Migration Stutter: Handling High-I/O Cutovers Without Data Loss
Every VMware exit plan eventually reaches the same moment: the maintenance window.
Licensing debates are finished. Procurement decisions are made. The architecture has been redesigned on paper. Now the migration plan meets the physics of the production system — the same system constraints covered in the Virtualization Architecture.
This is where most migrations actually fail.
Not because the tooling breaks. Not because the hypervisor is unstable. But because the cutover window concentrates multiple layers of I/O activity into the same few minutes — replication bursts, storage placement, and controller mediation — all competing for the same fabric at the same time.
When that collision is not modeled correctly, the result is Migration Stutter.
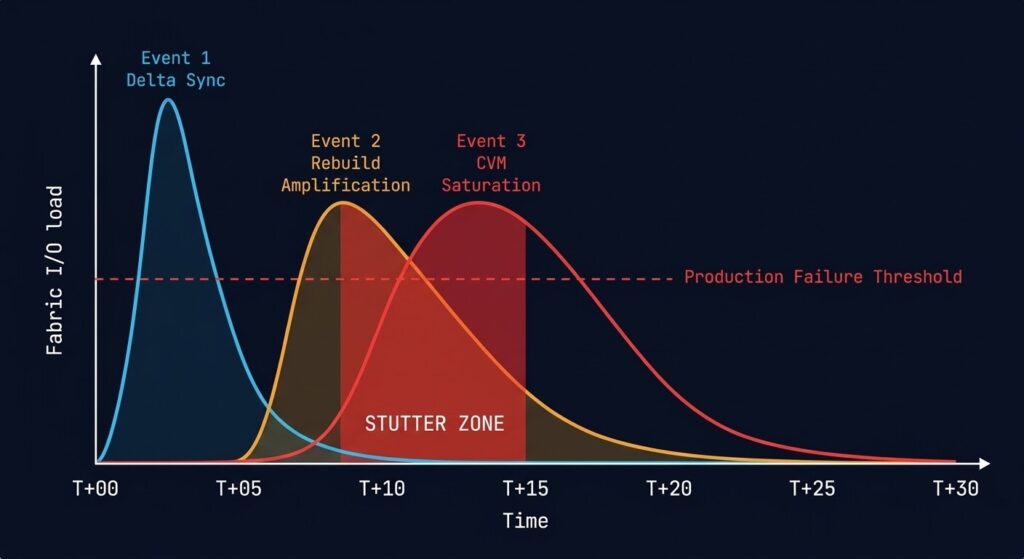
What Migration Stutter Actually Is
The term gets used loosely. Here is the precise definition for this series:
Migration Stutter is a sustained P99 storage latency event triggered during the final phase of a live migration cutover — specifically the interval between source VM quiesce and stable heartbeat confirmation on the target cluster. It occurs when replication surge traffic, distributed storage placement, and controller mediation all peak simultaneously on the same fabric.
It is distinct from a failed migration (tool error, VM won’t boot), post-migration performance degradation (CVM under-sizing, wrong vCPU allocation), or pre-migration replication lag (seed phase throttling, WAN bandwidth). Stutter happens in a narrow window — typically 2 to 15 minutes per VM batch — but it cascades across a wave if the fabric is not sized for the combined I/O load.
The tell is always the same: databases start logging lock timeouts. If you have already hit this in production, the Nutanix Migration Stutter: Why AHV Cutovers Freeze High-IO Workloads covers the immediate recovery steps — this post covers how to prevent it from happening. Application health checks begin failing intermittently. The monitoring dashboard shows CPU and memory as healthy while storage latency is quietly spiking to 40–80ms — 8 to 16x the baseline.
The Three I/O Events
Migration Stutter is not caused by a single failure. It is caused by three predictable I/O events colliding inside the same cutover window. Each is manageable in isolation. Together, they create the conditions for a P99 latency spike that production workloads cannot absorb.
