Kubernetes 1.35 Removes the Restart Tax — Why Stateful Workloads Just Became Easier to Operate
Kubernetes 1.35 in-place pod resize graduates to stable — and with it, six years of a hidden operational tax on stateful workloads comes to an end.
If a container needed more CPU or memory, the only safe answer was a restart. That design made sense for stateless services. It was painful for everything else.
Increase memory on a JVM service and the JIT cache disappears. Resize a PostgreSQL pod and WAL replay starts again from the last checkpoint. Restart Redis and your cache warm-up becomes a production event that ripples across dependent services. Restart a Kafka broker and partition rebalancing begins — consuming cluster bandwidth while your application waits.
Because of that reality, most platform teams quietly shelved one of Kubernetes’ most promising automation tools: Vertical Pod Autoscaler. VPA could recommend resource changes with reasonable accuracy. Actually applying them was a different calculation entirely. In production, the restart cost was often higher than the resource inefficiency it was fixing.
Kubernetes 1.35 removes that constraint.
In-Place Pod Resource Resize — first introduced as alpha in v1.27, promoted to beta in v1.33 — graduates to stable in 1.35. The resources field in a running pod spec is now mutable for CPU and memory. The kubelet applies the change directly through the cgroup layer. The container keeps running.
This post covers what that change actually means operationally, what breaks in 1.35 that requires your attention before upgrading, and what platform teams should do now.
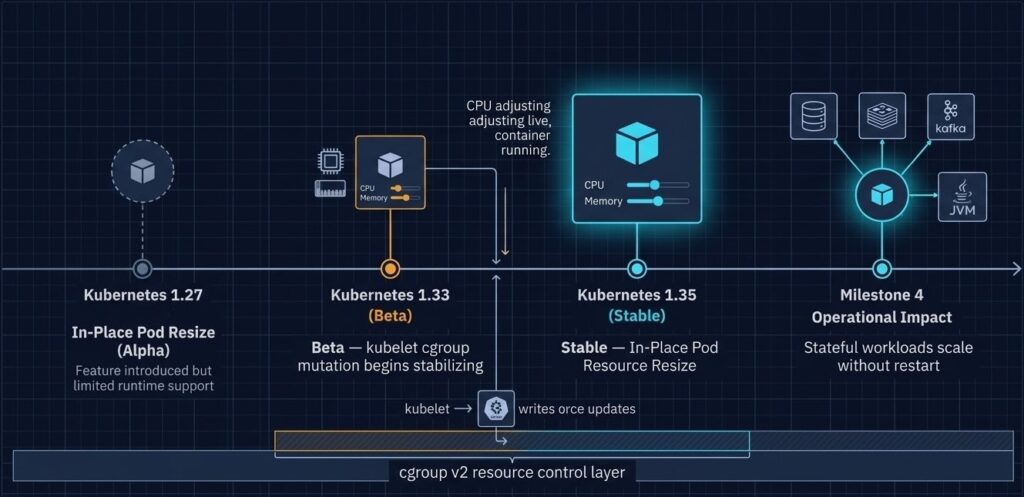
Why In-Place Resize Took Six Years
The feature was not slow due to lack of demand. It was delayed because safely mutating a running container’s resource envelope required solving several non-trivial problems simultaneously:
- Pod immutability was foundational — the original design treated the pod spec as sealed at creation. Mutating resources in-flight required rethinking kubelet reconciliation from the ground up.
- cgroup mutation needed safe exposure — changing CPU and memory limits for a running process requires direct cgroup manipulation. That path needed to be safe, auditable, and consistent across container runtimes.
- Status reconciliation was complex — the kubelet needed to track desired resources, allocated resources, and actual resources independently, and surface that state clearly for operators and autoscalers.
- Runtime support had to be universal — containerd and CRI-O both needed to implement live resource mutation through the CRI interface before the feature could be considered stable. cgroup v2 became the minimum requirement.
Related: Infrastructure State Gravity — this is the operational-dependency example in that framework’s “Three Places” breakdown. The six years this feature took to ship weren’t only an engineering problem — “resize requires recreation” had become a load-bearing assumption everything above the scheduler depended on being true. Removing it meant unwinding accumulated operational state gravity, not just closing a feature gap.
THE RESTART TAX: WHAT IT ACTUALLY COST
The restart was never free. In stateless service architectures — web servers, API gateways, short-lived workers — the cost was low enough to ignore. Spin the container back up, connections re-establish, traffic resumes within seconds.
