VIRTUAL STORAGE ARCHITECTURE
Survivability boundaries, failure domain modeling, and distributed fabric physics for virtualized storage platforms
SPECIALIZATION TRACK — VIRTUAL STORAGE ARCHITECTURE
- Track Discipline: How storage architecture decisions establish failure domain boundaries, govern distributed survivability, and determine whether a platform can absorb component failure without violating workload assumptions.
- Primary Architectural Tension: Data locality (read performance and I/O predictability) vs. distributed replication (fault tolerance and rebuild capacity).
- Architectural Boundary: Does not govern data protection schedules, backup platform selection, RPO/RTO engineering, or recovery SLA design — those belong to the Data Protection & Resiliency domain.
- Domain Path Relationship: Deepens Stages 2–4 of the Virtualization Architecture Path — Control Plane Architecture through Deterministic Platform Operations.
- Who This Track Is For: You’re sizing or re-architecting storage for a platform migration, hybrid HCI/SAN environment, or AI workload staging cluster — and the failure modes you’re encountering aren’t in the vendor playbook.
Storage architecture in virtualized infrastructure is fundamentally a failure domain problem. Every decision — which SDS platform, which replication factor, whether to converge compute and storage or disaggregate them — establishes boundaries that determine how far a component failure propagates before it becomes a cluster event. Those boundaries are set during design. They are not correctable at 2am during a rebuild storm.
Specialization Tracks deepen specific architectural disciplines across multiple maturity stages without replacing the progression logic of the Domain Path itself. The Virtualization Architecture Path addresses storage as an integration concern through Stages 2 and 3 — covering how storage connects to the hypervisor and fabric layer. That treatment is correct for its maturity scope, but it does not model the replication economics, locality degradation curves, or rebuild penalty arithmetic that determine whether a platform survives production failure at scale. That depth is what this Track provides.
>_ WHY THIS TRACK EXISTS
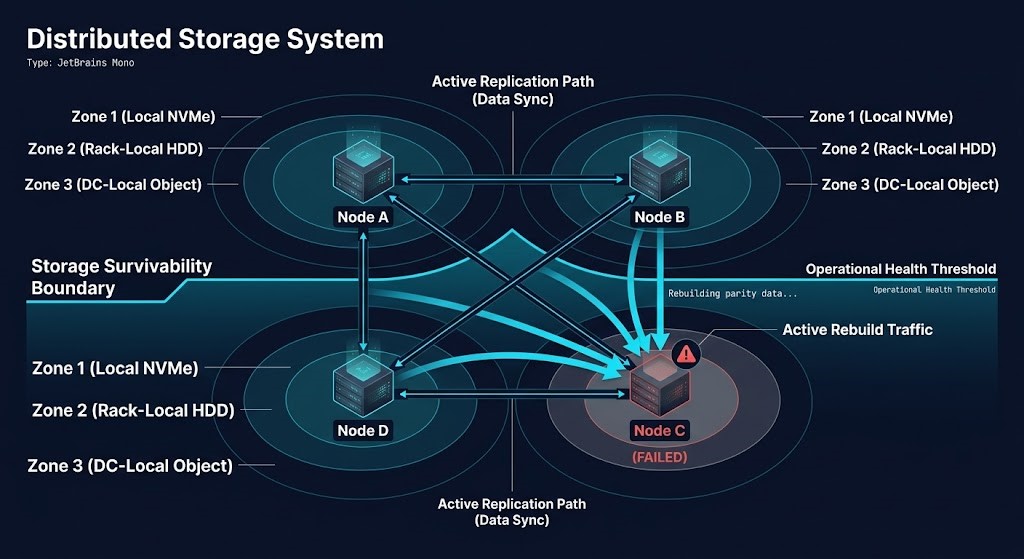
Storage architecture decisions establish the Storage Survivability Boundary long before a workload enters production.
FRAMEWORK #109 — STORAGE SURVIVABILITY BOUNDARY
The Storage Survivability Boundary is the point at which a storage architecture can no longer absorb component failure, rebuild activity, or locality degradation without violating workload performance or availability assumptions.
When that boundary is poorly modeled, storage failures propagate beyond the storage layer and become cluster instability events.
The Virtualization Domain Path introduces storage integration as an architectural concern, but it does not model rebuild penalties, locality degradation, replication overhead, or failure-domain survivability at operational depth.
This Track exists to define, measure, and govern the Storage Survivability Boundary across converged and disaggregated storage architectures.
WHAT THIS TRACK IS NOT
01 — NOT VENDOR STORAGE TRAINING
This Track covers the architectural problem that exists beneath every SDS platform — failure domain design, survivability modeling, and replication economics — not vSAN feature sets or Nutanix DSF configuration guides.
