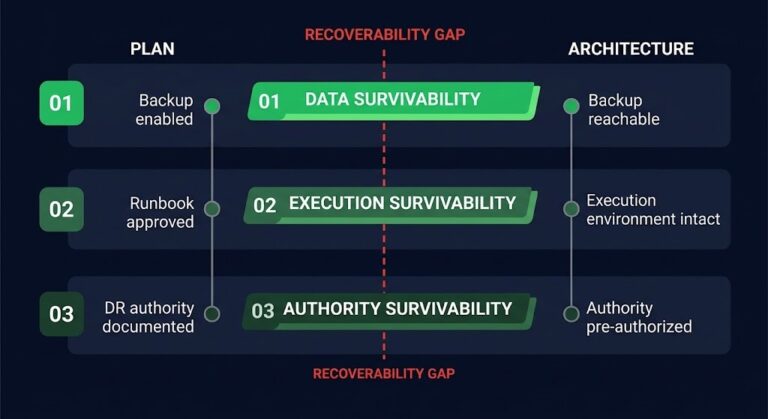
Your DR Test Passed. The Assumptions Didn’t.

The test passed.
The restore completed inside the window. The workload came online. The team signed off, closed the ticket, and filed the results. DR test: successful.
And then, somewhere between the test environment and the next real incident, the recovery plan drifted out of alignment with the infrastructure it was written to protect. Not dramatically. Not all at once. Gradually — through a cloud migration, an IdP consolidation, a new SaaS dependency, a network redesign that didn’t make it into the runbook.
DR plan failure rarely happens where you tested. It happens at the assumptions the exercise never reached.
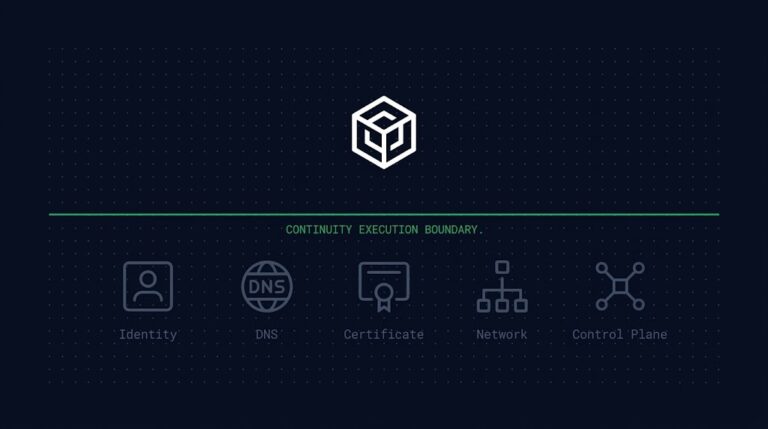
The Test Has a Boundary. The Incident Doesn’t.
A DR exercise begins with a defined scope. A specific workload. A known starting state. A target environment that has been prepared in advance. The team is available, credentialed, and not managing anything else. The blast radius is controlled before the test starts.
A real incident does none of that.
Scope expands from the first alert. Authentication problems surface because the IdP that wasn’t in the exercise scope is now unreachable. Networking issues appear because the failover path assumes a routing table that was updated three months ago. A vendor the plan never named is unavailable, and the recovery sequence stalls waiting for a dependency that was never documented as a dependency.
The plan was written for the conditions of the test. The incident arrives in conditions the plan never anticipated. That gap is where DR plan failure actually lives — not in the restore mechanism, but in everything the restore mechanism was assumed to be able to reach.
