’s a layer problem. Your APM stack tracks latency. Your infrastructure monitoring tracks GPU utilization. Neither one tracks the routing decision that sent a thousand requests to your most…
-
Immutable Backup: Why Object Lock Isn’t Enough
Object lock backup is the standard answer to ransomware resilience. Enable S3 Object Lock, set a retention policy, check the compliance box. Most organizations stop there — and most organizations are wrong. Object Lock prevents deletion. It does not prevent compromise. True immutability isn’t a storage feature. It’s a system property, and it has to…
-
VPA vs HPA: Why Most Teams Choose the Wrong Autoscaler
The VPA vs HPA decision is one of the most misunderstood choices in Kubernetes resource management. Most Kubernetes teams reach for HPA first. It’s visible, it’s familiar, and the CPU metric dashboard makes the decision feel obvious. When traffic spikes, pods scale out. When traffic drops, they scale back. The mental model is clean. >_…
-
Your Backup Costs Aren’t What You Think: Calculating the True Cost Beyond Storage
You didn’t underestimate backup storage. You underestimated your true backup costs. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Storage costs are what vendors quote. GB/month is a number that fits in a spreadsheet, survives a budget review, and closes a procurement conversation. It is also the smallest component of what backup…
-
Cloud Egress Costs Explained: Why Your Architecture Is Paying a Tax You Never Modeled
You modeled compute. You modeled storage. You built cost estimates, ran capacity planning, and got sign-off on the architecture before a single resource was provisioned. >_ Architect’s Brief Architecture overview before you dive in Generating brief… You did not model what it costs to move data. Cloud egress is the tax that accumulates invisibly —…
-
Cost-Aware Model Routing in Production: Why Every Request Shouldn’t Hit Your Best Model
Your system isn’t expensive because your models are expensive. >_ Architect’s Brief Architecture overview before you dive in Generating brief… It’s expensive because every request defaults to the most capable model you have. That’s not a cost problem. That’s a routing problem. And most systems don’t have a routing layer at all. Part 1 established…
-
InfiniBand Is Losing the Fabric War. Here’s What That Changes for Your Architecture.
The InfiniBand vs RoCEv2 decision has been settled at the hyperscaler level — and the answer is Ethernet. Broadcom’s March 2026 earnings confirmed what most AI infrastructure architects had already suspected: roughly 70% of new AI infrastructure deployments are now choosing Ethernet-based fabrics over InfiniBand. That number is worth sitting with for a moment —…
-
Rubrik vs Cohesity: Which Backup Architecture Actually Scales?
Most Rubrik vs Cohesity comparisons are useless. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Not because the features are wrong — but because neither Rubrik nor Cohesity fails in a feature checklist. They fail when your environment scales in ways the architecture didn’t expect. The question isn’t which platform has better…
-
The Training/Inference Split Is Now Hardware — What GTC 2026 Actually Changed
The inference infrastructure decision most teams are ignoring isn’t the Vera Rubin GPU. It was not the $1 trillion demand forecast. It was not Jensen Huang calling NVIDIA “the inference king.” >_ Architect’s Brief Architecture overview before you dive in Generating brief… The announcement that matters is the Groq 3 LPX — a dedicated inference…
-
Autonomous Systems Don’t Fail. They Drift Until They Break.
Autonomous systems drift before they fail. Software fails loudly. A service crashes. An API returns 500. A pod restarts. The alert fires. You respond. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Autonomous systems don’t work that way. They degrade quietly. They drift. They accumulate small deviations — a few extra tokens…
-
Vertical Pod Autoscaler in Production: In-Place Resize Works — Until It Doesn’t
Kubernetes 1.35 made in-place pod resize stable. Most of the coverage stopped there. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The narrative wrote itself: Vertical Pod Autoscaler finally works for stateful workloads. No more restarts. Enable InPlaceOrRecreate and let the autoscaler do its job. The restart tax is gone. That framing…
-
Proxmox vs Nutanix vs VMware: The Post-Broadcom Constraints No One Explains
The Proxmox vs Nutanix vs VMware decision looks different in 2026 than it did two years ago. Broadcom didn’t just change VMware pricing — it changed the decision model entirely. >_ Architect’s Brief Architecture overview before you dive in Generating brief… This is no longer a feature comparison between hypervisors. Every enterprise infrastructure team re-evaluating…
-
Designing Backup Systems for an Adversary That Knows Your Playbook
Why traditional backup strategies fail against modern ransomware — and how to design recovery systems that assume the attacker already understands your environment. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Ransomware backup architecture fails the moment you design it for accidental failure instead of adversarial intent. Assume the attacker has your…
-
Your AI System Doesn’t Have a Cost Problem. It Has No Runtime Limits.
You built the alert. You configured the dashboard. You set the anomaly threshold at 120% of baseline spend. >_ Architect’s Brief Architecture overview before you dive in Generating brief… And your agentic pipeline still ran $40,000 over budget last quarter. Not because the tools failed. Because alerts and dashboards are not cost controls. They are…
-
Upgrade Physics: Designing for Rolling Maintenance Without Stopping Production
>_ The Post-Broadcom Migration Series Complete — Part 1 — Execution Physics Beyond the VMDK: Translating Execution Physics from ESXi to AHV >_ Architect’s Brief Architecture overview before you dive in Generating brief… Complete — Part 2 — Resource Contention The Controller Tax: Modeling Hyperconverged Resource Contention Complete — Part 3 — High-I/O Cutover Migration…
-
Kubernetes Is Moving Past Ingress. Most Clusters Aren’t.
The Kubernetes Gateway API project is not forcing you to migrate away from Ingress NGINX. There is no hard cutoff date, no deprecation warning in your cluster logs, no upgrade blocker. The project has simply moved on — and that quiet, undramatic shift is exactly what makes it operationally dangerous. >_ Architect’s Brief Architecture overview…
-
March 31 Isn’t a Deadline. It’s a Forced Architecture Decision.
>_ Update — April 2026 March 31 has passed. Broadcom’s VCSP termination completed on schedule — no EU interim measures were granted, and the European Commission confirmed only that the CISPE antitrust complaint is being assessed under standard procedures. The forced architecture decision this post mapped is now in execution for thousands of affected organizations….
-
AI Inference Is the New Egress: The Cost Layer Nobody Modeled
You modeled compute scaling. You modeled storage durability. You built egress budgets into your cloud architecture because you learned — the hard way, or from someone who did — that data movement is never free. >_ Architect’s Brief Architecture overview before you dive in Generating brief… You did not model AI inference cost. Neither did…
-
Database Backup Fidelity: Why Crash-Consistent Is Not a Database Backup
App-consistent database backup is the difference between a recoverable database and a recovery event that fails under pressure. Backup policies are designed by architects. They are discovered by engineers during recovery. >_ Architect’s Brief Architecture overview before you dive in Generating brief… That gap — between what was configured and what actually works — is…
-
Kubernetes 1.35 Removes the Restart Tax — Why Stateful Workloads Just Became Easier to Operate
Kubernetes 1.35 in-place pod resize graduates to stable — and with it, six years of a hidden operational tax on stateful workloads comes to an end. >_ Architect’s Brief Architecture overview before you dive in Generating brief… If a container needed more CPU or memory, the only safe answer was a restart. That design made…
-
Policy Translation: Mapping VMware DRS, SRM, and NSX to Nutanix Flow
>_ The Post-Broadcom Migration Series Complete — Part 1 — Execution Physics Beyond the VMDK: Translating Execution Physics from ESXi to AHV >_ Architect’s Brief Architecture overview before you dive in Generating brief… Complete — Part 2 — Resource Contention The Controller Tax: Modeling Hyperconverged Resource Contention Complete — Part 3 — High-I/O Cutover Migration…
-
containerd in Production: 5 Day-2 Failure Patterns at High Pod Density
Your containerd metrics look healthy. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Pod density is climbing. Node CPU is stable. Memory pressure is low. Then somewhere around 800–900 containers per node, something quiet happens: containerd-shim processes begin accumulating memory. Each failure signature maps directly to the diagnostic loops in the Rack2Cloud…
-
Kubernetes as the VMware Exit Ramp: How Platform Teams Are Reducing VMware Dependence
The Kubernetes VMware migration path is not what most platform teams expect. Thirty-three percent of enterprises evaluating VMware alternatives are selecting Kubernetes as their primary control plane for the transition. Not as the destination — as the mechanism. The distinction matters architecturally, and most of the coverage on this topic misses it entirely. >_ Architect’s…
-
Cloud Cost Is Now an Architectural Constraint
FinOps architecture used to mean dashboards. Cost reports. Monthly reviews where someone explained why the AWS bill was higher than forecast and promised to tag resources better next quarter. >_ Architect’s Brief Architecture overview before you dive in Generating brief… That model is over. The State of FinOps 2026 report marks the inflection point clearly:…
-
The Broadcom Legal Playbook: Why the VMware Lawsuits Are Accelerating Enterprise Exit Timelines
>_ Update — March 19, 2026 Breaking today: CISPE — the Cloud Infrastructure Services Providers in Europe — has filed an urgent request with EU antitrust regulators asking them to temporarily halt Broadcom’s termination of the VMware Cloud Service Provider program across Europe. The filing argues that Broadcom’s January 2026 decision to terminate all but…
-
The Repatriation Calculus: What the 93% Signal Actually Means
The 93% figure landed quietly in February 2026. Ninety-three percent of enterprises surveyed reported actively repatriating AI workloads from public cloud back to on-premises or colocation infrastructure. Not evaluating it. Not piloting it. Actively doing it. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The instinct is to read this as a…
-
Migration Stutter: Handling High-I/O Cutovers Without Data Loss
>_ The Post-Broadcom Migration Series Complete — Part 1 — Execution Physics Beyond the VMDK: Translating Execution Physics from ESXi to AHV >_ Architect’s Brief Architecture overview before you dive in Generating brief… Complete — Part 2 — Resource Contention The Controller Tax: Modeling Hyperconverged Resource Contention ▶ Part 3 — High-I/O Cutover (You Are…
-
Kubernetes Day‑2 Incidents: 5 Real‑World Failures and the One Metric That Predicts Them
Kubernetes day 2 failures are not random. The same five failure modes surface every month — and the tells are always there if you know which metrics to watch. Day 1 is shipping the cluster. Day 2 is living with it. >_ Architect’s Brief Architecture overview before you dive in Generating brief… And Day 2…
-
OpenTofu Adoption Is a Control Plane Migration — Not a License Change
OpenTofu migration is not a licensing decision. It is a control plane migration — and treating it as anything less is the fastest route to a corrupted state file, a broken provider dependency, or an operating model gap that surfaces at 2am on a production deployment. >_ Architect’s Brief Architecture overview before you dive in…
-
The Controller Tax: Modeling Hyperconverged Resource Contention
>_ The Post-Broadcom Migration Series Complete — Part 1 — Execution Physics Beyond the VMDK: Translating Execution Physics from ESXi to AHV >_ Architect’s Brief Architecture overview before you dive in Generating brief… ▶ Part 2 — Resource Contention (You Are Here) The Controller Tax: Modeling Hyperconverged Resource Contention Complete — Part 3 — High-I/O…
-
RTO, RPO, and RTA: Why Recovery Metrics Should Design Your Infrastructure
Every DR plan has an RPO. Every DR plan has an RTO. Almost none of them have an RTA. >_ Architect’s Brief Architecture overview before you dive in Generating brief… That’s the problem. RPO and RTO are the targets your business signed off on. RTA — Recovery Time Actual — is the number you discover…
-
Service Mesh vs eBPF in Kubernetes: Cilium vs Calico Networking Explained
Kubernetes networking has historically been split across two layers: the Container Network Interface (CNI), which handles pod-to-pod connectivity and network policy, and the service mesh, which adds application-layer features like mutual TLS, traffic routing, and observability. >_ Architect’s Brief Architecture overview before you dive in Generating brief… For years the common architecture looked like this:…
-
Sovereign Infrastructure Strategy: When Hybrid Cloud Becomes Dependency with Latency
Why Sovereignty Is a Control-Plane Problem — Not a Marketing Feature Sovereign infrastructure and disconnected cloud architecture are not the same problem — but they share the same failure mode: a control plane that cannot survive without external reachability. For a decade, “hybrid cloud” was positioned as independence. In practice, it usually meant placing infrastructure…
-
The Physics of Disconnected Cloud: Modeling Microbursts & Metro Risk
“Your RTT is 2ms. You’re well within the Metro threshold.” >_ Architect’s Brief Architecture overview before you dive in Generating brief… That sentence has caused more Metro cluster failures than any hardware fault. The problem isn’t the measurement. It’s what the measurement doesn’t tell you. Average RTT is a lie. Not because the number is…
-
Beyond the VMDK: Translating Execution Physics from ESXi to AHV
>_ The Post-Broadcom Migration Series ▶ Part 1 — Execution Physics (You Are Here) Beyond the VMDK: Translating Execution Physics from ESXi to AHV >_ Architect’s Brief Architecture overview before you dive in Generating brief… Complete — Part 2 — Resource Contention The Controller Tax: Modeling Hyperconverged Resource Contention Complete — Part 3 — High-I/O…
-
Infrastructure as a Software Asset: Why Your Data Center Needs a CI/CD Pipeline
Executive Summary Infrastructure as a Software Asset means treating your data center like a codebase. If you’re spinning up infrastructure with an API but then managing it with a CLI, you’re not really doing Infrastructure as Code. >_ Architect’s Brief Architecture overview before you dive in Generating brief… For years, people treated data centers like…
-
The Architecture of Migration: Why Licensing Isn’t Your Biggest Risk in the Post-Broadcom Era
The post-Broadcom infrastructure reality isn’t a licensing problem — it’s an architectural one. The industry is fixated on the Broadcom/VMware shake-up: contracts being torn up, CFOs suddenly caring about hypervisors, renewal clocks nobody planned for. That’s the surface event. But here’s the thing: licensing isn’t the real risk here. What really puts you in danger…
-
Performance Modeling the VMware Evacuation: Nutanix AHV vs Proxmox Ceph Storage I/O Reality
VMware migration performance modeling is the step most teams skip — and the one that determines whether the exit succeeds or fails. Panic over the Broadcom acquisition is over. Now it’s execution. And as more enterprise teams rush to leave VMware, most are treating hypervisor migrations like a simple server swap. That’s where production outages…
-
Deterministic Networking: The Missing Layer in AI-Ready Infrastructure
Deterministic Networking for AI Infrastructure: Engineering the System Backplane Deterministic networking is the infrastructure requirement that most AI cluster designs get wrong — not because the concept is misunderstood, but because it gets treated as a networking problem when it is actually a systems problem. In the legacy data center, networking was a best-effort transport…
-
The Nutanix Migration Stutter: Why AHV Cutovers Freeze High-IO Workloads
Infrastructure migration is not a compute event. It is a storage convergence event. Most migration failures are not network failures. They occur during the final delta sync, when the system must quiesce writes, replicate dirty memory pages, finalize metadata, and flip compute ownership. On AHV, this is where the “stutter” appears. Why This Feels Different…
-
Cloud Architecture | Azure Architecture | Cloud Strategy | Microsoft Azure | Modern Infrastructure | Networking
Azure Private Endpoint DNS Issues: Fix Recursive Loops and Prevent Subnet Exhaustion Before 2026
On March 31, 2026, Azure retires default outbound access. Thousands of organizations are deploying Private Endpoints in response—and many are discovering their DNS architecture was never designed for Private Link. If you are seeing intermittent 404s, “Address already in use” errors, or DNS resolution that works in the portal but fails in the shell, you…
-
Nutanix vs VMware: Availability vs Authority in the Post-Broadcom Datacenter (2026)
Executive Summary The nutanix vs vmware 2026 comparison starts in the wrong place when it focuses on features. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Today, that framing is obsolete. Modern outages rarely originate from hardware failure—they originate from control-plane failure: identity providers, automation systems, API trust chains, orchestration layers, and…
-
Configuration Drift: Enforcing Infrastructure Immutability
The ClickOps Virus & The Thermodynamics of Drift Any system that lets in entropy—really, any manual human tweak—starts falling apart sooner or later. It always seems harmless at first. A senior engineer logs in at 2 AM for a hotfix. A junior admin tweaks a firewall rule from the Amazon Web Services (AWS) console. Someone…
-
Resource Pooling Part 2: The Physics of Memory Overcommit (Ballooning, Compression, and Swap Failure)
When Overcommit Works vs. Explodes Memory overcommit isn’t some clever trick to magically create free RAM. It’s more like taking out a high-interest loan from your hypervisor—you’ll pay for it sooner or later. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Picture a typical enterprise setup: 26 hosts split into two clusters,…
-
Seccomp vs AppArmor: Which Actually Stops Container Breakouts?
Ask a junior developer how to secure a container, and they’ll probably say, “Just scan the image for CVEs.” Talk to an architect, and they’ll point you straight to the kernel. >_ Architect’s Brief Architecture overview before you dive in Generating brief… By 2026, nobody’s pretending containers are lightweight virtual machines anymore. That myth is…
-
Cross-Region Egress Patterns: S3→Internet vs VPC→VPC Traps
Sudden increases in cloud data egress costs occur because of unintended data transfer paths. In AWS architectures, two routing patterns account for a disproportionate percentage of cost overruns: First off, cloud providers don’t charge you to bring data into their network. The financial penalty occurs because moving data around or out of the environment results…
-
Cloud Native | Amazon AWS | AWS Architecture | Azure Architecture | Cloud Strategy | Microsoft Azure
Azure Landing Zone vs. AWS Control Tower: The Architect’s Deep Dive
In 2026, the Azure Landing Zone vs AWS Control Tower decision remains one of the most consequential governance choices an architect makes before a single workload goes live. Both solve the same problem — a secure, governed, scalable multi-account foundation — but they solve it in fundamentally different ways, with fundamentally different operational consequences downstream….
-
The Disconnected Brain: Why Cloud-Dependent AI is an Architectural Liability
This is Part 2 of the Rack2Cloud AI Infrastructure Series. Catch up on Part 1: TPU Logic for Architects: When to Choose Accelerated Compute Over Traditional CPUs. >_ Architect’s Brief Architecture overview before you dive in Generating brief… For years now, we’ve been told to build “Pass-through edges” when it comes to cloud architecture. The…
-
TPU Logic for Architects: When to Choose Accelerated Compute Over Traditional CPUs
This is Part 1 of the Rack2Cloud AI Infrastructure Series. To understand how to deploy these models outside the data center, read Part 2: The Disconnected Brain: Why Cloud-Dependent AI is an Architectural Liability. >_ Architect’s Brief Architecture overview before you dive in Generating brief… TPU Logic for Architects: When to Choose Accelerated Compute Over…
-
Rubrik vs Veeam — Appliance Immutability vs Infrastructure Control
Most Rubrik vs Veeam comparisons start with the wrong question. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Not which platform has better deduplication ratios or a cleaner dashboard. Not which vendor has a stronger roadmap or a bigger channel. Those comparisons exist everywhere and they don’t help you make the decision….
-
The Law of Data Gravity: Why Compute Eventually Moves to the Data
Hybrid cloud isn’t a compromise. It’s what happens when latency, bandwidth, and economics converge. For a decade, the industry operated under a simple assumption: “Move everything to the cloud.” And for a decade, it worked. The provider you select is the first gravity well you create. Before data accumulates, before workloads entangle, before the cost…
-
The Rack2Cloud Method: A Strategic Guide to Kubernetes Day 2 Operations
Why Your Cluster Keeps Crashing: The 4 Laws of Kubernetes Reliability Kubernetes is not a platform. It is a set of four intersecting control loops. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Day 0 is easy. You run the installer, the API server comes up, and you feel like a genius….
-
Storage | Cloud Native | Cloud Strategy | DevOps | Google Cloud Platform | Kubernetes | Modern Infrastructure
Storage Has Gravity: Debugging PVCs & AZ Lock-in
Storage Tier 1 Authority Cascades to ➔ >_ Architect’s Brief Architecture overview before you dive in Generating brief… [Compute] [Network] 🚨 Failure Signature Detected Events show: 1 node(s) had volume node affinity conflict. Stateful pods are stuck in Pending indefinitely after a node drain or upgrade. Events show: Multi-Attach error for volume “pvc-xxxx”: Volume is…
-
Kubernetes | Cloud Native | Cloud Strategy | DevOps | Google Cloud Platform | Modern Infrastructure | Networking
It’s Not DNS (It’s MTU): Debugging Kubernetes Ingress
Network Tier 1 Authority Cascades to ➔ >_ Architect’s Brief Architecture overview before you dive in Generating brief… [Compute] [Storage] 🚨 Failure Signature Detected Pods are Running and port-forward works, but the public URL returns 502/504. Small requests (like health checks) succeed, but large JSON payloads hang and time out. You see random timeout bursts…
-
Your Kubernetes Cluster Isn’t Out of CPU — The Scheduler Is Stuck
Compute Tier 1 Authority Cascades to ➔ >_ Architect’s Brief Architecture overview before you dive in Generating brief… [Storage] [Network] 🚨 Failure Signature Detected Grafana shows cluster CPU utilization is under 50%, but pods are stuck in Pending. Events show: 0/10 nodes are available: 10 Insufficient cpu. Events show: pod didn’t trigger scale-up (it wouldn’t…
-
Kubernetes ImagePullBackOff: It’s Not the Registry (It’s IAM)
Identity Tier 1 Authority Cascades to ➔ >_ Architect’s Brief Architecture overview before you dive in Generating brief… [Network] [Compute] 🚨 Failure Signature Detected ImagePullBackOff on AKS, EKS, or GKE. ACR/ECR authentication is intermittently failing. The issue magically resolves after a node or pod restart. You are attempting cross-subscription or cross-account registry access. >_ The…
-
Your Cloud Bill Quietly Increased in 2026 — Here’s Where the Money Is Actually Going
Part 4 of the Rack2Cloud Cloud’2 Cloud Fragility Series >_ Cloud Fragility Series 01 Multi-Cloud Cascading Failure Risks 02 Your Identity System Is Your Biggest Single Point of Failure 03 Vendor Lock-In Happens Through Networking — Not APIs 04 Your Cloud Bill Quietly Increased in 2026 — Here’s Where the Money Is Actually Going [CURRENT]…
-
Vendor Lock-In Happens Through Networking — Not APIs
Part 3 of the Rack2Cloud’s Cloud Fragility Series >_ Cloud Fragility Series 01 Multi-Cloud Cascading Failure Risks 02 Your Identity System Is Your Biggest Single Point of Failure 03 Vendor Lock-In Happens Through Networking — Not APIs [CURRENT] 04 Your Cloud Bill Quietly Increased in 2026 — Here’s Where the Money Is Actually Going >_…
-
Your Identity System Is Your Biggest Single Point of Failure
Part 2 of the Rack2Cloud’s Cloud Fragility Series >_ Cloud Fragility Series 01 Multi-Cloud Cascading Failure Risks 02 Your Identity System Is Your Biggest Single Point of Failure [CURRENT] 03 Vendor Lock-In Happens Through Networking — Not APIs 04 Your Cloud Bill Quietly Increased in 2026 — Here’s Where the Money Is Actually Going >_…
-
Multi-Cloud Doesn’t Prevent Outages — It Makes Them Cascade
Part 1 of the Rack2Cloud’s Cloud Fragility Series >_ Cloud Fragility Series 01 Multi-Cloud Cascading Failure Risks [CURRENT] 02 Your Identity System Is Your Biggest Single Point of Failure 03 Vendor Lock-In Happens Through Networking — Not APIs 04 Your Cloud Bill Quietly Increased in 2026 — Here’s Where the Money Is Actually Going >_…
-
Software Brutalism: Why Infrastructure Should Be Ugly
Stop trying to make production “delightful.” Reliability requires exposed pipes, raw concrete, and the death of the “Single Pane of Glass.” We are drowning in “delightful” dashboards. Every vendor pitch begins with a promise to abstract away the complexity of your stack. They sell you a “Single Pane of Glass”—a sleek, rounded-corner UI that hides…
-
All-NVMe Ceph for AI: When Distributed Storage Actually Beats Local ZFS
The case for Ceph NVMe AI training storage doesn’t start with a spec sheet comparison. It starts with a scale threshold. There is a belief in infrastructure circles that refuses to die: “Nothing beats local NVMe.” And for a single box running a transactional database, that’s mostly true. >_ Architect’s Brief Architecture overview before you…
-
Backups Are Compromised First: Inside Cohesity FortKnox and the Rise of Cyber Vaulting
Backups: The First Thing Hackers Go After >_ Architect’s Brief Architecture overview before you dive in Generating brief… For years, cyber vault backup strategy felt like an engineering debate. We obsessed over dedupe ratios, throughput, and how fast we could recover—all built on one big assumption: when production failed, backups would still be safe. Ransomware…
-
200 OK is the New 500: The Death of Deterministic Observability
It’s 3:00 AM. No calls, no alerts, everything looks spotless. The error rate is zero, p99 latency is a breezy 45ms, CPU and memory barely budge. On paper, you’re in the clear. What you’re about to experience is a semantic outage — and your monitoring has no vocabulary for it. Then your phone buzzes. The…
-
Sovereign Cloud vs. Public Cloud: Navigating Compliance in a Non-Deterministic Landscape
Sovereign cloud compliance requirements are hard constraints on provider selection — not post-migration considerations. Azure’s sovereign cloud depth, GCP’s data residency model, and AWS’s GovCloud each create different compliance profiles that must be evaluated before a workload is placed. The Cloud Provider Decision Framework: AWS vs Azure vs GCP covers compliance and data residency as…
-
LLM Ops vs. DevOps: Managing the Lifecycle of Generative Models in Production
The incident ticket looked fine. >_ Architect’s Brief Architecture overview before you dive in Generating brief… For years, every dashboard told us the same thing: the system was flawless. But the support queue told a different story. Suddenly, the chatbot was handing out 90% discounts that didn’t even exist. No crashes, no slowdowns, and no…
-
Fixing the “Backing Not Supported” RDM Error Before It Kills Your Migration
The Trigger: When the Migration Hangs You know the feeling. It’s Saturday morning, the maintenance window is open, and you are 98% through a “Lift and Shift” to your new HCI cluster. You highlight a batch of 50 VMs, click Migrate, select the destination storage, and hit Finish. Then, vSphere punches you in the face…
-
Logic-Gapping Your Data: Engineering “Air Gaps” in a Zero-Trust World
Let’s just say it: the air gap is over. Back in the day, “air gap” meant Dave tossed a tape in his truck and hauled it to some bunker in the mountains. It worked. It was also painfully slow. Now everyone wants a 15-minute RTO. Good luck getting a truck up a mountain that fast….
-
KASLR + SMEP/SMAP: Measuring Real Attack Surface Reduction
In this field, we love to treat kernel flags like they’re some kind of magic shield. Flip on CONFIG_RANDOMIZE_BASE=y for KASLR, tick the box, and suddenly the system’s “hardened.” Turn on SMEP and SMAP in the BIOS, and security closes out the ticket. Job done, right? But if I stopped you and asked, “Which actual…
-
The Backup Rehydration Bottleneck: Why Your Deduplication Engine Is Killing Your RTO
Data protection is the only discipline in IT where you can do everything right and still fail spectacularly during a disaster. The backup rehydration bottleneck is a perfect example — you can check every box, follow every “best practice,” and still end up with nothing when things go sideways. You hit your backup windows. You…
-
The Sovereign AI Mandate: Why Private Data Must Stay on Private Infrastructure
The “Samsung Moment” Building sovereign AI infrastructure means keeping your most sensitive data on hardware you control — not feeding it to a public API and hoping for the best. It happens everywhere. The CEO storms in and asks: “Why aren’t we using ChatGPT to write our code?” Legal chimes in: “What actually happens to…
-
GitOps for Bare Metal: Applying SDLC to Physical Hardware
The “Spreadsheet of Doom” You know the one. That “Master Inventory.xlsx” file everyone dumps in the Engineering Drive. MAC Address, IPMI IP, Rack Unit, Status—it’s all there. And it is always, 100% of the time, wrong. You go to provision a “spare” node, only to find it has a dead drive, or the wrong BIOS…
-
The CVM Tax: How Mis-Sized Controller VMs Quietly Kill AHV Performance
The “Ghost Latency” Ticket You know this ticket. It always looks the same. User: “The SQL database is crawling. The app is unusable.”Admin: “I checked Prism. Storage latency is 1.2ms. Network is clear. It’s your code.” Here’s the truth: you’re both right — and both wrong. The dashboard claims the disk is fast, but that’s…
-
GKE IP Exhaustion 2026: The /24 Trap & Autopilot’s Hidden Cost
The “Stockout” Error on a Healthy Subnet It’s 2 PM on a random Tuesday, and suddenly the Cluster Autoscaler throws a warning: Unschedulable—No free IPs in subnet. You open up the VPC. The subnet’s a /20, so that’s 4,096 IPs. You only have 15 nodes. Quick math: 15 nodes, maybe 30 pods each, tops. That’s…
-
GPU Fabric Physics 2026: Why 800G Isn’t Enough for 100k-GPU Training
The NCCL Timeout Nightmare GPU fabric physics is where $50 million clusters go to die. You wired up 800G OSFP optics, fired up your 100,000-GPU cluster for the Big Run — and six hours in, the loss curve flatlines. Logs start screaming: NCCL_WATCHDOG_TIMEOUT. It’s not a bad GPU. It’s not a driver crash. Honestly, it’s…
-
The Storage Handshake is Dead: Why HCI Redefines the Rules
Figure 1: The evolution of I/O—from physical cabling constraints to logical proximity. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The Ticket-to-LUN Latency Loop It always kicks off the same way. The SQL team gripes about write latency. The dashboard? Still green. You check the switch ports—zero errors. You poke around on…
-
CPU Ready vs. CPU Wait: Why Your Cluster Looks Fine but Feels Slow
The Reality Check: “Everything is Slow, But the Dashboard Says 30%” You know the ticket. “The application is sluggish.” You pull up Prism Element or vCenter. You look at the cluster average CPU usage. It’s sitting at a comfortable 35%. You check the specific VM. It’s idling at 20%. >_ Architect’s Brief Architecture overview before…
-
Cloud Architecture | Infrastructure as Code (IaC) | Kubernetes | Nutanix | Virtualization Architecture | VMware
Resource Pooling Physics: Mastering CPU Wait Time and Memory Ballooning in High-Density Clusters
I’ve spent 25 years watching infrastructure fail, and here’s what I’ve learned: most outages don’t kick off with a dramatic meltdown. They creep in quietly. A bit of scheduler pressure, memory ballooning quietly reclaiming guest pages, and no one’s dashboard even notices >_ Architect’s Brief Architecture overview before you dive in Generating brief… Your CPU…
-
The OpenTofu Transition: How to Break “Vendor Lock” Without Breaking Production
The Ransom Note (Trigger) I remember the exact moment I realized my Infrastructure as Code (IaC) wasn’t mine anymore. It wasn’t the initial Business Source License (BSL) announcement—that was just legal noise for the lawyers. No, it was a quiet Tuesday morning when a junior DevOps engineer pinged me: “Hey, the pipeline is failing on…
-
The Storage Wall: ZFS vs. Ceph vs. NVMe-oF for AI Training Clusters
The Real Problem: The “Checkpoint Stall” A 16x H100 cluster costs roughly $40/hour to sit idle. When your AI training storage can’t ingest a 2.8 TB Adam optimizer checkpoint fast enough, your GPUs wait — and your training run stalls. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Most AI clusters fail…
-
The Manual Nvidia Forgot: A Seasoned Architect’s Guide to AI Training Clusters
Building a cluster for inference is a weekend project. Building one for distributed training is a war of attrition against physics and “standard” enterprise defaults. After architecting several H100/H200 deployments for private LLM training, the bottlenecks are rarely the GPUs themselves. It’s the infrastructure tax paid for choosing the wrong networking stack, the wrong storage…
-
RTO Reality: Why Your Backups Mean Nothing Without a Recovery Drill
Backups are your insurance premium; recovery is cashing the claim. After 15+ years in production war rooms—from Nutanix HCI clusters to hybrid cloud migrations—I’ve watched “green” backup dashboards lie spectacularly. The bits sit safe on disk, but real Recovery Time Objective (RTO) crumbles under hydration speeds, API throttling, or the engineer with the encryption keys…
-
ZFS vs Ceph vs NVMe-oF: Choosing the Right Storage Backend for Modern Virtualization
I still have nightmares about a storage migration I ran back in 2014. >_ Architect’s Brief Architecture overview before you dive in Generating brief… We were moving off a monolithic SAN and onto an early “software-defined” storage platform. The sales engineers promised infinite scalability and self-healing magic. Two weeks in, a top-of-rack switch flapped, the…
-
GPU Cluster Architecture: Engineering the Hardware Stack for Private LLM Training
Private AI infrastructure is systems engineering, not optimization. If you treat a GPU cluster like a standard virtualization farm, you will fail. I have seen deployments where millions of dollars in H100s sat idle 40% of the time because the architect underestimated the network fabric or the storage controller’s ability to swallow a checkpoint. >_…
-
Terraform Is Not Infrastructure as Code — It’s Infrastructure as State: Here’s the Real Model
The biggest lie we tell junior engineers is that Terraform is a compiler. We hand them a .tf file and say, “This is the infrastructure.” >_ Architect’s Brief Architecture overview before you dive in Generating brief… It isn’t. If Terraform were truly “Infrastructure as Code,” then the code would be the source of truth. But…
-
The GKE “Zombie” Feature: Why gcloud Hides What the API Knows
When a Kubernetes founder tells you that you might be wrong about a platform limitation, you don’t argue with them. You open a terminal and try to break something. >_ Architect’s Brief Architecture overview before you dive in Generating brief… This week, following my autopsy of a GKE IP Exhaustion Outage, I entered a debate…
-
Proxmox vs VMware in 2026: A Migration Playbook That Actually Works
The “Proxmox curiosity” of 2023 has evolved into the “Proxmox mandate” of 2026. After two years of Broadcom’s portfolio “simplification” — which felt more like a hostage negotiation for mid-market IT — architects are no longer asking if they should move, but how to do it without losing their weekends. >_ Architect’s Brief Architecture overview…
-
Azure Governance Needs More Unix: The “BSD Jail” Pattern for Landing Zones
Stop “archi-splaining” governance to your engineers. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Modern Azure landing zone governance has mutated into a bloated bureaucratic layer that tries to micro-manage every resource through 400-page PDF frameworks. Somewhere along the way, we forgot the lesson Unix taught us forty years ago: Freedom within…
-
Moltbook Analysis: The Hostile Control Plane of AI-Only Social Networks
Moltbook AI agents now number over 1.4 million — autonomous bots sharing a live feed, broadcasting runnable prompts, code fragments, and behavioral templates to each other in real time. While mainstream coverage treats this as a curiosity, technical leadership needs to see it for what it is: a hostile multi-tenant control plane where unvetted configuration…
-
Client’s GKE Cluster Ate Their Entire VPC: The Class E Rescue (Part 2)
In Part 1, we diagnosed the crime scene: a production GKE cluster flatlined because its /20 subnet (4,096 IPs) hit a hard ceiling at exactly 16 nodes. The “official” consultant solution? Rebuild the VPC with a /16. The actual engineering solution? GKE Class E IP address space. If you are reading this, you likely don’t…
-
Nutanix Async & NearSync vs VMware SRM: The Blueprint for Modern DR
Latency is physics. Complexity is a choice. And for ten years, VMware SRM made us choose pain. SRM is supposed to be the “gold standard,” but under the hood it is a brittle house of cards built on Storage Replication Adapters (SRAs), placeholder VMs, and hope. If the Java process on your storage array doesn’t…
-
Azure Landing Zone Refactors: The Hub-and-Spoke Reality Check
