-
-
Your DR Test Passed. The Assumptions Didn’t.
DR plan failure rarely happens where you tested. It happens at the assumptions the exercise never reached — the dependencies that weren’t in scope, the runbook written for last year’s architecture, the authority chain nobody tested at 2am.
-
-
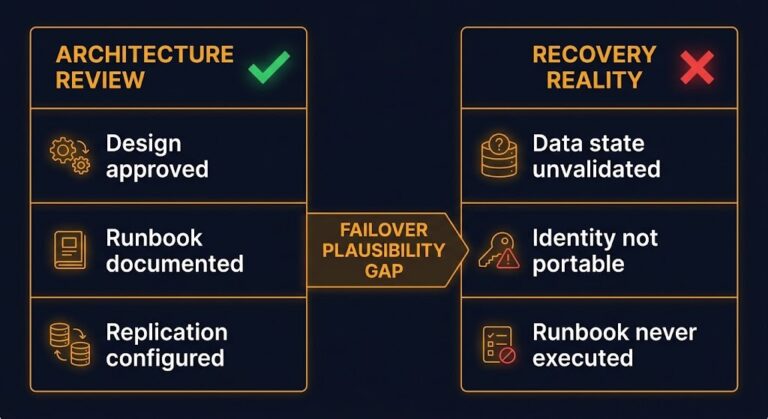
Multi-Cloud Failover Is Mostly Theater
Most multi-cloud architectures are designed to survive a cloud outage. Very few are designed to survive a failover. The Failover Plausibility Gap explains why — and what closing it actually requires.
Parent: none (top-level post)
Publish date: Friday June 5, 2026 -
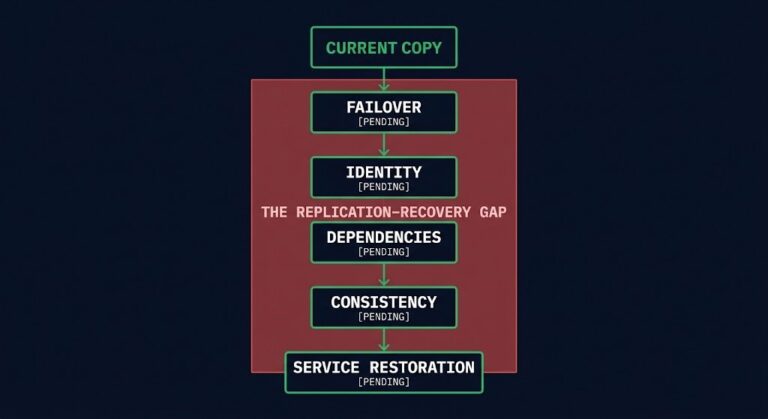
Cross-Region Replication Is Not Resilience
Every disaster recovery review eventually reaches the same sentence: “We have cross-region replication, so we’re covered.” It is said with confidence, because by every metric the team watches, it is true. The replica is current. Lag is measured in seconds. The dashboard is green. And that confidence is precisely the problem. The better replication works,…
-
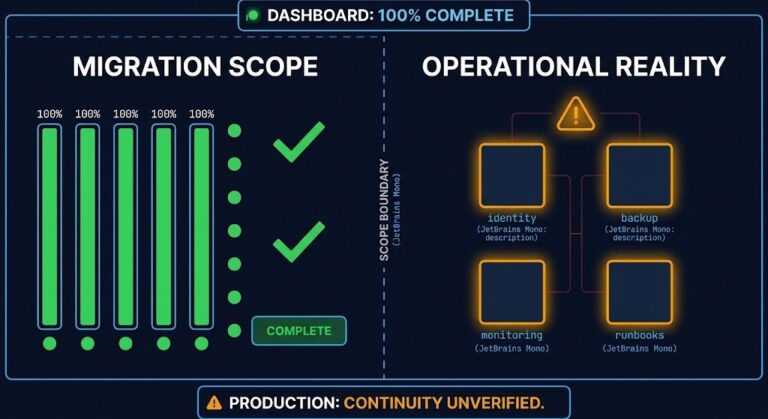
The Dashboard Said the Migration Succeeded
Migration dashboard failure has a consistent pattern: the tooling reports 100% complete, health checks pass, services respond — and production discovers a different set of facts three weeks later. The dashboard wasn’t wrong. It measured exactly what it was designed to measure. Task completion against a pre-defined scope. Operational continuity was never in that scope….
