Kubernetes as the VMware Exit Ramp: How Platform Teams Are Reducing VMware Dependence
The Kubernetes VMware migration path is not what most platform teams expect. Thirty-three percent of enterprises evaluating VMware alternatives are selecting Kubernetes as their primary control plane for the transition. Not as the destination — as the mechanism. The distinction matters architecturally, and most of the coverage on this topic misses it entirely.
Kubernetes does not replace VMware. It replaces the need for VMware to be the only answer. That is a different problem with a different solution architecture, and it is the reason platform teams are reaching for K8s as the exit vehicle rather than a direct hypervisor swap.
This post covers the architecture behind that decision — the why, the how, and the execution model — from three perspectives: the VMware admin evaluating the exit path, the K8s engineer whose organization is still running VMware, and the architecture lead who owns the transition decision.

Why Kubernetes and Not a Direct Hypervisor Swap
The obvious VMware exit path is a direct hypervisor replacement — move from ESXi to AHV, Proxmox, or KVM. That path is valid and well-documented in the Broadcom Exit Strategy and across the Post-Broadcom Migration Series. For organizations with primarily VM-based workloads, it is often the right call.
But a significant portion of enterprise infrastructure is not primarily VM-based anymore. It is a hybrid of legacy VMs that cannot be containerized on any reasonable timeline and modern workloads that were born cloud-native or are actively being refactored. For those organizations, a direct hypervisor swap solves the licensing problem without solving the platform problem.
Kubernetes as the exit ramp solves both simultaneously. It gives platform teams a unified control plane that can orchestrate containers natively while VMs complete their lifecycle on whatever hypervisor they currently run. The Broadcom licensing clock stops ticking on new workloads the moment they land in K8s, and the legacy VM estate migrates on its own schedule without a hard cutover deadline.
This is why 33% of enterprises are choosing this path. It is not ideological. It is the architecture that matches the actual state of most enterprise infrastructure — mixed, messy, and impossible to migrate in a single wave.
This is the Absorber camp’s mechanism specifically — one of three strategic postures the virtualization market has resolved into, distinct from the Consolidator (stay on VMware) and Replacer (swap hypervisors) paths.
What the VMware Admin Needs to Understand
If you are a VMware admin evaluating this path, the first thing to understand is that Kubernetes is not coming for your VMs. Not immediately, and in many cases not ever for specific workload classes. The exit ramp model is additive, not replacement — K8s handles new workloads and refactored applications while your VM estate continues to run.
What changes is where operational investment goes. New capabilities, new services, and new infrastructure decisions route through the Kubernetes control plane. The VMware environment enters a maintenance posture — kept running, kept stable, but no longer the platform where new architectural decisions are made. This is a meaningful shift in operational focus even if the VMs themselves do not move for months or years.
The practical implication: VMware administration skills remain valuable during the transition, but the career trajectory for platform engineers is moving toward Kubernetes fluency. The exit ramp is also a skills ramp, and the organizations executing this well are investing in both simultaneously — not waiting for the migration to complete before building K8s operational capability.
What the Architecture Lead Needs to Understand
If you own the transition decision, the question is not “K8s or VMware” — it is “what is the sequence, and what does done look like.” Both answers depend on your workload profile, your team’s operational maturity, and your Broadcom licensing exposure timeline.
The architecture lead’s decision framework has three variables. First, licensing pressure — how much runway does your current VMware agreement give you before renewal becomes an existential cost conversation? That timeline sets the outer boundary of the migration window. Second, workload containerization readiness — what percentage of your VM estate is realistically containerizable in that window? That determines how much of the exit can go through K8s versus requiring a direct hypervisor migration for legacy VMs. Third, platform engineering capacity — do you have the team to build and operate a K8s platform while simultaneously maintaining the VMware environment? Coexistence has an operational cost that must be in the model.
The honest answer for most enterprise environments is that the K8s exit ramp handles 40-60% of the workload migration. The remainder requires either a direct hypervisor swap for legacy VMs or a longer-term refactoring program. A complete exit strategy combines both tracks — K8s for cloud-native and refactorable workloads, direct hypervisor migration for the VM estate that cannot or will not be containerized on the available timeline.