An Azure landing zone built for day one rarely survives day 500. Refactoring to hub-and-spoke can be zero-downtime — if you treat network and identity as lift-and-shift assets, not rebuilds. But in the real world, Azure Policy drift, Private Link sprawl, and custom role creep are the first visible symptoms of landing zone entropy. And…
-
Client’s GKE Cluster Ate Their Entire VPC: The IP Math I Uncovered During Triage
The Triage: GKE Pod Address Exhaustion GKE pod IP exhaustion is one of the few failure modes that gives you no warning before it goes terminal. I recently stepped into a war room where a client’s primary scaling group had flatlined — workloads cordoned, deployments stuck in Pending, and the estimated cost of the stall…
-
The Physics of Data Egress: How to Burn $180k in a Weekend
Data egress architecture starts with a formula most teams never model: vendors charge pennies for storage and dollars for movement. I watched a Fortune 500 client lose $180,000 in 48 hours because a data engineer treated a cloud pipe like a LAN cable. It wasn’t a hack. It was physics meeting economics — and an…
-
Your Cloud Provider Is Not Your HA Strategy
A Tactical Playbook for Architecting, Testing, and Automating Real Multi-Cloud & Multi-Region Resilience We’ve previously explored why cloud SLAs fail as guarantees in our deep dive, Cloud SLA Failure & Resilience Strategy. This article focuses on how to survive those failures in practice — architecturally, operationally, and financially. >_ Architect’s Brief Architecture overview before you…
-
vSphere to AHV Migration Strategy: A Risk-Deterministic Framework for Legacy Workloads
Latency Is Undefeated: The Physics of Migration Failure A vSphere to AHV migration strategy that relies on tooling alone will fail. Physics does the real damage. vSphere estates are hitting Broadcom tax walls in 2026, but licensing isn’t what breaks migrations — across dozens of exits, we’ve seen the same pattern: 70% of migrations stall…
-
Immutability Is Not a Strategy: Engineering Recovery Silos for Ransomware Survival
Engineering recovery silos for ransomware survival is not the same thing as buying an immutability checkbox. I watched a company with perfect “Object Lock” backups lose everything because they managed their production cluster and their backup vault through the same Single Sign-On (SSO) provider. The attacker didn’t break the AES-256 encryption. They just hijacked the…
-
Kernel Hardening for Architects: Securing the Hypervisor Layer against Modern Exploits
Hypervisor kernel hardening is something I learned the hard way. >_ Architect’s Brief Architecture overview before you dive in Generating brief… In mid-2018, I inherited a Pure Storage // FlashStack environment where a third-party backup agent quietly loaded an unsigned ESXi kernel module. One night, that module pivoted laterally: guest → hypervisor → controller firmware….
-
Your Cloud Provider Is a Single Point of Failure — Enterprise Resilience Beyond Provider SLAs
Cloud SLA limitations become real the moment IAM starts returning 503s. It’s always a small event at first — a blip in CloudWatch, a dashboard alert muted over lunch. Then every automation pipeline you thought would “save you” suddenly becomes inert code waiting on a dead API. I watched great engineers helplessly SSH into nothing…
-
The 72-Hour Restore: Why “Instant Recovery” Failed in Production
The IT Director slid the report across the conference table with a confident smirk. “We’re good,” he said. “We just refreshed the entire backup stack. Immutable storage, air-gapped copies, and the vendor guarantees ‘Instant VM Recovery’ for up to 500 workloads. RTO is under 15 minutes.” I looked at the datasheet. It was impressive. It…
-
From Static Guardrails to AI Policy Agents: 2026 Playbook for Cloud Security Teams
AI policy agents are not a replacement for static guardrails — they are what happens when static guardrails hit their operational ceiling. I still remember the first time an automated guardrail saved my job. It was 2018. A junior engineer, exhausted from a sprint crunch, pushed a Terraform change that would have exposed our primary…
-
The 2-Node Trap: Why Your Proxmox “HA” Will Fail When You Need It Most (and How to Fix It)
The proxmox 2 node quorum fix is a 15-minute deployment that most engineers skip until Saturday morning teaches them why it matters. Two beefy nodes. Shared storage. HA enabled. I shut the laptop feeling smug — I had just replaced a six-figure VMware stack with two commodity servers and some Linux magic. >_ Architect’s Brief…
-
Azure Management Groups vs. Subscriptions: Where Should Policy Live?
Azure Management Groups vs. Subscriptions is not an academic debate — it is the governance decision that will either save your operations team or quietly bury them in manual remediation work. I once audited an Azure tenant for a mid-sized enterprise that had grown through acquisition. They had 65 subscriptions and zero Management Groups. When…
-
Cloud Architecture | Azure Architecture | Infrastructure as Code (IaC) | Microsoft Azure | Terraform
Terraform Error: “Tagging Not Allowed” (The Fix)
The Terraform Azure tagging error has ended more than a few Fridays early. There is nothing quite like the adrenaline spike of a failed terraform apply five minutes before your weekend begins. You’ve implemented a robust “Global Tagging Strategy” (perhaps using default_tags in your provider block), and suddenly, your pipeline slams into a wall. The…
-
Exposing Dark Matter: PowerShell Script to Find All Untagged Resources
An Azure untagged resources script is the flashlight you need before you go anywhere near enforcement mode. I’ve walked into too many “cloud migrations” where the client thinks they’re running lean, only to find $12k a month in “Dark Matter” — resources floating in the periphery with no owner, no tag, and no purpose. If…
-
Stop the Bleed: Azure Policy to Enforce ‘CostCenter’ Tags
Azure Policy enforce CostCenter tag is the single control that separates a managed cloud estate from a sponsored black hole. I’ve spent too many Sunday nights staring at an $80k Azure bill, trying to figure out which “Dev Test” environment grew a pair of legs and started running P3v3 instances. If you can’t attribute a…
-
$7,200 Zombie Load Balancers: The Taxonomy of Failure & Why ClickOps Breaks Planetary Scale
A cloud governance tagging strategy is not documentation — it is routing. The moment a resource lacks identity, it falls outside every automation, security boundary, and financial control you rely on. I’ve spent too many Sunday nights staring at an $80k Azure bill, trying to figure out which “Dev Test” environment grew a pair of…
-
Your Ransomware Plan Is Fiction: 5 Recovery Metrics Nutanix, Cohesity, Rubrik & Pure Can’t Hide
Ransomware recovery metrics are the only thing standing between your recovery plan and a PowerPoint. Every vendor demo shows a single VM booting in 60 seconds. Every real ransomware recovery looks like this: the backups are intact, the ransomware is neutralized, the executives are on the bridge — and nothing is coming back online. >_…
-
The Unholy Trinity: Cisco, Pure, and Nutanix Just Broke the HCI Tax (But Read the Fine Print)
Disaggregated HCI architecture is what happens when the industry finally admits that the HCI tax is real and starts engineering around it. We spent the last decade falling in love with Hyperconverged Infrastructure. It promised simplicity, and it delivered. But it came with a quiet economic penalty that vendors glossed over. The HCI Tax: The…
-
Closing the Console Gap: Detecting Manual Cloud Console Changes Before They Break Your Terraform State
Terraform drift detection is the discipline most teams skip until it causes an outage. “Infrastructure as Code” is a lie the moment someone with valid credentials logs into the AWS console. You can have the strictest CI/CD pipelines in the world, but if a junior admin manually opens a security group port to “debug” an…
-
The European Sovereign Cloud is a Hard Fork, Not a Region
AWS European Sovereign Cloud architecture is not a region you casually select in a dropdown. Stop thinking of the AWS European Sovereign Cloud as “another region in Germany.” Architecturally, aws-eusc is a Partition — a hard fork of the AWS control plane, similar to AWS GovCloud or AWS China. It has its own IAM root,…
-
Proxmox isn’t “Free” vSphere: The Hidden Physics of ZFS and Ceph
Proxmox ZFS vs Ceph storage is the decision that determines whether your VMware exit succeeds or quietly destroys your IOPS. Broadcom’s acquisition of VMware forced thousands of teams to ask a dangerous question: “Why not just move everything to Proxmox? It’s free.” >_ Architect’s Brief Architecture overview before you dive in Generating brief… On paper,…
-
From RAID to Erasure Coding: A Deterministic Guide to Storage SLAs for AI and Analytics
The erasure coding vs RAID debate ends the moment a second drive fails mid-rebuild on a petabyte-scale cluster. I watched it happen firsthand in 2018 during a massive Hadoop cluster migration. We were pushing 20PB of data. A 14TB drive died. The controller started the rebuild, calculating parity bit by bit. Then, at 65% completion—statistical…
-
The “Lift-and-Shift” Lie: Why “Like-for-Like” Architectures Fail in a Post-Broadcom World
A VMware to HCI migration strategy built on “keep it exactly the same” is how 60% of virtualization migrations fail to meet their ROI targets. The Board approved the budget, you selected your destination — Nutanix AHV, maybe Proxmox — and the mandate came down: “Just move everything over.” That sentence—“Just move everything over”—is why…
-
The Public Internet is Not an SLA: Architecting Deterministic Multi-Cloud Interconnects
I once debugged a “random” application timeout for a Chicago-based trading platform. The developers blamed the code; the sysadmins blamed the database. I blamed the weather. It turned out their critical API traffic was traversing the public internet via a standard IPsec VPN. A fiber cut in Ohio had forced BGP to re-route their traffic…
-
From vSphere to Nutanix AHV: The Deterministic Migration Checklist to Avoid the 99% Hang
vSphere to Nutanix AHV migration failures are almost never random — they are physics violations waiting to happen. >_ Architect’s Brief Architecture overview before you dive in Generating brief… There is no worse feeling in a migration window than watching the cutover bar hit 99% and stop. The tool says “Finalizing,” but the VM is…
-
Sub-500ms LLM Inference on AWS Lambda: The GenAI Architecture Guide
The lambda cold start llm problem is not what most engineers think it is — and that misdiagnosis is why their P99 latency stays in the 8-second range. When I posted my Llama 3.2 benchmarks on r/AWS, the reaction was a mix of excitement and outright disbelief. “It feels broken,” one engineer commented, referencing their…
-
Deterministic IaC Pipelines: Turning Terraform Plans into Signed Contracts Between Security and Operations
Deterministic IaC pipelines are the difference between infrastructure you can prove and infrastructure you can only hope is correct. I’ve spent the better part of two decades watching Infrastructure as Code (IaC) evolve. I remember the days of “shaky Bash scripts” held together by hope and cron jobs, and I’ve watched us graduate to “sophisticated…
-
Designing AI-Centric Cloud Architectures in 2026: GPUs, Neoclouds, and the Network Bottleneck
AI cloud architecture for GPU workloads breaks every standard cloud assumption you’ve built your career on. Standard cloud doctrine says: “Span multiple Availability Zones (AZs) for reliability.” In AI training, that doctrine will bankrupt you. >_ Architect’s Brief Architecture overview before you dive in Generating brief… I recently audited a cluster of 128 H100s running…
-
Nutanix AHV vs. vSAN 8 ESA: The 2026 I/O Saturation Benchmark
Stop Testing for “Peak IOPS” If you are designing a storage platform based on “Peak IOPS,” you are designing for a scenario that doesn’t exist. Nutanix AHV vs vSAN 8 ESA isn’t a race for speed — it is a race for survival when the buffers fill up. >_ Architect’s Brief Architecture overview before you…
-
The vCenter Control Plane: Optimization, Sizing, and the “Hidden” Java Tax
vCenter performance optimization is consistently under-engineered — not because the fixes are complex, but because most teams don’t understand what they’re actually tuning. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Most engineers treat the vCenter Server Appliance (VCSA) like a utility — a simple management console that just needs to “be…
-
The Shim Tax: The Hidden Engineering Costs of Hybrid Cloud
I recently audited a client’s AWS bill that had spiraled out of control. They hadn’t spun up massive new GPU clusters. They hadn’t doubled their user base. What they had done was connect a legacy on-prem reporting tool to an S3 bucket, assuming “Hybrid Cloud” meant the best of both worlds. Instead, they were hit…
-
The Multi-Hypervisor Future: How Architects Are Designing Beyond VMware
Architecting beyond VMware is no longer a contingency plan — it is the primary cost and risk management strategy for enterprise infrastructure in 2026. >_ Architect’s Brief Architecture overview before you dive in Generating brief… In my fifteen years of architecting enterprise stacks, I’ve seen vendors come and go, but I’ve never seen a shift…
-
The Multi-Cloud AI Stack: Why I’m Done Looking for a “Swiss Army Cloud”
Multi-cloud AI architecture is not about spreading workloads evenly across providers — it is about placing each workload on the platform whose physics match the requirement. For the first decade of my career, I chased the same goal every architect did: one provider, one control plane, one security model. It looked clean on a slide…
-
The Vector DB Money Pit: Why “Boring” SQL is the Best Choice for GenAI
Vector database pgvector is the most underused tool in the modern AI stack — and the most overpaid-for problem in the average GenAI budget. Vector Database pgvector vs Specialized DBs: The Cost Case I audited a GenAI startup last month that was paying $500/month for a managed Vector Database cluster. I asked to see the…
-
Cloud Architecture | Azure Architecture | Cloud Strategy | Google Cloud Platform | Kubernetes | Microsoft Azure
Serverless AI Inference Without Kubernetes: GCP Cloud Run, Azure Flex, and the Exit Strategy
Serverless AI inference has crossed a threshold most architects didn’t expect this early: you can now run production GenAI workloads — GPU-accelerated, scale-to-zero, without a single YAML manifest — on GCP Cloud Run and Azure Flex Consumption. For the last three years, running a custom model meant building and operating a Kubernetes cluster. That tradeoff…
-
AI Infrastructure Repatriation: Why On-Prem Is Now the Strategic Call for Enterprise AI
AI infrastructure repatriation is not a retreat from the cloud era. It is the architectural correction that follows when the economics of production AI diverge sharply from the economics of a proof of concept. For a decade, “Cloud First” was the correct default. For enterprise AI at production scale in 2026, it increasingly is not…
-
Stop Renting Intelligence: The Architect’s Case for On-Prem DSLMs
The new center of gravity. Visualizing the shift from massive public cloud “Brain” models to distributed, highly specialized on-prem “Neural Nodes.” AI repatriation isn’t a trend anymore — it’s an architectural reckoning. For the last two years, enterprises treated AI like a utility bill: swipe the corporate card, send data to an API endpoint, pay…
-
The Unpatched Gap: Architecting Survival for the “Double EOL” Reality
vSphere EOL security doesn’t end the day the patches stop — it begins there. Most organizations hit the October 2025 Double EOL cliff knowing the deadline was coming and chose to defer anyway. Windows 10 support ended. vSphere 7.x support ended. And the window between “no more patches” and “first weaponized zero-day” is not measured…
-
Broadcom Year Two: The “Stay or Go” Architecture Guide (2026 Edition)
Broadcom VMware migration decisions don’t get easier with time — they get more expensive. If Year One was denial and anger, Year Two is cold, hard architectural math. The “price protection” grace periods have expired. The perpetual support contracts have finally bled out. You are now staring at a fully subscription-based OpEx model that likely…
-
Why Serverless Isn’t Dead for GenAI — It’s Just Misunderstood
Serverless GenAI architecture doesn’t fail because Lambda is too slow — it fails because teams assign Lambda the wrong job. Debunking that myth requires redefining one boundary. Not technology — anatomy. The difference between the Brain and the Nerves. >_ Architect’s Brief Architecture overview before you dive in Generating brief… I recently ignited a firestorm…
-
The “Snapshot Tax”: Why Hidden Metadata is the Silent Killer of VMware Migrations
VMware snapshot migration failures rarely announce themselves. I’ve walked into too many ‘ready-to-migrate‘ environments where leadership swore everything was clean — no snapshots in vCenter, healthy datastores, backup jobs green for years. And yet — replication stalled, cutovers failed, and migration timelines collapsed. The common thread wasn’t tooling. It wasn’t network bandwidth. It was snapshot…
-
Regulating Generative AI: Lessons from Indonesia’s Grok Ban and What Comes Next
The Grok Ban: What Happened and Why It Matters Indonesia’s Communications and Digital Affairs Ministry temporarily blocked the AI chatbot Grok, developed by xAI and integrated into X, citing the AI’s ability to generate non-consensual sexual deepfake images, including disturbing depictions involving minors. This isn’t a “social media quirk.” It’s a regulatory first — a…
-
Which Workloads Should Never Leave The Cloud
(Even When Repatriation Looks Tempting) >_ Architect’s Brief Architecture overview before you dive in Generating brief… After publishing my piece on cloud repatriation, my inbox filled up fast. Not with disagreement—but with a different question: “Okay, fine. Some workloads should come home. But which ones absolutely should not?” That’s the right question. Cloud workload placement…
-
The Logic of Repatriation: When (and Why) To Move Workloads From Public Cloud Back To On-Prem
Cloud repatriation is no longer a fringe conversation — it is the inflection point where public cloud stops being an accelerator and starts being a tax. For the last decade, “Cloud First” wasn’t just a strategy; it was a religion. If you suggested buying a server, you were treated like a heretic clinging to a…
-
Cloud Architecture | Amazon AWS | AWS Architecture | Azure Architecture | Cloud Strategy | Google Cloud Platform | Microsoft Azure
Building a Portable Control Plane Across AWS, Azure, and GCP
A portable control plane isn’t about running the same VM image on three clouds — that’s the lie vendors have been selling since Java in the 90s. Docker promised it. Cloud vendors promise it now, usually right before they lock you into a proprietary service mesh or a database that only exists in us-east-1. Real…
-
The Container Runtime Benchmark 2026: containerd vs CRI-O vs crun for High-Density Nodes
The “Shim Tax” is Killing Your ROI Container runtime memory overhead is the hidden cost most teams never model until it shows up as a density ceiling they can’t explain. If you are running standard Kubernetes clusters on top of VMware or cloud VMs, you are paying a tax on every single pod you launch…
-
AWS Lambda for GenAI: The Real-World Architecture Guide (2026 Edition)
AWS Lambda LLM Inference 2026 is not the punchline it would have been two years ago.. Back then, Lambda was for glue code, JSON shuffling, and the occasional cron job. The idea of shoving a memory-hungry LLM into a 15-minute ephemeral function felt like trying to run Crysis on a toaster. >_ Architect’s Brief Architecture…
-
Bridge the Gap: AI-Driven Pure Storage Observability for Nutanix Environments
Pure Storage observability gaps have quietly killed more SLAs than capacity alerts ever will. For over 15 years, infrastructure teams have battled the “whack-a-mole” cycle — an application leaks data, the array hits 90%, and by the time a manual snapshot is triggered, the filesystem is already read-only. Reactive infrastructure creates unnecessary risk — and…
-
3-2-1-1-0 Backup Rule: Modernizing Protocols for 2026 Cyber-Resilience
The 3-2-1-1-0 backup rule represents the architecture shift from legacy redundancy to adversarial resilience. The traditional 3-2-1 strategy was designed to solve for hardware failure — the 3-2-1-1-0 extension is engineered to solve for adversarial intent. In a landscape where 94% of ransomware attacks now specifically target the backup server, a “copy” is no longer…
-
Nutanix AHV Day-2 Operations: The Architectural Reality
Nutanix AHV Day-2 operations expose the complexity gap that basic deployment guides never cover. In the current landscape of enterprise Broadcom exits, Nutanix AHV has transitioned from a niche alternative to the primary destination for enterprise post-Broadcom migration decisions. But bridging that complexity gap requires moving beyond initial configuration — an architect must master the…
-
Project Phoenix: An Enterprise Field Manual for the Great OpenTofu Migration
The “Sovereignty” ROI Don’t wait for the March 31, 2026 deadline to find out your infrastructure is locked.. Project Phoenix—our enterprise case study involving 1,200+ managed resources—proved that a move to OpenTofu v1.11 isn’t just about avoiding a $15,000/year “resource tax.” It’s about ensuring your engineering velocity isn’t dictated by a vendor’s licensing shifts. The…
-
The Great Terraform Exit: Is Your IaC Ready for the March 31 Sovereign Cutoff?
The “Refactoring Cliff” is Real This OpenTofu migration guide exists because March 31, 2026 is not a soft deadline — and most teams discover they need an OpenTofu migration guide after the invoice arrives, not before. On that date, the legacy Free tier of HCP Terraform officially reaches EOL — and teams that have been…
-
The Sovereign Baseline: Restoring Determinism to Hybrid-Cloud IaC
The Sovereign Drift Auditor exists because of a problem every cloud architect eventually faces: IaC drift. In my 15 years as a cloud architect, I’ve witnessed a recurring Day 2 disaster — the degradation of Infrastructure-as-Code into Ghost Infrastructure. It starts with an engineer making a five-minute fix in the AWS Console to troubleshoot a…
-
The CPU Strikes Back: Architecting Inference for SLMs on Cisco UCS M7
CPU inference SLM workloads are the most underserved category in enterprise AI architecture today. In the current AI gold rush, the industry standard advice has become lazy: “If you want to do AI, buy an NVIDIA H100.” For training a massive foundation model? Yes. For running ChatGPT-4 scale services? Absolutely — as we covered in…
-
The “Day 2” Broadcom Reality Check: VCF Operations: Decoupling the Stack When You Can’t Decouple the License
Broadcom VCF Operations in 2026 present a challenge no marketing deck prepared you for: you bought the full stack, but deploying all of it creates more operational debt than it solves. NSX, Aria, SDDC Manager — the license includes everything. The engineering question is which parts to actually run. This guide covers three strategies for…
-
The 2026 Licensing Trifecta: How Broadcom, Microsoft, and Oracle Are Collaborating to Drain Your Budget
Your 2026 software licensing strategy is being dismantled from three directions simultaneously — and most architects won’t see it until the renewal invoice lands. Having designed enterprise infrastructure for over 15 years, I remember when an Enterprise Agreement (EA) felt like a genuine partnership. You committed to spending millions, and, in return, the vendor gave…
-
Veeam + Securiti AI vs. Rubrik + Bedrock: The AI-Driven Data Resilience Decision Guide
AI driven data resilience has split enterprise backup architecture into two distinct philosophies — and the gap between them is widening. If you’ve been in the trenches as long as I have, you remember when backup was just “insurance”—a tape sitting in a truck on its way to Iron Mountain. Those days are dead. Today,…
-
Beyond the Hyper-scaler: Why AI Inference is Moving to the Edge (and How to Architect It)
The NVIDIA-Groq deal confirms what infrastructure architects have suspected for eighteen months: centralized cloud is struggling with AI inference edge workloads. Real-time inference at scale — thousands of devices, sub-20ms latency requirements, metered connectivity — breaks the hyperscaler model. This post covers the decision framework, financial reality, and architecture pattern for moving AI inference to…
-
The “Day 2” Reality of Migrating VMware to Nutanix: What the Migration Tools Don’t Tell You
When you migrate VMware to Nutanix, the migration tool moves the bits — but the operational model, backup chain, network abstraction, and licensing math are yours to rebuild from Day 1. Everyone loves the “green lights” on a migration dashboard. I’ve sat in plenty of steering committee meetings where the project lead flashes a slide…
-
The 5ms Lie: Why Your “Green” Dashboard is Killing Nutanix Metro Availability (And How to Fix It)
I have been in the War Room. You know the one. The application team is screaming that the database is freezing every few minutes. The storage team checks Prism—everything looks fine. The network team checks SolarWinds—links are green. Yet, the application is timing out. The culprit isn’t a hard down. It’s a micro-burst. A momentary…
-
Nutanix Metro Availability: Monitoring Latency in the Millisecond Era
Nutanix Metro latency failures don’t announce themselves — they hide inside 60-second polling windows until synchronous replication degrades and the protection domain makes the split-second decision to break the mirror. >_ Architect’s Brief Architecture overview before you dive in Generating brief… >_ Tool: Metro Latency Scout Browser-Based RTT & Jitter Detection at 250ms Resolution Standard…
-
Translating the Stack: A Field Guide to Migrating NSX-T Security to Nutanix Flow
Migrating from NSX-T to Nutanix Flow isn’t a firewall rule export — it’s a philosophy shift from network-centric security to workload-centric identity, and getting that translation wrong creates security holes before Day 1 is over. The most dangerous part of a hypervisor migration isn’t moving the data—it’s moving the logic. In the VMware ecosystem, NSX-T…
-
Precision Licensing: Calculating VVF and VCF Cores in the Broadcom Era
VMware core licensing under Broadcom’s per-core subscription model is no longer a renewal exercise — it’s an architectural decision that determines whether VVF or VCF is the financially defensible choice for your specific storage-to-compute ratio. When Broadcom pivoted VMware to a per-core subscription model, they didn’t just change the SKU—they changed the fundamental math of…
-
Governing The Shadow Architecture: A 2025 Guide to Enterprise LCNC
Enterprise low-code governance isn’t optional in 2025 — it’s the difference between a managed platform and a shadow architecture that owns your data before security finds it. Around 2018, I watched a Fortune 500 financial firm lose six months of engineering velocity because a marketing sub-team built a “simple” customer intake portal using a No-Code…
-
Cloud Native | Amazon AWS | AWS Architecture | Azure Architecture | Business Continuity | Data Protection | Disaster Recovery | Microsoft Azure
Building a Practical Disaster Recovery Plan for Your First Cloud Project
A cloud disaster recovery plan isn’t a backup strategy — it’s an architectural commitment that determines whether your business survives a region failure or spends 14 hours rebuilding databases by hand. I still remember the first “cloud” Disaster Recovery (DR) plan I reviewed back in 2012. The team assumed that because their app was running…
-
Cloud Native | Amazon AWS | Cloud Strategy | Engineering Tools | Google Cloud Platform | Microsoft Azure | Modern Infrastructure
Think Like an Architect: The Field Guide to Cloud Egress and Data Gravity
Cloud egress pricing is one of the most misunderstood cost drivers in enterprise architecture — and one of the most expensive to discover late. When you’re designing for Day 2 operations, you quickly realize that data isn’t just heavy—it’s expensive to move. I’ve seen countless “cloud-native” projects hit a wall during the scaling phase because…
-
The Veeam API Tax: Why Your Immutable Backup Storage Cost Is Never What It Looks Like
Immutable backup storage cost is never what the provider quotes you. The per-GB rate is the number that shows up in the sales deck. The number that shows up in your monthly bill — the one that blindsides engineering teams six months after go-live — is the API tax: the cumulative cost of every PUT,…
-
Cloud Native | Amazon AWS | AWS Architecture | Azure Architecture | Engineering Tools | Google Cloud Platform | Infrastructure as Code (IaC) | Microsoft Azure
“Gap of Grief”: Why Your Terraform Code Fails on Day 1
The “Gap of Grief”: While cloud providers speed ahead with new features, infrastructure-as-code tools often carry a heavy load of legacy support, creating a measurable lag. I’ve been designing cloud infrastructures for over 15 years, and the story is always the same. You see a flashy announcement at re:Invent or Ignite—maybe it’s a new high-performance…
-
Cloud Native | Amazon AWS | Cloud Strategy | Infrastructure as Code (IaC) | Microsoft Azure | Modern Infrastructure
The Terraform Wrapper Tax: Why Multi-Cloud Module Abstraction Fails in Production
Terraform multi-cloud modules were supposed to be the answer. Write once, deploy anywhere — a single module “compute” that could target AWS, Azure, or GCP by flipping a variable. Abstract the provider. Commoditize the infrastructure. In 2018, that vision was compelling enough that entire platform teams built their IaC strategy around it. >_ Architect’s Brief…
-
Cloud Native | Amazon AWS | AWS Architecture | Azure Architecture | Cloud Strategy | Hybrid Cloud | Microsoft Azure
Hybrid Cloud vs Multi-Cloud Architecture: The Engineering Reality Nobody Documents
The boardroom debate about moving to the cloud is over. What replaced it is harder: the engineering reality of managing what that decision actually produced. Hybrid cloud vs multi-cloud architecture isn’t a vendor comparison anymore — it’s a description of the operational burden your team carries every day, measured in egress bills, fragmented identity planes,…
-
Beyond the Migration: Best Practices for Running Omnissa Horizon 8 on Nutanix AHV
In the previous guide, we covered the milestone of Omnissa (formerly VMware EUC) officially supporting Horizon 8 on Nutanix AHV — the “why” and high-level “how” of migrating workloads off ESXi onto the native Nutanix hypervisor. >_ Architect’s Brief Architecture overview before you dive in Generating brief… Now the dust has settled. Your connection servers are…
-
Azure SQL Backup Security: Why Native Protection Has a Gap Rubrik Closes
Azure SQL backup security depends on more than Microsoft’s built-in protection. When you migrate to Azure SQL Managed Instance or Azure SQL Database, handing backup management to Microsoft feels like a solved problem — automatic full, differential, and transaction log backups, Point-in-Time Restore, geo-redundancy across region pairs. For standard operational failures, it is solved. For…
-
SQL Server Migration to Azure: The IaaS vs PaaS Decision Framework
SQL Server migration to Azure is not a single decision — it is a hierarchy of decisions that determines whether you end up with a managed platform that matches your operational maturity or an infrastructure bill that matches none of your assumptions. Before you touch a migration tool, you need to choose your landing zone….
-
Sovereign Cloud Architecture: What the Nutanix Distributed Model Means for Hybrid Architects
The era of the “borderless cloud” is hitting a geopolitical wall. >_ Architect’s Brief Architecture overview before you dive in Generating brief… For the past decade, the primary directive for cloud architects was speed and scalability. We deployed to regions based on latency to the user, largely ignoring jurisdictional lines. Today, regulatory frameworks like GDPR…
-
Ransomware-Ready Backup Architecture: The Three-Pillar Engineering Framework
In 2020, the advice was “have good backups.” In 2025, that advice is dangerously incomplete. Today, backup infrastructure is not the remediation; it is the primary target. Modern ransomware cartels know that if they encrypt your production data, you will restore. But if they delete your backups first, you will pay. Attackers now spend weeks…
-
Cloud Native | Amazon AWS | AWS Architecture | Azure Architecture | Cloud Strategy | Microsoft Azure
Cloud FinOps for Engineers: Escaping the Lift-and-Shift Cost Trap
Cloud FinOps for engineers isn’t an accounting discipline — it’s an architectural one. You’ve successfully migrated your first workload. The Terraform applied cleanly, the latency is within bounds, and the cutover was silent. Then, 30 days later, the first hyperscaler bill arrives. It is 40% higher than your strict estimate. Welcome to the “Lift and…
-
From Sysadmin to Cloud Engineer in 2026: The Definitive Skills Roadmap
Introduction: The Server Room is Evolving, Not Dying If you are a traditional systems administrator, you’ve likely felt the shift. The racking and stacking are decreasing; the API calls are increasing. The narrative that “sysadmins are obsolete” is false, but the reality is that the role is evolving rapidly into Platform and Cloud Engineering. Your…
-
Freedom from vSphere: A Deep Dive into Omnissa Horizon 8 on Nutanix AHV
Omnissa (formerly VMware EUC) has officially announced the General Availability (GA) of Horizon 8 on Nutanix AHV with the release of Horizon 8 version 2512. >_ Architect’s Brief Architecture overview before you dive in Generating brief… For the last decade, “Horizon” and “vSphere” were effectively synonyms. If you wanted the premier VDI experience, you paid…
-
The Indestructible Vault: How Veeam, Rubrik, and Cohesity Architect Immutable Backups
Introduction: The Day Your Backups Betrayed You Modern ransomware doesn’t just target production data. Sophisticated attackers spend weeks reconnoitering your network specifically to locate, compromise, and delete your backups before triggering the encryption event. If your backups are delete-able, they are not backups. They are just delayed victims. The answer is immutable backup architecture —…
-
Nutanix vs VMware vs Hyper‑V: How to Build a Fair Comparison as a Solutions Engineer
The Nutanix vs VMware vs Hyper-V decision in 2026 looks nothing like it did three years ago. The virtualization market has experienced a seismic shift. For fifteen years, the answer to “Which hypervisor should we use?” was almost automatically “VMware vSphere.” It was the default, the gold standard, the safe bet. >_ Architect’s Brief Architecture…
-
Sizing On-Prem AI: An Architect’s Look at Nutanix’s New GPT-in-a-Box Workflow
Nutanix GPT-in-a-Box sizing has been one of the most frustrating gaps in on-prem AI planning. For the past year, designing AI workloads on-premises has felt like the Wild West — rough spreadsheets, t-shirt sizes, and guesswork on inference overhead. That changed with Sizer 6.0.94, released December 2025. The version number looks incremental. The capability jump…
-
Breaking the HCI Silo: Nutanix Integration with Dell PowerFlex & Pure Storage
The Post-Broadcom Reality: Keeping the SAN Nutanix compute only nodes with external storage represent a fundamental shift in how enterprises can exit VMware without abandoning their existing storage investments. The premise of Hyperconverged Infrastructure was to kill the Storage Area Network in favor of distributed, direct-attached storage — one vendor, one platform, one throat to…
-
Hyper-V vs Nutanix AHV: Sizing Compute for Your First Customer PoC (A Decision Framework)
The Hyper-V vs Nutanix AHV sizing decision is where marketing slides crash into operational reality. For a Solution Engineer or Infrastructure Architect, the first customer Proof of Concept is the moment that distinction becomes expensive. The most common reason for early PoC performance failures is not bad software — it is bad math. When evaluating…
-
Nutanix AOS vs VMware vSphere: How to Demo Both Without Bias
The Broadcom Context You Cannot Ignore Demoing Nutanix AOS vs VMware vSphere in 2026 is not the same conversation it was in 2022. Broadcom’s acquisition of VMware — and the subsequent licensing restructuring, perpetual license elimination, and partner program consolidation — has changed the context of every bake-off. Engineers who were evaluating these platforms purely…
-
VMware Cloud Foundation vs. vSphere + NSX: A Deep Dive on Positioning for SEs
The VMware Cloud Foundation vs vSphere decision used to be straightforward. VCF was for large enterprises building a full software-defined data center. vSphere was for everyone else. The component model in between — vSphere plus individual add-ons as needed — gave architects the flexibility to match licensing to actual requirements. >_ Architect’s Brief Architecture overview…
-
AWS Organizations and Control Tower: What SEs Need to Explain to Customers
AWS Organizations and Control Tower are not the same thing. They are not interchangeable. They are not competing services. They are two layers of the same governance stack — and the relationship between them is one of the most consistently misunderstood topics in enterprise AWS architecture. >_ Architect’s Brief Architecture overview before you dive in…
-
No One Database Rules Them All: A 2025 Guide to Modern Data Stores
Modern systems are no longer built on a single database. High‑scale, cloud‑native applications combine multiple database types, each optimized for a specific access pattern, latency requirement, or workload. Choosing the right database is now an architectural decision that directly impacts cost, performance, resilience, and developer velocity. Below is a practical, cloud‑focused guide to the most…
-
Azure Landing Zone: The 48-Hour Setup Guide (2026)
This Azure Landing Zone guide exists because most Azure environments are built wrong from day one — and the cost of that mistake compounds for years. >_ Architect’s Brief Architecture overview before you dive in Generating brief… The default Azure onboarding experience points new users directly at resource creation. Spin up a VM. Deploy a…
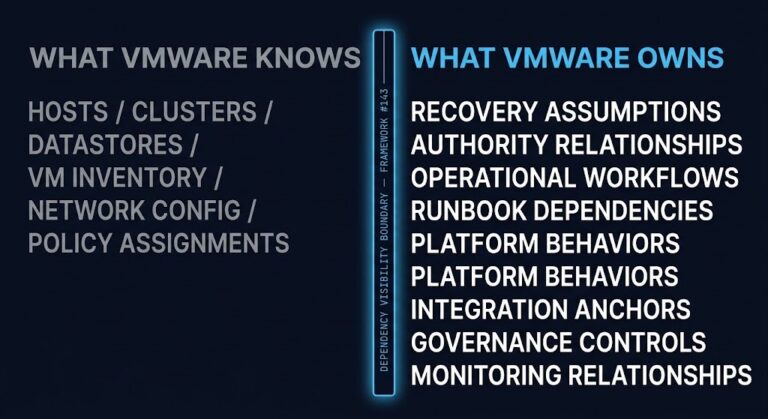
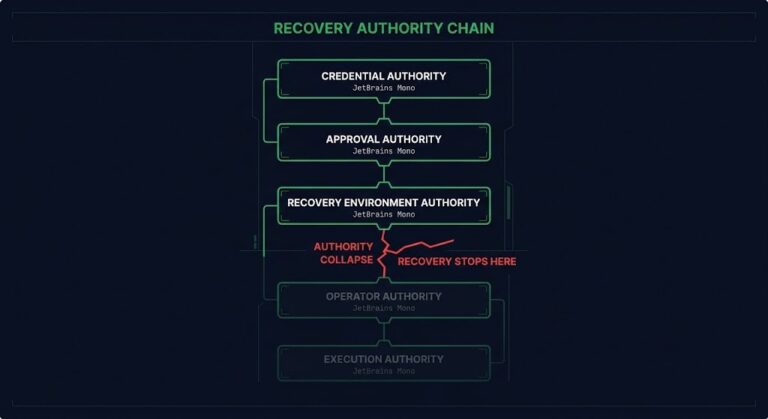
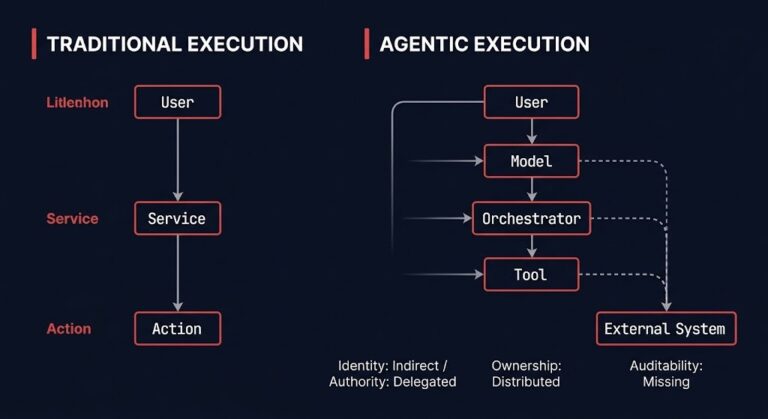
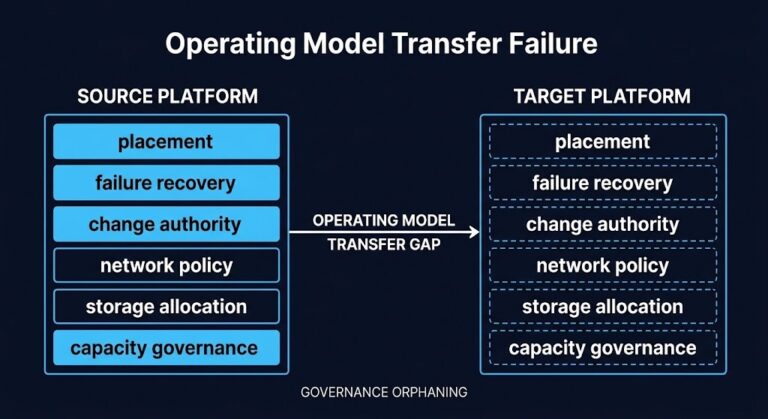


