Multi-Cloud Failover Is Mostly Theater
Most multi-cloud architectures are designed to survive cloud outages. Very few are designed to survive failover. The distinction matters more than most architecture reviews acknowledge — and the gap between them is rarely discovered until the moment you need to close it.
Multi-cloud failover has become a standard response to three persistent concerns: vendor lock-in, cloud provider outages, and board-level resilience mandates. The architecture is conceptually sound. Workloads split across providers. A failure in one region or one cloud triggers a shift to another. Recovery proceeds. The design looks defensible. What the design rarely reflects is what happens when you actually try to execute it.
The Architecture Only Has to Survive Procurement
Multi-cloud failover gets approved because it satisfies risk narratives — not because it has been operationally validated. Board concerns about cloud concentration risk get addressed. Vendor lock-in objections get answered. The resilience column in the risk register gets a checkmark. The architecture appears to solve the problem it was purchased to solve.
The architecture is evaluated during procurement. The failover is evaluated during an outage. Those are often years apart.
In that gap, nobody budgets for proving the architecture works. Nobody allocates engineering cycles for quarterly failover validation. Nobody funds cloud-to-cloud recovery exercises that would surface the dependency failures, identity mismatches, and data state inconsistencies that accumulate quietly while the architecture sits unused. The result is predictable: organizations purchase resilience. They never operationalize it.
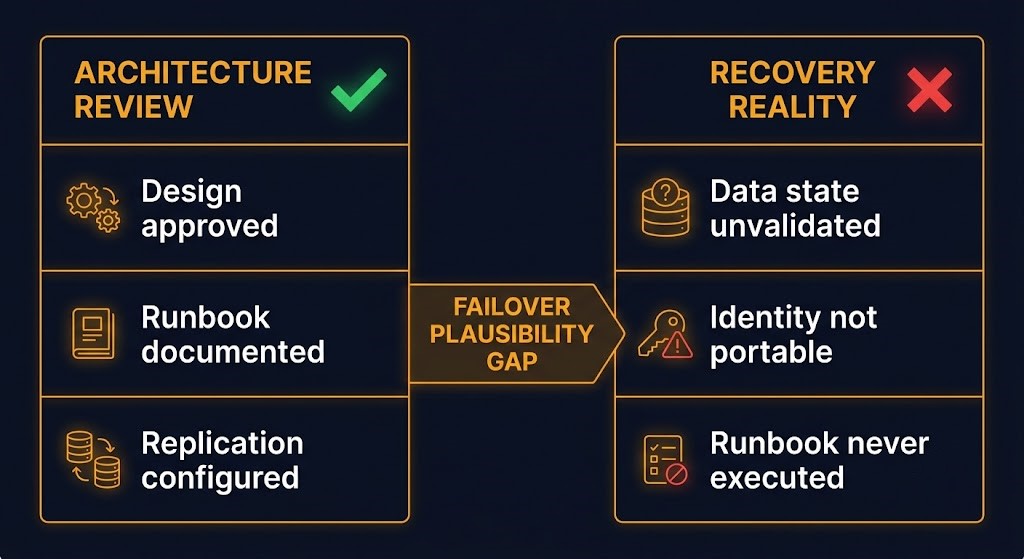
This is not a technical failure. It is an incentive structure failure. The procurement process rewards architectural plausibility. It does not reward operational proof. A multi-cloud failover design that passes architecture review and a multi-cloud failover design that has been executed under realistic conditions look identical in documentation. The organization cannot tell the difference until it matters.
The architecture only has to survive procurement. Recovery has to survive reality. Those are different requirements, evaluated at different times, by different people, under entirely different conditions.
Framework #113 — The Failover Plausibility Gap
This pattern has a name.
FRAMEWORK #113 — FAILOVER PLAUSIBILITY GAP
The distance between a failover architecture appearing recoverable in design documentation and being operationally recoverable under realistic failure conditions.
Multi-cloud failover strategies often survive architecture review because they are plausible. They fail recovery validation because they are unproven.
The Failover Plausibility Gap is not unique to multi-cloud environments — it appears anywhere an architecture is designed for a failure mode that is never exercised. But it concentrates in multi-cloud failover because the architecture is complex enough to appear credible, expensive enough to feel like a real investment, and rarely tested because testing it is operationally disruptive and organizationally unrewarded.
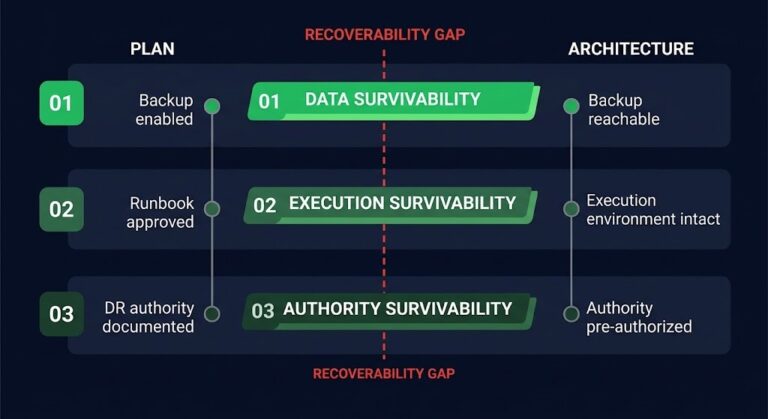
The four assumptions that create the gap are consistent across environments: identical or equivalent service availability in the target cloud, portable identity and policy models, synchronized or recoverable data state, and runbooks that have been executed under realistic conditions. Most multi-cloud environments satisfy none of these at failover time. Each assumption looks reasonable in design. Each collapses under operational pressure.