Which Workloads Move First
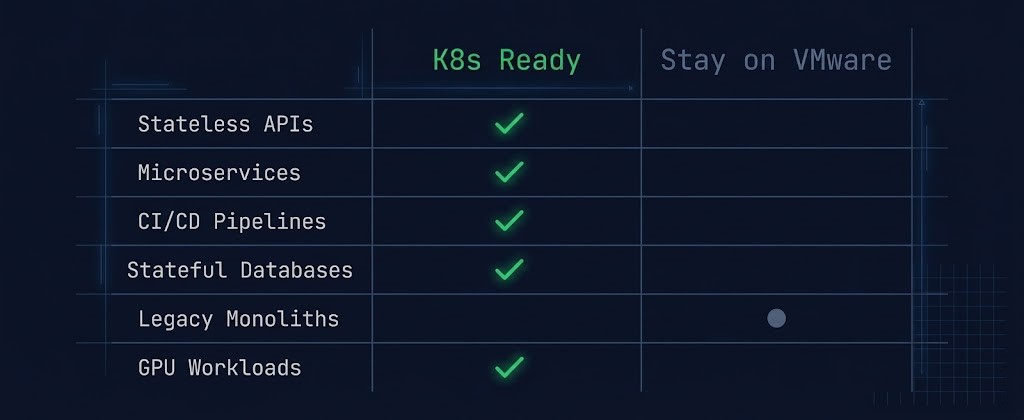
Not every workload belongs in Kubernetes, and forcing containerization on the wrong workload class creates more operational complexity than it resolves. The selection criteria for K8s migration are straightforward — workloads that are stateless, horizontally scalable, and already service-oriented are strong candidates. Workloads with deep OS dependencies, stateful storage requirements, or legacy application architectures are not.
The workloads that move first are the ones that require the least architectural surgery — stateless services, CI/CD infrastructure, and web-tier applications. These establish the K8s platform operationally and demonstrate the model before the harder migration decisions are made. Legacy VMs and stateful databases are addressed in later phases or handled through direct hypervisor migration in parallel.
The Coexistence Architecture
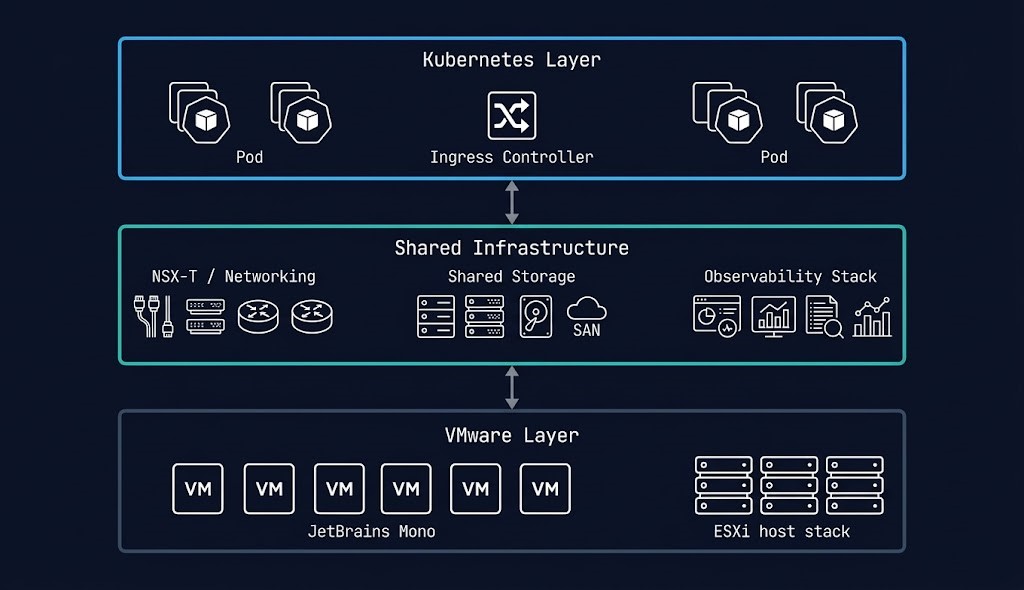
The coexistence architecture is the most underspecified part of every K8s exit ramp conversation. Organizations spend significant time on the Kubernetes platform design and almost no time on how K8s and VMware share infrastructure during the transition. That gap is where migrations stall.
Three infrastructure layers require explicit coexistence design: networking, storage, and observability.
The coexistence architecture also has a governance dimension that the three infrastructure layers above don’t capture. Running K8s and VMware simultaneously means operating two control planes at once — with split management authority, split policy enforcement, and split operational tooling. The Fragmented Control Plane problem that emerges during this window is not resolved by clean networking and shared storage. It requires an explicit governance model for the hybrid operational state. The VMware Exit Has Entered the Coexistence Era maps that governance architecture — the operational model that prevents the coexistence window from becoming a permanent condition.
Networking. The K8s cluster and VMware environment need to communicate cleanly across a defined boundary. For organizations running NSX-T, the NSX-T to Flow migration path provides a structured transition for the network policy layer. For others, a well-defined VLAN boundary with explicit ingress and egress rules between environments is the minimum requirement. Undefined networking between K8s and VMware is the most common source of coexistence failures.
Storage. Persistent volume claims in K8s need to resolve to storage that is available during the coexistence period. For organizations where VMware datastores are the primary storage layer, a shared storage backend that serves both environments — NFS, iSCSI, or a software-defined storage platform like Ceph — is the cleanest architectural answer. This is also the layer where the Controller Tax analysis from Part 2 of the Post-Broadcom Series becomes directly relevant — storage I/O contention between K8s persistent volumes and VM datastores on shared HCI infrastructure is a real operational constraint that must be modeled before the architecture is finalized.
