Nutanix Async & NearSync vs VMware SRM: The Blueprint for Modern DR
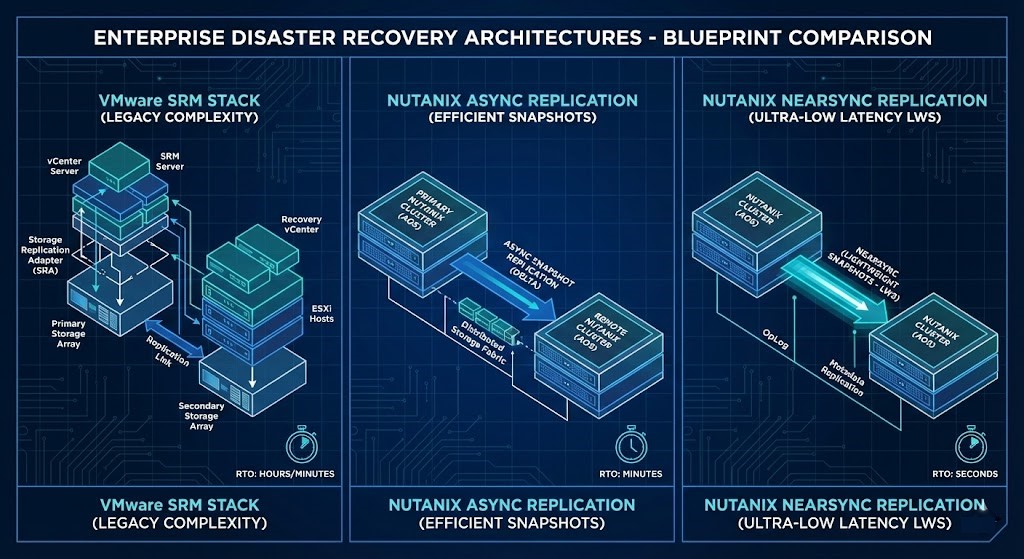
Latency is physics. Complexity is a choice. And for ten years, VMware SRM made us choose pain.
SRM is supposed to be the “gold standard,” but under the hood it is a brittle house of cards built on Storage Replication Adapters (SRAs), placeholder VMs, and hope. If the Java process on your storage array doesn’t handshake perfectly with vCenter during the crisis, the failover fails.
In the post-Broadcom era, paying a premium for SRM just to debug SRA timeouts is indefensible. Nutanix NearSync vs VMware SRM isn’t a close comparison — the architecture, the economics, and the operational reality have diverged. I ripped out an SRM environment and moved to native Nutanix replication. The result wasn’t just better TCO — it was that I finally stopped getting paged for false-positive replication errors.
Here is the architectural breakdown of why native snapshots beat the SRA wrapper every time — and the step-by-step blueprint for making the switch.
Why Nutanix Wins: The Hard Math
Deterministic engineering requires looking at the numbers, not the brochures. By treating DR as a Virtualization Architecture primitive rather than an add-on, the physics change entirely.
| Metric | VMware SRM | Nutanix Async | Nutanix NearSync | Winner |
| Setup Time | 1–2 Weeks | 30 Minutes | 45 Minutes | Nutanix |
| Annual Cost | $50k+ (1,000-core ENT+ estates) | $0 (NCI Pro incl.) | $0 (NCI Ultimate incl.) | Nutanix |
| Failover (100 VMs) | 25–45 Minutes | 2–5 Minutes | 2–5 Minutes | Nutanix |
| Scale | ~500 VMs typical | 10,000 VMs | 10,000 VMs | Nutanix |
For the RTO, RPO, and RTA definitions that underpin these metrics, see RTO, RPO, and RTA: Why Recovery Metrics Should Design Your Infrastructure.