Data State Is the Problem Nobody Wants to Solve
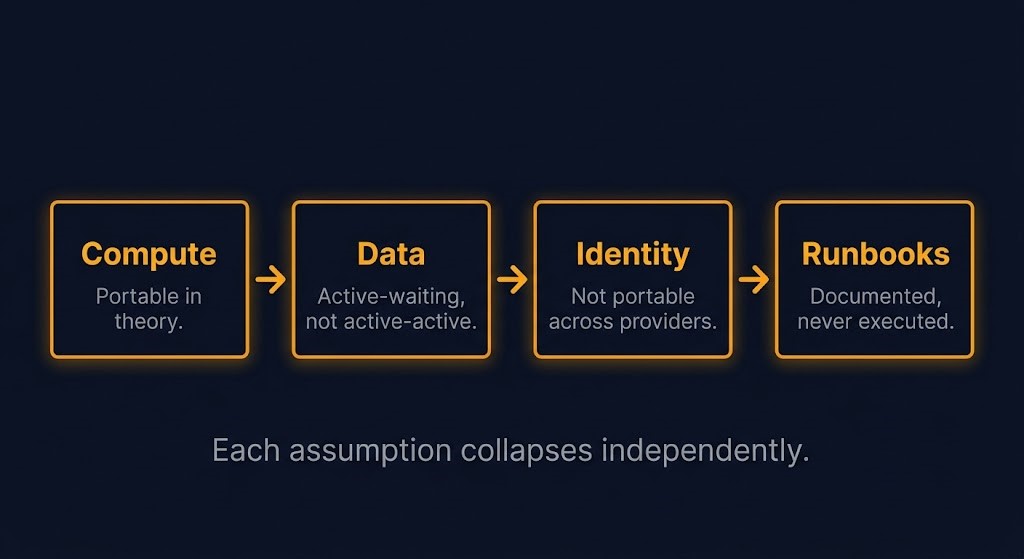
Multi-cloud failover discussions default to compute. Which instances run where, how traffic routes, which load balancers activate. Compute is portable in concept and the cloud providers make it easy to believe that is where the complexity lives.
It is not where the complexity lives.
Active-active data synchronization across cloud providers is expensive, latency-constrained, and conflict-prone in ways that make most organizations quietly design around it rather than through it. Cross-cloud replication introduces latency that forces consistency tradeoffs most applications cannot absorb cleanly. Conflict resolution at the data layer — when writes happen on both sides of a failover boundary — requires application-level logic that was usually not part of the original design. Storage architectures optimized for a single cloud’s block or object storage primitives do not translate directly to another provider’s equivalents without re-platforming that looks a lot like migration.
The result is that most multi-cloud data strategies are not active-active. They are active-waiting. One cloud holds the authoritative state. The other holds a replica that may or may not be consistent at failover time, may or may not include recent transactions, and may or may not include the metadata and configuration state that the application requires to resume operation. Cross-region replication has the same structural problem — replication confirms data movement, not data recoverability.
⚠ COMMON MISTAKE
Treating replication as failover readiness. Replication confirms that data moved. It does not confirm that the replica is consistent, complete, or that the application can resume against it. These are separate properties that require separate validation.
Data gravity doesn’t fail over.
The Identity Problem Is Usually Worse Than the Compute Problem
Most multi-cloud failover content treats identity as a configuration problem. The cloud provider docs describe it as a migration step. Neither framing is accurate when the failover is unplanned and time-pressured.
IAM policies between major cloud providers do not translate cleanly. AWS IAM role structures, permission boundaries, and service control policies have no direct equivalent in Azure Entra ID or GCP IAM — the models differ at the level of how identity is attached to compute, how trust relationships are established between services, and how authorization is evaluated at runtime. An IAM policy that is correct in one environment must be rebuilt, not migrated, in another.
Cloud-native service identities — the identities assigned to running workloads for service-to-service communication — are not portable. An AWS instance profile identity cannot be presented to a GCP service. The trust relationship that allows a service to call another service in one cloud does not exist in the other until it is explicitly constructed. In a planned migration this is a documented step. In an unplanned failover it is a dependency that fails silently until something that should work doesn’t.