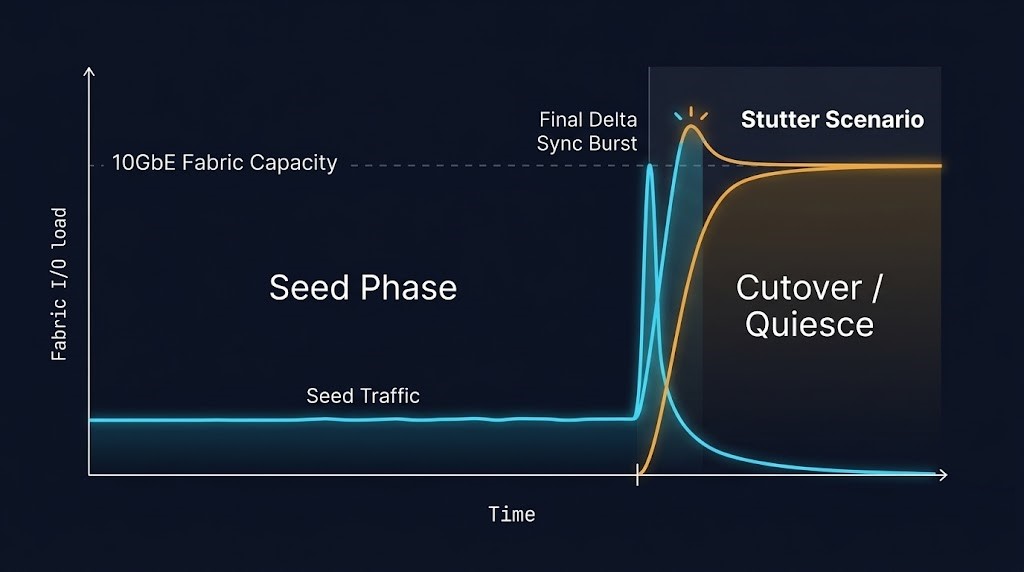
Event 1: Final Delta Sync — The Replication Surge
Nutanix Move operates on a continuous replication model during the seed phase. The source VM stays live, Move tracks dirty pages, and the delta is continuously synchronized to the target. This keeps the final cutover window short — in theory.
In practice, the delta sync surge happens when you initiate cutover on a high-write workload. The source VM is quiesced, Move performs a final pass to replicate all dirty pages written since the last sync cycle, and the replication traffic hits the network in a burst.
A database VM with 100GB of active working set and a moderate write rate of 50MB/s will accumulate roughly 3GB of dirty pages in a 60-second sync interval. At cutover, that 3GB must replicate across the fabric before the target VM can boot. On a 10GbE East-West fabric shared with production traffic, this is a concentrated burst — and something else is always competing for that bandwidth.
Use the Kadence code block for these metric names:
nutanix_move_replication_lag_seconds
nutanix_cluster_storage_io_bandwidth_MBps
Event 2: Storage Rebuild Amplification
This is the event most architects miss entirely in the migration plan.
When a VM is migrated to AHV, Nutanix AOS places its vDisk on the distributed storage fabric according to the current data placement policy — typically RF2 (Replication Factor 2), which means every write creates two copies across different nodes. During a migration wave, you are not just moving VMs. You are simultaneously writing new vDisk data, triggering AOS data placement and rebalancing, and potentially triggering rebuild traffic if any node is under pressure.
The rebuild amplification multiplier is typically 2x the raw migration I/O. On a 4-node cluster migrating a 500GB VM, the effective fabric traffic is approximately 1TB — not 500GB — plus whatever rebalancing AOS triggers to maintain data locality.
nutanix_cluster_storage_rebuild_io_bandwidth_MBps
nutanix_node_storage_controller_avg_io_latency_usec
Hidden Constraint: Queue Depth Collapse
High-I/O migrations rarely fail because bandwidth is exhausted. They fail because queue depth collapses inside the storage controller layer.
Every replication write, rebuild write, and production write must enter the same storage queue before the CVM can process it. As queue depth rises, write acknowledgement latency increases even if the network fabric itself is not saturated. This is why monitoring bandwidth alone misses the early warning signal — the full I/O modeling methodology is covered in the Performance Monitoring Learning Path.
For teams earlier in the decision process — still evaluating whether Nutanix is the right migration destination — the operational constraints that make this kind of cutover complexity real are covered in Proxmox vs Nutanix vs VMware: The Post-Broadcom Constraints No One Explains.
nutanix_storage_controller_outstanding_io
Event 3: CVM I/O Mediation — The Tax at Scale
Part 02 of this series covered CVM sizing under steady-state production load. At cutover, the CVM tax becomes acute in a way that steady-state operation does not expose.
Every I/O during the migration window — replication traffic, rebuild traffic, and production VM I/O — passes through the CVM on each node. Under normal production load, a correctly sized CVM handles this without noticeable overhead. During a migration wave, the CVM is simultaneously processing production I/O, accepting inbound replication traffic from Move, managing rebuild I/O from new vDisk placements, and handling metadata operations for newly created vDisks.
