Operating Gateway API in Production: What the Migration Guides Don’t Cover

You migrated. Traffic is flowing. ReferenceGrants are in place. The controller reconciliation loop is clean. And then — quietly, without a single alert firing — things start breaking in ways your observability stack was never built to see.
Most Gateway API migration guides end at cutover. That is the wrong place to stop. The real operational surface of gateway api production begins exactly where those guides close — and it is governed by a different set of failure physics than anything Ingress introduced.
The thesis of this post is explicit: Gateway API doesn’t just change how traffic is routed. It changes where routing failures live — and how invisible they become.
That single shift drives everything that follows: why your observability model needs rebuilding, why your policy stack has a new layer, and why the five failure modes most teams hit in the first 60 days of production don’t look like failures at all.
The Gap Nobody Talks About
Part 0 was the decision. Part 1 was the shift. Part 2 was the migration. Part 3 is the reality.
When you ran Ingress, failures were infrastructure-visible. A misconfigured annotation broke routing and your logs showed it. A missing backend returned a 502 and your alerting fired. The failure surface was shallow and legible — it lived in the same layer as your existing monitoring stack.
Gateway API moves routing failures into the decision layer. HTTPRoutes can be accepted by the controller — syntactically valid, status condition green — while silently misrouting traffic. ReferenceGrants can be deleted during a routine namespace cleanup with no downstream alert. Header matching logic from the annotation era doesn’t translate 1:1, and the mismatch produces no error. It just routes incorrectly.
This is not a tooling gap. It is an architectural one. Your monitoring didn’t miss these incidents — it was never designed to see the layer where they happen.
Observability: What Changes After Gateway API
Ingress failures were infrastructure-visible. Gateway API failures are decision-layer invisible. That is the framing shift every platform team needs to internalize before they instrument anything.
Understanding what your monitoring stack actually covers requires mapping it against three distinct layers.
Layer 1 — Controller Metrics (What You Get)
Standard Prometheus scraping covers the controller layer. You get reconciliation loop latency, controller health, memory and CPU, and whether the controller is processing resources at all. This is the layer most teams think of as “Gateway API observability” — and it is the least useful layer for diagnosing production routing failures. A healthy controller reconciliation loop tells you nothing about whether the routing decision it produced is correct.
Layer 2 — Spec State (What You Miss)
HTTPRoute status fields are not surfaced by default in most monitoring stacks. The conditions you need to be watching — Accepted, ResolvedRefs, Parents — exist in the Kubernetes API but require explicit instrumentation to reach your dashboards. This is the layer where silent failures live. A route in Accepted: True with a backend in ResolvedRefs: False will route requests to nothing — and your controller metrics will show green the entire time.
Layer 3 — Runtime Behavior (What Actually Matters)
Routing outcomes, backend selection, header and path matching decisions — this is the layer that determines whether a request reaches the right destination. 200 OK is the new 500: a request that returns a success status from the wrong backend is operationally identical to a silent outage. Runtime behavior requires traffic-level instrumentation — service mesh telemetry, eBPF-based flow data, or access log enrichment — to become visible.
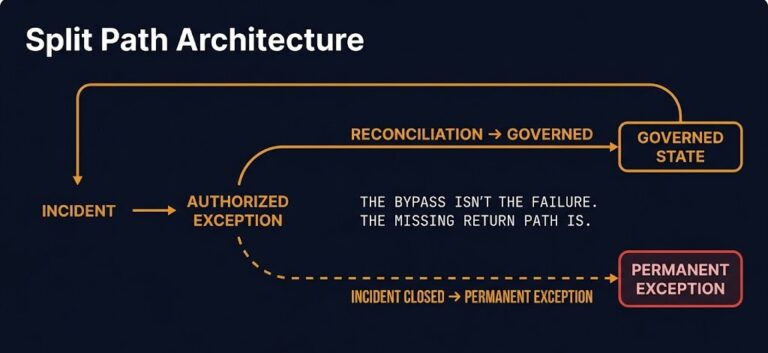
Your monitoring stack sees the controller. It does not see the routing decision.
