Your VMware Exit Was Successful. The First Incident Will Tell You If That’s True.
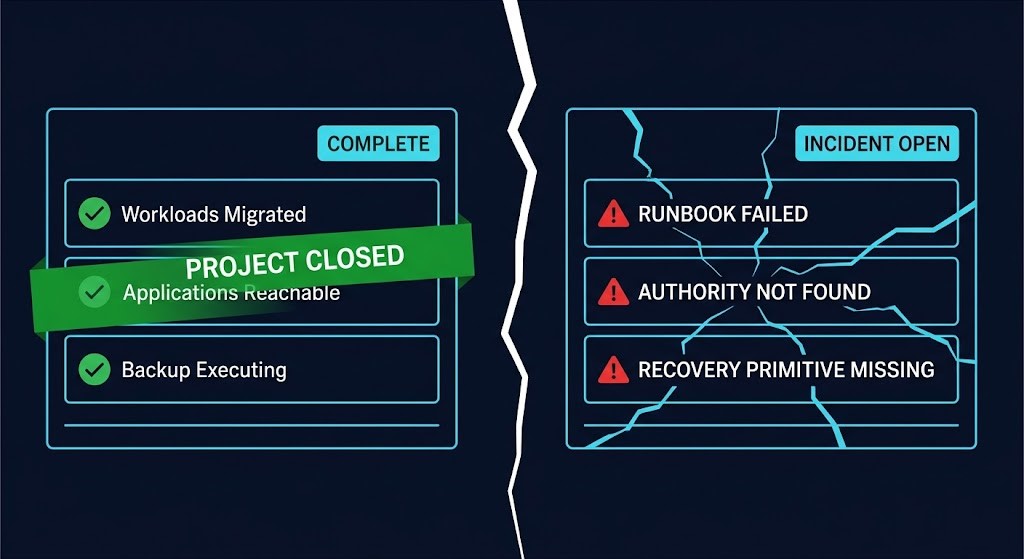
VMware exit survivability is the question your migration project never formally scheduled — and the first production incident on the new platform will answer it whether you are ready or not. The cutover completed. The workloads are running. The project closed green. None of that tells you whether the operating model, runbooks, authority structures, and recovery primitives that matter under failure actually made it across with them.
This is the test that comes after the migration. Most organizations don’t realize they haven’t passed it until the first incident starts.
The Migration Closed Green. That Wasn’t the Test.
Every VMware exit has a definition of done. Workloads migrated. Applications reachable. Performance within tolerance. Backup jobs executing. The project board turns green, the steering committee debrief happens, and the hypervisor migration is declared complete.
That definition of done measured virtualization architecture movement, not operational survivability. The migration project’s success criteria were scoped to the cutover — to the moment workloads started running on the new platform. They were not scoped to what happens when something breaks on that platform at 2am on a Tuesday, three months later, with a team that has never responded to an incident in this environment before.
The operating model transfer gap (#137) is the foundational problem in VMware exit programs. Organizations migrate the workloads. They do not consistently migrate the operational knowledge, authority chains, and recovery processes that keep those workloads alive under pressure. vSphere lifecycle governance (#112) established the original debt — governance decisions about patching, change control, and lifecycle management accumulated for years under VMware. That debt doesn’t disappear at cutover. It reappears under a different platform label on the first real incident.
The migration closing green is not the test. It is the setup.
The First Incident VMware Never Tested
Migration validation programs are thorough within a specific scope. That scope almost always excludes the failure scenarios that matter most.
Most VMware exit projects validate:
01 — WORKLOAD STARTUP
VMs power on, services initialize, application health checks pass. The migration tool confirms successful transfer.
02 — APPLICATION REACHABILITY
Users and dependent services can reach applications over the network. DNS resolves correctly. Latency within tolerance.
03 — PERFORMANCE BENCHMARKS
CPU, memory, and storage I/O are measured against pre-migration baselines. Results are documented and accepted by stakeholders.
04 — BACKUP EXECUTION
Backup jobs are configured and confirmed to execute successfully. Job logs show green. Retention policies are set.
Almost no VMware exit project validates:
- Recovery execution — whether a restore from backup on the new platform actually completes successfully, within RTO, using the new platform’s recovery primitives
- Authority continuity — whether the people with recovery authority on the old platform still hold that authority in the new environment, or whether escalation chains were never rebuilt
- Runbook translation — whether incident response procedures reference new-platform constructs or still describe vCenter, SRM, and DRS operations that no longer exist
- Escalation survivability — whether the on-call chain under a major incident leads to engineers who know the new platform or to engineers whose expertise ended at VMware
- Identity continuity under failure — whether VM identity, access, and authentication survive the incident response process itself, not just the migration cutover
The dependency visibility boundary (#143) is the silent amplifier here. Dependencies that were never fully mapped don’t announce themselves during calm operations. They surface during incidents, when the recovery action requires a service, credential, or network path that the migration never confirmed existed in the new environment. The migration closes before the test that actually matters. The project documented what moved. It did not document whether what moved was sufficient to recover under failure.