Most DR Plans Depend on Things They Never Recover
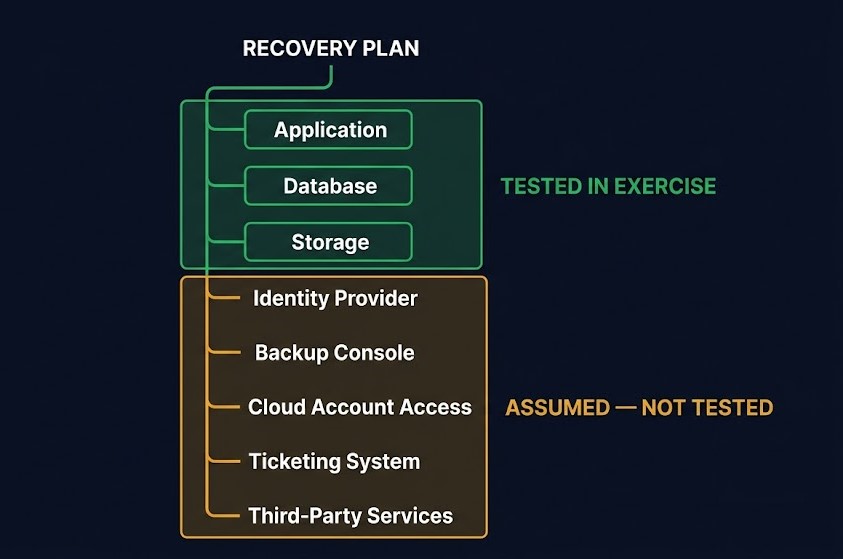
The recovery exercise validates a workload. What it rarely validates is the recovery infrastructure itself.
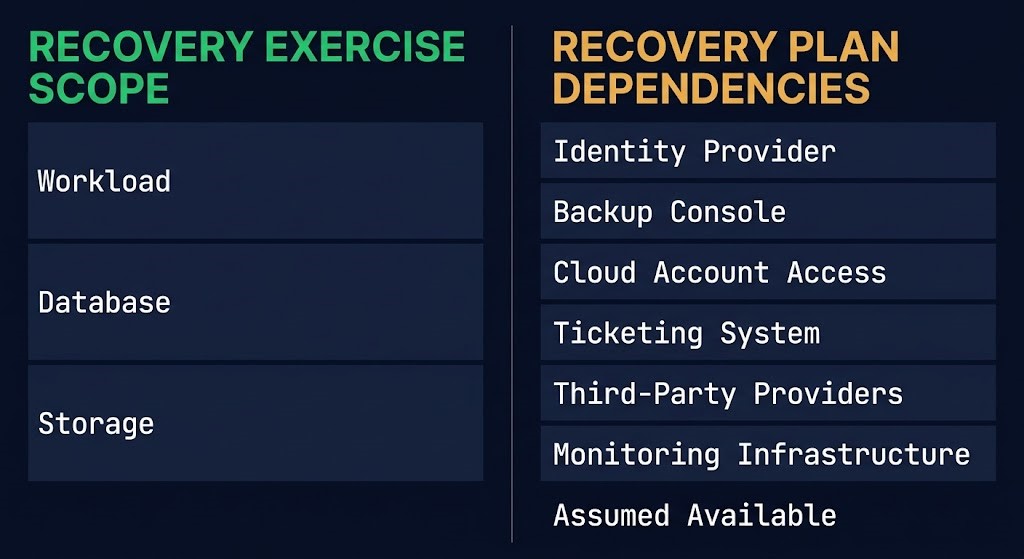
Consider what a typical enterprise DR plan silently depends on:
ASSUMED — NOT TESTED
- Identity provider — authentication for every recovery action
- Backup management console — the interface used to initiate restore
- Cloud account access — credentials, roles, and permission boundaries
- Ticketing and incident management systems — required for authorization workflows
- Third-party providers — whose availability the plan treats as guaranteed
- Monitoring and alerting infrastructure — the systems that confirm recovery succeeded
None of these are typically included in the recovery exercise. The identity provider is the most consequential omission — when the IdP becomes unreachable, every downstream action stalls, including the recovery sequence itself. All of them are treated as available by default. All of them are treated as available by default. When one fails during a real event, the plan doesn’t have a response — because the plan assumed it would never need one.
This is the architecture problem backup blast radius describes: the systems that protect workloads are themselves part of the failure domain. The same logic applies to recovery orchestration. A recovery plan that depends on infrastructure it never tested recovering is not a recovery plan. It’s a recovery assumption with a completion certificate. Even when recovery infrastructure survives the blast radius intact, a separate gap emerges at restore time. Restore architecture — the five dependency layers beyond data recovery — is almost never designed, only assumed. Platform recovery, identity recovery, dependency recovery, and validation recovery are treated as automatic consequences of data recovery. They are not. Nor is a passing completion check the same claim as a validated recovery — the gap between the two is usually invisible until a ransomware incident forces the distinction. And past restore sits one more seam the exercise never reached: the Continuity Execution Boundary — whether the DNS paths, certificates, and cutover ownership the business depends on failed over with the workload is a separate claim no green dashboard makes on its own — the exact determinism gap the Disaster Recovery & Failover Architecture stage’s Cluster 4 names directly: a recovery that passes every test can still produce a different outcome next time if sequence, dependency, authority, and validation weren’t independently fixed. Cluster 4’s determinism claim is exactly what adversarial restore testing exists to operationalize — injecting credential revocation, control-plane contention, and repository denial deliberately, on the assumption that a real incident will supply that interference for free if the drill doesn’t.
