INFRASTRUCTURE PERFORMANCE ARCHITECTURE
Modeling contention, latency amplification, and failure-state headroom before production exposes them
SPECIALIZATION TRACK — INFRASTRUCTURE PERFORMANCE ARCHITECTURE
- Track Discipline: How to model the interaction surfaces between CPU scheduling, memory pressure, storage amplification, and network determinism to predict whether infrastructure will remain inside its Performance Survivability Envelope under load, failure, and recovery conditions.
- Primary Architectural Tension: Steady-state utilization efficiency (density and cost) vs. failure-state headroom (the reserve capacity required to absorb N+1 failure without violating workload latency expectations).
- Architectural Boundary: Does not govern application-layer performance tuning, vendor sizing calculator configuration, or observability tooling setup — those inherit from the architectural model this Track builds.
- Domain Path Relationship: Deepens Stages 2–4 of the Virtualization Architecture Path — the scheduling, memory, and storage mechanics the Domain Path introduces but does not model as a coupled system under failure-state conditions.
- Who This Track Is For: You’re responsible for predicting infrastructure behavior, not just reacting to it. Your dashboards show green. Your users report slow. Your cluster looks healthy at 40% CPU utilization — until a host fails and you discover the headroom model was a utilization target, not a survivability calculation.
Performance modeling in enterprise virtualization is the discipline of treating infrastructure as a coupled system — not a collection of independently monitored components. CPU scheduling fairness, memory locality, storage write amplification, and network determinism do not fail independently. They interact. Increase replication factor and you increase CPU overhead. Increase scheduler contention and you amplify tail latency. Reduce headroom and every failure becomes nonlinear. Performance modeling is the architectural practice of understanding those interactions before production exposes them.
Specialization Tracks deepen specific architectural disciplines across multiple maturity stages without replacing the progression logic of the Domain Path itself. The Virtualization Architecture Path covers the mechanics of scheduling, memory, storage, and networking across Stages 2 through 4 — each layer treated at its own maturity depth. What it does not model is how those layers couple under contention and failure-state conditions, or how headroom collapses when a host fails and load redistribution forces the platform beyond its validated operating boundary. That coupling is what this Track exists to model.
>_ WHY THIS TRACK EXISTS
Infrastructure performance is governed by interacting constraints rather than isolated metrics. The question every architecture decision must answer is: Does this move the platform outside its Performance Survivability Envelope?
FRAMEWORK #110 — PERFORMANCE SURVIVABILITY ENVELOPE
The Performance Survivability Envelope is the operating boundary within which infrastructure can absorb contention, failure, resource redistribution, and recovery activity without violating workload latency expectations.
When that boundary is poorly modeled, clusters appear healthy until a failure, migration event, or contention spike forces the platform beyond its ability to recover predictably.
The Domain Path introduces the mechanics of scheduling, memory, storage, and networking, but it does not model how those systems interact under failure-state conditions — where contention cascades, headroom collapses, and latency amplification makes the platform unpredictable.
This Track exists to define, measure, and validate the Performance Survivability Envelope before production becomes the testing environment.
WHAT THIS TRACK IS NOT
01 — NOT A PERFORMANCE MONITORING GUIDE
This Track does not cover alert threshold configuration, dashboard setup, or observability tooling — it builds the architectural model that makes observability meaningful: without a performance model, dashboards are forensic instruments, not predictive ones.
02 — NOT VENDOR SIZING CALCULATOR TRAINING
Vendor sizing tools approximate the physics this Track models explicitly — this Track builds the underlying architectural understanding that allows you to validate, challenge, and extend those tools rather than rely on them as black boxes.
03 — NOT APPLICATION-LAYER PERFORMANCE TUNING
This Track ends at the hypervisor and fabric layer — application-layer optimization, database tuning, and runtime performance engineering inherit from the infrastructure model this Track builds, but are outside its scope.
04 — NOT THE COMPUTE ARCHITECTURE TRACK
The Compute Architecture Track covers scheduling mechanics, NUMA topology, and vCPU sizing decisions at the hypervisor layer — this Track models how those mechanics couple with memory, storage, and network under load to produce system-level performance behavior inside or outside the Performance Survivability Envelope.
INFRASTRUCTURE PERFORMANCE ARCHITECTURE — READING SCOPE
| Scope | Coverage | Estimated Time |
|---|---|---|
| Core Reading Sequence | Clusters 1–3: Infrastructure as a Coupled System, Contention Physics & Locality, Constraint Cascades — the foundational interaction model and the failure modes that emerge from it | ~2–3 hr |
| Full Track | All 5 clusters — includes Performance Survivability Envelope modeling and Deterministic Validation & Operational Governance | ~4–6 hr |
>_ WHERE TO ENTER THIS TRACK
Start at Cluster 01 if infrastructure performance problems in your environment surface as surprises — dashboards showing healthy utilization while users report degraded application behavior, and no architectural model to explain the gap. The coupled-system frame this Track builds is the prerequisite for everything in Clusters 03 through 05.
