Cross-Region Replication Is Not Resilience
Every disaster recovery review eventually reaches the same sentence: “We have cross-region replication, so we’re covered.” It is said with confidence, because by every metric the team watches, it is true. The replica is current. Lag is measured in seconds. The dashboard is green. And that confidence is precisely the problem.
The better replication works, the more dangerous the assumption becomes.
This is not an argument against replication. Modern replication is one of the most reliable primitives in infrastructure — it does exactly what it claims, continuously and without drama. The argument is against the false confidence that reliability manufactures. Replication is a data-movement capability. Resilience is a recovery capability. They are routinely treated as the same thing, and they are not even close. A current copy at a second site tells you that your data exists somewhere else. It tells you nothing about whether a service can be brought back to life from it, how long that would take, or whether the thing you recover is even valid.
What follows is five structural reasons cross-region replication is not resilience: why a current copy is not a recoverable one, why replication faithfully copies disasters, why consistency quietly breaks recovery, why dependencies fail when infrastructure doesn’t, and why failover is a different engineering discipline entirely. Each is a separate failure surface. By the end, they collapse into a single idea — that replication creates data state, and recovery requires something else.
What Cross-Region Replication Actually Guarantees
It is worth being precise about the primitive before dismantling the assumptions stacked on top of it. Cross-region replication maintains a copy of data in a geographically separate location, kept current to within some bounded window. Synchronous replication holds the replica byte-identical to the source at commit time; asynchronous replication accepts a small lag in exchange for not blocking writes on a distant round trip. Object stores do it at the bucket level (AWS S3 Cross-Region Replication), storage platforms do it at the account or volume level (Azure storage redundancy), and databases do it at the transaction-log level.
That is the entire guarantee: a current copy exists elsewhere. It is a real and valuable guarantee. It protects against the loss of a region, a data center, a storage array. It bounds how much data you can lose to a hardware or facility event.
What it does not guarantee is anything about the act of recovery. Replication is the continuous answer to one narrow question — “is the copy current?” — and it answers nothing else. The moment you ask a different question, the guarantee evaporates.
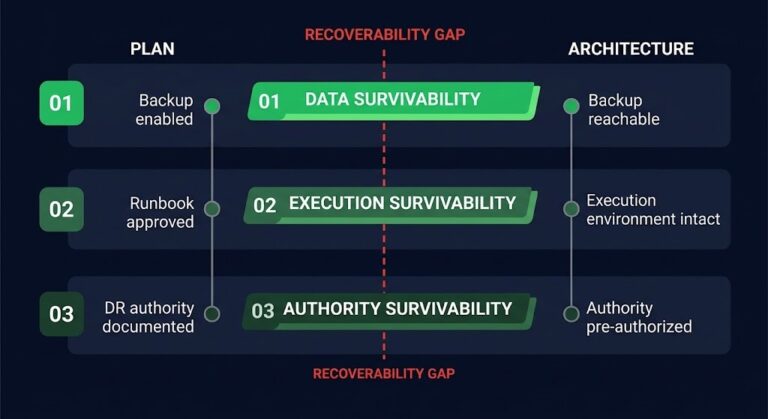
RPO Is Not RTO
The first place the guarantee fails is the gap between the two metrics every recovery program claims to manage. Recovery Point Objective measures how much data you can afford to lose — how current the copy must be. Recovery Time Objective measures how long you can afford to be down — how fast service must return. Replication is purely an RPO instrument. It drives data loss toward zero. It does precisely nothing for RTO.