02 — NOT A STORAGE ADMINISTRATION GUIDE
This Track does not cover LUN provisioning, RAID set configuration, or HBA tuning — it covers the tradeoffs, failure domain consequences, and survivability arithmetic that those operational decisions produce at scale.
03 — NOT THE DATA PROTECTION & RESILIENCY TRACK
Data Protection governs backup architecture, immutability policy, and RPO/RTO engineering — this Track ends where backup policy begins; its concern is the survivability of the storage fabric itself, not the recovery workflows built on top of it.
04 — NOT CLOUD OR OBJECT STORAGE ARCHITECTURE
This Track governs virtualization-layer storage — the distributed fabric that hypervisors sit on. Cloud storage integration, object storage design, and S3-compatible tier architecture are outside scope.
VIRTUAL STORAGE ARCHITECTURE — READING SCOPE
| Scope | Coverage | Estimated Time |
|---|---|---|
| Core Reading Sequence | Clusters 1–3: Storage Survivability Models, Data Locality & Survivability, Replication Economics — the foundational failure domain and constraint layer | ~2–3 hr |
| Full Track | All 5 clusters — includes Convergence vs. Disaggregation governance models and Storage Portability & Platform Dependence | ~4–6 hr |
>_ WHERE TO ENTER THIS TRACK
Start at Cluster 01 if you have not explicitly modeled distributed storage failure domains before — if your storage mental model was formed on three-tier SAN/NAS architecture and you’re now operating or sizing HCI or SDS platforms. The foundational shift from centralized authority to distributed locality is where survivability assumptions break silently.
You can likely skip to Cluster 03 if all three of the following apply:
- You currently operate vSAN, Nutanix DSF, or Ceph in production and have modeled FTT/PFTT or replication factor per workload tier
- You have debugged a data locality degradation event or a Curator scan anomaly under production load
- You have sized a cluster for rebuild state, not just steady-state IOPS
If any of those require translation, start at Cluster 01. The failure modes in Clusters 03 and 04 build directly on the locality and failure domain vocabulary established in the first two.
>_ READING SEQUENCE
Each cluster below is organized by architectural problem. Every cluster answers: what becomes architecturally unstable if this discipline is misunderstood?
Where Is the Survivability Boundary Created — or Lost?
Storage architecture changes fundamentally when storage becomes distributed. Traditional three-tier storage assumes centralized authority and isolated failures. SDS assumes locality, replication, and coordinated recovery. The survivability model is not a feature set — it is a set of physics constraints that determine how far failure travels before it stops. This cluster establishes the vocabulary and architectural frame for everything that follows.
When Does Distributed Storage Start Producing Instability?
Distributed storage survives failure by moving data closer to compute and replicating it across nodes. Every improvement in survivability increases coordination overhead, east-west traffic, and rebuild complexity. The architectural challenge is determining where that tradeoff stops producing resilience and starts producing instability — and recognizing that data locality degradation is the leading indicator, not a lagging one.
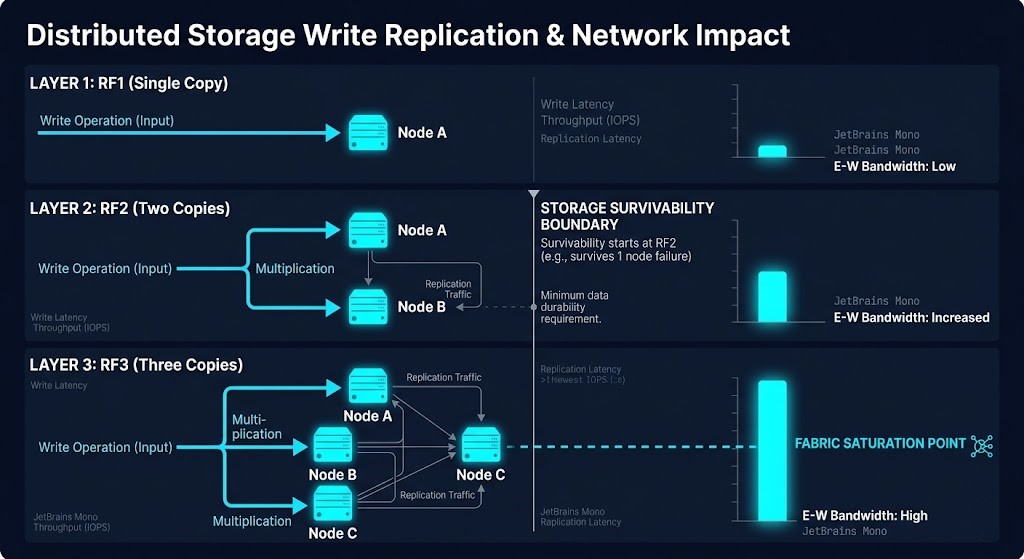
When Does Protection Policy Become a Performance Constraint?