Framework #145 — Migration Survivability Test
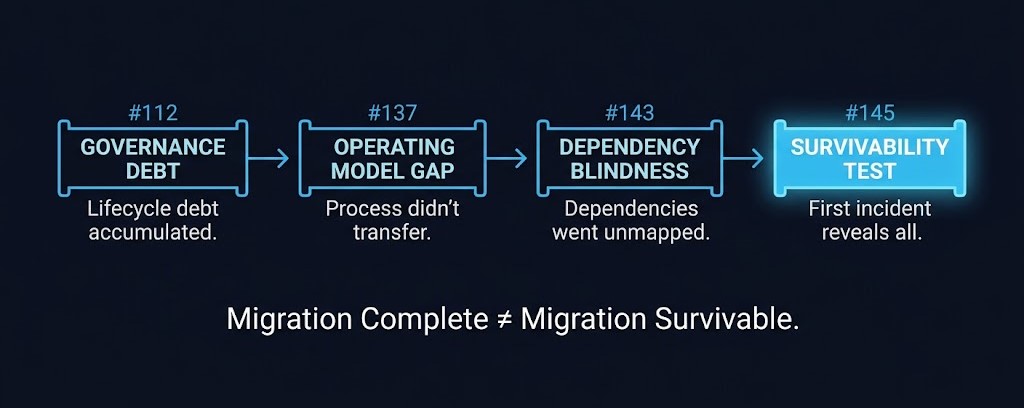
FRAMEWORK #145 — MIGRATION SURVIVABILITY TEST
The property of a migrated environment that determines whether it can absorb its first real production incident using only the operating model, tooling, authority, and knowledge that successfully transferred from the platform it replaced. The Migration Survivability Test is passed when recovery executes successfully without requiring primitives, runbooks, authority structures, or institutional knowledge anchored to the platform that was replaced.
When #145 fails, the incident reopens the migration project. Recovery requires knowledge, tooling, or authority from the platform that was replaced — proving the migration was never complete.
⚠ FAILURE STATE — FRAMEWORK #145
The first production incident on the new platform exceeds the recovery capability that actually transferred. The runbook references vCenter, SRM, or DRS constructs that no longer exist. Escalation routes lead to authority scoped to the dead platform. The recovery action assumes a snapshot, replication, or failover primitive that was never reproduced in the new environment. The migration project closed green. The first incident reopened it red.
Migration Assumed vs. First Incident Revealed
This is the survivability audit the migration project never ran. Six gaps — each one a decision the migration program deferred and the first incident is forced to resolve in real time, under pressure, with users and stakeholders watching.

| Migration Assumed | First Incident Revealed |
|---|---|
| Workload moved | Recovery model didn’t — the new platform has no tested restore path for this workload under failure |
| Runbook exists | Runbook references VMware constructs — vCenter operations, SRM failover steps, DRS rebalancing actions that do not exist in the new environment |
| Authority transferred | Authority still anchored to old platform — the recovery escalation chain leads to engineers whose VMware access and expertise no longer applies |
| Recovery authority exists | Recovery authority fragmented across old and new platforms — Recovery Authority Fragmentation (#144) surfaces when the incident spans workloads in two environments simultaneously |
| Backup succeeded | Recovery execution was never tested — backup jobs ran green, but no one confirmed that a restore completes within RTO using the new platform’s primitives |
| Team trained | Knowledge never transferred — Operational Memory Boundary (#129) and the Operating Model Transfer Gap (#137) are visible here: the team knows VMware incident response; they have never executed it on this platform |
When the recovery primitive never transferred — when the new platform’s snapshot, replication, or site-failover capability was assumed rather than validated — the incident exposes a localized form of Recovery Dependency Collapse (#122). The workload’s recovery path depended on a capability that exists only on the platform that was replaced. The dependency was invisible until the incident made it concrete.
The Nutanix AHV post-migration operations reality is consistent with this pattern: organizations that migrated workloads to AHV and documented the availability vs. authority tradeoffs before the first incident recovered faster than those that assumed authority would transfer automatically. The gap was never technology. It was governance, knowledge, and authority — the things that don’t appear in migration checklists.
Designing for VMware Exit Survivability Before the Incident
The Migration Survivability Test does not have to run unplanned. Architects can schedule it.
Rehearse the first incident before it happens. Pick the three most likely failure scenarios on the new platform — a storage node failure, a VM that won’t power on, a replication job that stops — and run them in a maintenance window before the migration closes. Not as a validation check. As an incident drill. Escalate through the actual on-call chain, reference the actual runbooks, involve the actual engineers who will respond at 2am. Document what breaks in the drill, not in production.
Rewrite runbooks in new-platform primitives before close. Every runbook that contains a VMware verb — vMotion, DRS, SRM, vCenter — is a runbook that will fail during the first incident on the new platform. Day-2 operations on the new platform require runbooks written in the new platform’s operational vocabulary. This is not a documentation task. It is an operational readiness gate. Post-migration incident response failure patterns consistently trace back to runbooks that were never translated — they were copied, renamed, and assumed to be equivalent.
Remap and test recovery authority chains before close. Recovery authority that was scoped to vCenter administrator roles, SRM replication groups, or NSX segment managers does not automatically transfer to equivalent roles on the new platform. Map the new authority structure explicitly. Test the escalation path in the drill. Confirm that the engineers who hold recovery authority on the new platform have actually exercised it under simulated failure before a real incident delegates that authority to them.
The incident recovery process failure mode is the same regardless of platform: organizations that test recovery before the incident reveal the gaps in a controlled environment. Organizations that don’t discover them in production.
Architect’s Verdict
A migration is not complete when the workload starts on the new platform. It is complete when the new platform absorbs its first production incident without requiring authority, tooling, knowledge, or recovery primitives from the platform it replaced.
Most VMware exit programs never run that test deliberately. They run it involuntarily — on a production incident, under time pressure, with incomplete runbooks and engineers who have never responded to a failure in this environment. The migration project measured movement. It did not measure survivability. Those are different audits, and only one of them happens on a schedule you control.
The migration project measures movement. The first incident measures survivability.
SERIES: VMware Exit Architecture
← Previous — Part 03
VMware Licensing Pressure Created a Dependency Audit ProblemSeries Complete
Part 04 of 04Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session