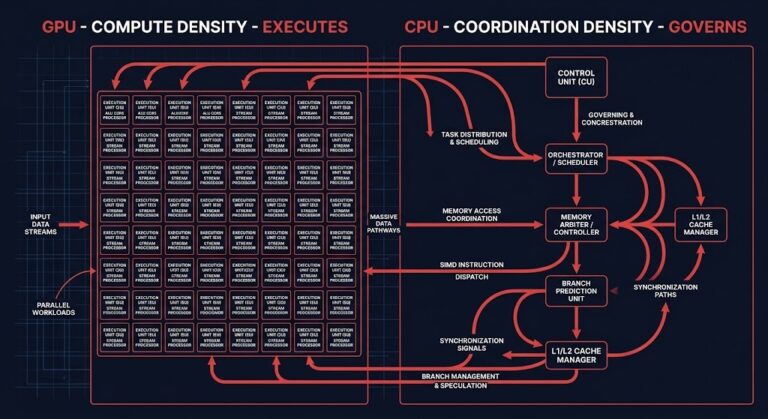

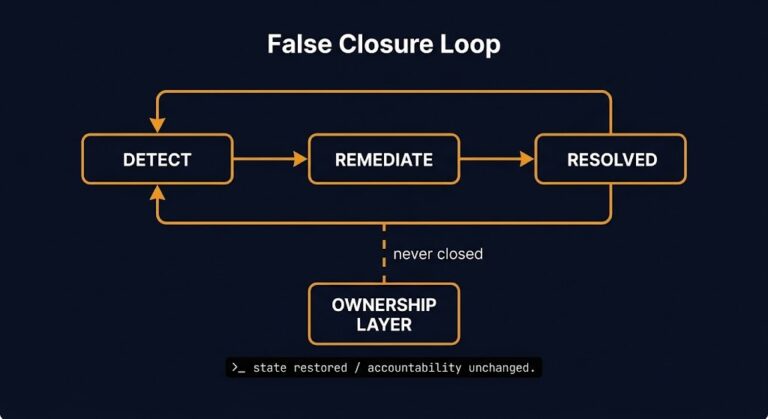
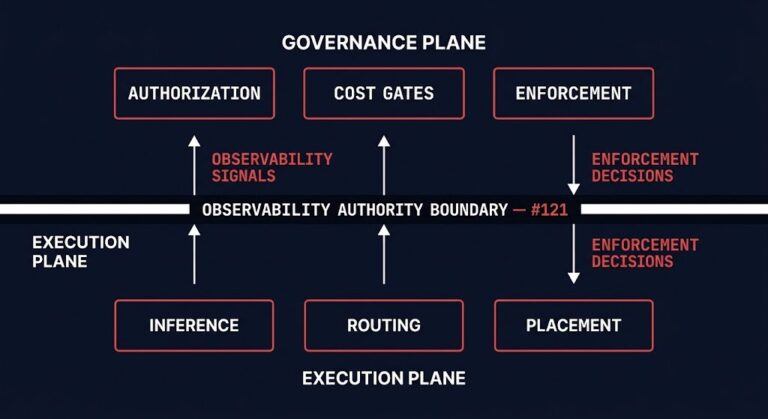
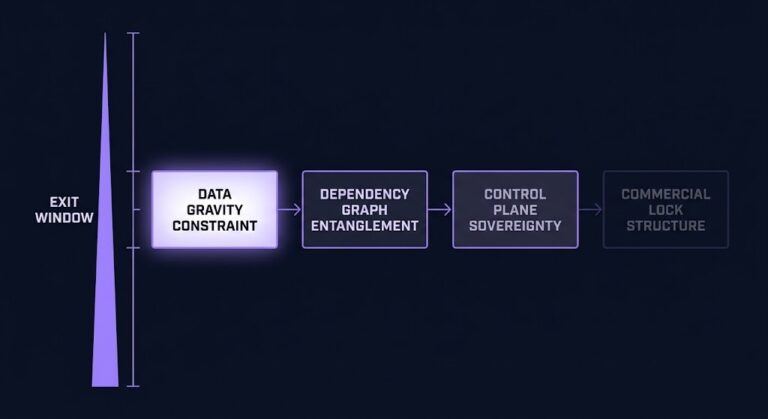
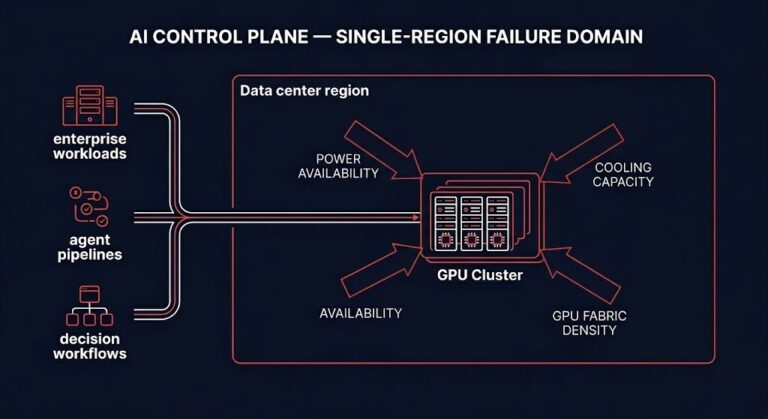
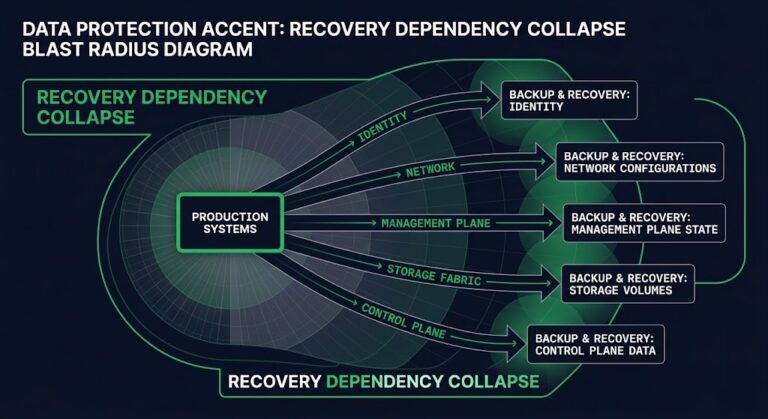
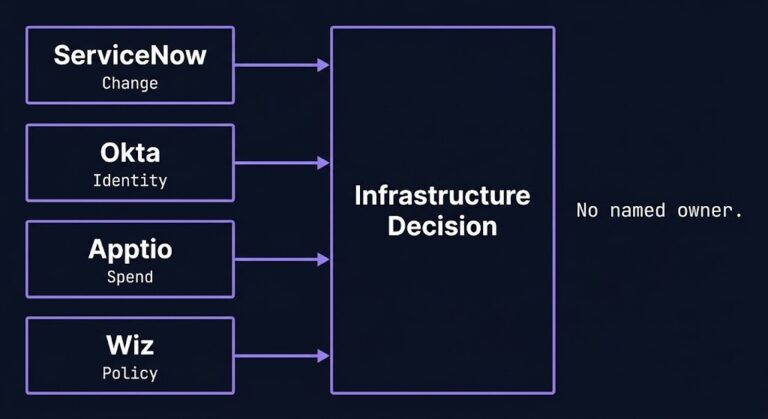

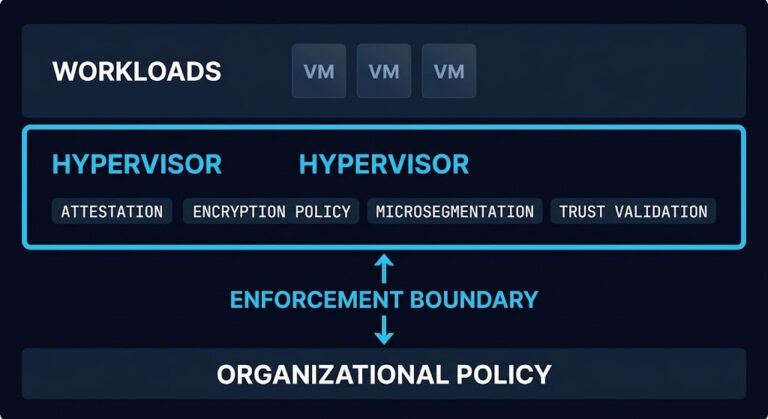
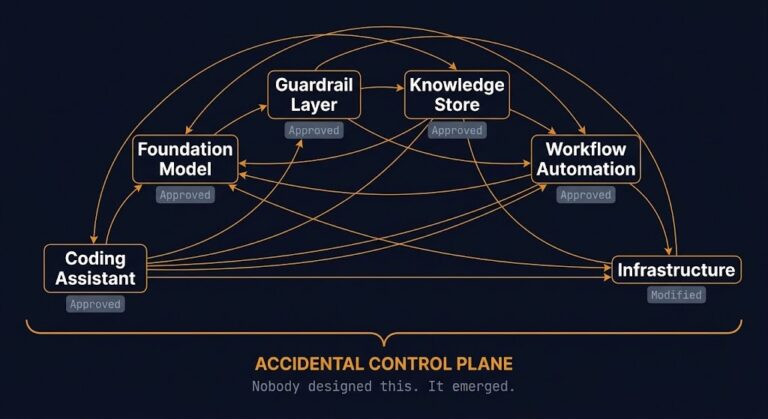

