Why Most Disaster Recovery Tests Don’t Test Recovery
The test passed. The runbook completed. Infrastructure came back online inside the RTO window. None of that means the organization can recover from an actual disaster.
Disaster recovery testing is designed to succeed. Clean environments, pre-staged dependencies, known failure modes, available staff — each design decision is operationally reasonable. Collectively they remove the conditions that make real recovery hard. What the test validates is test completion, not recovery capability. The gap between those two things is where real incidents live, and it is why organizations with mature DR programs still fail to recover on schedule when a real event occurs.

The Test Is Designed to Pass
Every design decision in a standard DR test tilts toward a successful outcome. The test window is pre-announced, so the right engineers are available. The scope is pre-defined, so unexpected systems don’t surface mid-exercise. The environment is either isolated or pre-staged, so competing failures don’t complicate the recovery sequence. The data state is known and clean, so integrity issues don’t slow the restore. The declaration point is assumed, so nobody has to make an ambiguous call under pressure.
None of these decisions are wrong in isolation. Controlled tests have legitimate uses — validating runbook syntax, confirming tooling, training new staff on recovery procedures. The problem is when a controlled test is treated as evidence of recovery capability under real incident conditions. A test designed to remove the variables that make recovery hard cannot produce evidence about what happens when those variables are present. It produces evidence about what happens when they are absent, which is a different problem entirely.
What Disaster Recovery Testing Actually Excludes
The five categories below are not edge cases. They are standard features of real incidents that standard DR tests are explicitly designed to exclude.
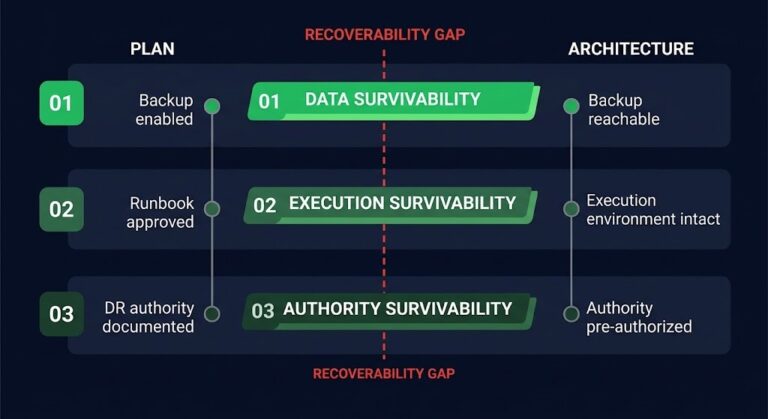
Declaration threshold. In a DR test, recovery starts at a pre-agreed time. In a real incident, recovery starts when someone decides the situation has crossed the threshold for declaration — a decision that is rarely clean, frequently contested, and routinely delayed by 45 minutes to several hours while the team attempts to resolve the issue without escalating. That delay is inside the real outage window and outside the test clock. It never appears in the RTO validation. The structural reason it keeps happening is that most DR plans don’t define disaster recovery authority — who holds declaration rights, what the threshold criteria are, and who has standing to make the call when the primary coordinator is unavailable.
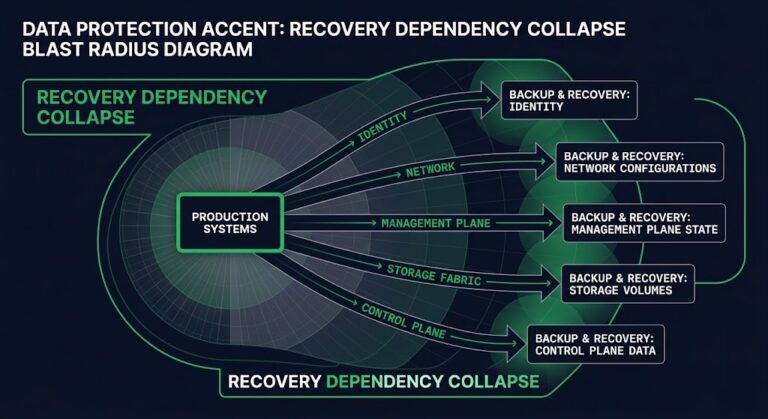
Dependency assumptions. DR tests run against known, pre-cleared dependencies. Systems that the recovery sequence relies on are confirmed available before the test begins. Real incidents surface undocumented dependencies that were never in scope — a configuration service that hasn’t been touched in two years, an authentication endpoint that wasn’t in the architecture diagram, a database the recovery team didn’t know existed. These surface at the worst possible time and have no place in a test that pre-cleared everything before the clock started.
The deeper structural risk is that those undocumented dependencies may include the backup infrastructure itself — sharing identity, control plane, or network path with the systems under recovery. That condition has a name: Recovery Dependency Collapse, and it is not detectable from standard DR testing or backup monitoring.