You can likely skip to Cluster 03 if all three of the following apply:
- You can diagnose the difference between CPU Ready and CPU Wait, and have modeled NUMA boundary exposure per workload before placement
- You have debugged a memory reclamation cascade — ballooning through to compression or swap — in a production environment
- You have sized at least one cluster for rebuild-state capacity rather than steady-state utilization targets
If any of those require translation, start at Cluster 01. The constraint cascade and survivability envelope concepts in Clusters 03 and 04 build directly on the coupled-system vocabulary established in the first two clusters.
>_ READING SEQUENCE
Each cluster below is organized by architectural problem. Every cluster answers: what becomes architecturally unstable if this discipline is misunderstood?
Why Does Infrastructure Fail When Utilization Looks Healthy?
Performance is not a metric — it is a function. CPU scheduling, memory locality, storage amplification, and network determinism are not independent systems that fail independently. They interact. The gap between what dashboards report and what users experience is the entire subject of this Track — and closing that gap starts with the coupled-system model this cluster establishes.
Where Does Scheduler Contention Begin Pushing Latency Outside the Envelope?
Scheduler contention and NUMA boundary exposure amplify tail latency in ways that average utilization metrics never surface. A cluster can report 40% CPU utilization while individual VMs are experiencing scheduler starvation — because utilization measures what was consumed, not how long workloads waited to consume it. This cluster models the contention signals that precede envelope violation.
When Does Pressure in One Subsystem Become Failure in Another?
Constraint cascades occur when pressure in one subsystem propagates into another. Memory reclamation becomes scheduler delay. Write amplification becomes network congestion. Storage recovery becomes compute contention. These cascades are invisible in per-component dashboards — they are only visible in the coupled-system model. This cluster is where the Performance Survivability Envelope begins to compress.
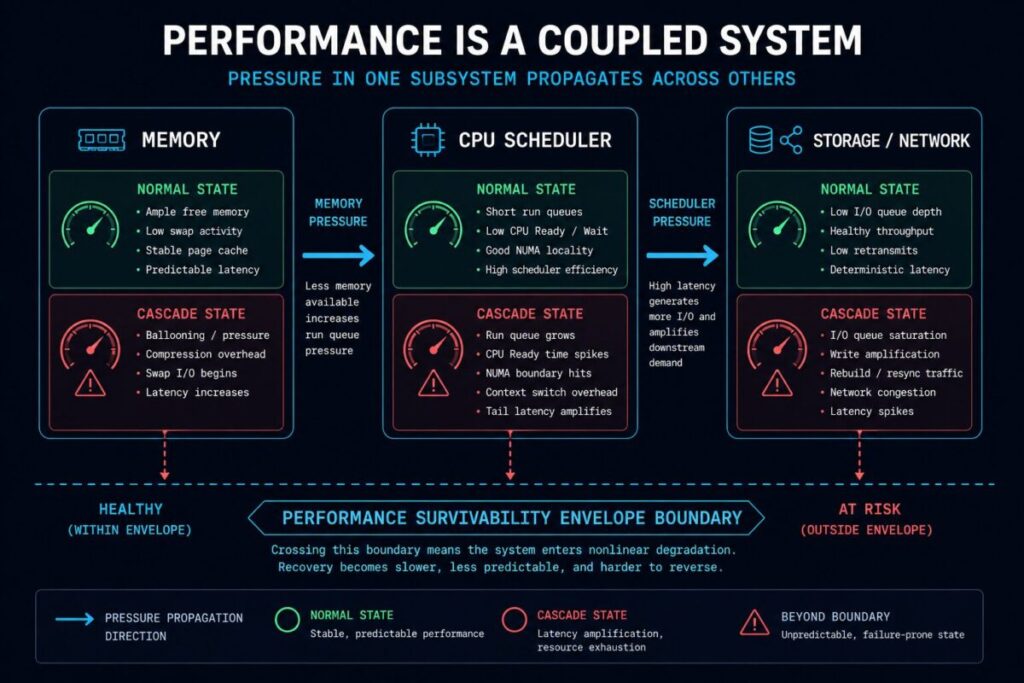
What Happens to the Platform When Failure Forces It Outside the Envelope?