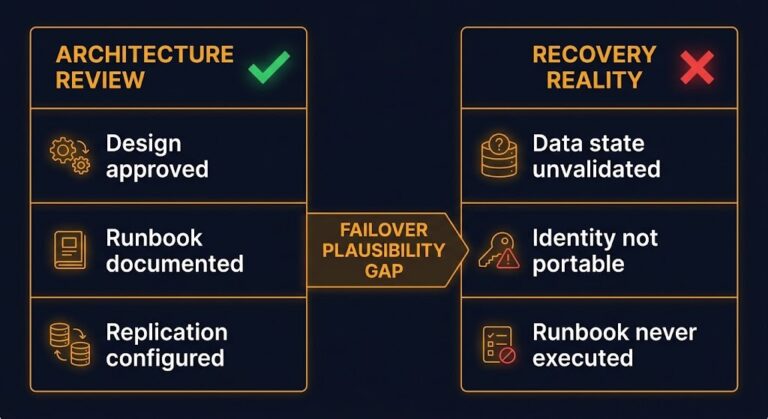
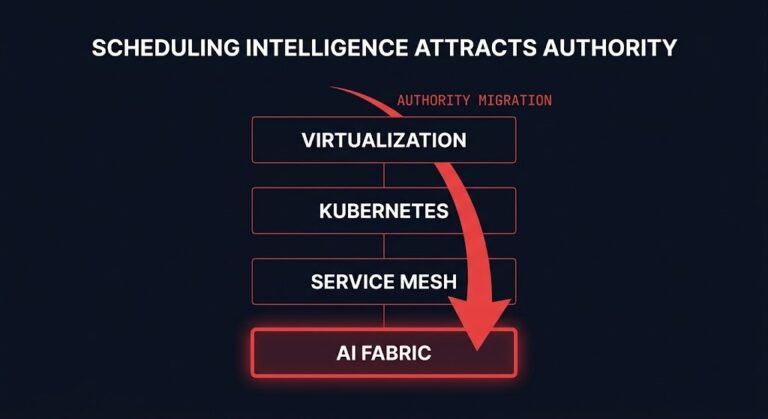
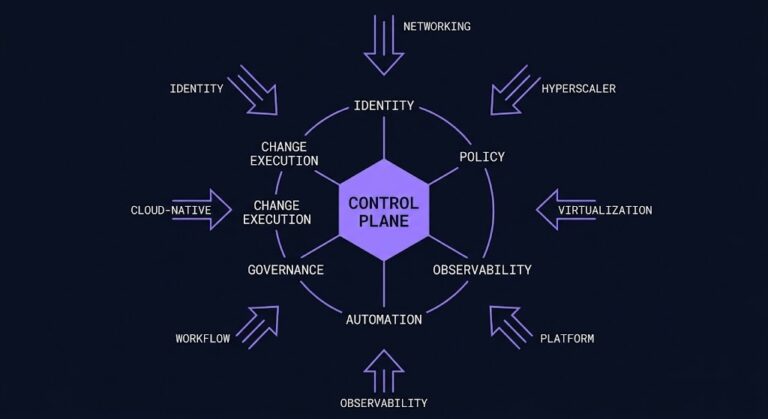
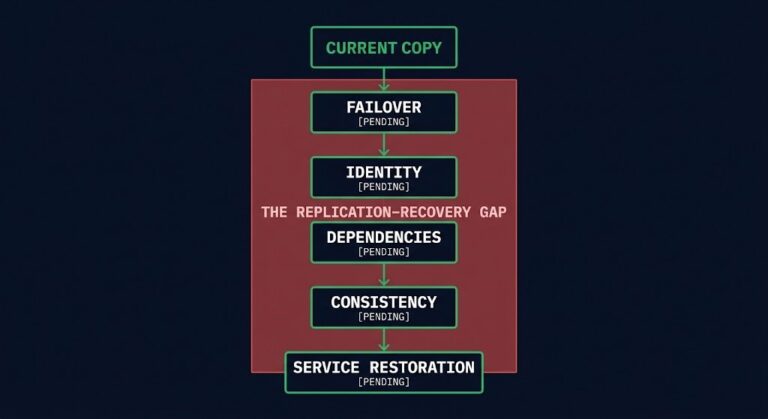
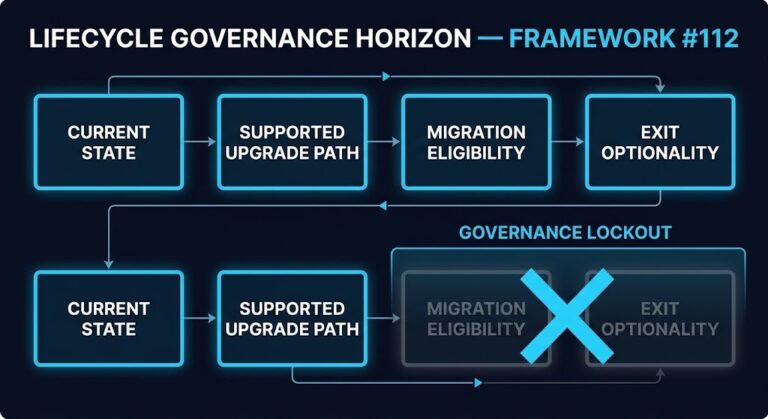

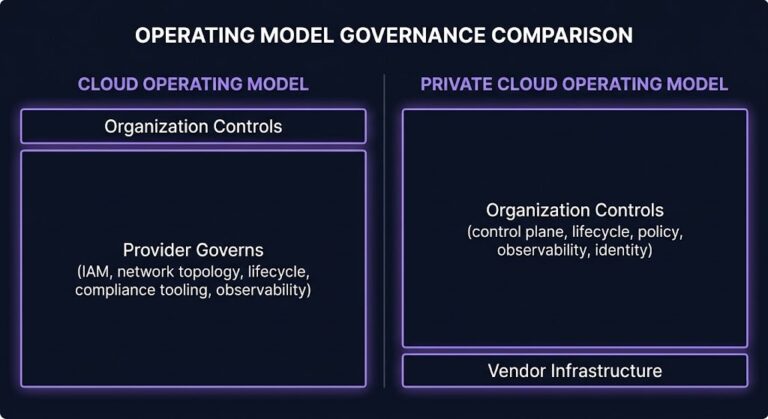
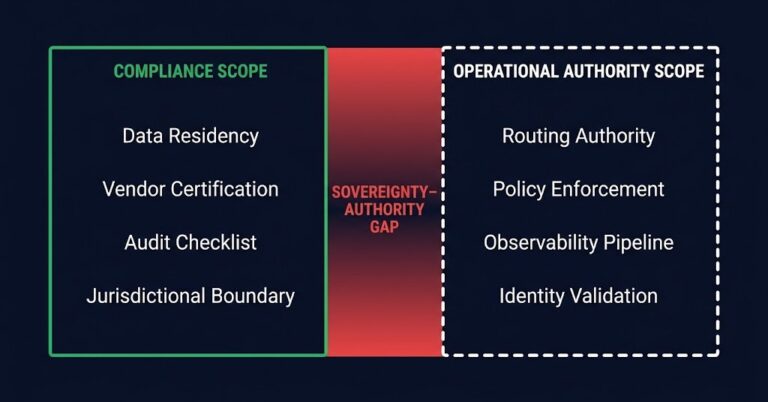
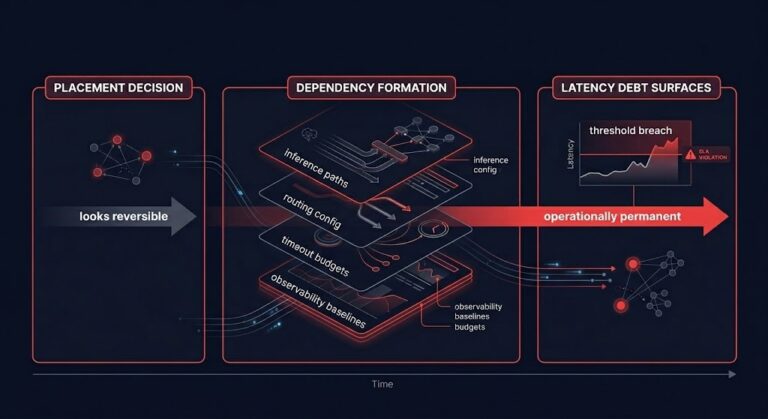
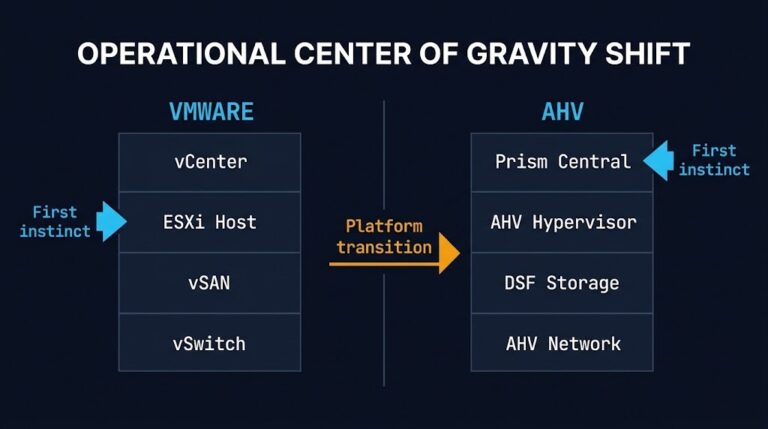

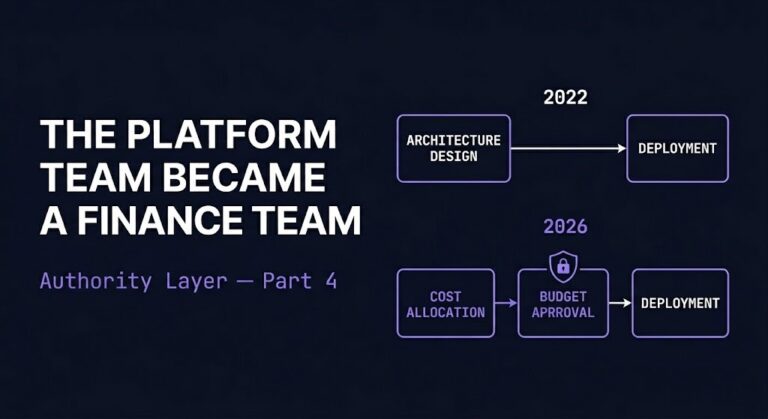
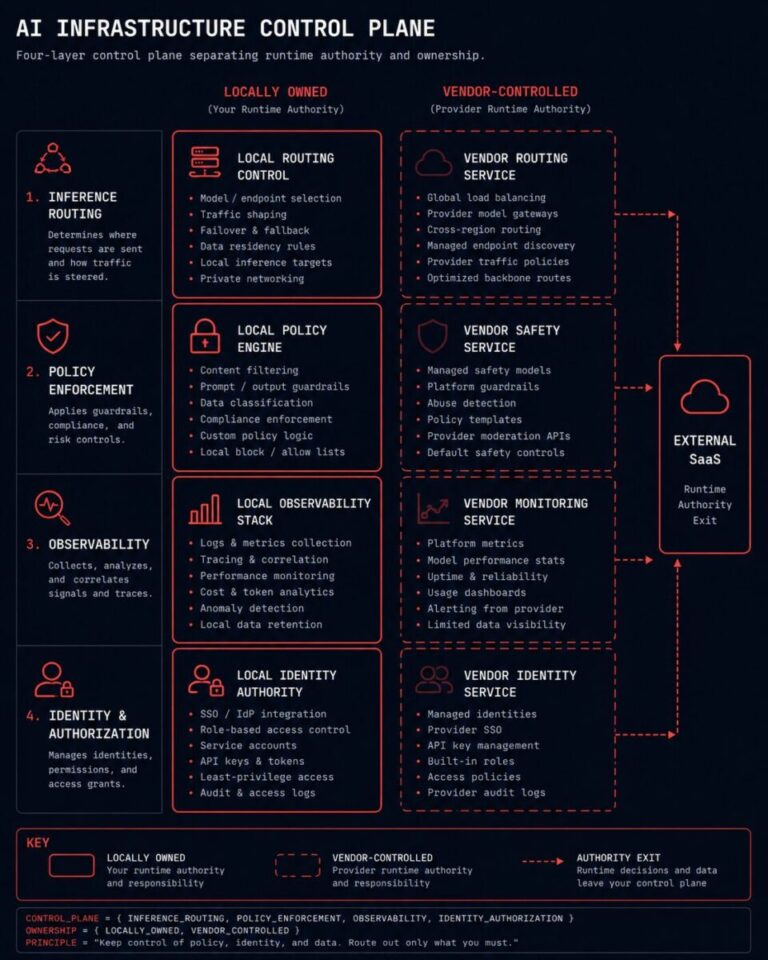
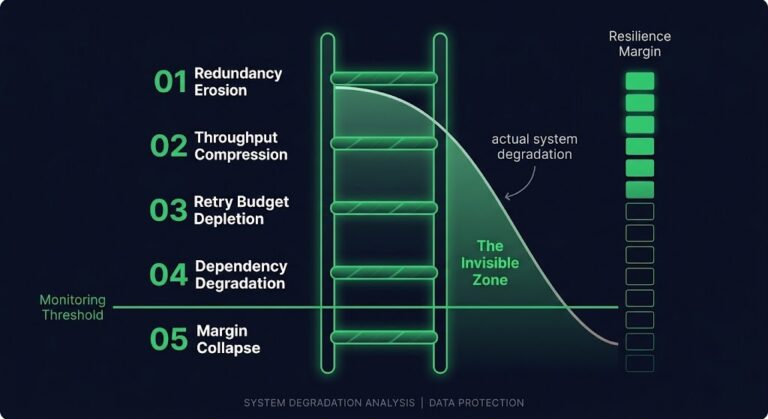
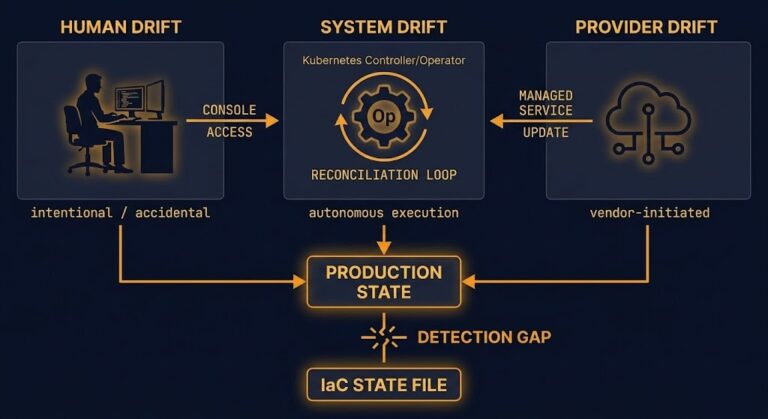
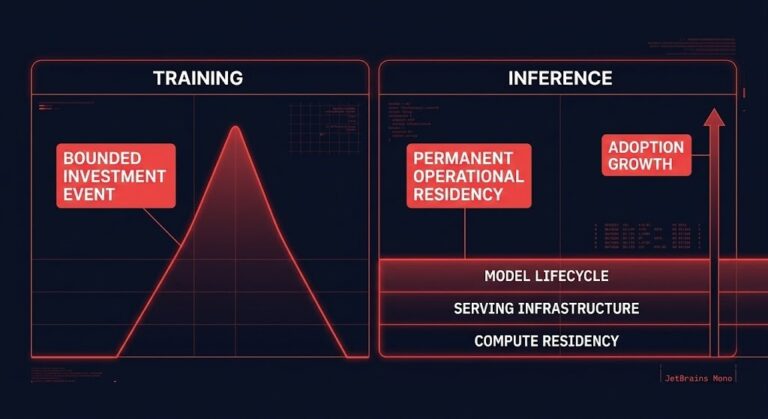
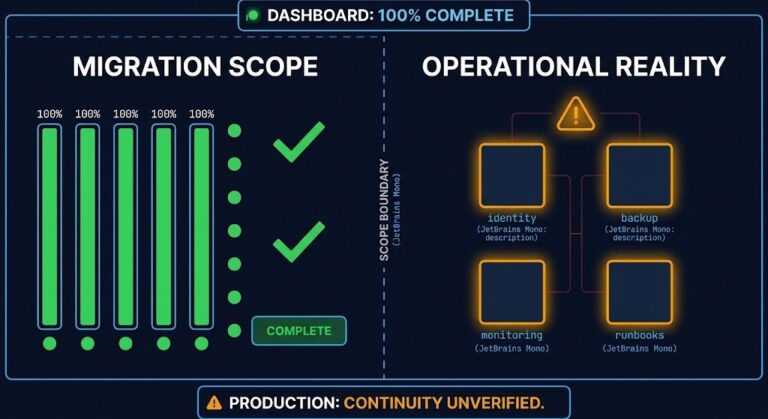

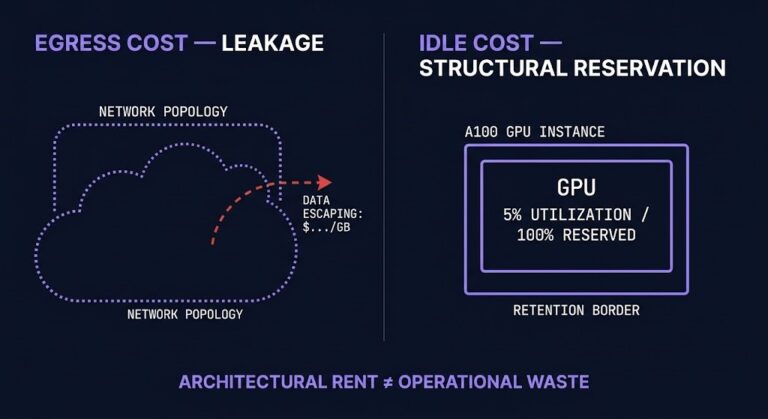
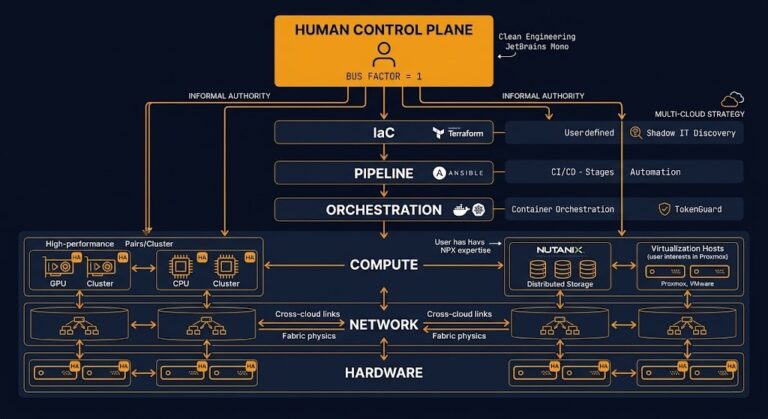
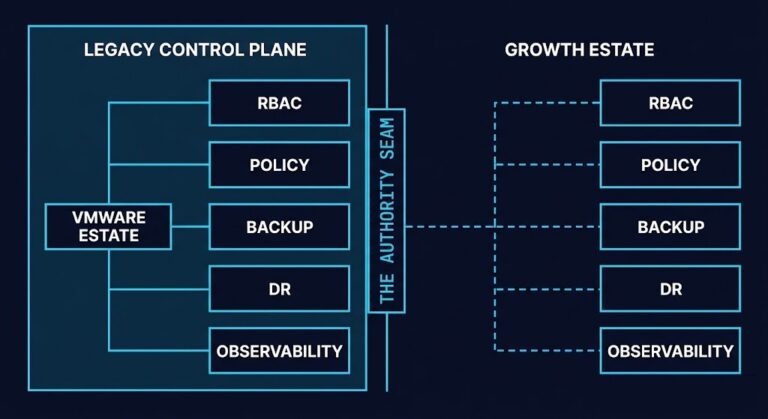
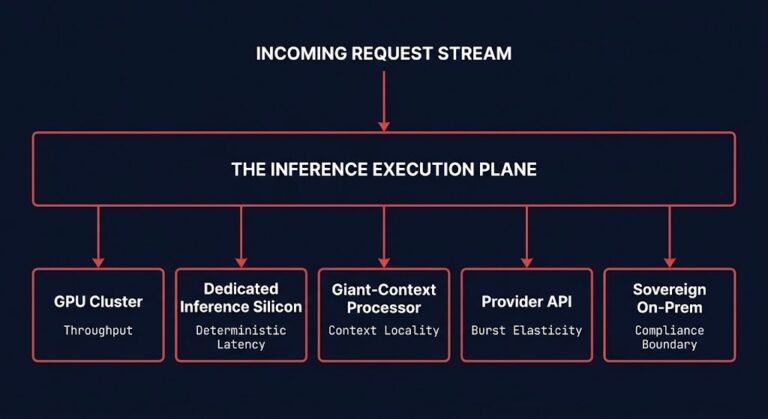
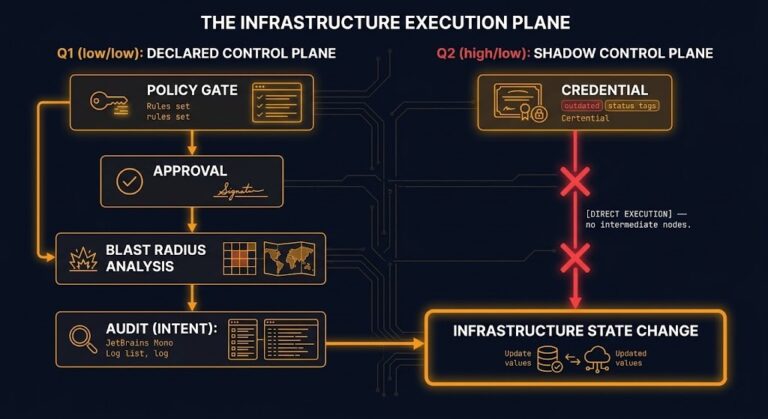
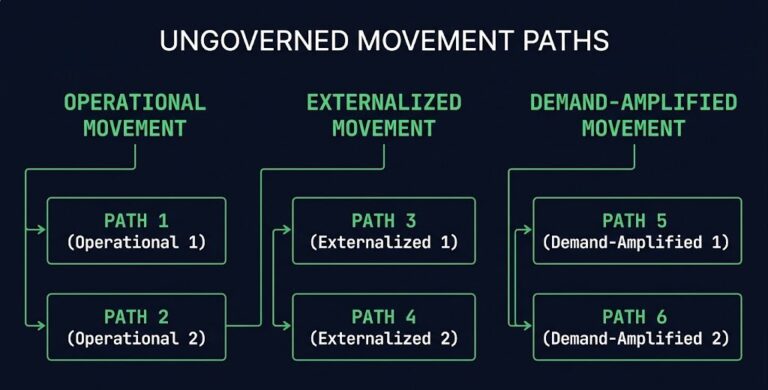
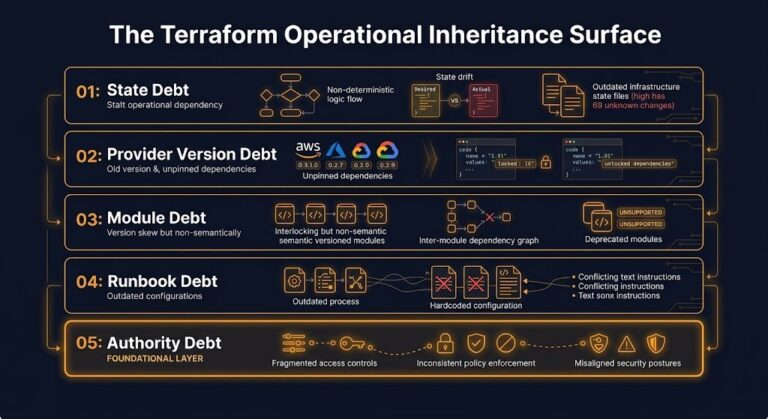
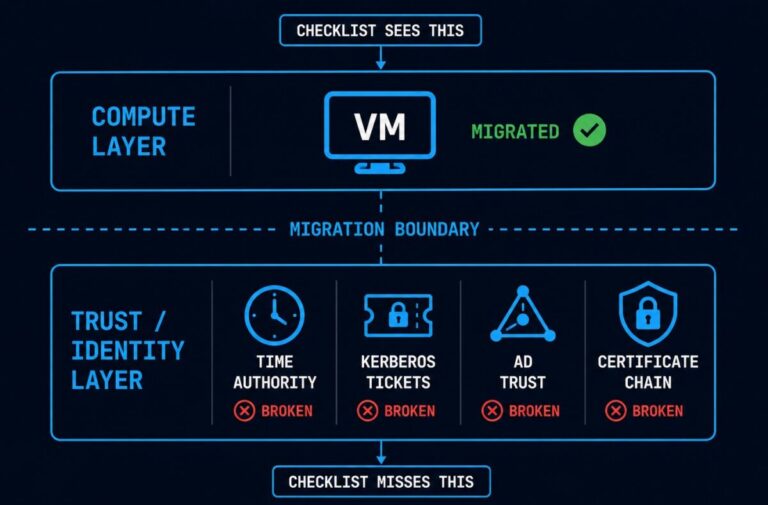
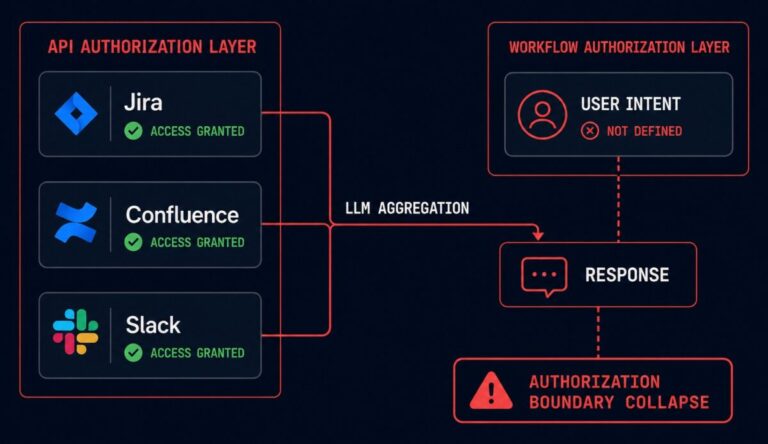
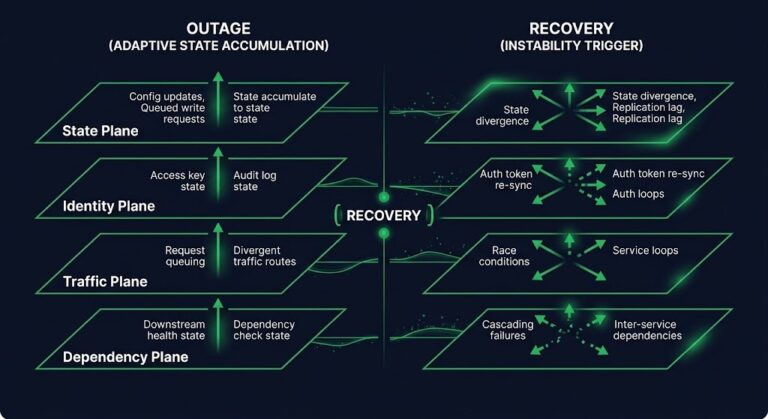
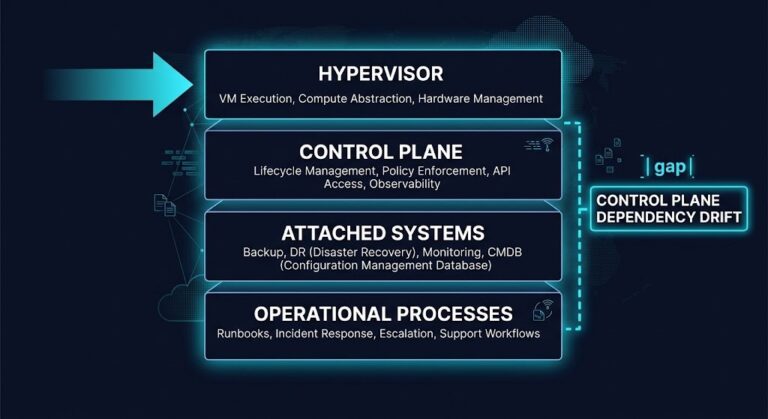
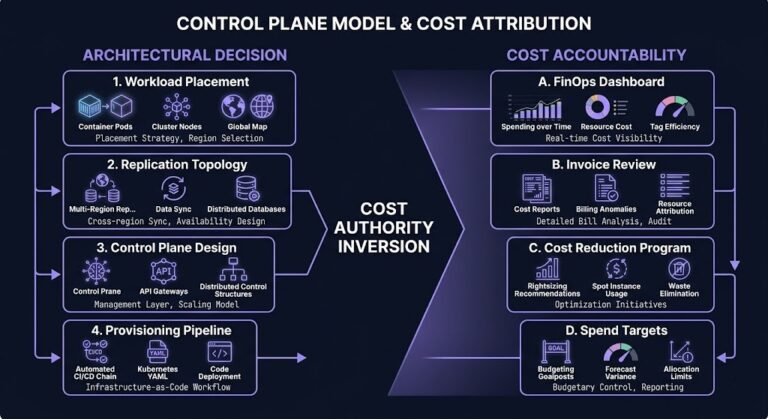
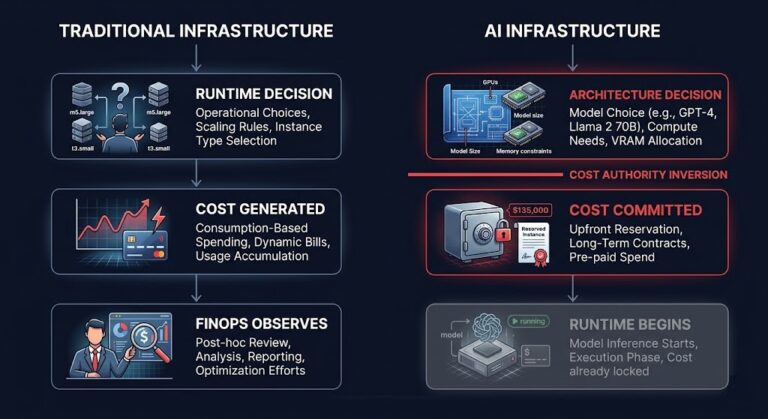
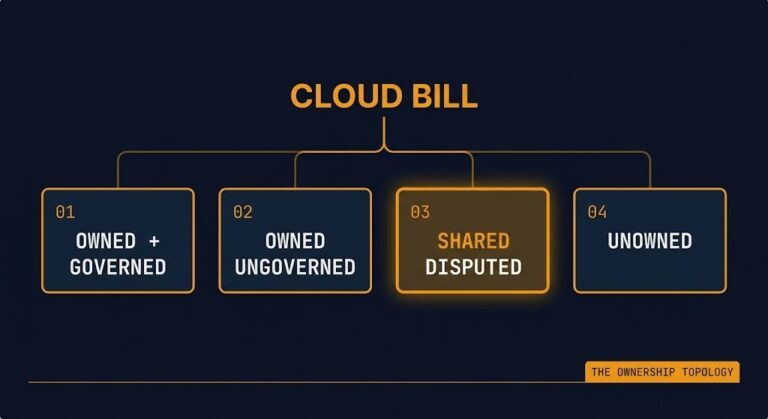
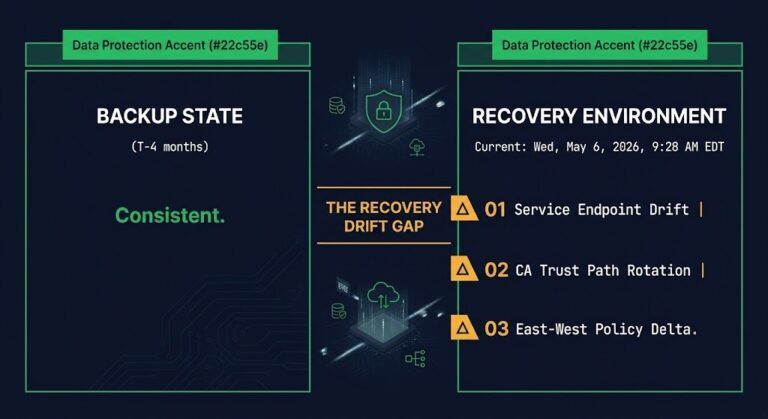