| RPO | RTO | |
|---|---|---|
| The question | How much data can we lose? | How long until we serve again? |
| Driven by | Replication frequency | Orchestration, dependencies, people |
| Replication’s effect | Drives toward zero | Unchanged |
| Where it’s proven | Continuously, automatically | Only under failure |
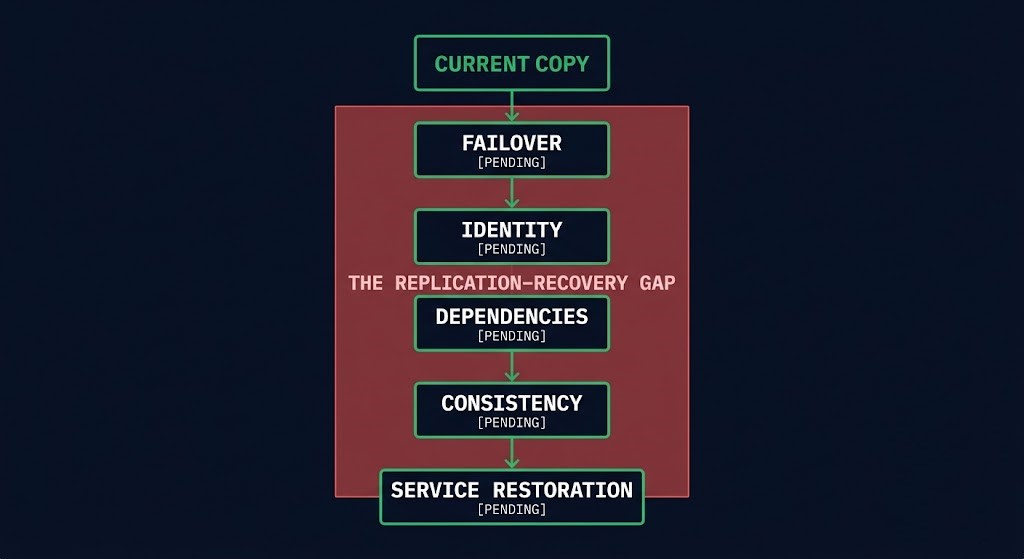
This is the heart of what I’ll call the Replication–Recovery Gap: the structural distance between data being current at a second site and a service being recoverable from it. A replica with a two-second RPO and an undefined RTO is not a recovery posture — it is a very current pile of bytes with no path back to a running system. Teams measure the left column obsessively and infer the right column for free. The right column is not free. It is not even addressed by the thing they are measuring. If you want the mechanics of why recovery metrics should drive infrastructure design rather than describe it after the fact, the RPO, RTO, and RTA breakdown goes deeper than this post can.
Replication Faithfully Copies the Disaster
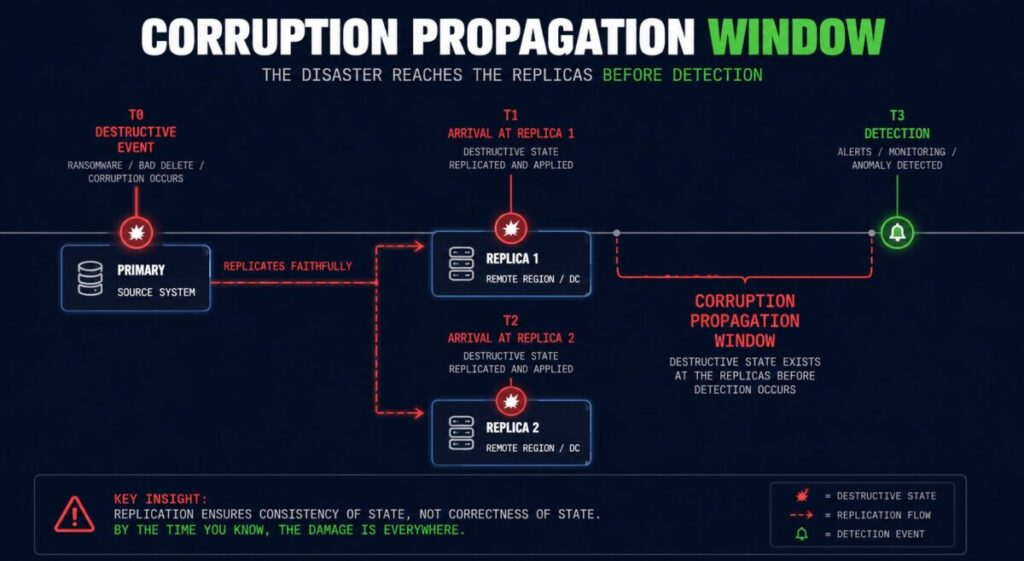
The second failure is more dangerous, because it turns your resilience investment into an accelerant. Replication has no concept of intent. It does not distinguish a legitimate write from a catastrophic one. Ransomware encryption, an accidental DROP TABLE, a malformed schema migration, a bad automation run, a deletion that should never have shipped — to the replication engine these are all just changes, and changes are what it exists to propagate. Faithfully. In seconds.