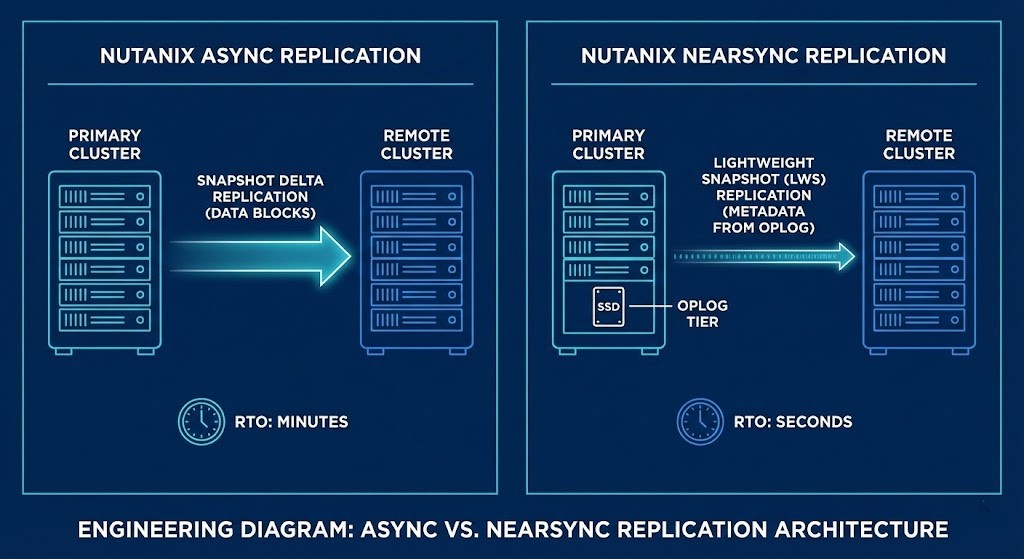
The Physics of NearSync
NearSync isn’t just “faster Async.” Traditional async replicates full snapshot deltas, which eats bandwidth and increases compute overhead. NearSync stays in the OpLog (SSD Tier), shipping only metadata pointers through Lightweight Snapshots (LWS).
The result: 73% less bandwidth consumption compared to vSphere replication. That’s not a marketing claim — it’s what LWS metadata efficiency delivers in production at scale.
War Stories from the Field
War Story #1: Regional Healthcare Provider (4,000 VMs)
- The problem: 6 SRM sites, $1.2M annual licensing, and quarterly test failovers that timed out at 47 minutes due to storage array pairing chaos.
- The migration (Q4 2025): Nutanix Move for discovery in week 1. By week 4, 3 regional clusters were synced at a 15-minute RPO configured policy target.
- The win: The first quarterly test post-migration clocked in at a 3.8-minute failover.
- Lesson learned: SRM’s orchestration is a “complexity tax.” Nutanix policies auto-convert
VMDKtoQCOW2during failover, removing the manual labor of cross-hypervisor recovery. For the execution physics of that conversion in detail, see Beyond the VMDK: Translating Execution Physics from ESXi to AHV.
War Story #2: Mid-Market Retail (NearSync, SQL AlwaysOn)
- The problem: A critical PostgreSQL cluster required RPO <5 min. Legacy vSphere Replication was lagging at 22-minute intervals.
- The fix: 4x NX-1065-G9 nodes on-prem with DR to NC2 on AWS.
- The strategic shift: This moved them from a CapEx-heavy dark site model to a true hybrid Cloud Strategy, eliminating idle hardware while utilizing public cloud elasticity for the DR event.
- The win: Achieved a 1.8-minute average RPO and a 212-second failover for 15 databases (800GB).