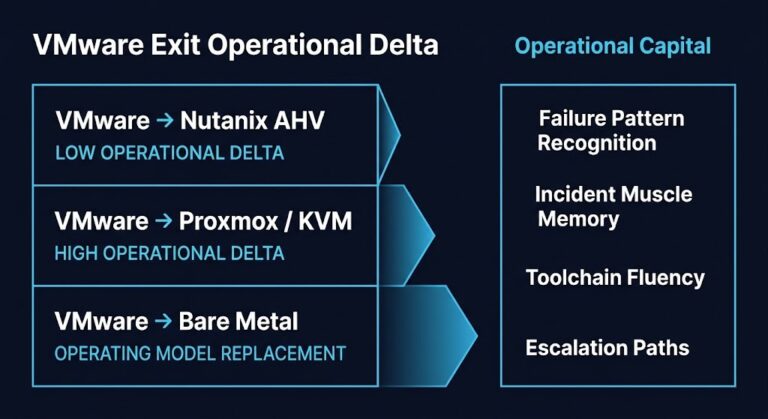







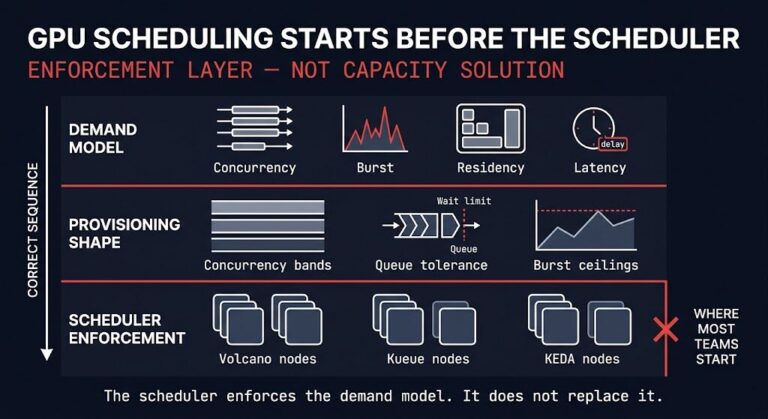
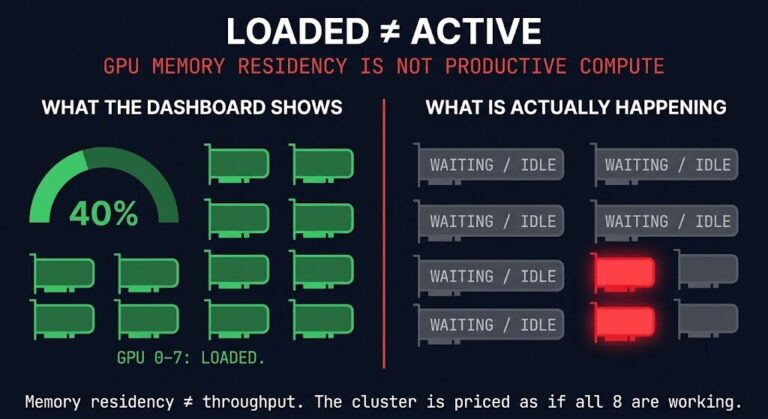

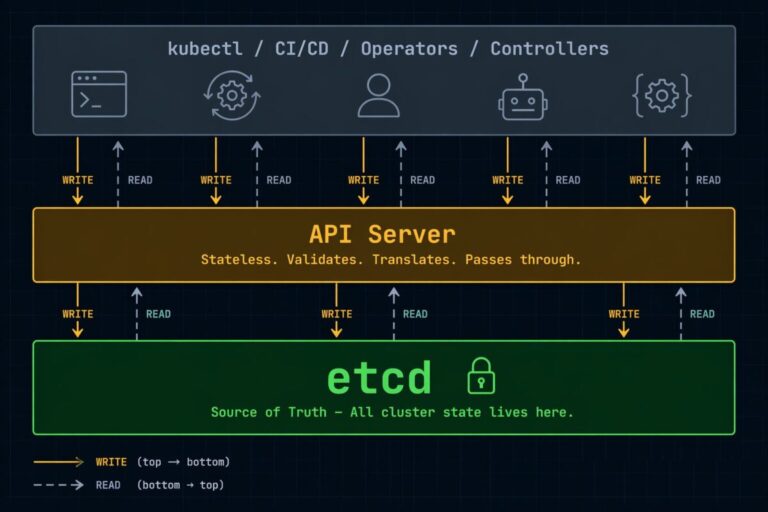

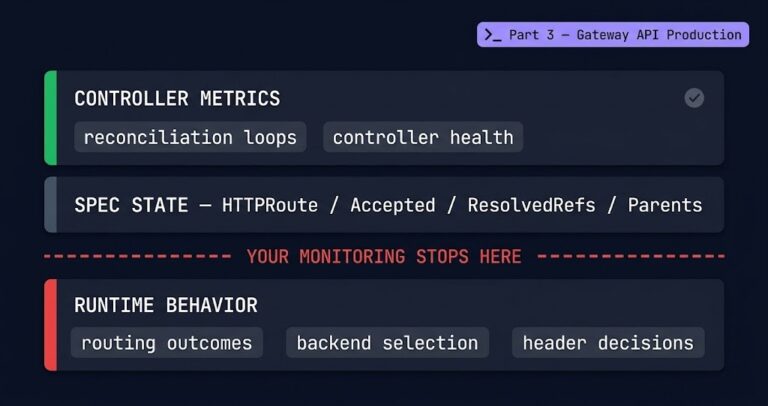
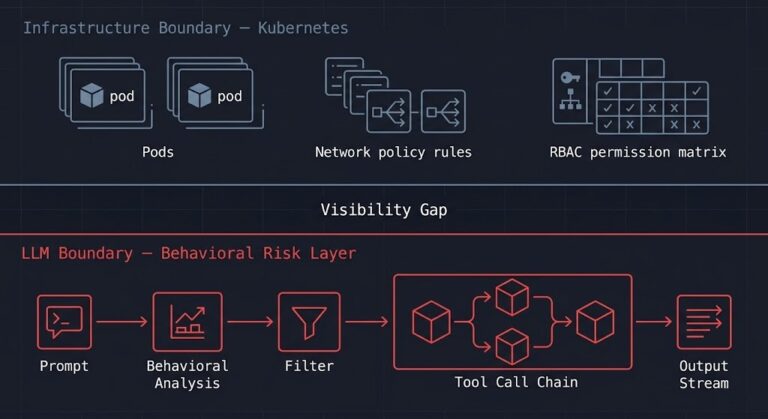

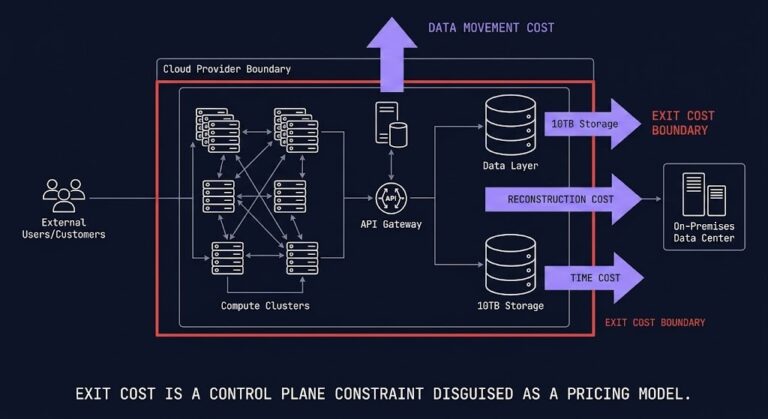
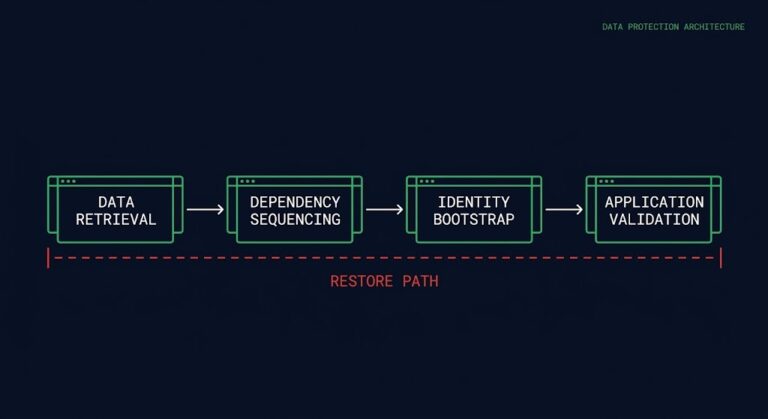
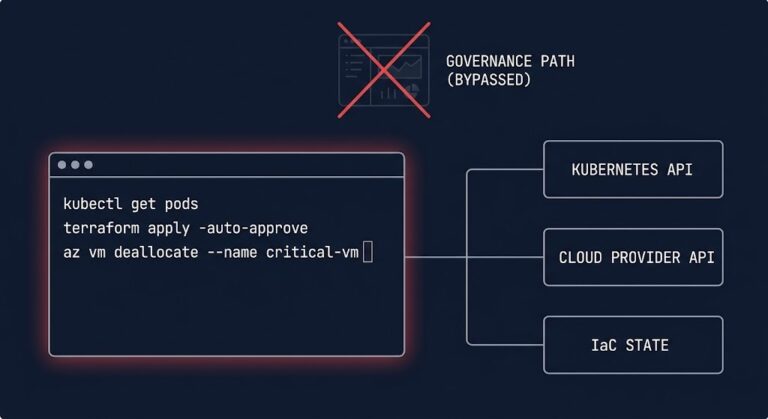
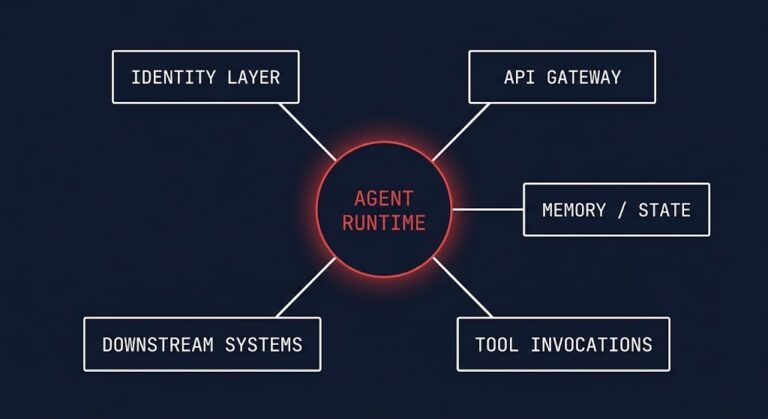

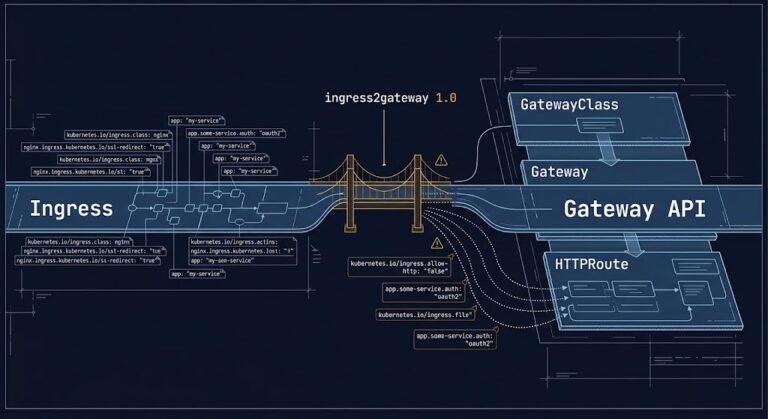
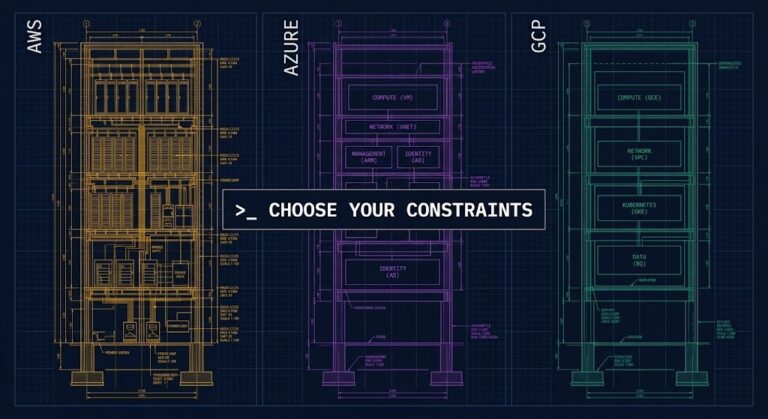

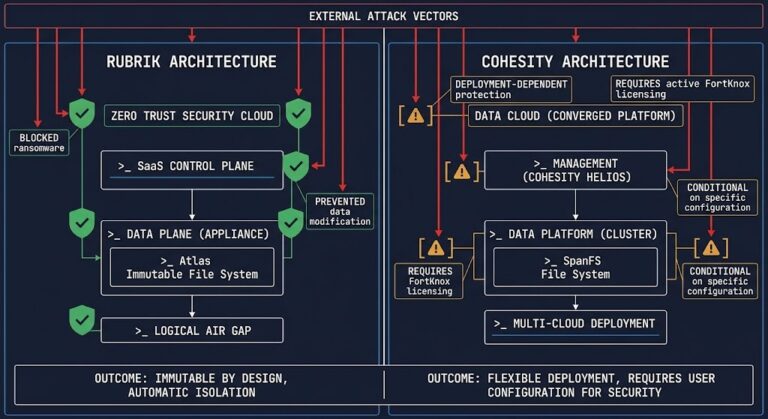



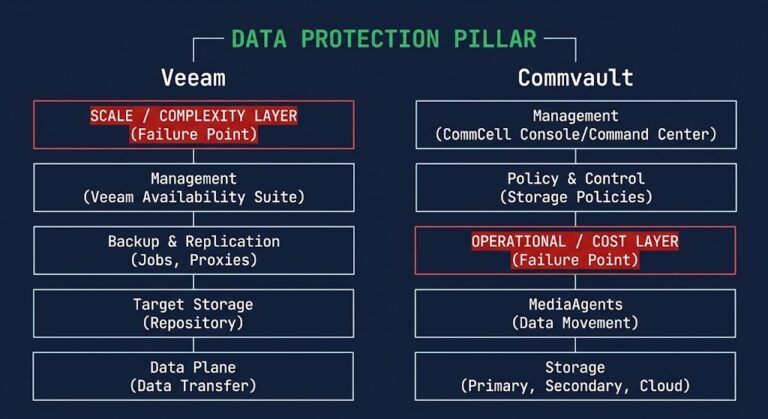


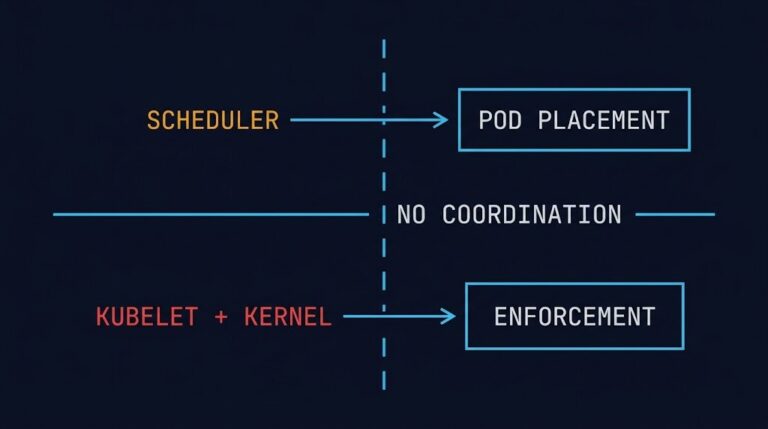
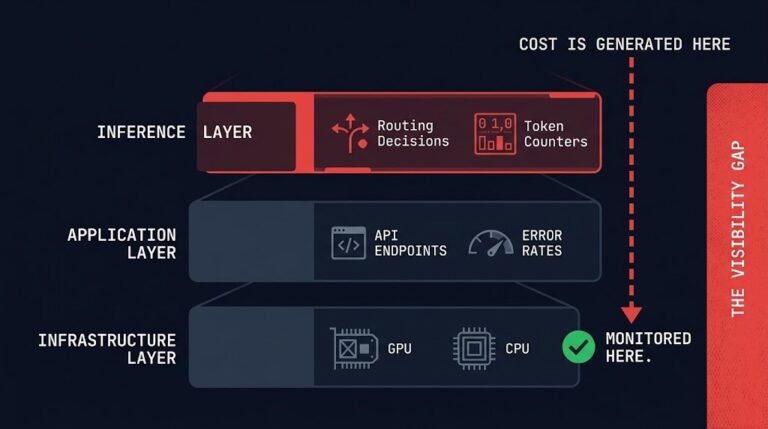

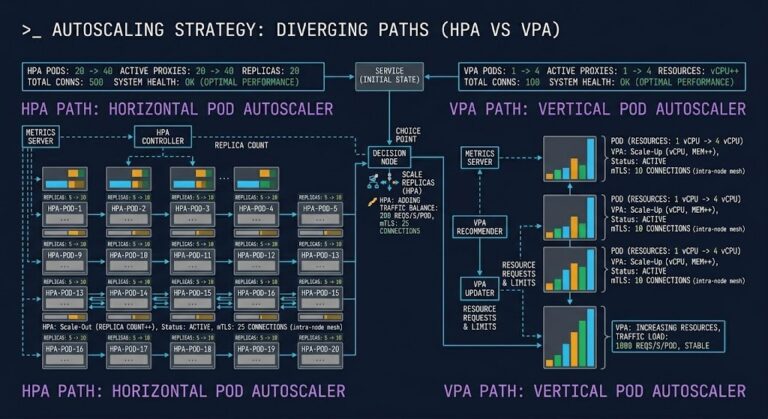
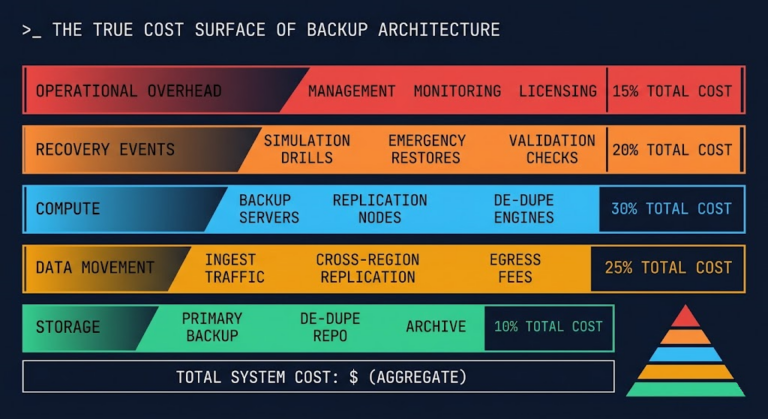

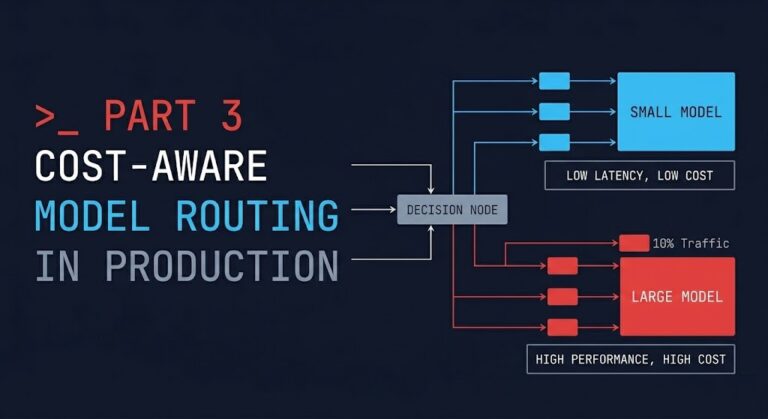
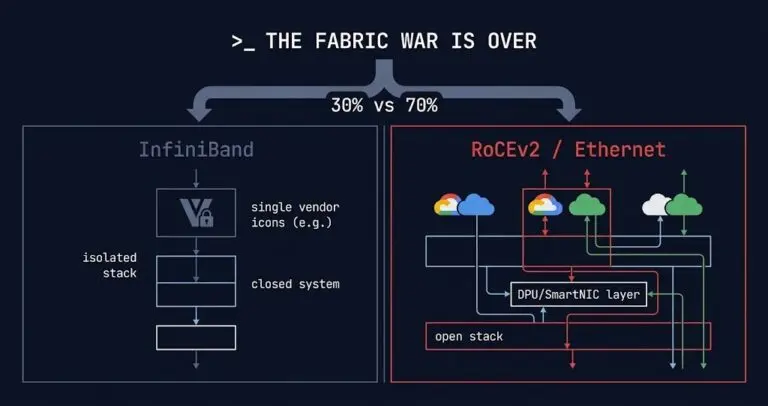
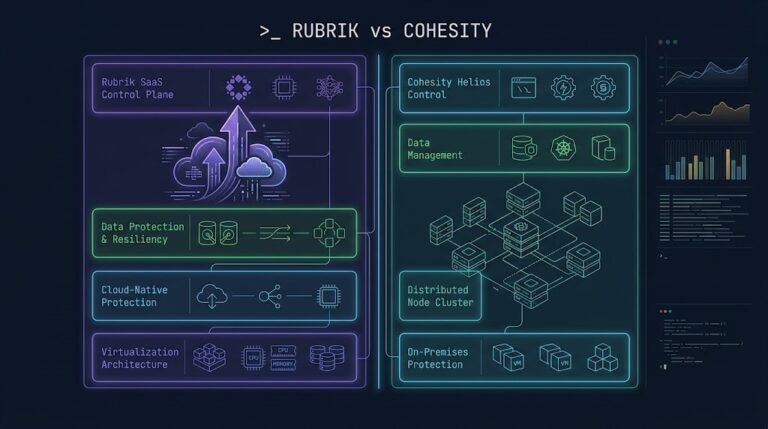
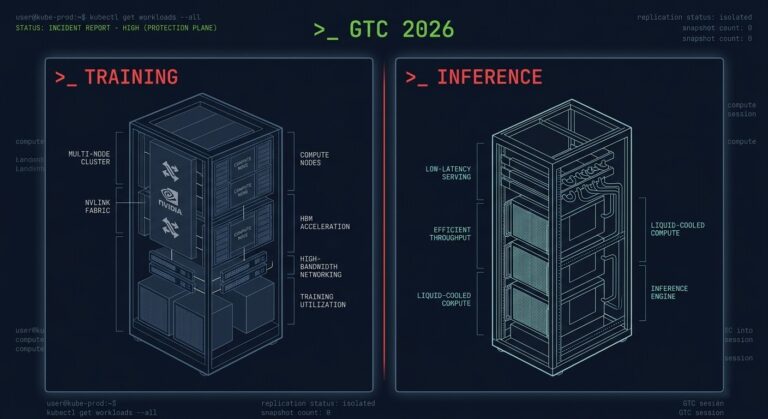
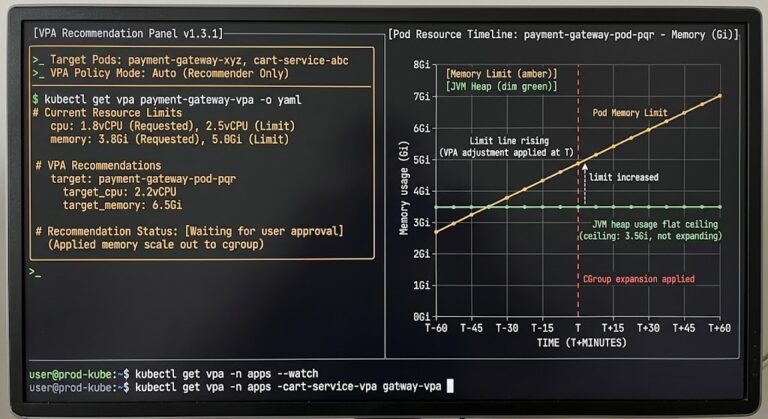