For the workload classes that make up most of enterprise infrastructure, the math was different.
| Workload | What a Restart Actually Caused | Downstream Impact |
|---|---|---|
| JVM Applications | JIT profile loss + cold GC behavior | Performance degrades for 10–30 min post-restart while JIT recompiles hot paths |
| PostgreSQL | WAL replay + connection pool churn during restart | Recovery time scales with WAL backlog; pgBouncer pools drain and rebuild |
| Redis | Full cache warm-up required | Cache miss storm hits origin databases until warm-up completes — can cascade |
| Kafka Brokers | Partition rebalance cascade | Consumer lag spikes across all partitions during leader re-election |
| ML Inference Services | Model reload from storage | Cold start latency while model weights reload from storage into memory — requests queue or fail |
The operational consequence was predictable: teams stopped treating resource sizing as a tunable parameter. Instead, over-provisioning became the safe default. Requests and limits were set conservatively at deployment time and rarely revisited — not because the right values weren’t known, but because the cost of correcting them was too high to justify outside a maintenance window.
VPA existed to automate that correction. In practice, most teams ran it in recommendation mode only — reading its output during capacity reviews and applying changes manually during planned maintenance. Automated resource management for stateful workloads in Kubernetes was effectively off the table.
How Kubernetes 1.35 In-Place Pod Resize Works
The mechanism is direct: when you patch a running pod’s resource spec, the kubelet detects the change and writes the new values to the container’s cgroup without triggering a container restart. The container keeps running. The process ID does not change. The network namespace is preserved.

The resizePolicy Field
The behavior on resize is controlled per-container via a resizePolicy field. Two restart policy values are available:
NotRequired— the resource change is applied to the cgroup without restarting the container. This is the right setting for CPU changes on most workloads, and for memory increases where the application can consume additional heap without being restarted.RestartContainer— the container is restarted when the specified resource is changed. This is appropriate for memory decreases on workloads where the allocator won’t release memory without a restart, or for applications that read resource limits at startup and don’t re-read them at runtime.
yaml
containers:
- name: postgres
resources:
requests:
cpu: "1"
memory: "2Gi"
limits:
cpu: "2"
memory: "4Gi"
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired
- resourceName: memory
restartPolicy: RestartContainerIn the example above, a CPU resize is applied live. A memory resize triggers a container restart. Both are valid operational choices depending on the workload — the key is that they are now explicit and configurable rather than implicit and universal.
The Two-Field Model
1.35 introduces a clean separation between what you’ve requested and what’s actually running:
spec.containers[*].resources— the desired state. Mutable for CPU and memory.status.containerStatuses[*].resources— the actual resources currently configured at the cgroup layer.
When a resize is in progress, these fields will differ. When complete, they converge. This gives operators a reliable signal for resize status without needing to inspect cgroup values directly.
The cgroup v2 Requirement
In-place resize requires cgroup v2. This is not optional. The unified cgroup hierarchy in v2 is what makes live resource mutation safe and consistent. If your node fleet is still running cgroup v1 — either by legacy OS configuration or because you haven’t pinned cgroup versions across node pools — in-place resize will not function, and the 1.35 upgrade path has additional consequences covered in Section 4.
The mixed-cgroup failure pattern — where clusters contain nodes running different cgroup versions — is covered in detail in containerd in Production: 5 Day-2 Failure Patterns at High Pod Density. That post covers exactly the resource accounting corruption that occurs when cgroup versions are inconsistent across a node fleet.
THE REAL STORY IS VPA
For years, Vertical Pod Autoscaler had an awkward reputation in production environments. The promise was sound: observe actual resource consumption, recommend optimal requests and limits, and apply them automatically to reduce waste and prevent OOM kills. The missing piece was a safe way to apply those recommendations without restarting the workload. The execution had a fundamental flaw.
Applying VPA recommendations meant restarting pods. For stateless services that was a reasonable trade. For databases, brokers, caches, and long-running compute jobs, it was operationally risky enough that most teams disabled the Auto and Recreate update modes entirely. VPA became a read-only advisory tool — useful for capacity planning, useless for live automation.