Most infrastructure is sized against steady-state utilization rather than the Performance Survivability Envelope — the resource condition entered during host failures, rebuild activity, migration bursts, and maintenance events. Headroom is not unused capacity — it is the reserve required to keep the platform inside its envelope when something fails. Does this move the platform outside its Performance Survivability Envelope? This cluster is where that question gets a quantitative answer.
How Do You Confirm the Platform Remains Inside Its Validated Envelope?
Modeling predicts. Observability confirms. Without both, you are either guessing or reacting. The governance question at this cluster is whether your operational practice validates the performance model continuously — or only discovers that the envelope was wrong when production makes the case for you. This is where observability, deterministic operations, and performance governance converge.
>_ TRACK FAILURE PATTERNS
Six failure patterns that emerge when infrastructure performance is managed at Domain Path breadth without Track-level modeling depth.
| Failure Pattern | Architectural Consequence |
|---|---|
| Sizing clusters for average utilization, not failure-state headroom | A single host failure redistributes load across surviving nodes — if headroom was sized for steady state, N+1 failure triggers nonlinear performance degradation that no dashboard predicted |
| Treating CPU utilization percentage as a scheduling health signal | Run queue depth, CPU Ready time, and NUMA boundary crossings are the actual contention signals — utilization percentage measures what was consumed, not how long workloads waited to consume it |
| Modeling memory capacity without modeling the reclamation escalation path | Ballooning is recoverable; compression is a warning; swap failure is a performance event — the escalation happens faster than monitoring intervals under burst workloads, and each stage introduces scheduler delay |
| Treating write amplification as a storage-only concern | Replication overhead consumes CPU cycles and east-west bandwidth simultaneously — storage write amplification is a coupled-system constraint that propagates into scheduler contention and network saturation |
| Treating observability as a substitute for a performance model | Dashboards confirm what failed after it failed — without a performance model, observability is forensic, not predictive; the Performance Survivability Envelope cannot be validated by monitoring alone |
| Treating headroom as unused capacity | Recovery, rebuild, and migration activity consume the reserved capacity — infrastructure that appears over-provisioned at steady state is frequently under-provisioned for the failure conditions that force it beyond its Performance Survivability Envelope |
>_ CROSS-TRACK DEPENDENCIES
Tracks share foundational mechanics across disciplines. Understanding which Tracks compound with this one prevents siloed architectural analysis.
| Depends On | Dependency Direction | Why It Matters |
|---|---|---|
| Compute Architecture Track | Upstream Constraint | Scheduler mechanics, NUMA topology, and vCPU sizing decisions are the foundational inputs — the Performance Survivability Envelope inherits those architectural choices as its primary constraint set |
| Storage Architecture Track | Upstream Constraint | Storage policy decisions, replication factor, data locality health, and the Storage Survivability Boundary are primary inputs to failure-state performance modeling — storage is where constraint cascades most commonly originate |
| Networking Architecture Track | Upstream Constraint | East-west bandwidth capacity and fabric determinism set the ceiling on write amplification absorption, rebuild recovery speed, and the network component of constraint cascade propagation |
| HCI Architecture Track | Upstream Constraint | The HCI convergence model and node sizing determine the failure-state headroom envelope — the Performance Survivability Envelope is applied to the platform the HCI architecture defines |
| Migration Strategy Track | Bidirectional | Migration execution is one of the fastest ways to force infrastructure beyond its modeled Performance Survivability Envelope — cutover sequencing, write amplification bursts, and post-migration stability validation all depend on the headroom model this Track builds |
| Virtualization Architecture Path | Domain Path Parent | The Domain Path introduces scheduling, memory, storage, and networking mechanics across Stages 2–4 — this Track models how those mechanics interact as a coupled system under failure-state conditions |
>_ TRACK GRADUATES CAN NOW
Infrastructure performance modeling at Track depth means the Performance Survivability Envelope is an explicit, calculated boundary — not an assumption derived from utilization averages. The shift is from reactive diagnostics to deterministic infrastructure: the question “Does this move the platform outside its Performance Survivability Envelope?” now has an answer before production tests it.
- Model CPU scheduling contention and NUMA boundary exposure as a placement constraint, not a post-deployment diagnostic
- Diagnose constraint cascades from the first subsystem pressure signal — before memory reclamation escalates or write amplification propagates into scheduler contention
- Size clusters for failure-state headroom — N+1 and N+2 capacity requirements — with a quantitative model rather than a utilization-based estimate
- Validate migration architecture against the Performance Survivability Envelope before cutover — execution physics must be modeled, not discovered during rollback
- Apply the performance model as a governance gate for infrastructure decisions — any change that compresses headroom or introduces new coupling surfaces must answer the envelope question first
>_ WHERE DO YOU GO FROM HERE
YOUR HEADROOM MODEL IS AN ASSUMPTION — NOT A CALCULATION
Every infrastructure platform has a Performance Survivability Envelope. The Infrastructure Architecture Review surfaces where yours sits — and whether your current scheduler headroom, memory capacity model, and failure-state reserve actually keep the platform inside its validated boundary when something fails.