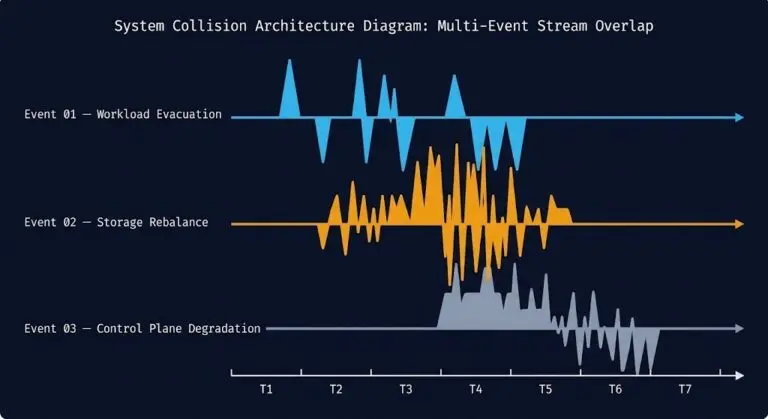
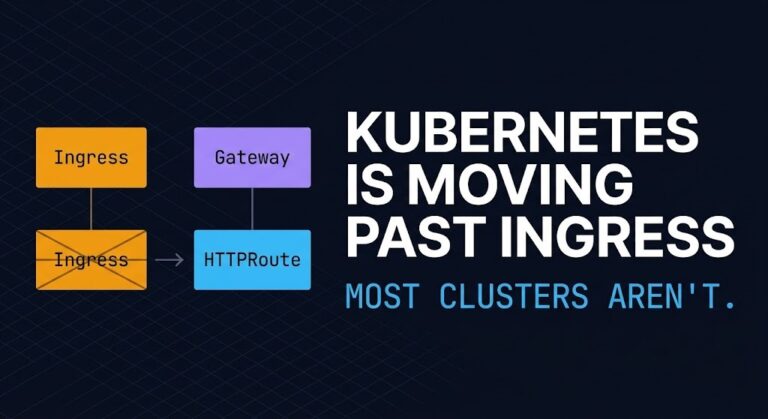
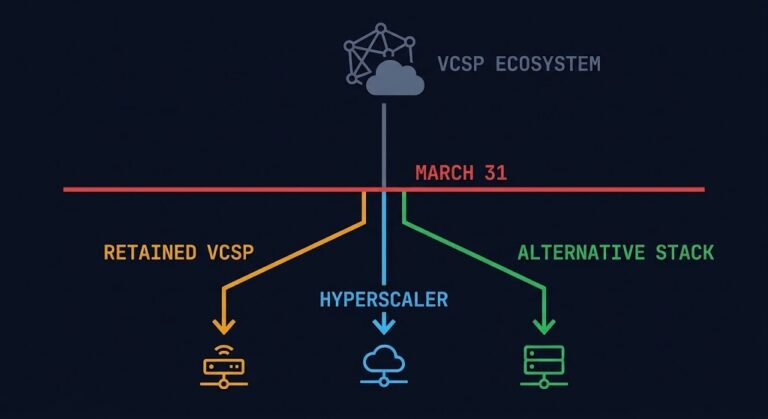
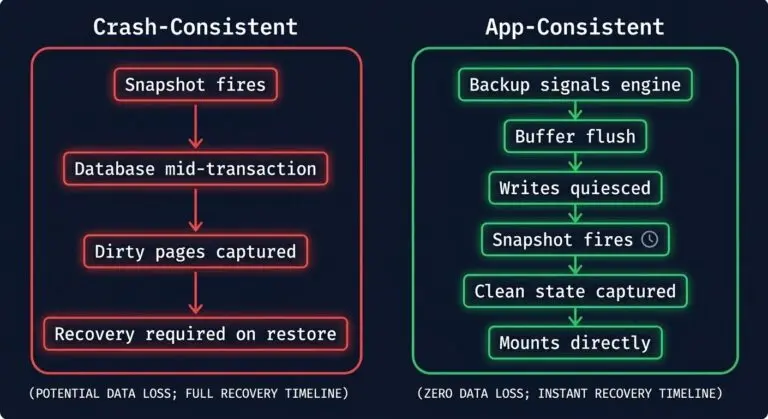
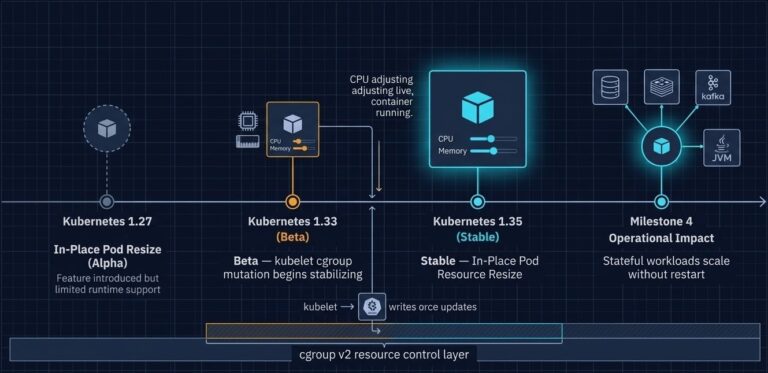
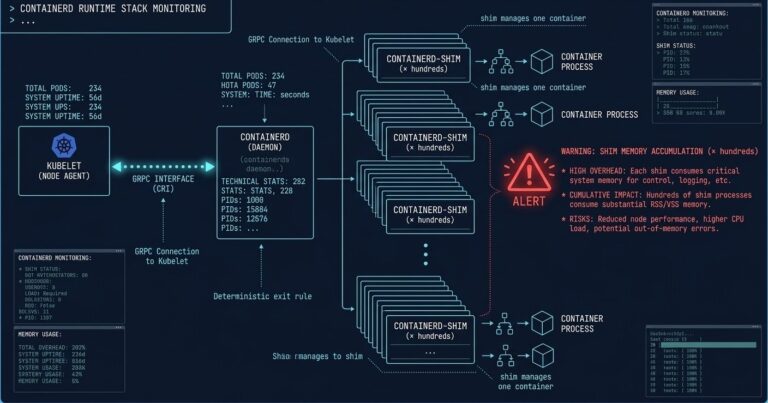
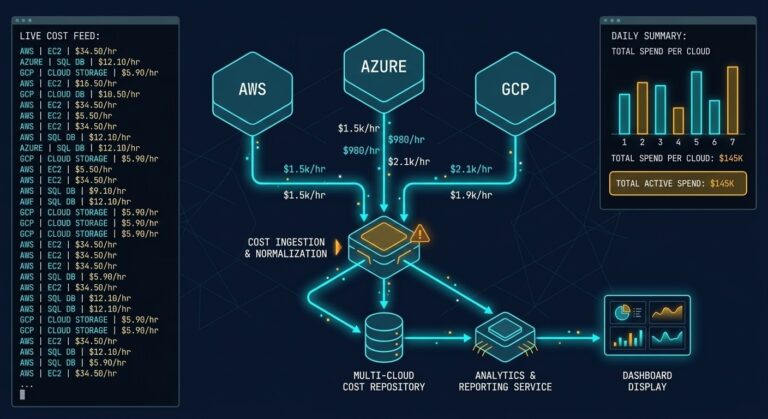
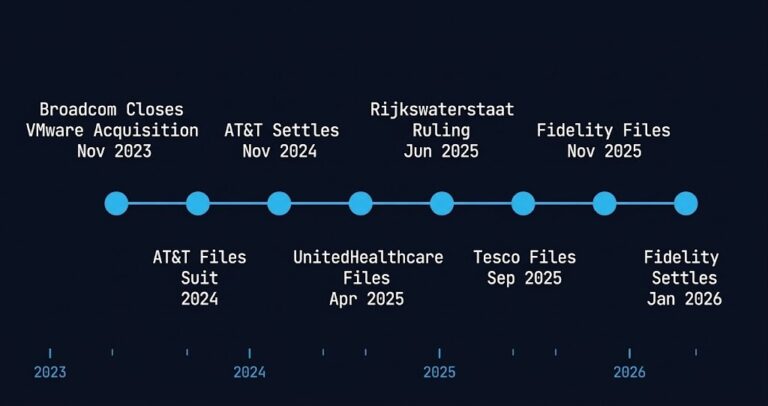
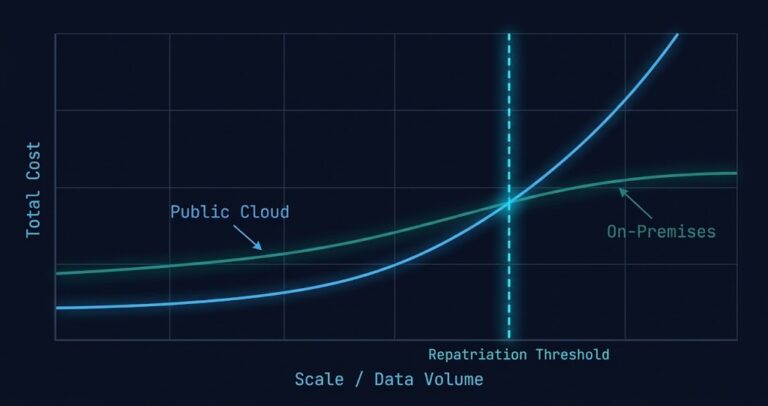
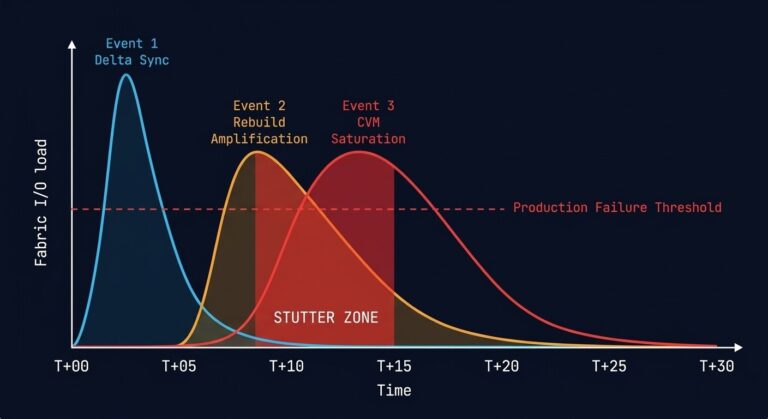
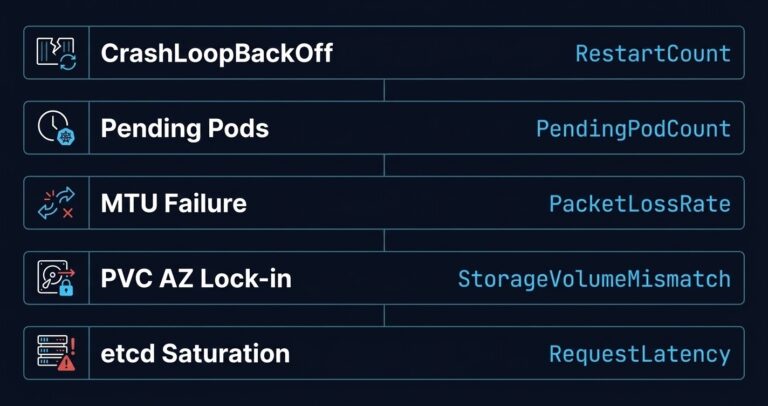
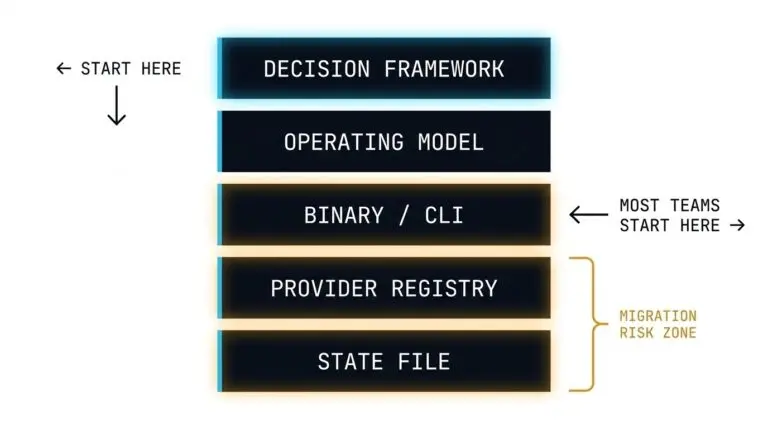
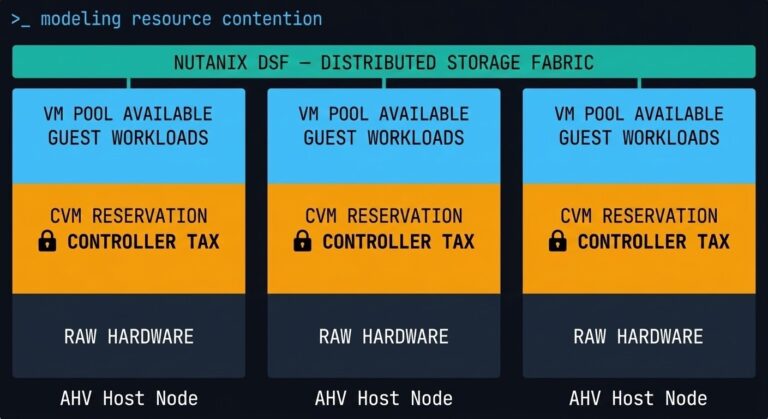
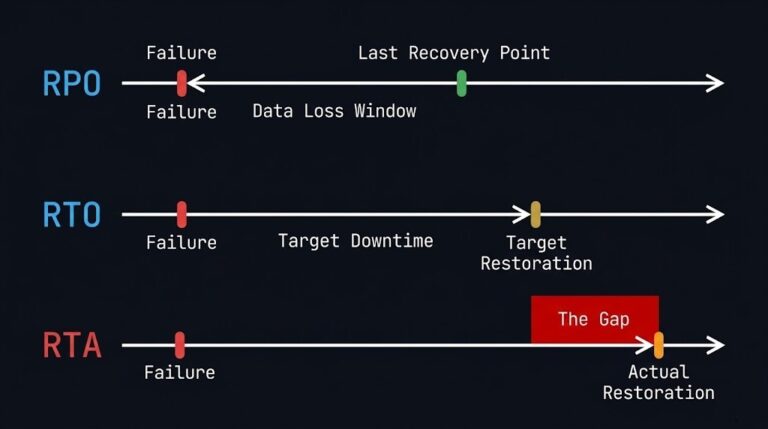
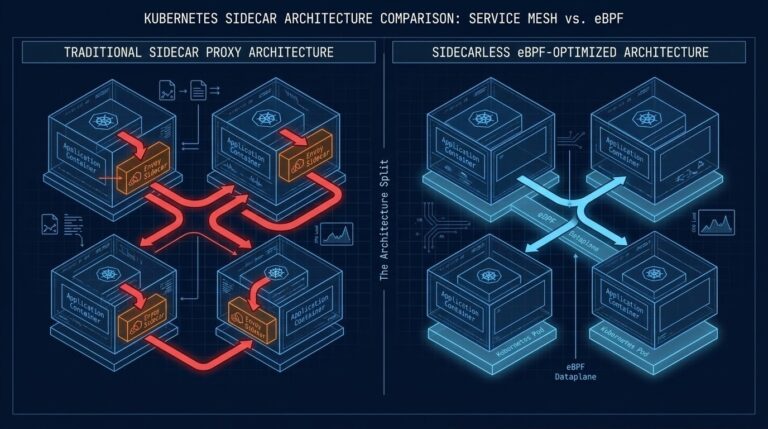
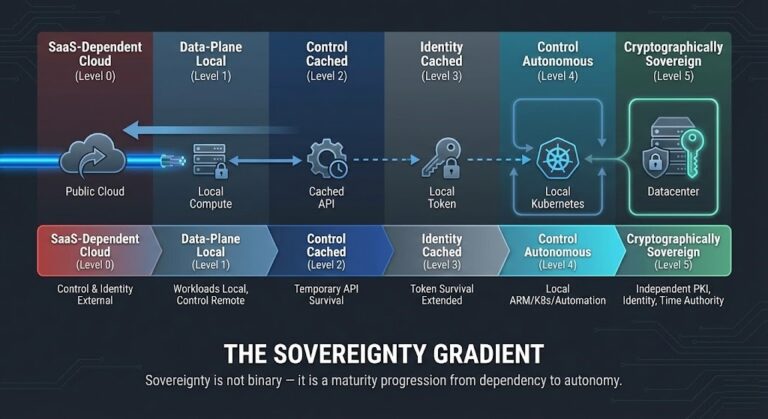
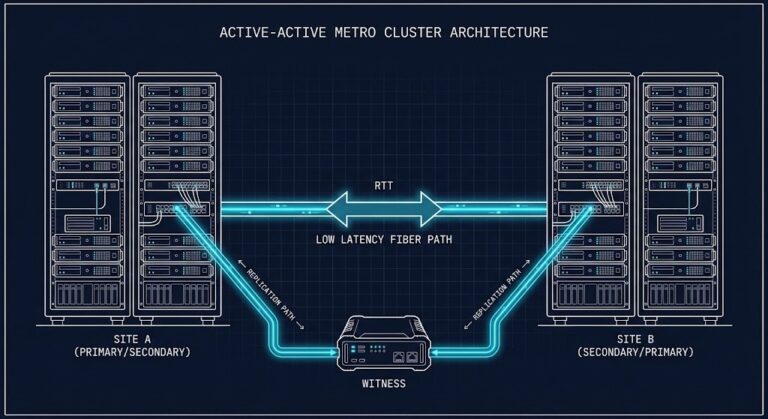
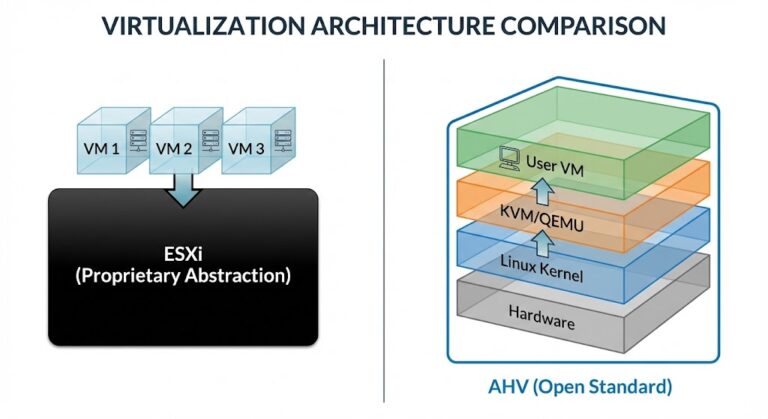
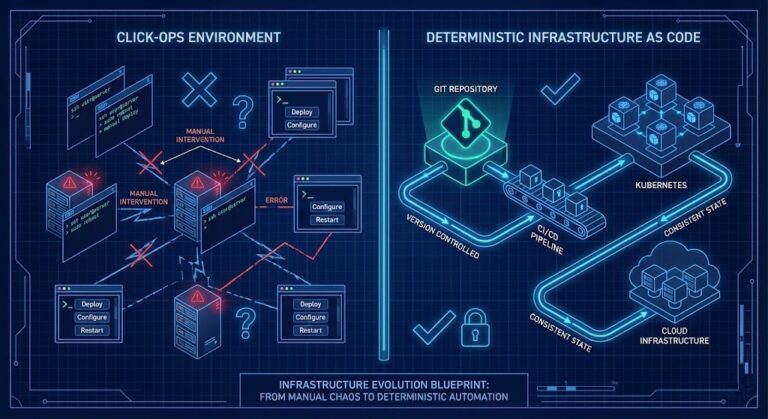
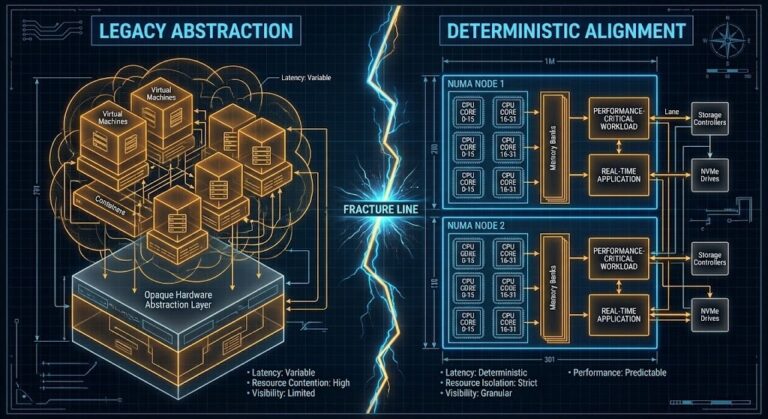
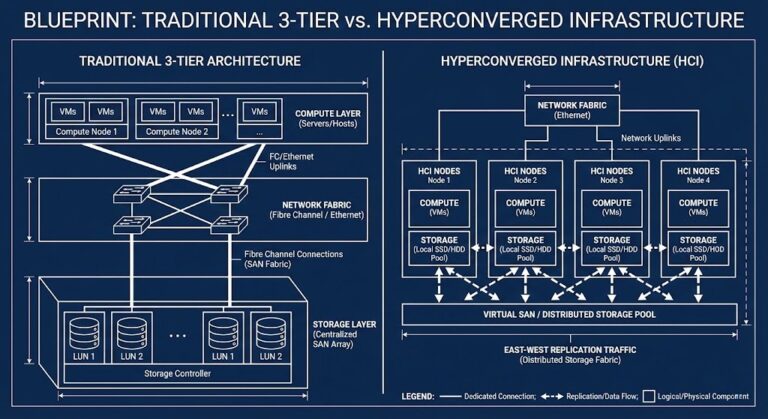
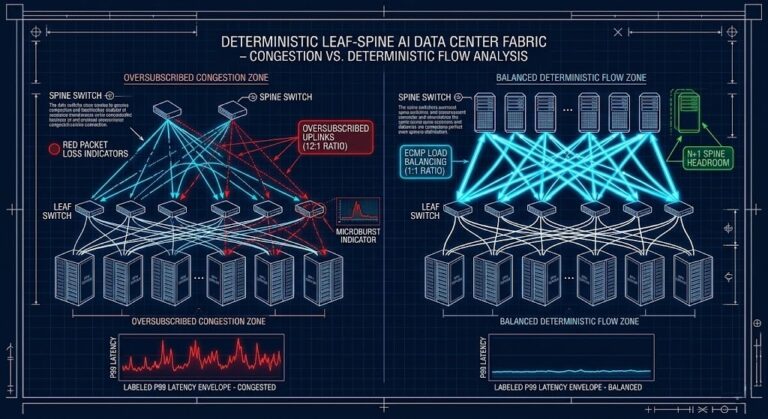
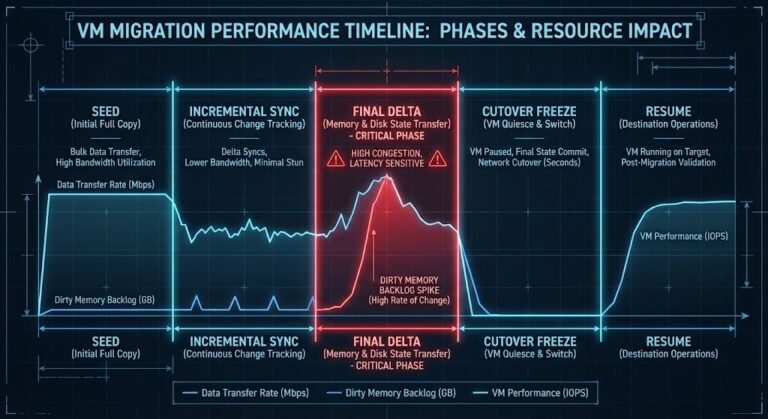
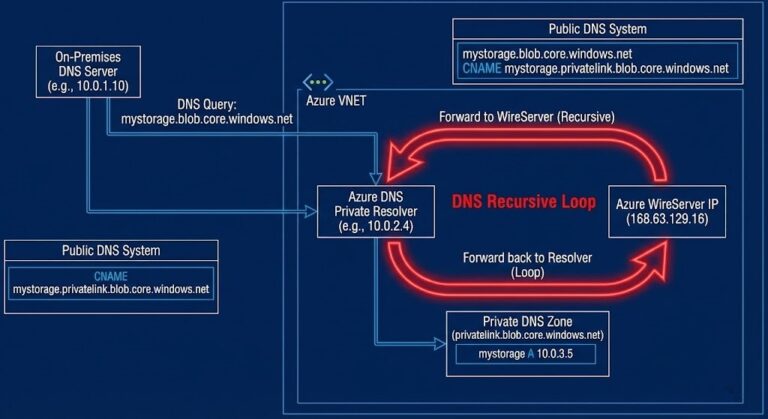
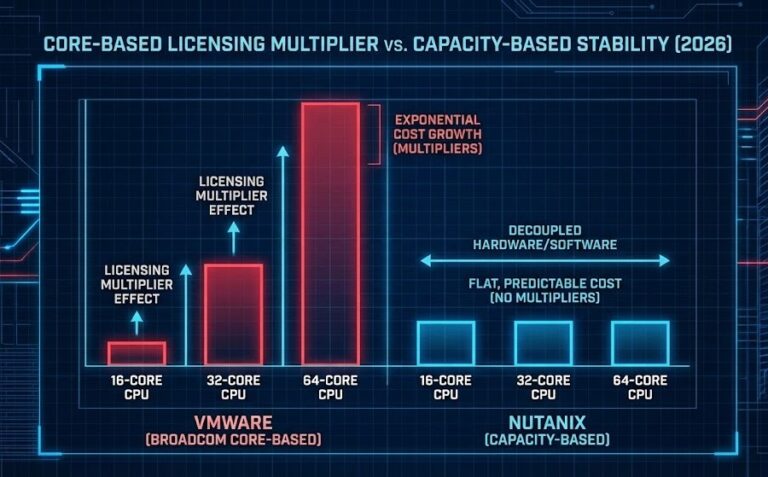
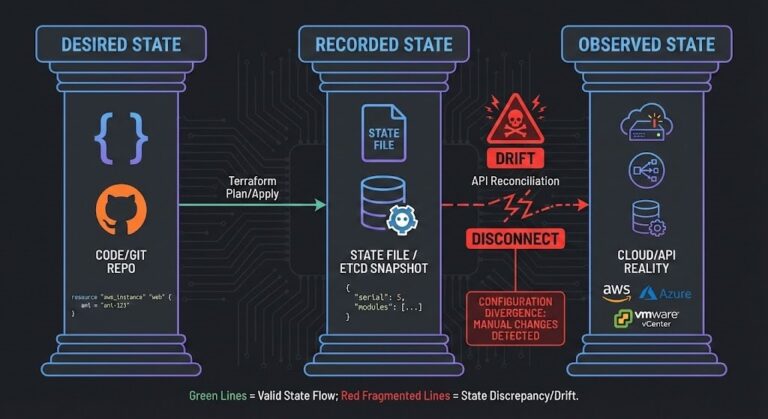