Replication creates survivability by multiplying writes. Every additional protection layer — FTT, RF2, RF3, SPBM policy — consumes bandwidth, storage capacity, and recovery time. Storage policy design is therefore an economic decision as much as a resiliency decision. Replication factor is not a resiliency strategy — it is a cost function with a survivability ceiling, and that ceiling is what this cluster models.
Who Owns the Consequences When Disaggregated Storage Fails?
Disaggregated storage changes more than performance characteristics. It changes ownership boundaries, failure-domain accountability, upgrade sequencing, and operational governance. The question is no longer where storage runs — it is who owns the consequences when it fails. The convergence decision is a governance decision, and it propagates into every operational process that touches the storage fabric.
When Do Storage Decisions Create Dependencies That Outlast the Platform?
Storage systems create some of the longest-lived dependencies in infrastructure. Compute can move. Hypervisors can be replaced. Storage architectures often survive multiple platform generations — and the design decisions made during initial deployment constrain every migration, upgrade, and platform replacement that follows. Sovereignty begins when storage decisions become portable rather than platform-bound.
>_ TRACK FAILURE PATTERNS
Five failure patterns that emerge when storage architecture is handled at Domain Path breadth without Track-level depth.
| Failure Pattern | Architectural Consequence |
|---|---|
| Treating FTT=1 as production-adequate for all workload tiers | Single host failure triggers data unavailability on tier-1 VMs — storage policy is not a global setting, and the blast radius scales with workload density |
| Undersizing east-west bandwidth for replication and rebuild traffic | Rebuild storms under node failure saturate the fabric, amplify write latency across surviving nodes, and push the platform toward its Storage Survivability Boundary under normal recovery conditions |
| Sizing HCI clusters for steady-state IOPS, not rebuild-state capacity | A three-node cluster under a node failure is operating at theoretical maximum I/O across two surviving nodes — the survivability model was never tested at the only moment it needs to work |
| Treating compute-only disaggregation as architecturally equivalent to full HCI | The data locality guarantee is eliminated — read latency becomes network-dependent, I/O becomes unpredictable under contention, and failure-domain accountability shifts to a separately operated storage platform |
| Treating replication factor as a resiliency strategy | Data survives the failure, but rebuild duration exceeds operational tolerance — pushing the platform beyond its Storage Survivability Boundary not through data loss but through sustained performance degradation |
>_ CROSS-TRACK DEPENDENCIES
Tracks share foundational mechanics across disciplines. Understanding which Tracks compound with this one prevents siloed architectural analysis.
| Depends On | Dependency Direction | Why It Matters |
|---|---|---|
| HCI Architecture Track | Upstream Constraint | The HCI convergence model defines the storage failure domain boundary — storage policy modeling, node sizing, and survivability arithmetic all inherit from HCI architectural decisions |
| Compute Architecture Track | Bidirectional | CVM resource contention and NUMA locality connect storage I/O pressure directly to VM scheduling behavior — write saturation and rebuild storms manifest first in CPU ready and memory pressure metrics |
| Networking Architecture Track | Upstream Constraint | East-west replication and rebuild traffic topology governs storage failure blast radius — fabric design and bandwidth capacity set the ceiling on how fast a storage architecture can recover |
| Migration Strategy Track | Bidirectional | Cutover sequencing, replication state during migration windows, datastore topology, and post-cutover data locality directly influence migration execution risk and cluster stabilization time |
| Performance Modeling Track | Downstream Consumer | Storage architecture decisions — media tier, replication factor, data locality health — are the primary inputs to performance modeling under failure and rebuild conditions |
| Virtualization Architecture Path | Domain Path Parent | The Domain Path covers storage and network integration through Stages 2–3 — this Track extends that treatment into failure domain modeling, survivability arithmetic, and governance of the Storage Survivability Boundary |
>_ TRACK GRADUATES CAN NOW
Storage architecture at Track depth means the Storage Survivability Boundary is no longer implicit — it is a modeled constraint with explicit inputs. The shift is from “how much storage do we need?” to “where does this architecture stop being survivable, and under what failure conditions does it cross that line?” That question now has an answer before the workload enters production.
- Model distributed storage failure domains and rebuild penalties for any replication configuration — including the failure state the vendor playbook doesn’t test against
- Design storage policies by workload tier and failure tolerance, not cluster default — with explicit FTT/RF decisions tied to workload availability requirements
- Diagnose data locality degradation as a leading instability signal before it surfaces as latency anomalies in performance dashboards
- Evaluate HCI convergence vs. disaggregated storage tradeoffs against actual workload physics and governance accountability, not vendor positioning
- Apply storage failure domain constraints to Data Protection architecture — RPO achievability is a function of replication topology and rebuild capacity, not backup schedule alone
>_ WHERE DO YOU GO FROM HERE
YOUR STORAGE ARCHITECTURE IS MAKING AN RTO PROMISE IT MAY NOT KEEP
Every storage architecture has a Storage Survivability Boundary. The Recovery Readiness Assessment surfaces where yours sits — and whether your current replication topology, rebuild capacity, and failure domain design can actually honour the recovery commitments your organization is relying on.