DIAGNOSTIC QUESTION
“When the destructive event lands on the primary, how long until it lands on every replica — and is that interval shorter than your detection time?”
That interval is the Corruption Propagation Window: the time between a destructive event reaching the primary and that same event being faithfully copied to every replica, before anyone detects it. Synchronous replication shrinks that window to near zero, which means the more aggressive your replication, the faster your disaster reaches your safety copy. The replica is not a recovery point. It is a mirror, and a mirror reflects ransomware as cleanly as it reflects a healthy transaction. This is why ransomware recovery is an architecture problem, not a backup problem, and why breaking the propagation path — air gaps, immutability, versioned point-in-time copies — is a categorically different capability from replication. Replication keeps the copy current. Recovery requires a copy that predates the event. Those are opposite design goals.

The Consistency Boundary Problem
Most DR writing stops at currency and corruption. The failure that practitioners understand least — and that takes down recoveries most quietly — is consistency. Not crash-consistency versus application-consistency at the single-database level, which is well-trodden ground covered in why crash-consistent is not a database backup. The harder problem is consistency across a system of independently replicated components.
A modern service is not one data store. It is a database, an object store, a message queue, a cache, an event stream, a search index — each with its own replication mechanism, its own lag, its own failure mode. The database replicates synchronously. The object store replicates with a few seconds of lag. The queue is not replicated at all because someone decided it was ephemeral. The cache is partially replicated. The event stream is asynchronous and eventually consistent by design.
Replicate each of those components independently and every one of them will report healthy at the destination. The database is current. The object store is current. The monitoring is green across the board. And the recovered system is still operationally invalid — because the messages in flight when the region failed exist in the database but not the queue, the cache references objects that replicated but points to a state the database has already moved past, and the event stream is hours behind the transactions that depend on it.
⚠ COMMON MISTAKE
Treating per-component replication health as system recoverability. Individually healthy components can collectively form an unrecoverable application — the inconsistency lives in the relationships between stores, which no single dashboard monitors.
This is the sentence to keep: recovery is not the restoration of systems — it is the restoration of relationships between systems. Replication operates on components. Recovery operates on the consistency boundary that spans them. Cross-region replication has no awareness of that boundary, which means it cannot protect it, which means a perfectly replicated multi-store system can fail over into a state that has never existed and cannot run.
Failover Is the Resilience. Replication Is Just Plumbing.
Here is the reframe that ties the first four failures together. Replication is passive. Recovery is active. Replication happens continuously, automatically, under normal conditions, and is measured every day. Recovery happens rarely, with humans in the loop, under abnormal conditions, and is measured exactly once — during the crisis you built it for. These are not two settings of the same capability. They are two different engineering disciplines, and being excellent at the first tells you nothing about the second.
The replica is dormant. It is data at rest in another region. Turning it into a serving system is an orchestration problem: promoting the standby, re-pointing traffic, sequencing dependent services, re-establishing identity and trust, validating consistency, and absorbing load that arrives all at once. Replication does none of that. The plumbing carries the water; it does not decide when to open the valve, in what order, or whether the pipes downstream are even connected.