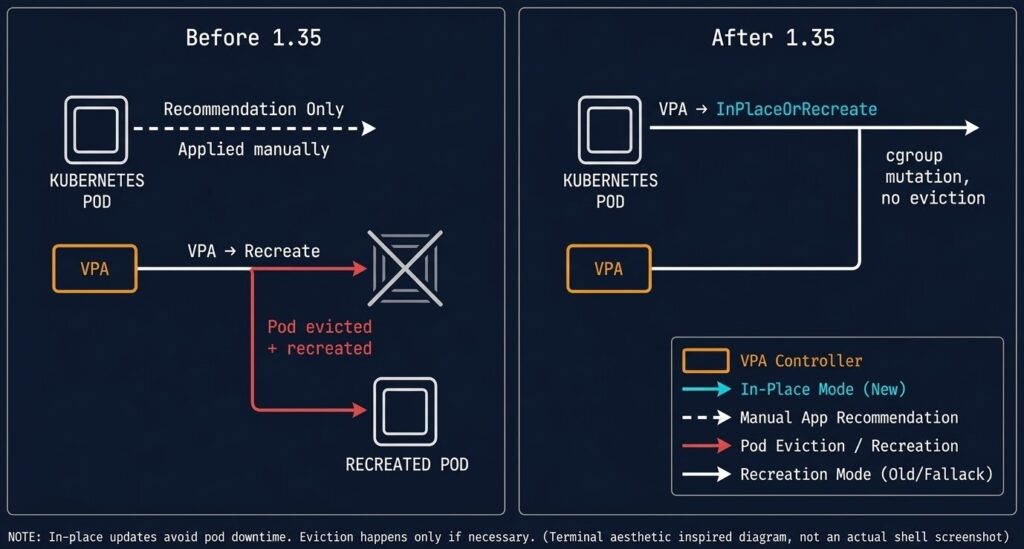
VPA InPlaceOrRecreate — Beta in 1.35
With Kubernetes 1.35 in-place pod resize now stable, the InPlaceOrRecreate VPA update mode graduates to beta. The behavior is exactly what the name implies:
- VPA attempts to resize the pod in-place by patching the resource spec
- The kubelet applies the change via cgroup mutation — no eviction, no restart (subject to
resizePolicy) - If the node lacks sufficient capacity to honor the resize, VPA falls back to the traditional evict-and-recreate path
This fallback behavior is important for production planning. In-place resize is not a guarantee — it is a best-effort optimization. Capacity constraints can still force eviction. The difference is that eviction is now the exception rather than the rule for well-provisioned clusters.
Why This Matters for Databases
The operational shift is most significant for database workloads, which previously had no safe automated scaling path in Kubernetes.
- Scaling memory → pod restart
- Pod restart → connection loss
- Connection loss → pgBouncer pool drain
- Pool drain → application error spike
- VPA automation disabled for safety
- Scaling memory → cgroup mutation
- cgroup mutation → workload continues
- Connections remain established
- Application sees no disruption
- VPA InPlaceOrRecreate viable for production
PostgreSQL, MySQL, and other databases that accumulate WAL backlog during restart now have a viable path to automated vertical scaling in Kubernetes. The same applies to Redis clusters where cache warm-up time is a production concern, and to Kafka brokers where partition rebalancing during restarts creates consumer lag across the cluster.
The Operator Warning
In-place resize changes the container’s resource limits immediately at the cgroup layer. The application does not always adapt instantly.
Memory allocators, JVM heap sizing, and database buffer pools are typically configured at startup. Increasing memory limits in-place makes more memory available to the container — but the application may not consume it without explicit configuration changes or a deliberate restart. For JVM workloads specifically, -Xmx is still a startup parameter. Raising the memory limit without adjusting the JVM heap configuration produces a container with more headroom but the same effective heap ceiling.
Test resize behavior in non-production environments before enabling VPA automation for stateful workloads. Not all applications react predictably to live resource changes, particularly memory shrinks.
UPGRADE LANDMINES IN KUBERNETES 1.35
In-place resize is the headline. The breaking changes are what require immediate attention before upgrading production clusters.
1 — cgroup v1 Is Gone
This is not a deprecation. cgroup v1 support has been removed in 1.35.
If any nodes in your fleet are still running cgroup v1 — by OS default, by explicit configuration, or because node pool images haven’t been updated — the upgrade will break resource enforcement on those nodes. This is not a graceful degradation scenario.
The diagnostic path is straightforward:
bash
# Check cgroup version on a node
stat -fc %T /sys/fs/cgroup/
# cgroup2fs = v2 (compatible)
# tmpfs = v1 (incompatible — must be remediated before upgrade)
# Check containerd's cgroup driver
containerd config dump | grep SystemdCgroup
# Verify kubelet matches
systemctl show kubelet | grep cgroup-driverAll three values must be consistent. If stat returns tmpfs, that node cannot run 1.35 without OS-level remediation. The mixed-cgroup failure patterns this creates — and the diagnostics for catching them — are documented in containerd in Production: 5 Day-2 Failure Patterns at High Pod Density.