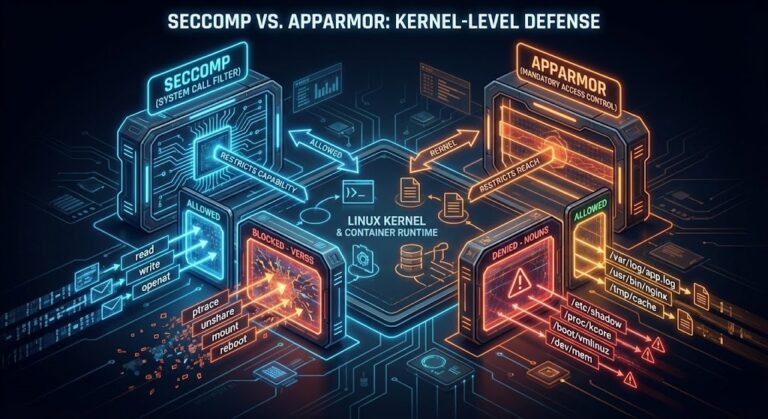
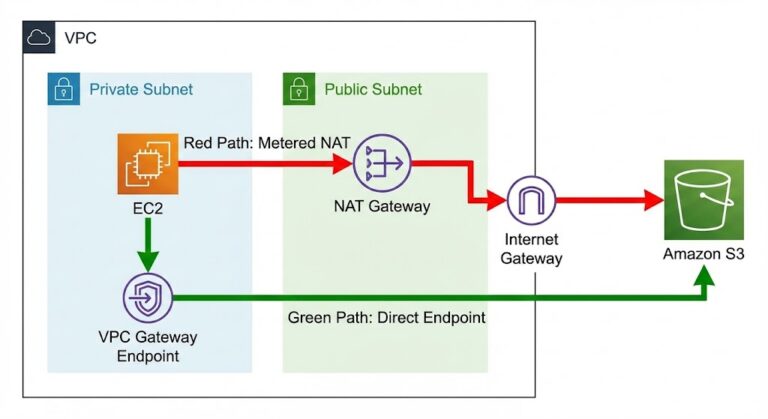
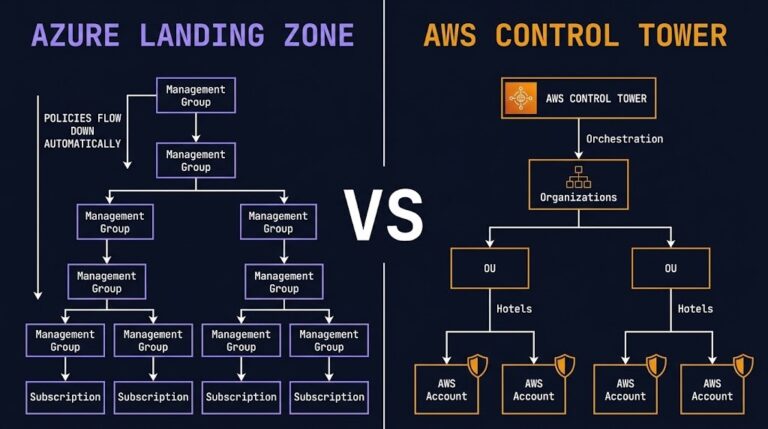
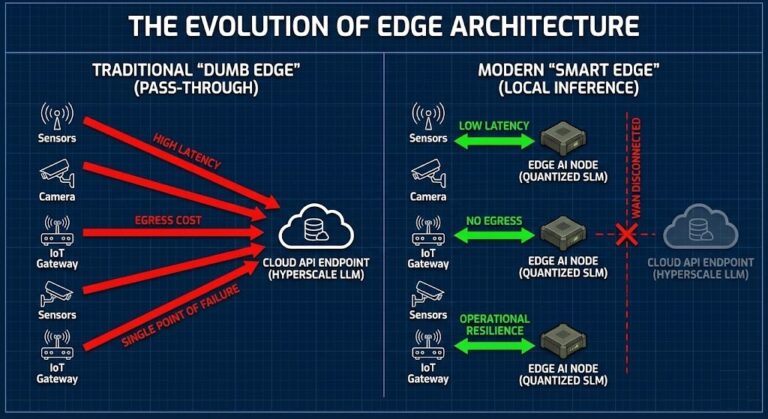
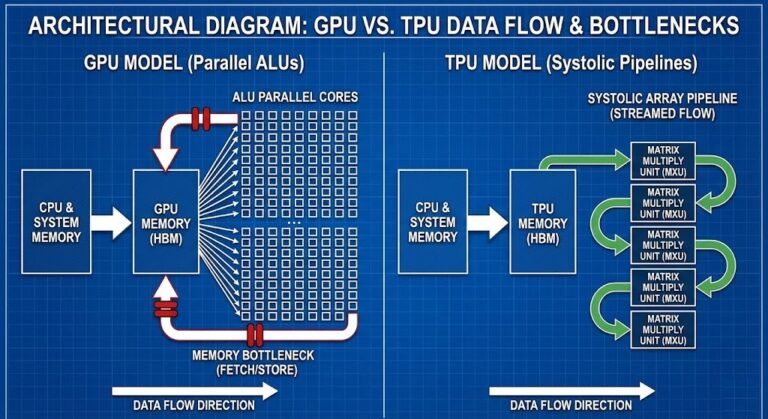
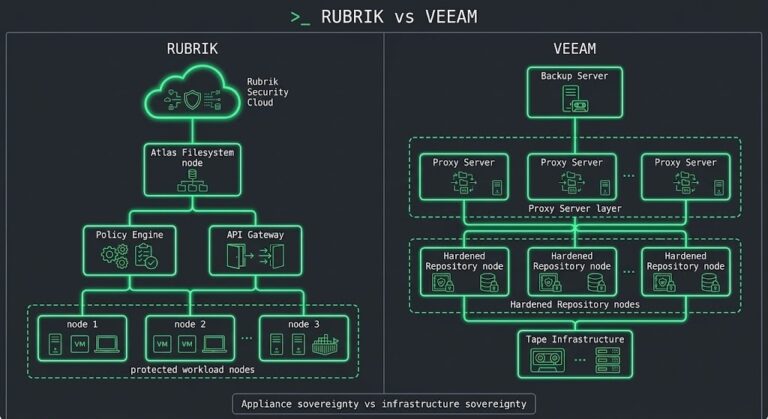
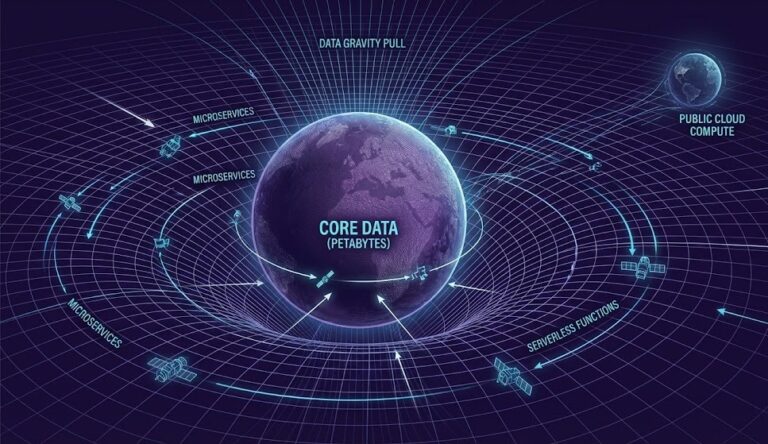
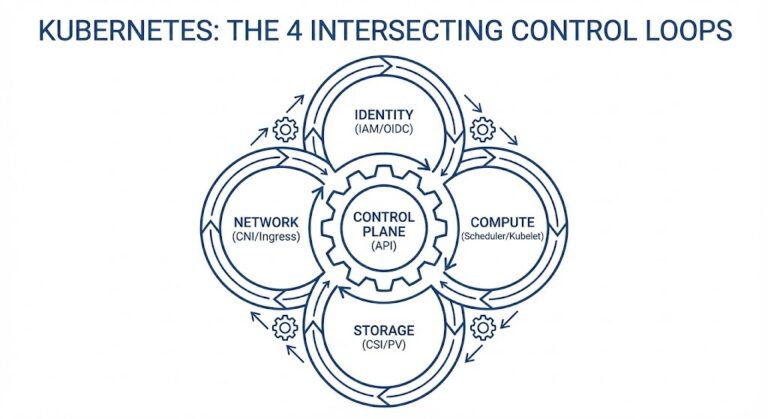










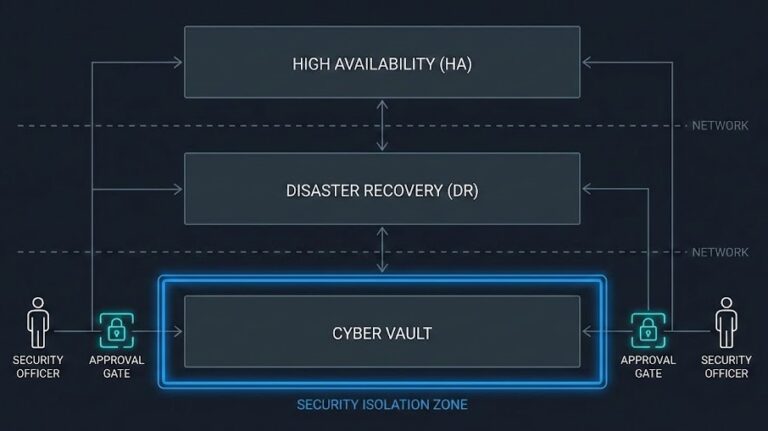

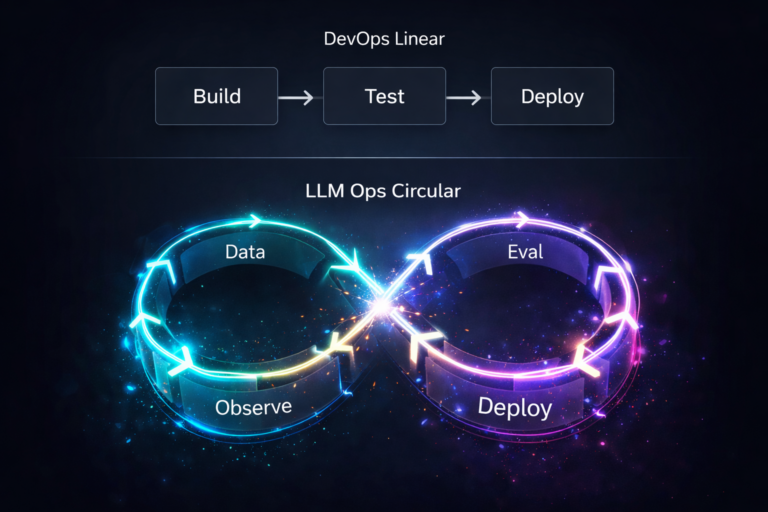


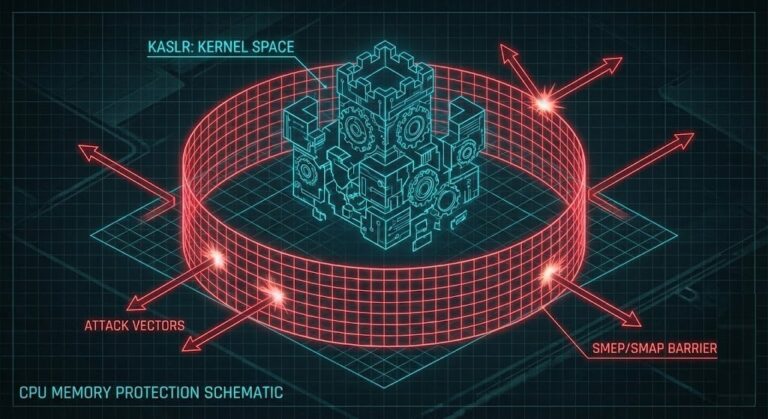
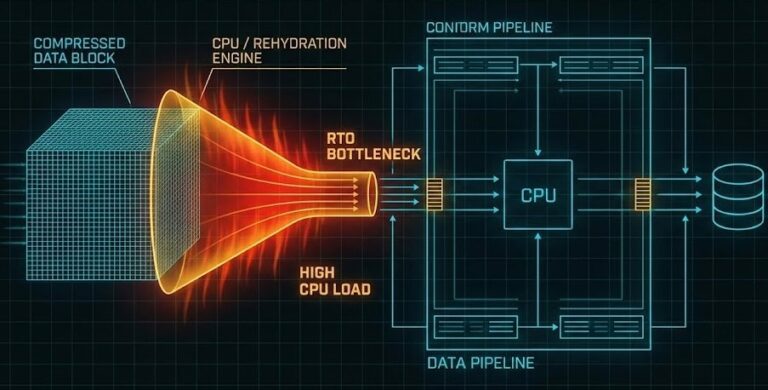



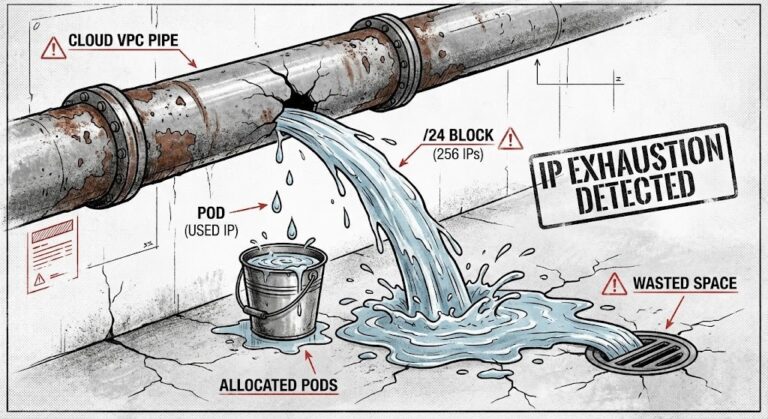



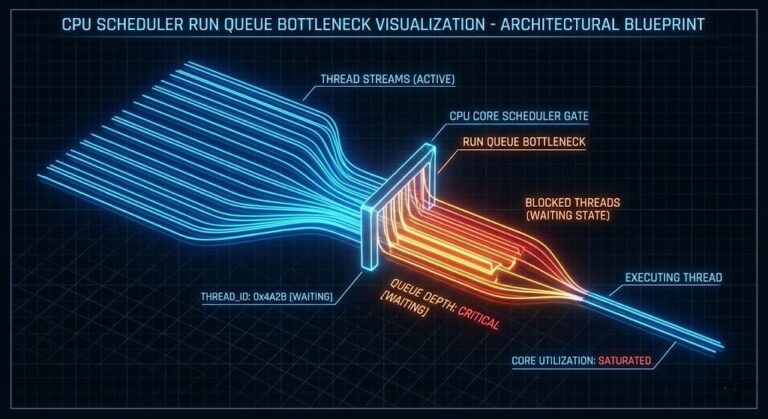


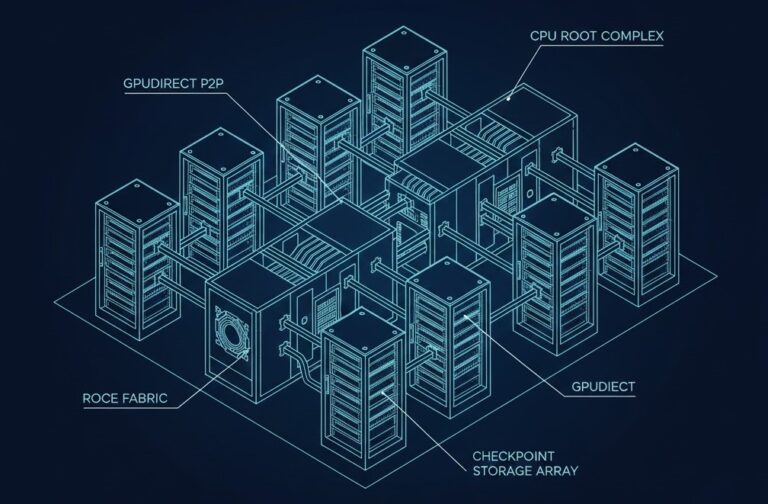
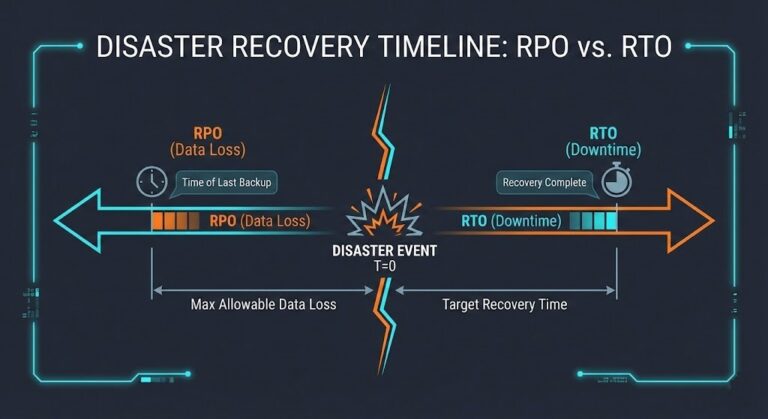

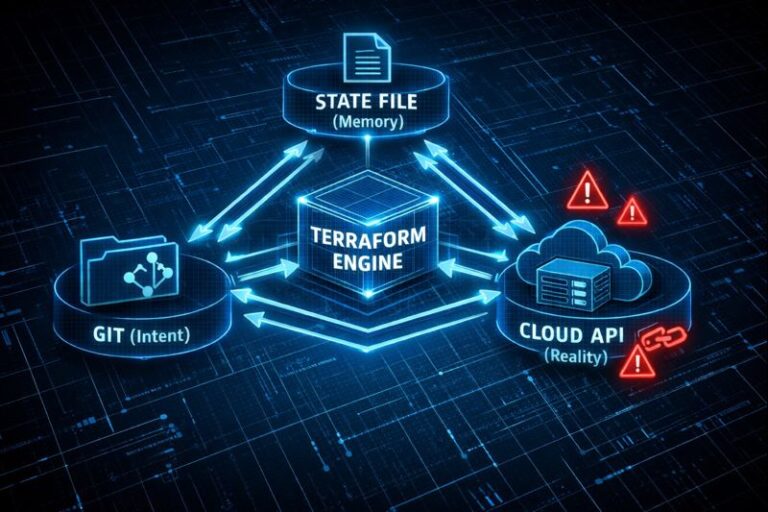

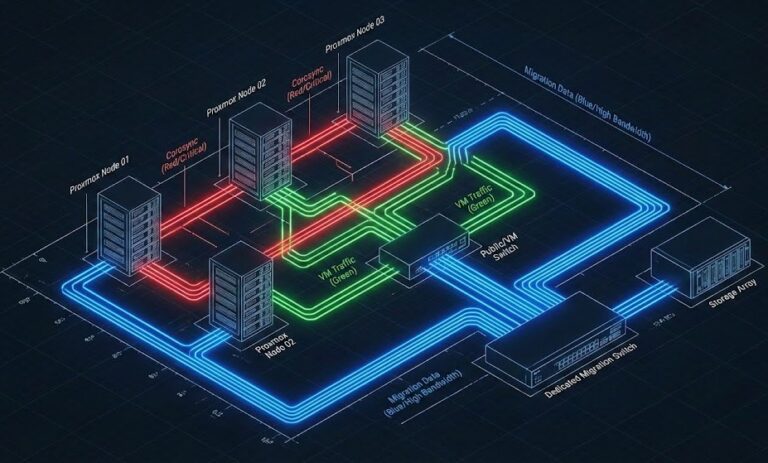
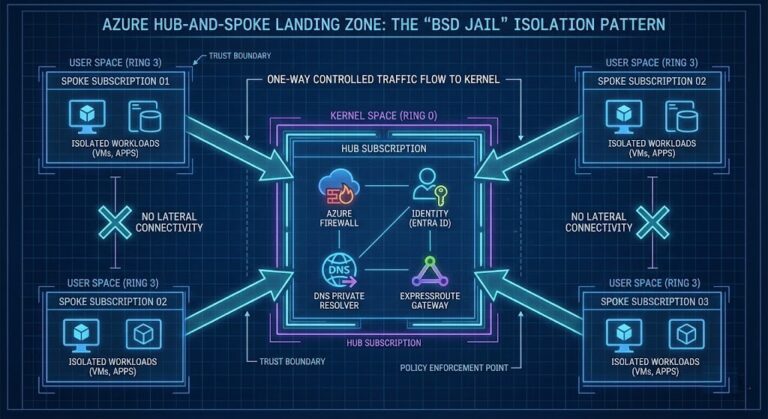
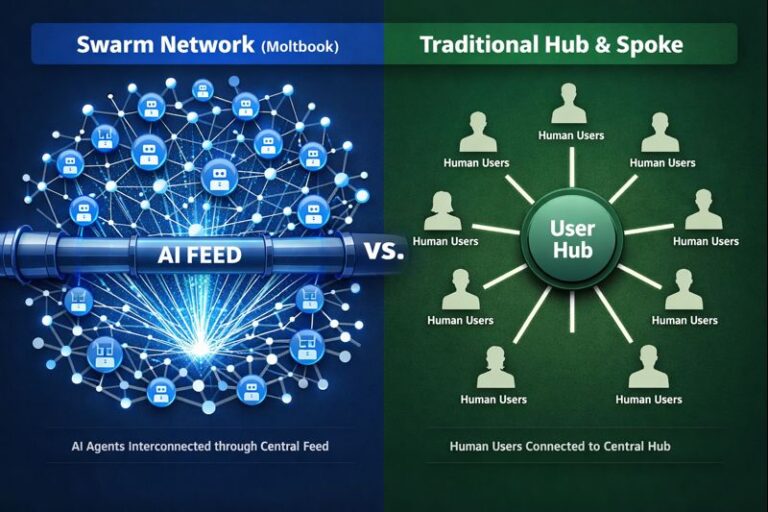
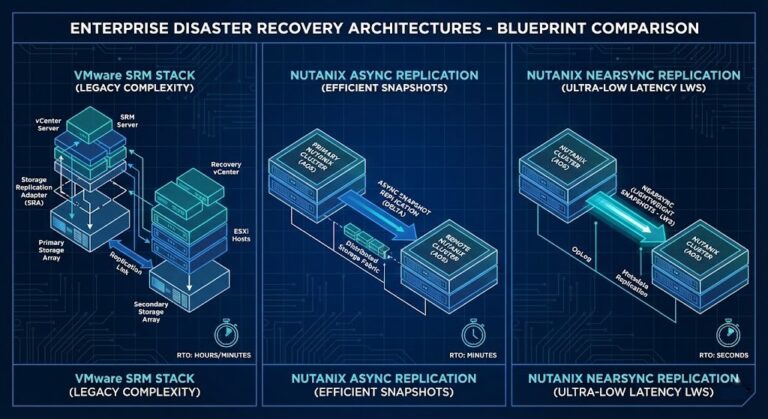
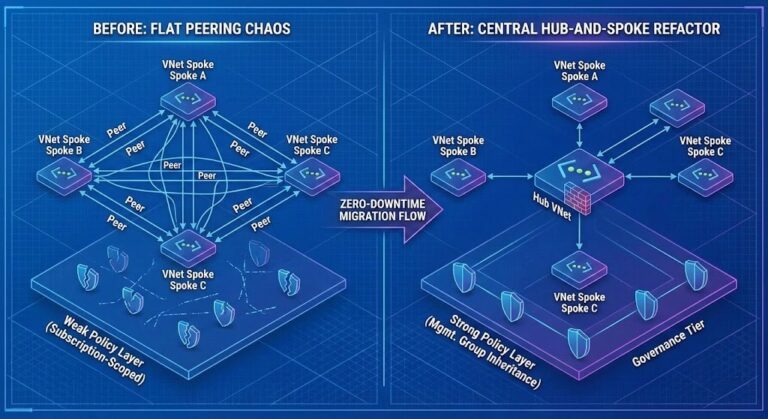
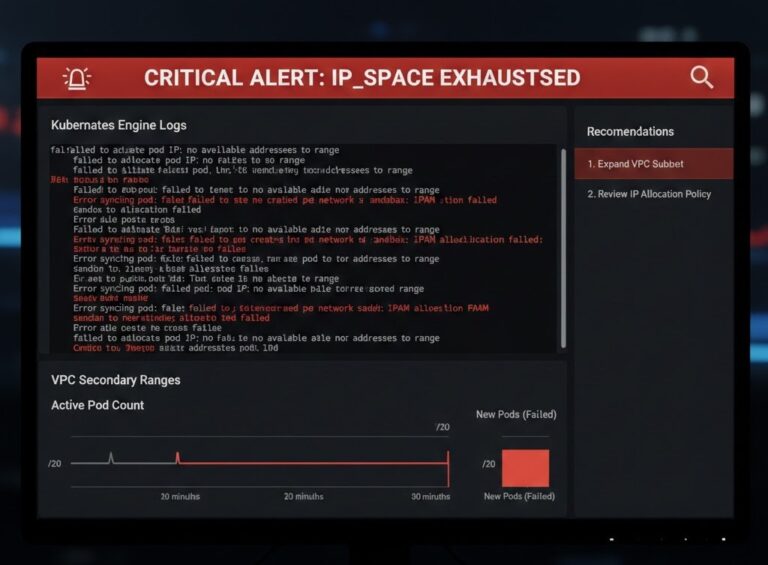
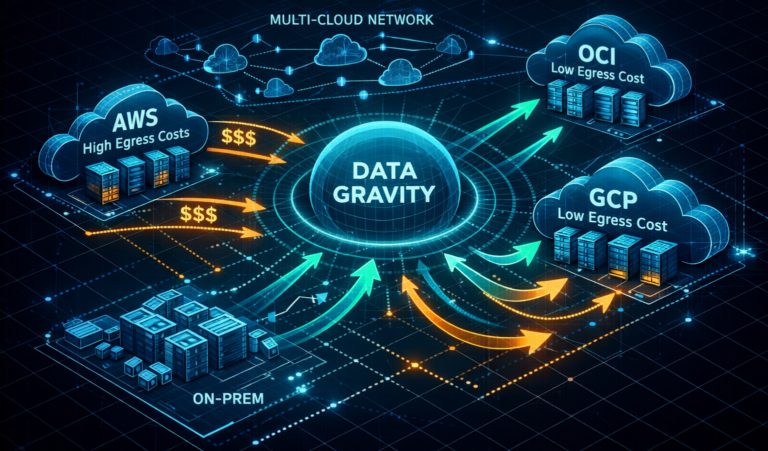

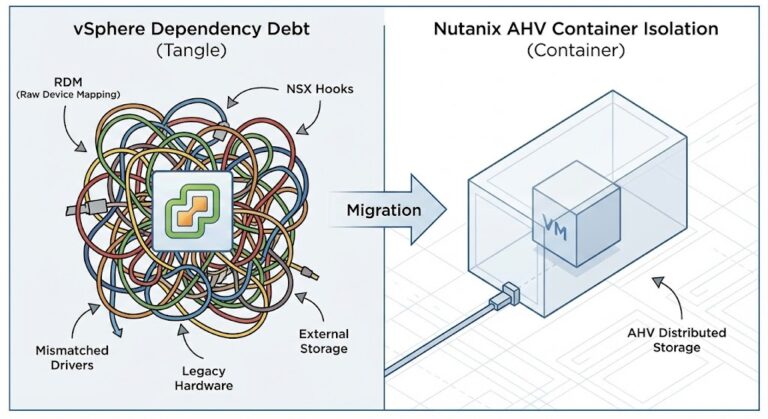
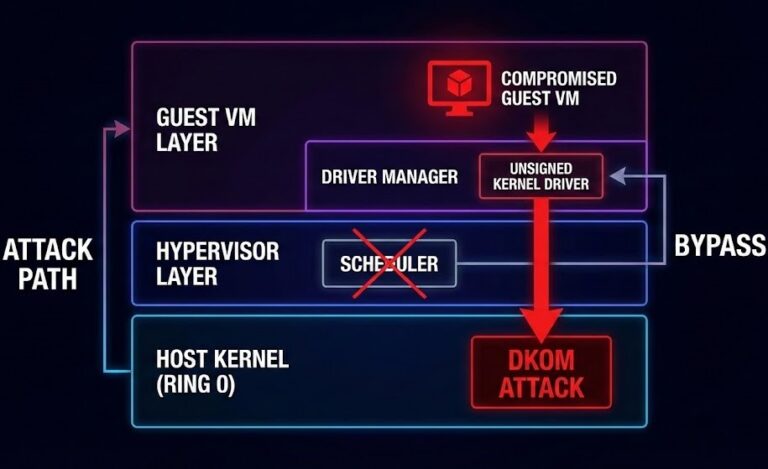