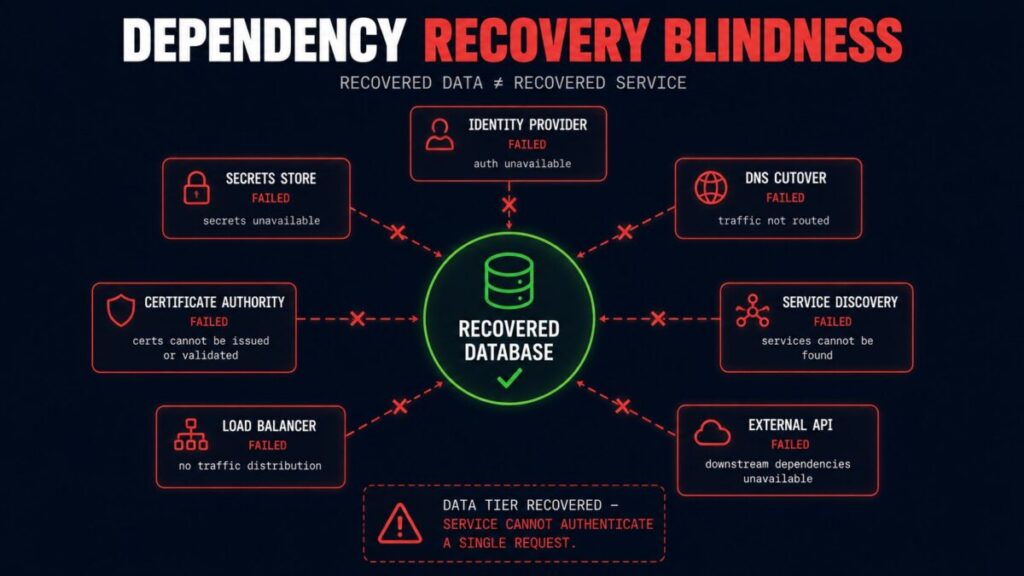
The Dependency Recovery Problem
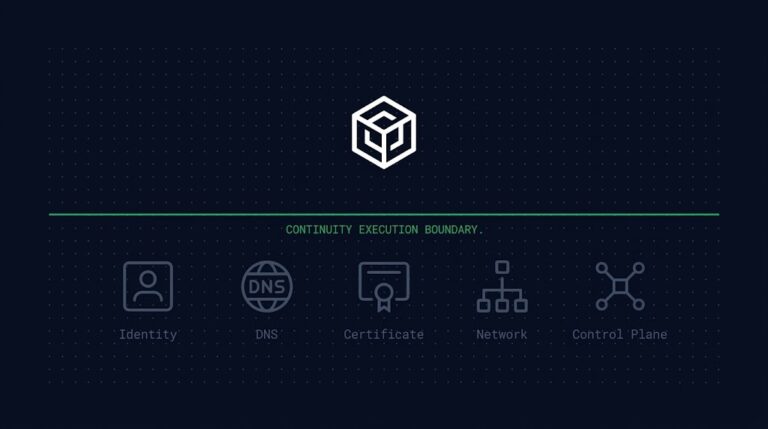
This is where modern recoveries actually die, and it deserves its own name: Dependency Recovery Blindness — the failure to recognize that a service recovers as a dependency graph, not as an infrastructure stack. Teams replicate the things they think of as “the data”: databases, storage, VMs. They routinely do not replicate, or do not failover, the things the data depends on to mean anything.
The database came back. But the identity provider it authenticates against is in the failed region. The secrets store that holds its credentials did not failover. DNS still resolves the service endpoint to the dead region because the cutover automation was never built. The certificate authority is unreachable, so mutual TLS fails between every service that did recover. Service discovery points at instances that no longer exist. The load balancer config lives in infrastructure-as-code that nobody applied to the recovery region. An external API the service calls has your dead region’s IP allowlisted.