The CVM CPU and memory footprint scales with I/O depth. A CVM running at 60% CPU under normal production load will hit 95%+ during a migration wave on the same node — and at that threshold, write acknowledgement latency begins to climb.
The cascade is always the same: CVM latency → storage write latency → application write timeout → database transaction rollback → application error log fills up → on-call gets paged → everyone blames the network.
nutanix_cvm_cpu_usage_percent — per node, alert at >80%
nutanix_storage_controller_timeouts_count — any non-zero value is a warning
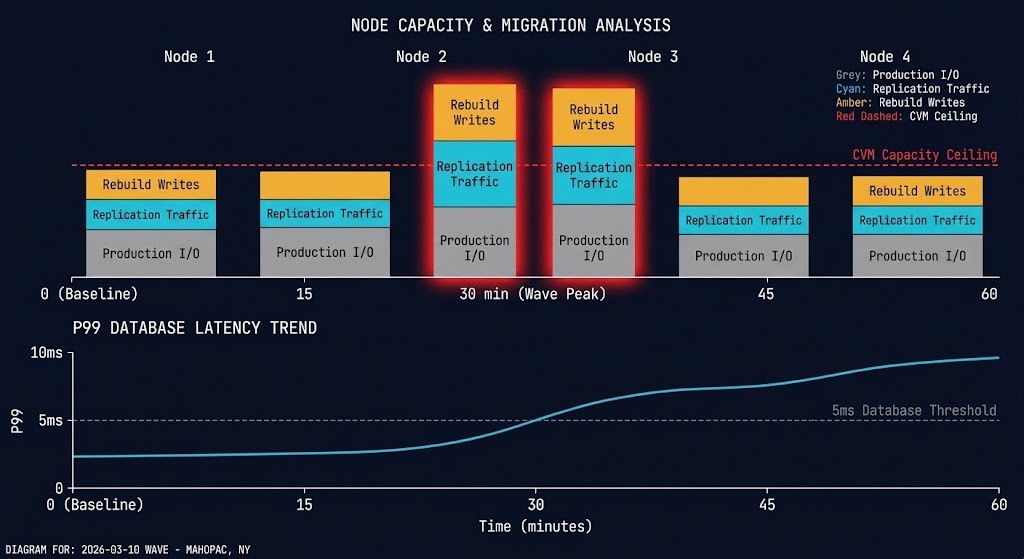
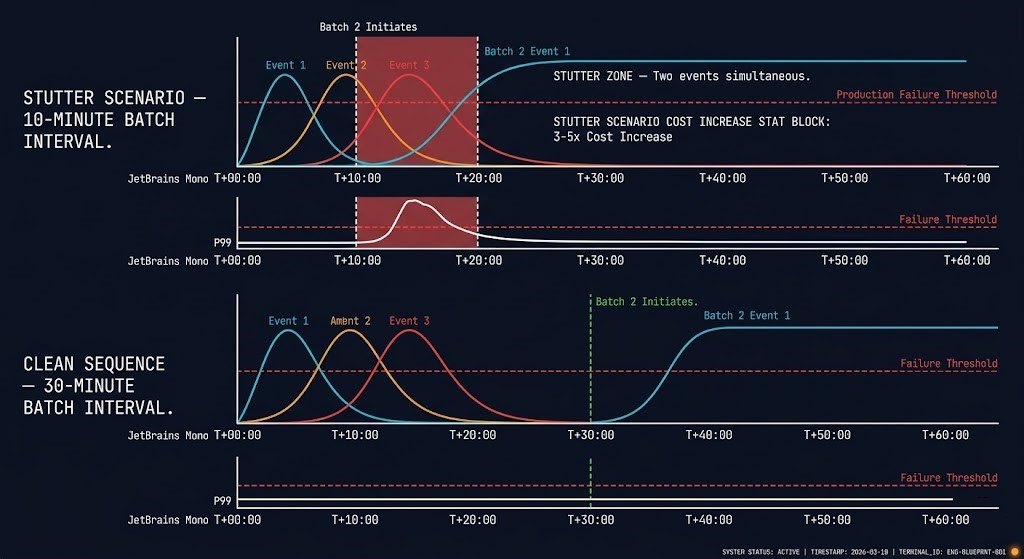
The Sequencing Model
The three events are not independent — they cascade in a specific order that determines whether your window holds or breaks.
This is the clean sequence on a correctly sized cluster running a single VM batch. The minimum safe interval between batches is T+30:00 — when the fabric has fully cleared from the previous wave.