Observability. Running two platforms with two separate observability stacks is the fastest path to operational chaos during a migration. A unified observability layer — metrics, logs, and traces from both K8s and VMware feeding into a single platform — is not optional for organizations running coexistence at scale. The K8s Day 2 operations framework covered in the K8s Day 2 Method applies directly here, with the addition of VMware-sourced metrics alongside the container telemetry.
The Four-Phase Migration Model

The K8s exit ramp is not a big-bang migration. It is a phased architectural transition that takes 12 to 36 months to execute correctly depending on the size and complexity of the VMware estate. Organizations that attempt to compress this timeline consistently underestimate the Kubernetes VMware coexistence architecture operational burden and the workload assessment effort required before migration begins.
Where This Fits in the Post-Broadcom Series
The K8s exit ramp is not an alternative to the Post-Broadcom Migration Series — it is a parallel track that serves the portion of the enterprise estate that is containerization-ready. The series covers the physics of migrating VM workloads to AHV: execution physics in Part 1, resource contention modeling in Part 2, and high-I/O cutover sequencing in Part 3.
For most enterprise environments, the complete exit strategy combines both tracks. VM workloads that cannot be containerized on the available timeline follow the AHV migration path. Cloud-native and refactorable workloads follow the K8s exit ramp. The Broadcom licensing clock is the shared deadline that both tracks are working against.
The architecture decision is not which track to choose — it is how to resource both tracks simultaneously without creating operational chaos in either direction. That is the conversation most organizations are not having early enough, and it is the reason VMware exits that look straightforward on paper consistently take longer than planned.
The VMware exit has moving parts across licensing, resource contention, networking, and cutover sequencing. The Engineering Workbench maps the operational framework for each phase — core exposure modeling, migration risk assessment, NSX-T policy translation, and metro latency validation before the maintenance window opens.
→ Open VMware Exit & MigrationYou know the risk of carrying forward architectural debt. Now, we tear down the mechanics. Track the series below as we map the exact physical changes required for a deterministic migration.
Skip the wait. Download the complete Deterministic Migration Playbook (including the Nutanix Metro Cluster Implementation Checklist) and get actionable engineering guides delivered via The Dispatch.
SEND THE BLUEPRINTQ: Can Kubernetes replace VMware entirely?
A: Kubernetes can replace VMware as the primary control plane for cloud-native and containerizable workloads, but it does not replace VMware for every workload class. Legacy monolithic applications, stateful databases with complex OS dependencies, and workloads requiring full VM isolation are better served by a direct hypervisor migration to AHV, Proxmox, or another platform. Most enterprise environments require both tracks running in parallel.
Q: How long does a Kubernetes VMware exit take?
A: A complete K8s exit ramp migration takes 12 to 36 months depending on the size and complexity of the VMware estate. Phase 1 platform build and validation typically takes 3-6 months. New workload migration begins in months 6-12. VM estate migration runs from months 12-24. Platform consolidation completes between months 24-36. Organizations that attempt to compress this timeline consistently underestimate the coexistence operational burden.
Q: What is the coexistence architecture for Kubernetes and VMware?
A: The coexistence architecture requires explicit design across three layers — networking, storage, and observability. Networking requires a defined boundary with clean ingress and egress rules between the K8s cluster and VMware environment. Storage requires a shared backend that serves both persistent volume claims and VM datastores. Observability requires a unified platform that ingests metrics, logs, and traces from both environments. Undefined coexistence in any of these layers is the most common cause of migration stalls.
Q: Which VMware workloads should move to Kubernetes first?
A: Stateless APIs, microservices, CI/CD pipelines, and web-tier applications are the strongest candidates for early K8s migration. These workloads require minimal architectural surgery and establish the platform operationally under real production load before harder migration decisions are made. Stateful databases, legacy monoliths, and GPU workloads should be evaluated carefully and in many cases remain on VMware or follow a direct hypervisor migration path.
Q: How does Kubernetes help reduce Broadcom licensing exposure?
A: Every workload that migrates to Kubernetes removes VMs from the VMware estate, directly reducing the core count subject to Broadcom licensing. New workloads that land in K8s never enter the VMware licensing calculation at all. Over the 12-36 month migration window, the combination of workload migration and new workload routing to K8s can reduce Broadcom licensing exposure by 40-70% before the VM migration tracks are complete.
Q: What is the relationship between the K8s exit ramp and the Post-Broadcom Migration Series?
A: The K8s exit ramp and the Post-Broadcom Migration Series are parallel tracks, not alternatives. The series covers VM-to-AHV migration physics for workloads that cannot or should not be containerized. The K8s exit ramp covers the containerizable portion of the estate. Most enterprise VMware exits require both tracks running simultaneously against the same Broadcom licensing deadline.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