Every one of those is a dependency, not a data store — and a recovery is only as complete as its least-recovered dependency. You can replicate the entire data tier flawlessly and still have a service that cannot authenticate a single request. This is why DNS failover so often doesn’t actually fail over, and why configuration drift surfaces precisely during a drill rather than before it. The dependency graph is where recovery fails, and replication has no view of the graph at all. When that dependency graph includes the backup infrastructure itself — sharing identity, network, and control plane with the systems under recovery — the failure mode has a specific name: Recovery Dependency Collapse. (When this same blindness scales to multiple providers, it becomes its own genre of theater — covered in Multi-Cloud Failover Is Mostly Theater.)
Recovery Is Exercised Under Stress
| Replication | Recovery |
|---|---|
| Continuous | Rare |
| Automated | Human-involved |
| Predictable | Chaotic |
| Measured daily | Measured during crisis |
| Operates during normal conditions | Operates during abnormal conditions |
The asymmetry in that table is the whole argument in miniature. Replication proves your infrastructure can copy data. Recovery proves that people, processes, dependencies, and systems can survive failure together, under pressure, on the worst day. A capability you exercise only during the incident is a capability you have never actually tested. Replication’s daily success is real — and it is silent about every column on the right.
What Resilience Actually Requires
If replication produces a current copy and recovery requires a great deal more, the gap between them needs a name you can design against. Call it Recovery State: the condition in which data, dependencies, orchestration, and operational authority are simultaneously available to restore service. Replication creates data state. Recovery requires recovery state. Every failure in this post is a specific way the two diverge — currency without a clean point, a copy that includes the disaster, components that are individually current but collectively invalid, a data tier that recovered without the dependency graph that makes it usable. Ransomware forces this distinction into the open faster than any other incident type: the recoverability gap is what’s left when a backup has satisfied every replication and completion metric and still hasn’t proven it can produce a validated recovery.
Designing for recovery state, rather than data currency, means treating the following as first-class:
| Capability | Replication | Recovery |
|---|---|---|
| Data currency | ✓ | Partial |
| Point-in-time recovery | ✗ | ✓ |
| Dependency orchestration | ✗ | ✓ |
| Identity availability | ✗ | ✓ |
| DNS cutover | ✗ | ✓ |
| Application consistency | Partial | ✓ |
| Service restoration | ✗ | ✓ |
The left column is what cross-region replication delivers. The right column is what a recovery actually consumes. Closing the distance requires immutable, versioned copies that predate corruption; consistency groups that span the components that fail together; a rehearsed, sequenced failover that includes identity, secrets, DNS, and trust; and an RTO that has been measured under realistic stress rather than asserted in a runbook. It also requires accepting that recovery does not end when systems restart — restored service is the beginning of the incident’s hardest phase, not the end of it, which is the thread the incident recovery process picks up where this post leaves off. Replication is not recovery; recovery is not restore; restore is not incident-closed. Each is a different obligation, and conflating any two of them is how resilience programs develop blind spots.
Where point-in-time integrity is the constraint rather than recovery time, the Veeam immutable storage cost estimator sizes the copies that replication structurally cannot provide.
Architect’s Verdict
Most resilience programs do not measure recovery. They measure replication success and assume recovery success — and the assumption holds right up until the day it is tested, which is the only day it matters. Replication is the easiest part of disaster recovery to buy, the easiest to monitor, and the easiest to mistake for the whole. Its reliability is exactly what makes the mistake so comfortable.
The real problem is not that teams trust replication. It is that they never name the difference between data state and recovery state, so they never design for the second. A current copy in another region is necessary. It is nowhere near sufficient. Everything that turns that copy into a running business — point-in-time integrity, cross-store consistency, the dependency graph, the sequenced and rehearsed cutover — sits in the space replication does not touch.
Replication answers one question: “Is the copy current?” Recovery answers a different question: “Can the business operate from it?” The distance between those two answers is where most disaster recovery strategies fail.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session