Secrets management compounds this further. Secrets stored in AWS Secrets Manager, Azure Key Vault, or GCP Secret Manager are not automatically available across providers. Certificate chains differ. Service mesh identities differ. The authorization models that determine which service is allowed to call which other service at runtime — often established through platform-specific primitives — do not survive a cross-cloud boundary intact. This is the same reconstruction-authority question the Infrastructure Pipeline Survivability Analyzer scores directly — whether identity and secrets retrieval can execute independent of the environment being recovered, before a failover path is ever invoked.
This connects directly to Dependency Recovery Blindness (#101) — the failure mode in which a recovery plan restores individual components without accounting for the dependency relationships that determine whether the recovered environment can actually function. In multi-cloud failover, compute comes back. Identity doesn’t follow automatically. The application fails to authenticate, fails to authorize, or fails to retrieve the secrets it needs — and the failover that looked clean in the runbook surfaces three cascading failures that were never in scope.
The Runbook Problem
Runbooks that have never been executed under realistic conditions are not runbooks. They are documentation with an assumed outcome.
Most multi-cloud failover runbooks are written during the architecture phase, updated occasionally when the infrastructure changes, and never executed against a realistic failure scenario. The DNS cutover steps assume a TTL that may not match the actual configuration. The database promotion steps assume a replica lag that may not reflect actual replication state at the time of failure. The identity re-establishment steps assume that the IAM policies written during initial deployment are still correct — which requires someone to have kept them current across two cloud environments simultaneously.
DR testing has the same structural problem at the recovery layer. The Recovery Validity Boundary (#111) defines the threshold a test must cross to produce genuine evidence of recovery capability — not just evidence of test completion. For multi-cloud failover, crossing that boundary means executing the full failover path: DNS cutover, data state validation, identity re-establishment, dependency verification, and a functional test of the recovered environment under load. Most exercises stop well short of this. The runbook gets walked through. The environment is not actually failed over. The organization records a successful DR exercise and the Failover Plausibility Gap remains exactly as wide as it was before the test. The structural reason most exercises fall short of the Recovery Validity Boundary — and what genuine evidence of recovery capability requires — is mapped in Why Most Disaster Recovery Tests Don’t Test Recovery. The upstream problem that precedes runbook failure is in Cross-Region Replication Is Not Resilience — replication confirms movement, not recoverability, which is the same gap the Failover Plausibility Gap compounds.

What Actual Multi-Cloud Resilience Requires
Multi-cloud resilience is not the same as a multi-cloud architecture. The architecture is a precondition. Resilience is what the architecture demonstrates under pressure.
The organizations that have genuine multi-cloud failover capability share several characteristics that distinguish them from organizations that have multi-cloud failover documentation. They have identified specific workloads — not the entire environment — where cross-cloud recovery is genuinely required and worth the operational cost to validate. They have tested those specific workloads under realistic failure conditions, which means an actual failover execution, not a walkthrough. They have established a repeatable validation cadence, because a test that was accurate eighteen months ago is not evidence of current recoverability. And they have accepted that multi-cloud resilience is an operational discipline, not an architectural state. The movement constraint that multi-cloud architecture creates — how redundancy design produces egress lock-in rather than movement optionality — is mapped in full at Movement Architecture, the Operational stage of the Cloud Strategy Architecture Learning Path.
Scoping is the lever most organizations resist using. Multi-cloud failover for everything sounds like resilience. Multi-cloud failover for the three workloads where it has been proven sounds like a gap. The latter is more defensible because it is true.
DIAGNOSTIC QUESTION
“Which workloads have been failed over and recovered under realistic conditions in the last 90 days?”
“Which data stores were validated after recovery?”
“Which identities were re-established during the exercise?”
“Which dependency failed during testing?”
“Which failure scenario was the exercise designed to simulate?”
If every answer is “none,” the architecture has not demonstrated recoverability. It has demonstrated plausibility.
Azure’s July 23 outage is a worked instance of plausibility passing as validation from the other direction. The redundant-path check wasn’t skipped — it ran, and it passed. What failed was scope: the automation touched devices the check was never evaluated against. A passing check and an unconstrained failure are not contradictory. They’re the same architecture gap this post names, one layer removed from failover specifically.
The ownership question underneath every one of these diagnostic answers is the same one Framework #157 names directly: Multi-Cloud Coherence Is an Ownership Problem, Not a Technology Problem. A failover that has never been exercised is a technology gap. A failover where nobody can say which provider’s team is accountable for the decision to invoke it is an ownership gap — and it’s the more common failure of the two.
Architect’s Verdict
Multi-cloud failover fails for the same reason most recovery programs fail: the data state was assumed and the dependencies were assumed.
The Failover Plausibility Gap exists because architectures are reviewed as designs but recoveries are proven as operations. A multi-cloud environment can appear recoverable for years without ever demonstrating recovery capability. The procurement process that approved the architecture had no mechanism for verifying it — and no one built one afterward.
Multi-cloud architecture does not create multi-cloud resilience. Recovery capability begins at the point where failover has been executed, validated, and repeated under realistic conditions.
Most multi-cloud strategies live inside the Failover Plausibility Gap. The architecture appears recoverable. The recovery has never been proven.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session