Infrastructure Architecture Review
An architectural review of your performance survivability posture — failure-state headroom, scheduler contention exposure, and whether your platform’s coupled-system constraints are modeled or assumed.
- > Performance Survivability Envelope assessment
- > Failure-state headroom validation
- > Scheduler contention and NUMA exposure review
- > Constraint cascade analysis across CPU, storage, and fabric
Architecture Playbooks. Field-Tested Blueprints.
Field-tested blueprints for infrastructure performance architecture — envelope modeling, constraint cascade analysis, and the headroom calculations that determine whether your platform survives what it’s eventually going to face.
- > Performance Survivability Envelope modeling
- > Failure-state headroom calculations
- > Constraint cascade identification and intervention points
- > Deterministic validation against the coupled-system model
Zero spam. Unsubscribe anytime.
>_ FREQUENTLY ASKED QUESTIONS
Q: What is performance modeling in enterprise virtualization?
A: Performance modeling in enterprise virtualization is the discipline of treating infrastructure as a coupled system and predicting its behavior under load and failure conditions — before production provides the answer. The architectural problem it solves is that CPU scheduling, memory pressure, storage amplification, and network determinism interact. A platform can appear healthy across every individual component metric while approaching the boundary of its Performance Survivability Envelope. Modeling those interactions is what closes the gap between what dashboards report and what users experience.
Q: How does the Infrastructure Performance Architecture Track differ from the Compute Architecture Track?
A: The Compute Architecture Track covers scheduling mechanics, NUMA topology, and vCPU sizing decisions at the hypervisor layer — it governs how the compute substrate is configured. The Infrastructure Performance Architecture Track models how those decisions couple with memory, storage, and network under load to produce system-level performance behavior. Compute architecture is an upstream constraint for performance modeling; they are not redundant — one governs configuration, the other governs survivability prediction.
Q: What is the Performance Survivability Envelope and why does it matter more than utilization targets?
A: The Performance Survivability Envelope is the operating boundary within which infrastructure can absorb contention, failure, resource redistribution, and recovery activity without violating workload latency expectations. Utilization targets describe steady-state resource consumption. The Envelope describes failure-state capacity — the reserve required when a host fails and load redistributes across surviving nodes. Most clusters are sized against utilization. The ones that survive failures cleanly are sized against the Envelope.
Q: What is a constraint cascade and what makes it architecturally dangerous?
A: A constraint cascade occurs when pressure in one subsystem propagates into another: memory reclamation introduces scheduler delay, write amplification saturates east-west fabric, storage rebuild consumes the CPU cycles that VM scheduling needs. What makes cascades architecturally dangerous is that they are invisible in per-component dashboards — each component may still show acceptable individual metrics while the platform as a system is moving toward its Performance Survivability Envelope boundary. They are only visible in the coupled-system model.
Q: What breaks architecturally when headroom is treated as unused capacity?
A: Recovery, rebuild, and migration activity consume the capacity that appears unused at steady state. A cluster sized at 70% average utilization may have almost no headroom for a host failure — because N+1 failure means the remaining nodes must absorb 100% of the failed node’s load, plus ongoing rebuild traffic. Infrastructure that appears over-provisioned during normal operations is frequently under-provisioned for the specific failure conditions that test the Performance Survivability Envelope.
>_ RELATED SYSTEMS
The full virtualization pillar — hypervisor architecture, platform decision frameworks, and the operational architecture that the Performance Survivability Envelope governs.
Open Pillar →Deterministic Platform Operations — the Domain Path governance layer where lifecycle management and operational discipline maintain the infrastructure inside its validated performance envelope over time.
Open Stage →The upstream constraint set for performance modeling — NUMA topology, vCPU sizing, and scheduler mechanics are the architectural decisions the Performance Survivability Envelope is applied against.
Open Track →RTO architecture inherits from the same failure-state headroom constraints that define the Performance Survivability Envelope — recovery time and survivability are governed by the same underlying physics.
Open Domain Path →VMware vSphere Resource Management documentation — primary engineering reference for CPU scheduler mechanics, memory reclamation hierarchy, and NUMA topology behavior in vSphere environments.
Open Reference →The Nutanix Bible — CVM Sizing and Performance sections. Primary engineering documentation on controller resource allocation, data locality physics, and HCI performance behavior under load.
Open Reference →