The fix is not a new tool. It is a new instrumentation philosophy. Instrument HTTPRoute status conditions into your alerting. Build dashboards around ResolvedRefs failures, not just controller health. Add traffic-level observability at the Gateway boundary using service mesh or eBPF-based data plane telemetry. Treat routing decisions as first-class observable events — not implementation details beneath the monitoring surface.
Policy Enforcement at the Gateway Layer
Gateway API introduces routing-level trust boundaries, not just network boundaries. That is a category shift in what your policy stack needs to cover — and most teams don’t model it until something breaks.
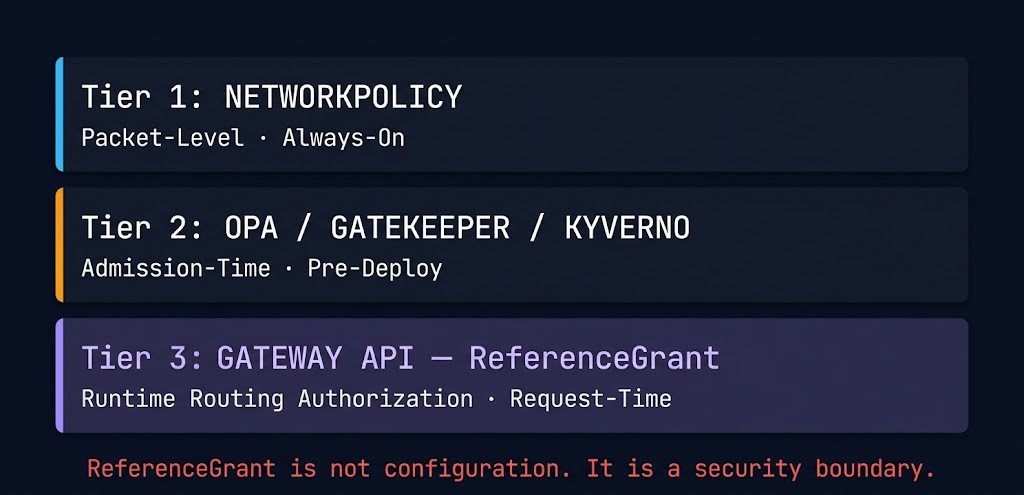
The real shift is temporal. Your existing policy layers operate at different enforcement windows:
ReferenceGrant is not configuration. It is a security boundary. A ReferenceGrant deletion — which can happen silently during namespace cleanup, RBAC rotation, or automated resource pruning — immediately collapses cross-namespace routing trust. There is no deprecation window. There is no graceful degradation. Traffic stops reaching its backend, and the only signal is a ResolvedRefs: False condition that most teams aren’t alerting on yet.
The three policy failure modes that only surface post-migration: admission policies that validate HTTPRoute syntax but not routing intent; ReferenceGrant audits that don’t run continuously; and admission gaps where policy enforcement covers resource creation but not resource deletion. Container security architecture addresses the broader policy stack — Gateway API adds a new enforcement layer on top of it that needs its own audit cadence.
The Day-2 Failure Patterns
These are not edge cases. These are the failures teams discover in the first 30–60 days of gateway api production operations — after the migration post-mortems are written, the runbooks are filed, and the team has moved on to the next project.

Accepted: True means valid configuration — not correct behavior. Backend weight misconfiguration, path prefix overlap, or header match ordering errors produce accepted routes that route to the wrong destination. No alerts fire. No errors surface. Traffic just goes somewhere wrong.ResolvedRefs: False and traffic stops. Recovery requires manual ReferenceGrant reconstruction.Multi-Cluster and Multi-Tenant Considerations
Gateway API simplifies single-cluster routing. It complicates multi-cluster ownership. That is not a criticism — it is an architectural reality that needs to be modeled before you scale.