The recovery platform itself belongs on this list. The backup console, the recovery orchestration system, and the credentials used to operate them are treated as available by default in the same way the identity provider and ticketing system are. None of them are typically exercised as part of a DR test. Recovery Platform Architecture, the second stage in the Data Protection & Resiliency Learning Path, addresses this gap directly — testing whether the platform responsible for executing recovery, and the authority required to operate it, remain available when the conditions that triggered recovery are also working against them.
The RPO and RTO commitments on paper assume all of this underlying infrastructure performs as expected. Most RTO failures in production aren’t caused by backup technology failing. They’re caused by a dependency the RTO calculation never included.
The Architecture Changed. The Plan Didn’t.
Recovery documentation has a publication date. Infrastructure doesn’t stay synchronized with it.
In most enterprise environments, the DR plan was written to match a specific architectural state. Since then, the organization has likely moved workloads to cloud, consolidated identity providers, introduced new SaaS dependencies, redesigned network segmentation, or changed backup vendors. Each of those changes created new recovery dependencies. Few of them made it into the runbook.
⚠ COMMON MISTAKE
Treating a successful DR test as confirmation the plan is current. The test validates a mechanism against the architecture that existed when the exercise was designed. It doesn’t validate the plan against the architecture that exists today.
The exercise validated the mechanism. The mechanism may still work exactly as designed. But the plan — the sequence, the dependencies, the contacts, the authorization chain — was written for infrastructure that no longer exists in its original form.
This is also where configuration drift and recovery planning intersect. The same pattern that produces drift in production environments produces drift in recovery documentation. Both reflect the gap between a documented state and a current state. The difference is that drift in production generates alerts. Drift in recovery plans generates nothing until they’re needed.
Recovery Starts With Decisions, Not Technology
When a real incident triggers the recovery plan, the first constraint isn’t technical. It’s organizational.
Who has authority to declare a disaster? Who is authorized to initiate failover — and accept whatever data loss that entails? If the failover doesn’t go cleanly, who decides whether to roll back or push forward? Who signs off on the recovery being complete?
The infrastructure may be ready to recover faster than the organization can answer those questions.
DIAGNOSTIC QUESTION
“If your primary recovery coordinator is unreachable at 2am, who has authority to initiate failover — and does your DR plan name them?”
DR exercises rarely test the decision layer. The test starts after someone has already decided to run it. In a real event, that decision is the first bottleneck — and the people who need to make it may be unavailable, may not have the access they need, or may disagree about what the situation requires.
Recovery plans that are strong on technical sequence and thin on authority structure will stall at the organizational layer. Disaster recovery authority — who holds declaration rights, who approves failover, and what happens when those people are unavailable — is the layer most DR plans leave implicit. The continuity cascade that follows a restore is rarely part of what the DR test measures, but authority fragmentation is almost always what drives it.
Architect’s Verdict
Passing a DR test confirms the recovery mechanism works. It confirms that the tooling, the restore path, and the tested sequence can produce a result within a controlled window. That matters. It should be tested regularly.
But the test is not the plan. The test is a subset of the plan, executed under conditions the plan rarely replicates. It runs inside a defined scope with a prepared environment, available personnel, and infrastructure that isn’t simultaneously failing for real. The plan has to work when none of those conditions hold.
Recovery plans rarely fail at the point they were tested. They fail at the assumptions that were never exercised — the dependencies that weren’t in scope, the runbook sections that weren’t updated after the last migration, the authority questions that didn’t come up because someone had already made the decision before the exercise started.
Most organizations don’t discover those assumptions during the exercise. They discover them during the disaster.
One of those untested assumptions deserves naming directly: that the platform running recovery, and the people authorized to operate it, will both still be standing when the disaster arrives. Decision authority, covered earlier, determines whether someone can call it. Platform authority determines whether, once called, recovery can actually be carried out. Recovery Platform Architecture addresses that second question — mapping whether execution authority and platform capability remain aligned under the specific failure conditions an organization is most likely to face.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session