Data state. Test environments use clean or pre-staged data. Real recovery requires handling whatever state the data was in at the moment of failure — partial transactions, corrupted blocks, inconsistent replication lag, log files that don’t match what the restore expects. The application-consistent backup architecture problems that compound this don’t appear in tests that use pre-staged clean datasets.
Staffing assumptions. DR tests happen when the right people are available. Real incidents happen when the incident decides they should happen — not during business hours, not when the primary SME is in the building, not when the team isn’t already managing three other things. The organizational recovery capability that a test validates is the best-case staffing scenario, not the realistic one.
Cascading failure. Tests run in isolation. A declared DR scenario has clean boundaries. Real disasters frequently involve concurrent failures outside the declared scope — the monitoring system that went down with the primary, the ticketing platform that isn’t available during the recovery, the network segment that is degraded but not failed. Real recovery happens against a background of partial failures that DR tests never introduce.
Recovery Validity Boundary — Framework #111

A DR test that controls its own conditions can only prove that the controlled conditions produce the expected outcome. It cannot prove recoverability under uncontrolled conditions — which is the only condition that actually matters.
The Recovery Validity Boundary is the threshold a DR test must cross to produce genuine evidence of recovery capability, as distinct from evidence of test completion. Four criteria determine whether the boundary has been crossed:
01 — DECLARATION EXERCISED
The declaration threshold was exercised, not assumed. Someone in the test had to make a real judgment call about when recovery conditions were met — not start the clock at a pre-agreed time.
02 — DEPENDENCIES NOT PRE-CLEARED
Dependency scope was not confirmed or staged before the test began. The recovery sequence had to discover and resolve its own dependency map as part of the exercise.
03 — UNPLANNED VARIABLE ABSORBED
At least one variable outside the test script was introduced and absorbed. Not full chaos engineering — but not zero. Recovery succeeded despite something the runbook didn’t account for.
04 — INDEPENDENTLY VALIDATED
Recovery outcome was independently validated rather than declared successful by the recovery team. Self-graded tests produce self-serving results. The team that runs the recovery is the wrong team to certify it succeeded.
The fourth criterion is the one most programs skip entirely. A team can satisfy criteria one through three and still produce useless evidence if the team that executed the recovery is also the team that decided it passed. Independent validation is what separates evidence from confidence.
Through-line: “A DR test that controls the conditions is not a test. It is a rehearsal.”
DIAGNOSTIC QUESTION
“When did your last DR test introduce an unplanned variable — and who declared it successful?”
Why Disaster Recovery Tests Become Easier Every Year
Teams do not intentionally make DR tests easier. They optimize for the metric they are tracking, and the metric they are tracking is test completion. Each annual exercise produces cleaner runbooks, more pre-staging, fewer surprises, and narrower scope. The team gets better at running the test. Success rates improve. Confidence in recovery capability increases.
What actually happened is that recovery evidence declined while rehearsal fidelity improved. The runbooks are tighter because the team has run them multiple times under controlled conditions. The pre-staging is more thorough because the team learned what they needed from the previous exercise. The scope is narrower because ambiguous systems were quietly removed after they caused friction. Every one of those improvements makes the test easier and the evidence weaker.
The easier a DR test becomes, the less it resembles a disaster.
This is not a failure of discipline. It is the natural outcome of treating test success as the goal instead of recovery validity. The program measures what it can measure — completion rates, RTO adherence in test, runbook coverage — and the team optimizes accordingly. The Recovery Validity Boundary is never measured, so it never improves.
Recovery Clock Distortion
The documented RTO gap between committed recovery time and actual recovery time in production incidents is not primarily a technical problem. It is a measurement problem. DR tests and real incidents are measuring different things and calling both of them RTO.

Test clock:
| Event | Time |
|---|---|
| Recovery starts | 10:00 |
| Service restored | 11:00 |
| RTO validated | 60 minutes |
Real incident clock:
| Event | Time |
|---|---|
| Infrastructure failure | 08:15 |
| Incident declared | 09:05 |
| Recovery starts | 09:15 |
| Service restored | 10:15 |
| Actual outage duration | 120 minutes |
The recovery execution in the real incident took 60 minutes — identical to the test. But the total outage was 120 minutes because the test clock started at first recovery action, not at failure. Declaration delay, escalation time, initial triage, and dependency identification consumed the first 60 minutes before the recovery sequence started. None of that appears in the RTO validation because none of it was in scope for the test.
Recovery Clock Distortion is the gap between when recovery timing begins in tests and when recovery timing begins in reality. It is not a measurement error — it is a scope error. The test was measuring the right thing for the test scope. The test scope excludes the part of the outage that most affects business impact.