The fundamental shift at multi-tenant scale: the problem is no longer routing. The problem is who is allowed to define routes. Gateway API’s role separation — infrastructure providers owning Gateways, application teams owning HTTPRoutes — creates a governance surface that didn’t exist with Ingress. A shared Gateway model requires explicit policy around which teams can attach routes to which Gateways, which namespaces can reference which backends via ReferenceGrant, and what happens when those boundaries are violated or accidentally deleted.
Gateway-per-team is the operationally cleaner model for most enterprises: each team owns their Gateway and HTTPRoutes within a namespace boundary, ReferenceGrant surface is minimal, and blast radius for misconfigurations is contained. The shared Gateway model reduces resource overhead but introduces a ReferenceGrant audit problem at scale — tracking which cross-namespace trust relationships exist, why they exist, and whether they are still valid becomes a non-trivial operational concern. Platform engineering architecture needs to own that audit function, not application teams.
Cross-cluster route federation remains experimental. The Gateway API spec is moving in this direction, but what is stable today is single-cluster. Multi-cluster Gateway API implementations are controller-specific, not spec-guaranteed — model them as beta operationally, regardless of what the controller documentation claims.
Kubernetes 1.36 — What Actually Changed
This matters only if you are tracking Gateway API spec evolution closely — most production clusters lag behind spec changes by one to three minor releases, which means many of the April 2026 experimental channel updates won’t be operationally relevant for most teams for months.
What is confirmed and relevant: the experimental channel continues to advance BackendLBPolicy and BackendTLSPolicy toward broader stability, and the ParentReference model received clarifications around attachment semantics that affect multi-Gateway deployments. If your controller has not been updated to track these changes, behavior between spec and implementation will diverge silently — which maps directly onto Failure Mode 04 above.
The operational constraint: pin your controller version to the Gateway API channel version it was built against. Cluster fleet management at scale needs to track this relationship explicitly — not assume that a Kubernetes version bump automatically advances your Gateway API implementation parity.
The Real Problem
Teams think they migrated an ingress layer. What they actually introduced is a new control plane.
This is the thread that runs through the entire series. The control plane shift isn’t a Gateway API phenomenon — it is the defining architectural pattern of this infrastructure era. Every layer that used to be configuration is now a control plane: service meshes, policy engines, GitOps operators, and now routing. Each one introduces a decision layer that sits above your existing monitoring surface and below your existing policy enforcement.
Gateway API’s routing model is well-designed. The spec is maturing correctly. The failure modes documented above are not flaws in the spec — they are the expected operational consequences of introducing a new control plane into a stack that wasn’t instrumented to see it. The teams that operate Gateway API well in production are not the ones with the best controllers. They are the ones that rebuilt their observability model before they needed it.
Gateway API doesn’t fail loudly. It fails in decisions your tooling doesn’t see.
Architect’s Verdict
Part 0 was the decision. Part 1 was the shift. Part 2 was the migration. Part 3 is the reality — and the reality is that Gateway API production operations require a fundamentally different observability model, a new policy enforcement layer, and an audit discipline that didn’t exist when you were running Ingress. The teams that operate this well aren’t the ones that migrated fastest. They’re the ones that rebuilt their instrumentation before they needed it.
- ✓ Treat Gateway API as a control plane layer — instrument routing decisions, not just traffic
- ✓ Alert on HTTPRoute status conditions —
ResolvedRefs: Falseis a production incident - ✓ Audit ReferenceGrants continuously — treat deletions as security boundary changes, not cleanup
- ✓ Pin controller versions to the Gateway API channel they implement — track skew explicitly
- ✓ Own the ReferenceGrant audit function at the platform engineering layer, not the application team layer
- ✗ Assume
Accepted: Truemeans working — it means syntactically valid configuration - ✗ Treat migration as completion — cutover is the start of the operational surface, not the end
- ✗ Let controller behavior drift from spec assumptions — reconciliation loop health is not routing correctness
- ✗ Port Ingress annotation logic directly to HTTPRoute without verifying match semantics
- ✗ Trust cross-cluster Gateway API federation claims without verifying your controller’s implementation channel
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session