Most migration plans run batches every 10–15 minutes to stay on schedule. At T+10:00, Event 3 from batch 1 is still peaking when Event 1 from batch 2 begins. The fabric carries both simultaneously. The CVM has no headroom. Latency climbs.
Never allow more than one of the three migration events to peak simultaneously.
The sequencing discipline that prevents stutter during cutover assumes the source environment is clean. VMware architects migrating to Proxmox face a compounding risk: operating model assumptions about snapshot behavior and storage semantics that pass pre-flight audit and add latency inside the cutover window itself. The Proxmox Migration Assumptions That Break at Cutover documents the assumption layer that interacts with Event 1 and Event 2 timing on the Proxmox path.
Pre-Cutover Checklist
The checklist below assumes the workload inventory is accurate and the integration surface around each VM is known. In practice, VMware estates accumulate licensing dependencies, integration hooks, and platform behavioral assumptions that don’t appear in vCenter’s configuration state. A VM that looks like a standalone application workload may have undocumented storage policy dependencies or backup integration hooks that affect which batch it belongs in and what its RTO actually is. VMware Licensing Pressure Created a Dependency Audit Problem is where that surface gets recovered before the migration window opens.
Before the maintenance window opens, verify each of the following. These are not optional — they are the conditions under which the T+30:00 sequencing model holds.
acli host.list | grep -i bandwidth ncli host list | grep -i "cvm"
ncli pd list | grep -i rebuild
allssh "top -bn1 | head -5"
CVM CPU threshold to pause wave: 80%
Maximum window extension before escalation: ___ minutes
The Stutter Recovery Protocol
If stutter occurs during the window, the recovery sequence matters as much as the diagnosis. These steps are ordered — do not skip ahead.
Do not initiate the next batch. The instinct is to push through to stay on schedule — resist it. More batches compound the I/O pile-up. The wave pauses. The window extends. That is acceptable. A data consistency incident is not.
Use Kadence code block for these commands:
ncli cluster get-dom-fault-tolerance-state type=node
allssh “top -bn1 | head -5”
ncli pd list | grep -i rebuild
This is the hardest step operationally. The bridge call has stakeholders. The window is burning. Wait anyway. Forcing the next batch before the fabric clears is how a manageable latency event becomes a data consistency incident.
If the wave was running 10 VMs per batch, drop to 5. Rebuild the cadence from a smaller base. The window extends, but the wave completes cleanly.
Every stutter event has a root cause in pre-migration sizing. After the window closes, identify which of the three events was primary and update the migration plan for subsequent waves. The second wave should never stutter the same way.
The Connection to Part 02
Part 02 covered CVM sizing under steady-state production load. The cutover window is not steady-state — it is a burst event that temporarily doubles or triples the I/O demand on the CVM and the storage fabric.
The sizing models from Part 02 give you the production baseline. The multipliers in this post — 2x rebuild amplification, Event 3 CVM saturation ceiling — give you the migration burst model. What happens after the window closes — the operational reorientation, runbook audit, and monitoring recalibration that AHV requires — is covered in Nutanix AHV Operations: What Changes After VMware Migration.
The combined rule: Size the CVM for production load plus 60%. That 60% headroom is what absorbs the migration wave without stutter. If Part 02’s sizing model left you with a CVM at 70–80% CPU under production load, you do not have migration headroom. Fix the sizing before the migration window opens — not during it.
When a migration cutover takes production down and recovery means pulling from cloud object storage — do you know what that restore actually costs and how long it takes? Model egress fees and transfer time before the event, not during it.
>_ Model Your Recovery CostWhat Part 04 Covers
The I/O events in this post assume the storage and compute layers are the primary risk during cutover. They usually are. But the most operationally complex cutover failures happen one layer up: policy translation.
VMware DRS affinity rules, SRM failover policies, and NSX-T micro-segmentation logic do not port automatically to Nutanix Flow. Part 04 maps the translation physics — where policies carry over cleanly, where they require re-architecture, and where the gaps in translation create security exposure that doesn’t surface until the first DR test post-migration.
>_ Subscribe via The Dispatch to be notified when Part 04 publishes.
You know the risk of carrying forward architectural debt. Now, we tear down the mechanics. Track the series below as we map the exact physical changes required for a deterministic migration.
Skip the wait. Download the complete Deterministic Migration Playbook (including the Nutanix Metro Cluster Implementation Checklist) and get actionable engineering guides delivered via The Dispatch.
SEND THE BLUEPRINTAdditional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session