The Replication–Recovery Gap, Dependency Recovery Blindness, and Recovery State frameworks (Frameworks #99–#102) describe what accumulates in the gap between replication and actual recovery. Recovery Clock Distortion names why that gap goes undetected in standard testing programs. When the recovery path crosses multiple cloud providers, the distortion compounds — untested cross-cloud failover sequences carry declaration delay, dependency blindness, and consistency failures simultaneously. That failure pattern is covered in Multi-Cloud Failover Is Mostly Theater.
⚠ TEST VALIDITY DECAY
Every successful DR test becomes progressively less valid as infrastructure changes accumulate after the test completes. Configuration drift, new service dependencies, platform updates, and staffing changes are all invisible to a test that hasn’t run since they were introduced. The test validated the infrastructure that existed when it was designed — not the infrastructure that will be running when the disaster occurs.
What a Test That Crosses the Validity Boundary Actually Requires
Crossing the Recovery Validity Boundary does not require chaos engineering at scale. It requires removing the structural controls that prevent the test from producing real evidence.
In practice that means five things. The RTO clock starts at failure detection, not at first recovery action — capturing declaration delay and initial triage as part of the measured window. The dependency map is validated as part of the test, not pre-confirmed beforehand — the recovery sequence has to find what it needs under exercise conditions. The data state includes at least one integrity challenge — a dirty backup, a replication lag, a restore that requires verification before the system can be declared healthy. A bounded unplanned variable is introduced — something outside the script that the team has to absorb without stopping the exercise. And recovery outcome is validated by someone who was not part of the recovery execution.
None of these requirements are technically complex. They are organizationally difficult because they produce a higher failure rate in the short term. Tests that introduce unplanned variables sometimes fail. RTO windows that include declaration delay look worse than RTO windows that don’t. The metric gets worse before it gets better. That is exactly the signal the program needs — and the signal that optimizing for test success systematically suppresses.
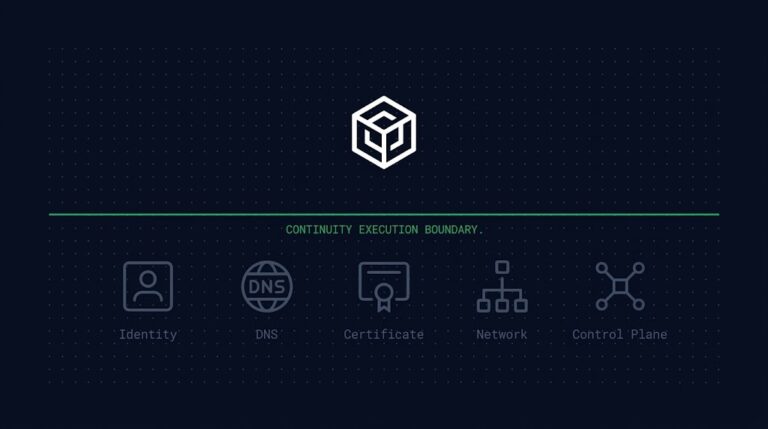
A related requirement sits outside this list because it concerns the test’s premise rather than its execution: whether the platform running the recovery exercise would still be operable if the test conditions were real. A test can satisfy every requirement above and still produce a false positive if the backup console, orchestration layer, or recovery credentials used during the exercise happen to share infrastructure with the systems being recovered. Recovery Platform Architecture, the second stage in the Data Protection & Resiliency Learning Path, is built to test that premise directly — whether the platform and the authority to operate it would survive the same incident the recovery test is meant to validate against. A second premise sits outside the list for the same reason: even a test that clears all four Recovery Validity Boundary criteria only validates that recovery executes — it says nothing about whether the six continuity dependencies named in the Continuity Execution Boundary (#163) failed over with it.
The Recovery Doesn’t End the Incident and The Degradation Ladder posts in the Recovery Engineering series cover the operational layer of what real recovery looks like once the validity boundary has been crossed. This post is about the test design gap that precedes it.
Architect’s Verdict
Most DR programs are not measuring recovery capability. They are measuring rehearsal fidelity. That distinction matters because rehearsal fidelity goes up over time — the team gets better at running the test — while actual recovery capability may be degrading as infrastructure complexity accumulates outside the test scope.
Rehearsals improve because participants learn the script. Recovery improves only when the script stops working and the system still survives.
The Recovery Validity Boundary is where the evidence stops. Declaration was assumed, not exercised. Dependencies were pre-cleared, not discovered. Recovery was self-certified, not independently validated. The test passed every criterion it was designed to pass, which is a different thing from passing the criterion that matters: can this organization actually recover?
If the test never crossed the boundary, the organization does not know what it knows. It knows the rehearsal worked. That is not the same thing.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session