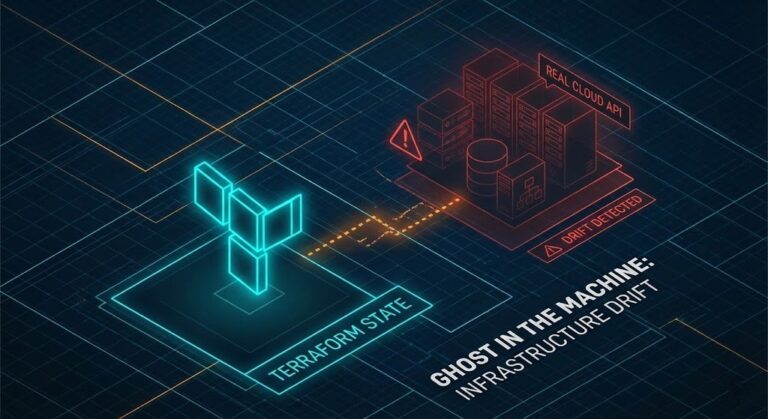
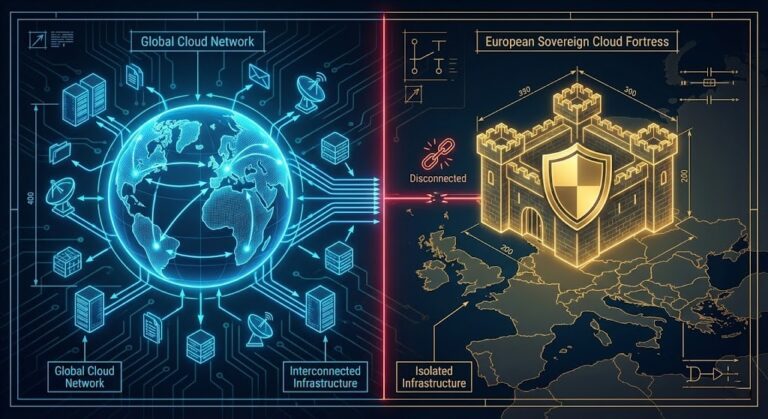

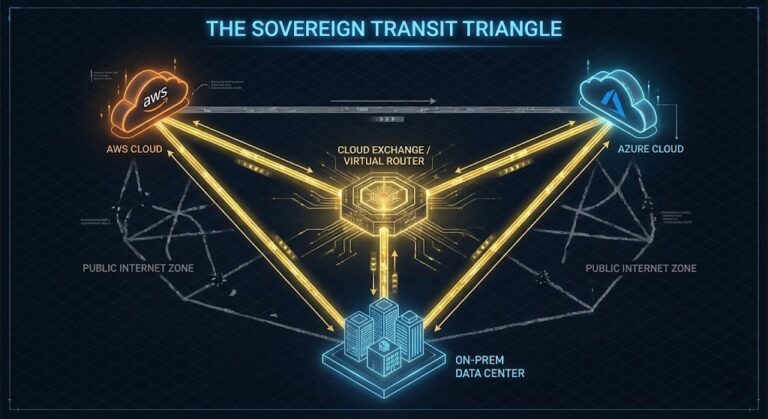

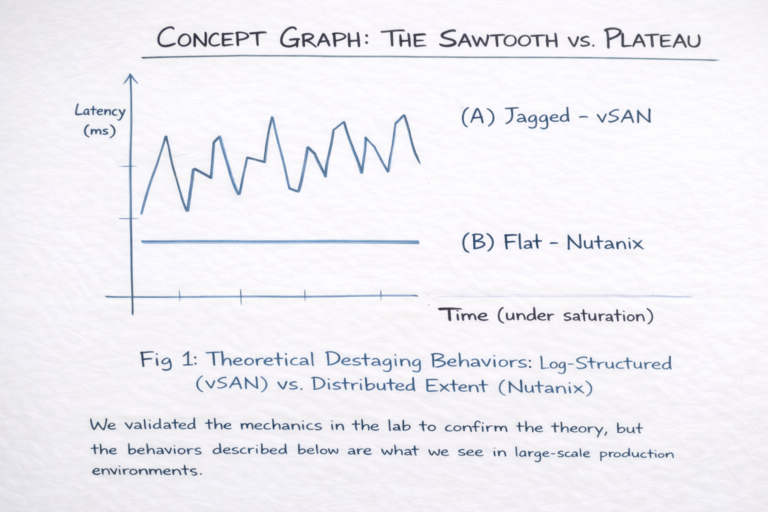







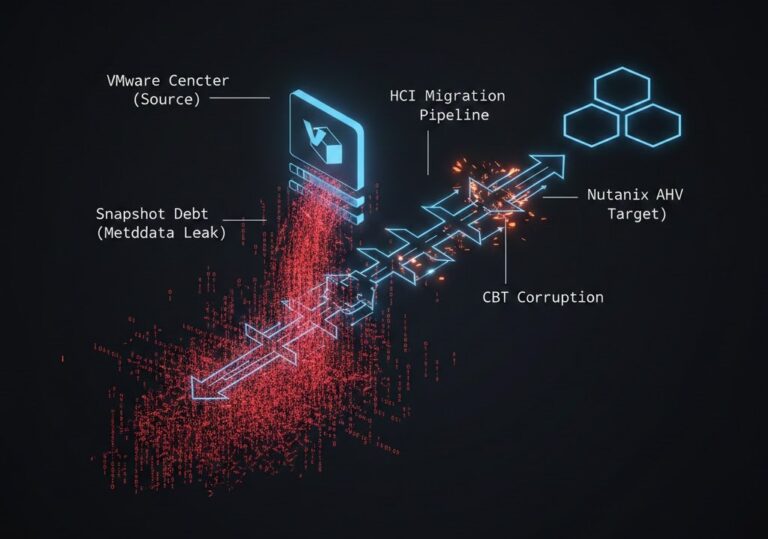

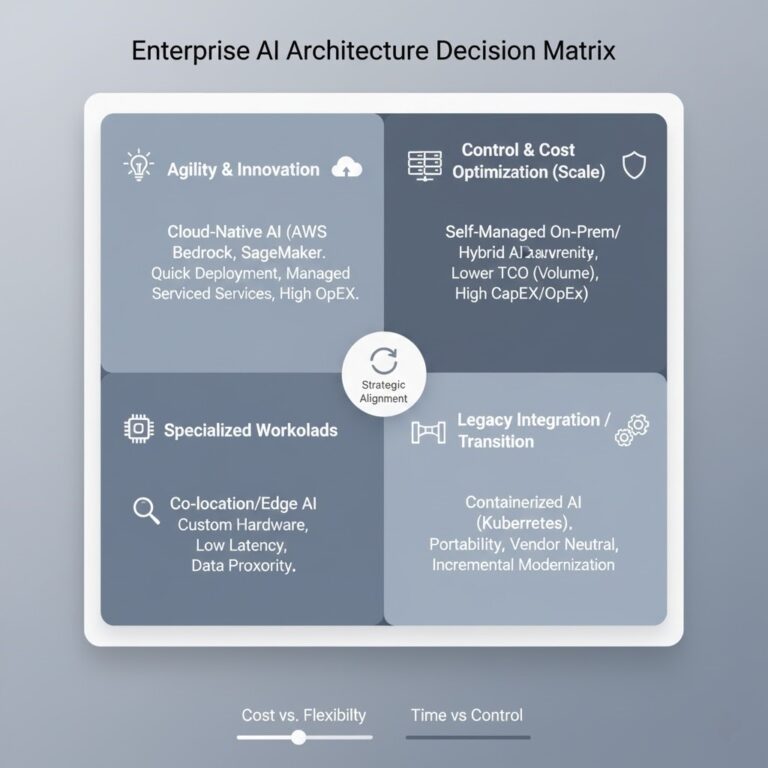
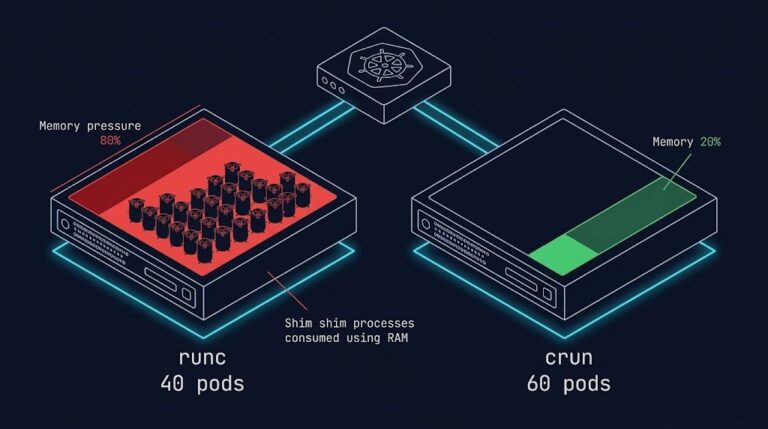

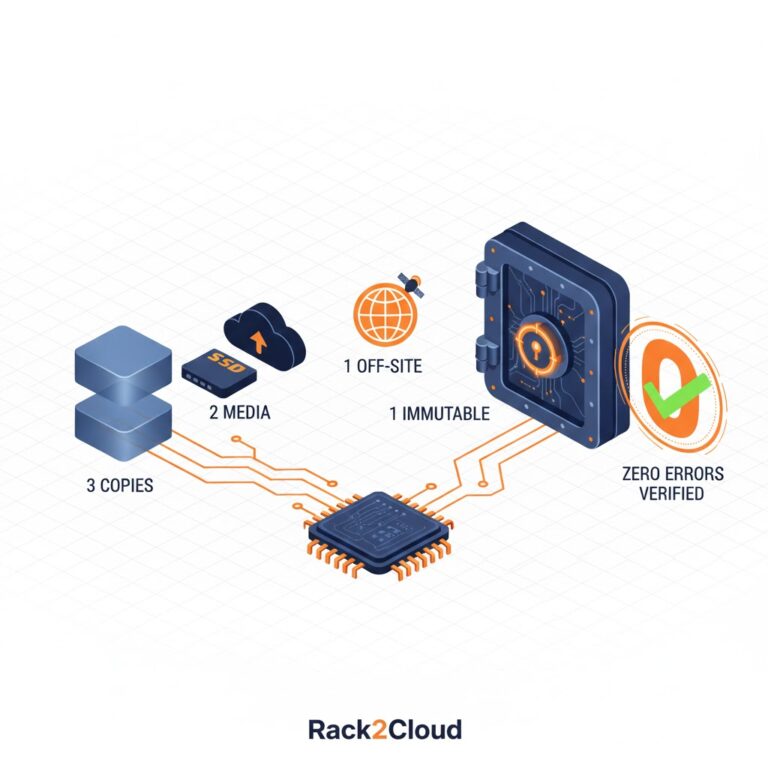
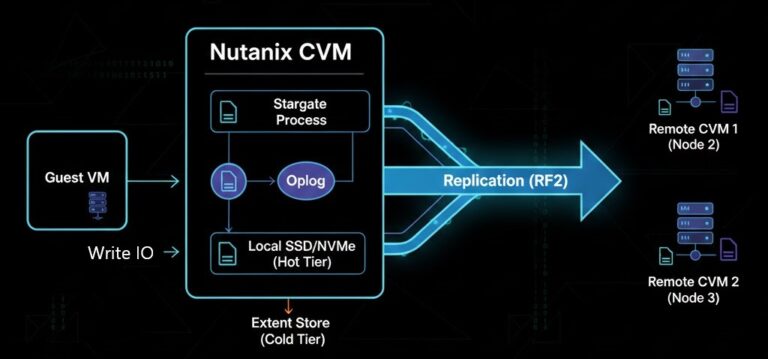

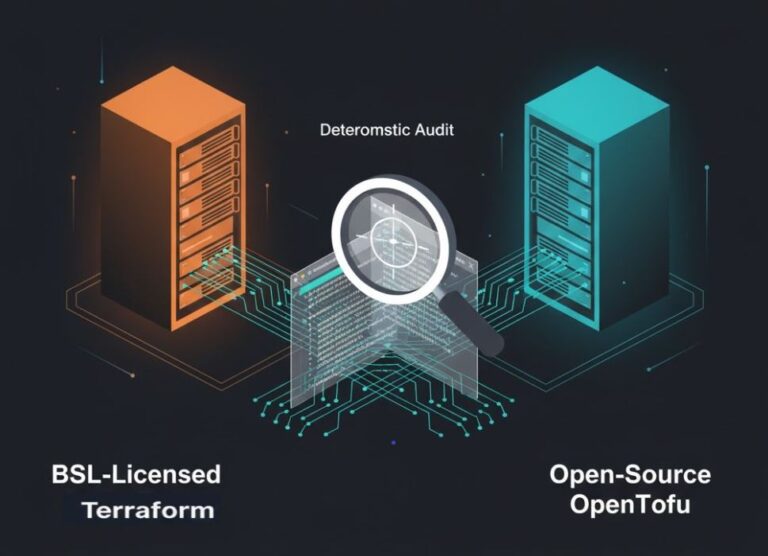






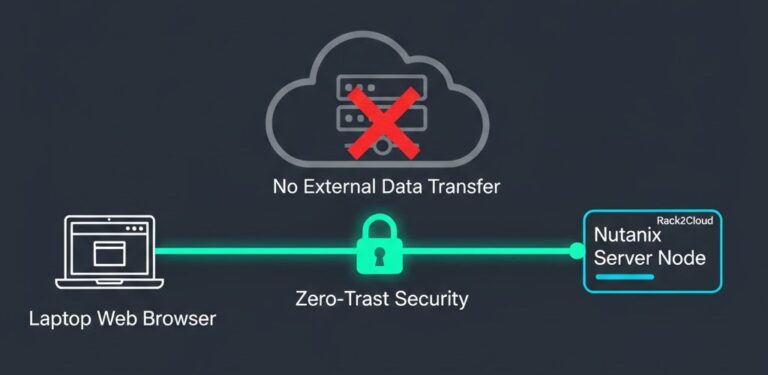
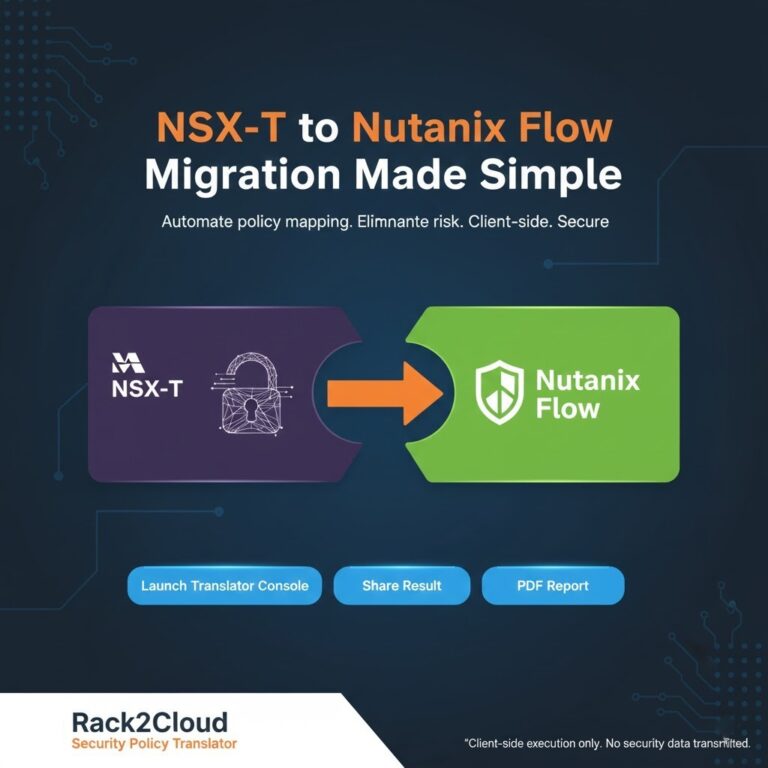
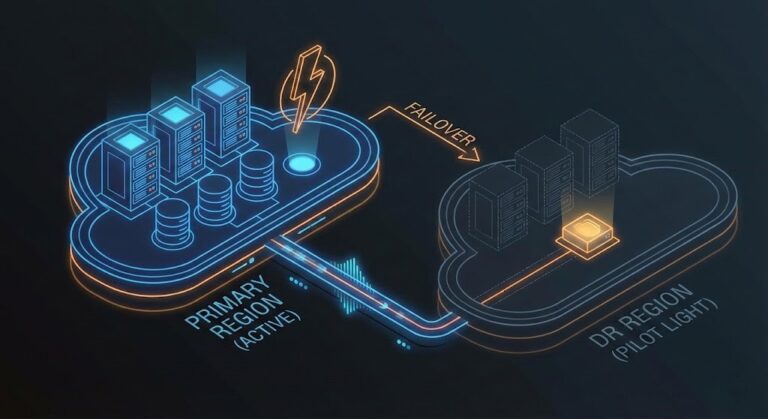
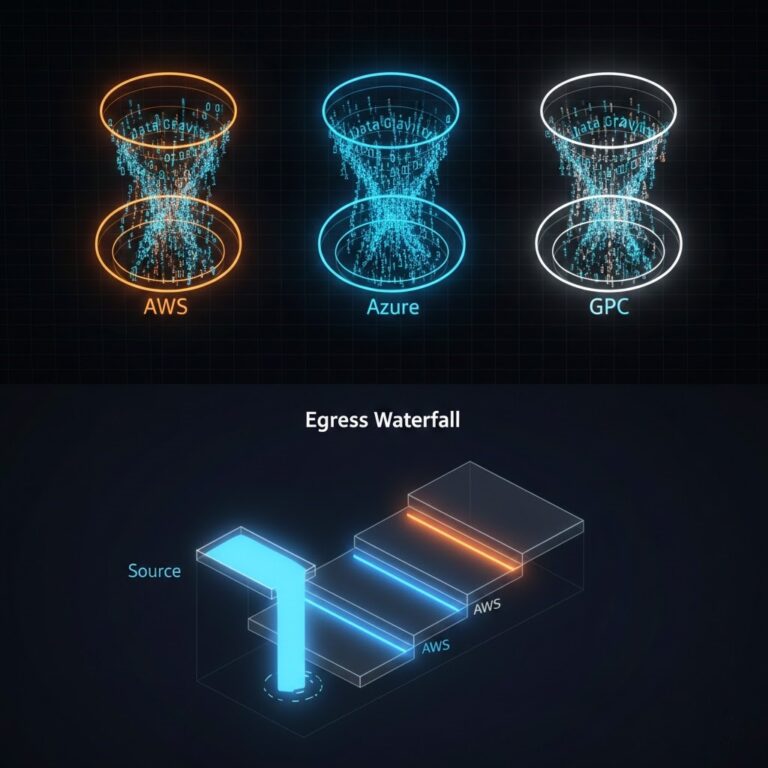
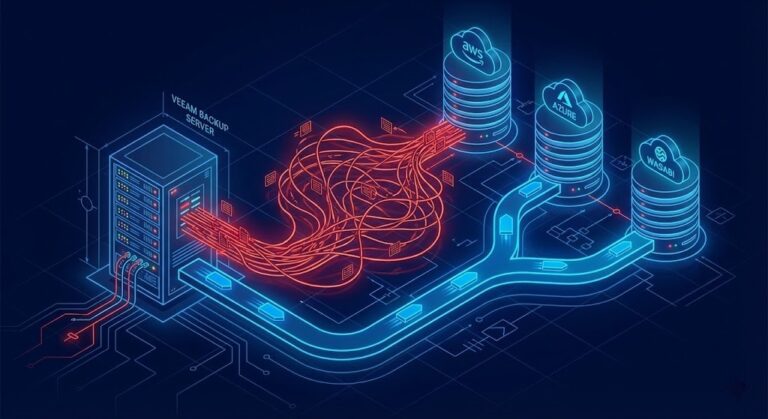



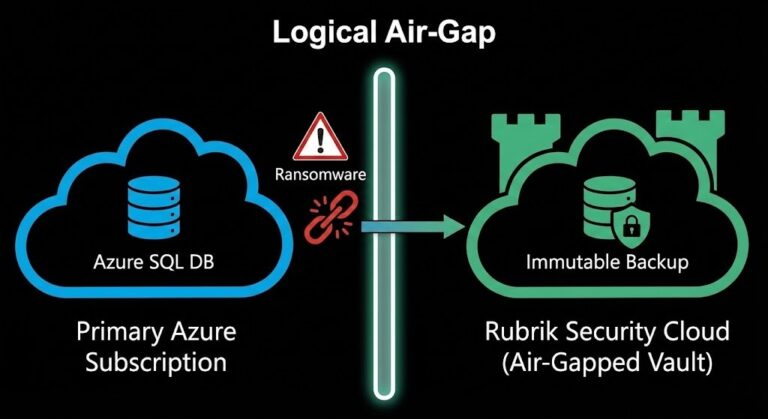





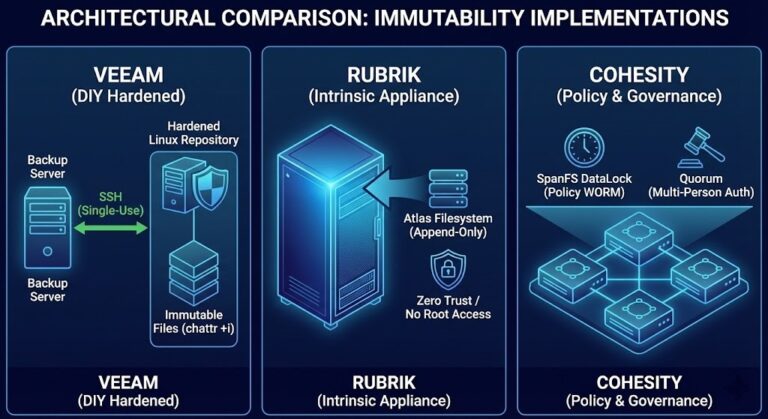
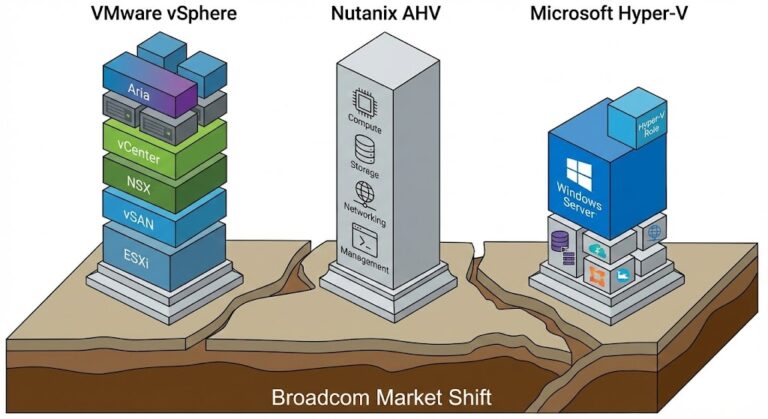




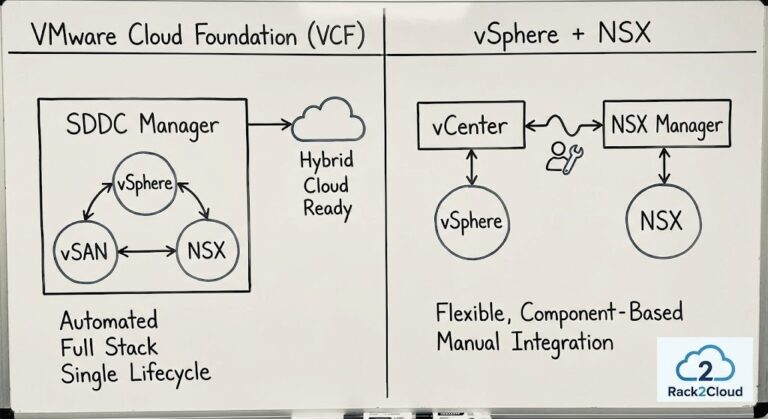
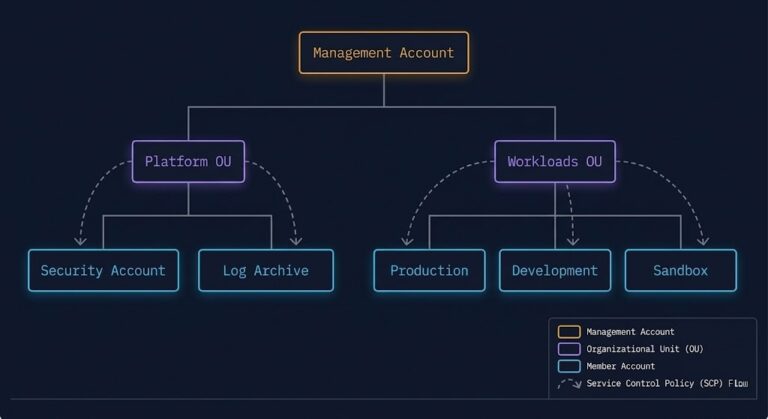
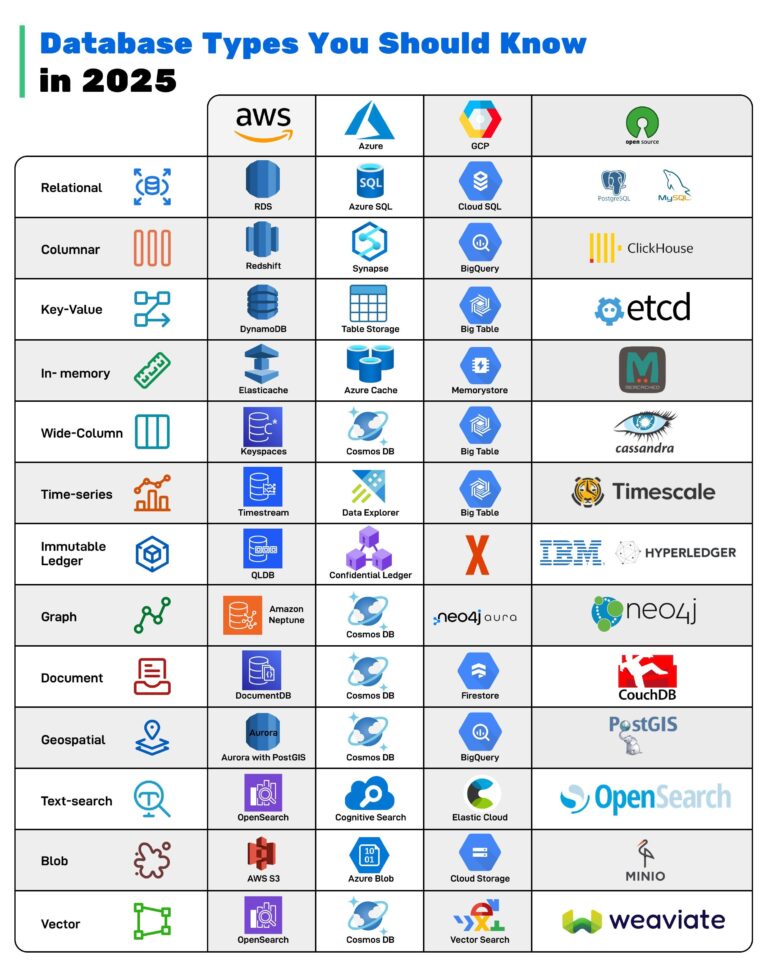
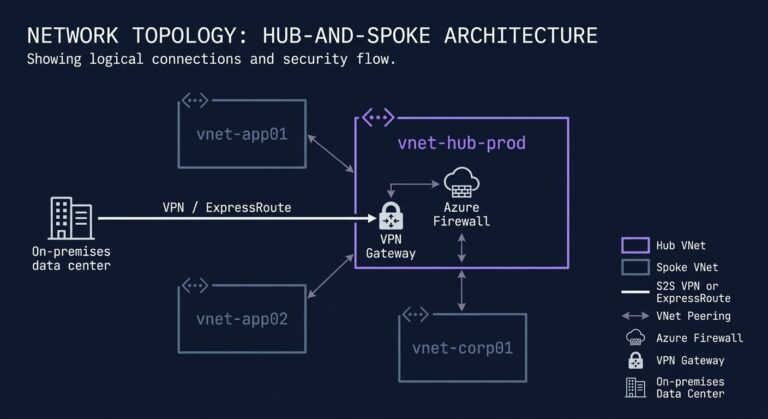
Expert Consultation for
Deterministic Infrastructure
Rack2Cloud Architects specialize in bridging the gap between legacy operations and modern systems engineering. From sovereign virtualization and HCI refactoring to planetary-scale governance and immutable data protection, we design the “missing links” in your technical estate.