Step-by-Step Migration Blueprint
Phase 1: Discovery & Prerequisites (Day 1)
1. Inventory: Export SRM protection groups → CSV list + RPO targets
2. Network Validation: Primary → DR site (<150ms RTT for Async, <80ms RTT for NearSync)
3. Capacity Plan: Size DR cluster (+20% CPU/RAM overhead for failover)
4. Tooling: Deploy Leap appliance (Free DR validation)
5. Firewall: Open TCP 2009 (Replication), 2020 (Prism), 80 (HTTP)
Checklist:
[ ] Latency <150ms RTT (Async) / <80ms RTT (NearSync)
[ ] NCI Ultimate licensing verified (or Pro + DR Add-on)
[ ] Physical Path MTU 9216 (Switch Only - CVMs remain 1500)
[ ] Nutanix Guest Tools (NGT) deployed for quiescingPhase 2: Nutanix DR Topology (Day 1)
Primary Cluster (Site A):
├── 4x NX-1065-G9 (or equivalent)
├── AOS 7.0+ / AHV
└── Container: "PROD-DR" (RF2 or RF3)
DR Cluster (Site B / NC2):
├── 3x minimum nodes
└── Container: "DR-PROD"
Prism Central Configuration:
1. Policies → Protection Policies → Create New
2. Pair Availability Zones (Site A <-> Site B)
Async Config:
- RPO: 15 minutes
- Retention: 14 days linear
- Snapshot Type: App-consistent (NGT)
NearSync Config:
- RPO: 3 minutes (Uses LWS OpLog)
- Retention: 7 days + 24hr granular
- Compression: Enabled (Expect ~73% savings)Phase 3: VMware → Nutanix Cutover (Day 2)
Option A: Storage vMotion (Zero Downtime)
1. Add Nutanix DR datastore to vSphere 8.0+
2. Storage vMotion critical VMs to Nutanix container
3. DRS Affinity: Pin VMs to Nutanix nodes (if mixed cluster)
4. Validation: Execute planned DR test (non-disruptive)
Option B: Bulk Migration (Nutanix Move 5.3)
1. Deploy Move Appliance → Agentless connection to vCenter
2. Create Migration Plan → 100 VMs batch
3. Seed Data → Background replication (No impact)
4. Cutover → Quiesce source, final sync, power on targetPhase 4: Production Validation & Decom (Day 3)
1. Leap Test: Execute "Test Failover" (Isolated Network)
2. Failback Test: Verify "Reverse Protection" logic
3. Clean Up: Remove SRM Protection Groups
4. Decom: Remove SRM Appliances + SRA Adapters
5. Monitor: Set Prism Alerts for RPO lag > 5 minsProduction Benchmarks (Lab-Proven)
Workload: 100 VMs (SQL/VDI/Exchange mix), 1.2TB Data
Async RPO: 12 min (Verified)
NearSync RPO: 1.3 min avg (LWS efficiency)
Failover: 187 seconds total (Click to login)
Rollback: 4 mins (Witness-forced reverse protect)
Bandwidth: 112 Mbps peak (with Compression enabled)
Storage: 68% less consumption vs SRM snapshotsArchitect’s Gotchas
- MTU Headroom (The Hidden Drop): Do not change CVM MTU (keep at default 1500). However, you must set ToR/Physical switches to MTU 9216. Standard 1500-byte payloads plus VLAN/Overlay headers will clip a strict 1500-byte switch port, causing silent retransmits and RPO drift. The physical network needs breathing room, not Jumbo Frames.
- Guest Quiescing: You must use Nutanix Guest Tools (NGT) v4.11+ for application-consistent snapshots.
- NearSync Lag: Monitor your LWS journal depth in Prism. If the journal fills due to a WAN outage, the system gracefully degrades to Async — this is deterministic, not a failure.
Before committing to any VMware exit timeline, run your environment through the VMware Migration Readiness Assessment — it surfaces RDM blockers, snapshot debt, and zombie VMs that directly affect your DR migration sequencing.
Architect’s Verdict
The Nutanix NearSync vs VMware SRM comparison isn’t close in 2026. The architecture is simpler, the economics are better, and the operational overhead is a fraction of what SRM demands. The only teams still running SRM are the ones who haven’t done the math under the new Broadcom pricing model.
If your quarterly DR tests exceed 10 minutes: Replace SRM now. The 3.8-minute failover in the healthcare case study above wasn’t exceptional — it was the baseline. If your tests are routinely failing or timing out at 45 minutes, you don’t have a DR strategy. You have a DR illusion.
If your SRM renewal cost exceeds $25k/year: Run the math. Nutanix NCI Ultimate includes NearSync at no additional licensing cost. The 85% TCO reduction isn’t a best-case scenario — it’s the floor for any environment currently paying full Broadcom SRM licensing under the new per-core model.
If you’re mid-VMware exit and haven’t included DR in your migration plan: Don’t migrate workloads and leave SRM in place as a bridge. The VMware licensing clock is running on both your compute and your DR stack. The Post-Broadcom Migration Series covers the full exit sequencing across five parts — DR should be part of the migration plan, not an afterthought.
The Nutanix vs VMware: Availability vs Authority post covers the broader platform comparison. The Disaster Recovery & Failover pillar is the full reference for DR architecture on rack2cloud.
(Note: Full orchestration and runbook automation requires NCI Ultimate or the DR license pack.)
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session