-
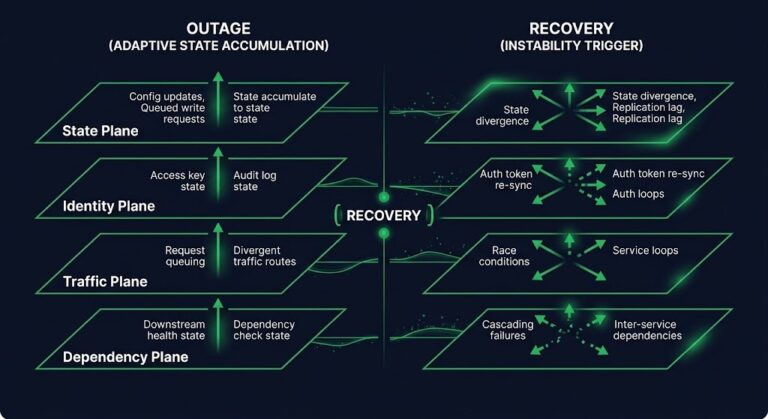
Recovery Ends the Outage. It Doesn’t End the Incident.
THE RECOVERY ENGINEERING SERIES PART 01 The Retry Storm Is a Self-Inflicted DDoS LIVE PART 02 Incident Recovery Process: Why the Incident Isn’t Over After Restore LIVE PART 03 Recovery Ends the Outage. It Doesn’t End the Incident. YOU ARE HERE PART 04 The Degradation Ladder: How Systems Fail Before They Fail LIVE Business continuity…
-
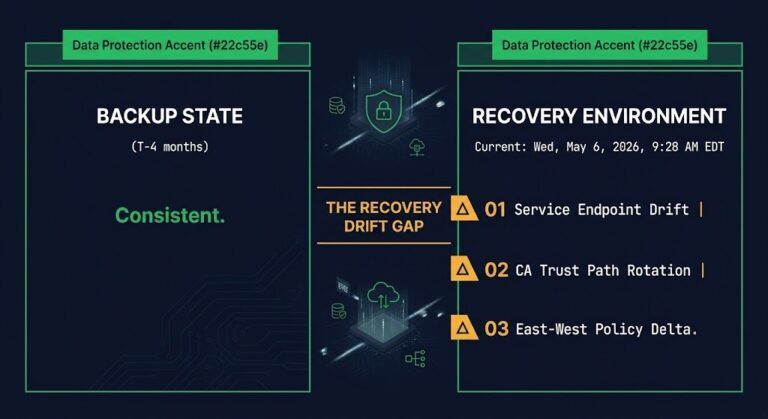
The Configuration Drift Discovery During a Drill
Quarterly recovery drill. Backup job green for four months. Restore executes cleanly — data intact, VM boots, database service starts. The application fails on the first transaction. Three hours disappear into backup triage before anyone checks the environment. The backup was not the problem. It never was. This is recovery configuration drift — and it…
-
Why Your DNS Failover Didn’t Actually Fail Over
The failover was declared at 02:14. The runbook was followed. DNS records updated. Health checks passing on secondary. The on-call engineer closed the incident bridge call at 02:31 with a single line in the ticket: failover complete. At 02:32, a monitoring alert fired. Traffic was still hitting the dead primary. The DNS record had changed…
-
Incident Recovery Process: Why the Incident Isn’t Over After Restore
THE RECOVERY ENGINEERING SERIES PART 01 The Retry Storm Is a Self-Inflicted DDoS LIVE PART 02 Incident Recovery Process: Why the Incident Isn’t Over After Restore YOU ARE HERE PART 03 Recovery Ends the Outage. It Doesn’t End the Incident. LIVE PART 04 The Degradation Ladder: How Systems Fail Before They Fail LIVE The restore…