Recovery Readiness Assessment
An architectural review of your storage survivability posture — failure domain boundaries, rebuild penalty modeling, and whether your current platform can absorb the failure it’s eventually going to face.
- > Failure domain boundary audit
- > Rebuild penalty and east-west bandwidth modeling
- > Data locality health and degradation risk assessment
- > Storage policy tier alignment vs. workload recovery requirements
Architecture Playbooks. Field-Tested Blueprints.
Field-tested blueprints for storage architecture — failure domain design, survivability modeling, and the replication economics that determine whether your platform survives what it’s eventually going to face.
- > Storage Survivability Boundary modeling
- > Rebuild storm architecture and east-west capacity planning
- > HCI vs. disaggregated governance tradeoffs
- > Data locality degradation as a survivability signal
Zero spam. Unsubscribe anytime.
>_ FREQUENTLY ASKED QUESTIONS
Q: What is storage architecture in the context of enterprise virtualization?
A: Storage architecture in enterprise virtualization is the discipline of designing storage systems as failure domain models — not hardware configurations. The decisions that matter architecturally are where survivability boundaries are established: replication factor, data locality policy, east-west bandwidth allocation, and whether compute and storage converge or disaggregate. Every one of those decisions determines how far a component failure propagates before it becomes a cluster event.
Q: How does the Virtual Storage Architecture Track differ from the HCI Architecture Track?
A: The HCI Architecture Track covers convergence physics — how compute and storage are combined in a single failure domain and what that means for scheduling, controller overhead, and cluster sizing. The Virtual Storage Architecture Track takes the storage layer specifically and goes deeper: failure domain modeling, replication economics, data locality degradation, and the Storage Survivability Boundary. HCI architecture is a prerequisite for understanding storage architecture in converged environments; they are not redundant.
Q: What breaks architecturally when storage policy is treated as a cluster-wide default?
A: Storage policy is a per-workload survivability contract. When it is applied as a cluster-wide default, tier-1 workloads inherit the protection level of tier-3 workloads — or vice versa. The consequence is either over-provisioned replication overhead consuming east-west bandwidth unnecessarily, or under-protected workloads that hit data unavailability on the first single-host failure. Neither failure is visible in normal operations. Both are visible during the first unplanned node outage.
Q: What is data locality and why does its degradation matter more than raw IOPS?
A: Data locality is the proportion of a VM’s reads served from the local node’s storage rather than traversing the network to a remote node. High locality means reads are fast and predictable; degraded locality means reads compete with replication traffic on east-west fabric links. The reason locality matters more than raw IOPS is that IOPS can look healthy while locality is degrading — the platform appears fine until east-west saturation tips it into instability. Locality degradation is a leading indicator of approaching the Storage Survivability Boundary; IOPS degradation is a lagging one.
Q: When does disaggregated HCI create architectural risk that converged HCI does not?
A: In converged HCI, the storage fabric is co-located with compute — reads are local, failure domains are unified, and the upgrade and governance model is a single vendor stack. Disaggregated HCI — compute-only nodes connected to an external SAN — eliminates data locality, reintroduces network-dependent read latency, and splits failure-domain accountability across two separately operated platforms. The architectural risk is not that disaggregation performs worse under steady-state load. It is that it performs worse under the specific conditions — concurrent node failure, fabric saturation, maintenance windows — where storage architecture is actually tested.
>_ RELATED SYSTEMS
The full virtualization pillar — hypervisor architecture, platform decision frameworks, SDS strategy, and HCI operational architecture for private cloud environments.
Open Pillar →The Virtualization Architecture Path treatment of storage and network integration — the maturity-level context this Track extends into failure domain modeling depth.
Open Stage →DSF data locality mechanics, CVM architecture, and the full HCI stack — the architectural baseline for understanding storage survivability in converged Nutanix environments.
Open Sub-Domain →The domain that builds recovery architecture on top of the storage survivability foundation this Track establishes — RPO and RTO engineering inherits directly from failure domain design.
Open Domain Path →The Nutanix Bible — Storage Architecture section. Primary engineering documentation on DSF data locality, replication mechanics, and Curator scan cycle behavior.
Open Reference →VMware vSAN Design Guide. Primary engineering documentation on SPBM policy modeling, FTT configuration, and vSAN architecture for enterprise deployments.
Open Reference →