2 — containerd 1.x Is End of Life
containerd 1.x reaches end of life with the 1.35 release cycle. The minimum supported version is containerd 2.x.
This matters operationally because containerd 2.x changed default behaviors around cgroup driver configuration, image garbage collection thresholds, and shim management. A containerd upgrade is not a drop-in binary swap — validate runtime behavior in non-production before rolling to production node pools.
If you’re running high pod density environments (400+ containers per node), the shim accumulation and socket serialization behaviors documented in the containerd Day-2 failure patterns post apply directly to the containerd 2.x migration. Review that post before upgrading your runtime.
3 — IPVS Mode Is Formally Deprecated
kube-proxy’s IPVS mode is formally deprecated in 1.35. The project is moving toward nftables as the primary dataplane, with iptables maintained as a compatibility layer during the transition.
If your clusters use IPVS for kube-proxy — common in high-throughput environments where IPVS’s O(1) connection lookup was the operational justification — begin planning the migration path. The deprecation does not mean immediate removal, but production clusters should not be built on deprecated dataplanes. Validate your current kube-proxy mode:
bash
kubectl get configmap kube-proxy -n kube-system -o yaml | grep modeWHAT PLATFORM TEAMS SHOULD DO BEFORE UPGRADING
The upgrade checklist for Kubernetes 1.35 in-place pod resize is more operationally demanding than a typical minor release. The cgroup v1 removal and containerd EOL create real blockers for clusters that haven’t been actively maintained.

Step 1 — Verify Node Runtime Compatibility
Run the cgroup version check across all nodes before scheduling the upgrade. Nodes still on cgroup v1 must be remediated at the OS level — typically by updating the kernel boot parameters and rebooting — before 1.35 can be safely deployed.
Verify containerd version across all nodes:
bash
# Check containerd version on all nodes via kubectl
kubectl get nodes -o wide
# Then on each node:
containerd --version
# Must return 2.xStep 2 — Audit StatefulSet and Deployment Specs
Add resizePolicy to StatefulSets where you intend to use in-place resize particularly for databases, JVM workloads, and memory-sensitive services. Without explicit resizePolicy configuration, the default behavior is NotRequired for CPU and NotRequired for memory — meaning both changes are attempted in-place. For workloads where memory changes require a restart (JVM heap, database buffer pools), set restartPolicy: RestartContainer for memory explicitly.
Step 3 — Re-Evaluate VPA Configuration
Many platform teams disabled VPA’s automatic update modes years ago specifically because of the restart cost. With 1.35 and InPlaceOrRecreate graduating to beta, those decisions should be revisited. Start with non-critical stateful workloads in non-production environments. Validate resize behavior before enabling automation on production StatefulSets.
Step 4 — Test Resize Behavior Per Workload Class
Not all applications respond predictably to live resource changes. Before enabling VPA automation or building operational workflows around in-place resize, run controlled resize tests:
- Increase CPU limits and verify application performance response
- Increase memory limits and verify the application actually consumes additional memory (JVM heap check)
- Test memory decrease behavior — the kubelet makes a best-effort to prevent OOM kills during memory limit reductions, but provides no guarantees
The Kubernetes Day-2 diagnostic framework for compute-layer failures — including scheduler behavior during resize operations — is documented in the Kubernetes Scheduler Stuck: CPU Fragmentation and Pending Pods post.
Architect’s Verdict
Kubernetes is slowly removing the assumptions that made it feel stateless-only.
In-place pod resize is not a minor convenience feature. It closes a six-year operational gap that forced platform teams to choose between resource efficiency and workload stability. For the workload classes that make up most of enterprise infrastructure — databases, caches, brokers, long-running compute — that trade-off is now gone.
But the operational complexity doesn’t disappear. It shifts.
Runtime compatibility, cgroup version consistency, and Day-2 resource drift still decide whether clusters stay stable after upgrade. The teams that will get the most out of 1.35 are the ones who audit their node fleet before upgrading, test resize behavior before enabling automation, and treat resizePolicy as an explicit architectural decision rather than a default.
The five failure modes that surface most consistently in production Kubernetes environments — including the resource contention patterns that in-place resize is designed to prevent — are documented in Kubernetes Day 2 Failures: 5 Incidents & the Metrics That Predict Them.
KubeCon EU runs March 24–26 in Amsterdam. Expect in-place resize, VPA automation, and the containerd 2.x migration to be recurring topics across platform engineering sessions.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session