Your Backup System Is Part of the Blast Radius
The call came in at 02:00. Production encrypted. By 02:10, recovery had been declared. By 02:15, the backup console was unreachable. By 02:20, the identity provider was down — same AD domain as production. By 02:30, the repository had been located. By 02:35, nobody could authenticate to it. By 02:40, the team understood what had actually happened. The backup existed. It was intact. It could not be reached. The backup blast radius had consumed the recovery infrastructure along with everything else.
That is not a backup failure. It is an architecture failure — and it had been present in the environment for years before anyone noticed.
What Blast Radius Means for Backup Architecture
Blast radius is the set of systems degraded or destroyed by a single failure event. Most architecture reviews scope it to production: which services go down, which workloads are affected, how far the failure propagates through the application stack. That scope is incomplete.
Backup infrastructure shares an environment with the systems it protects. It authenticates somewhere. It traverses a network. It runs on a management layer. It writes to storage. Every one of those connections is a dependency — and every dependency is a potential path through which a single failure event can propagate from production into the recovery layer.
The backup blast radius is the portion of that failure event that reaches backup and recovery infrastructure. When it is large enough to make recovery impossible at the moment recovery is needed, the result is not a backup problem. It is a structural failure mode with a specific name — and it sits at the center of data protection architecture that most organizations have never fully audited.
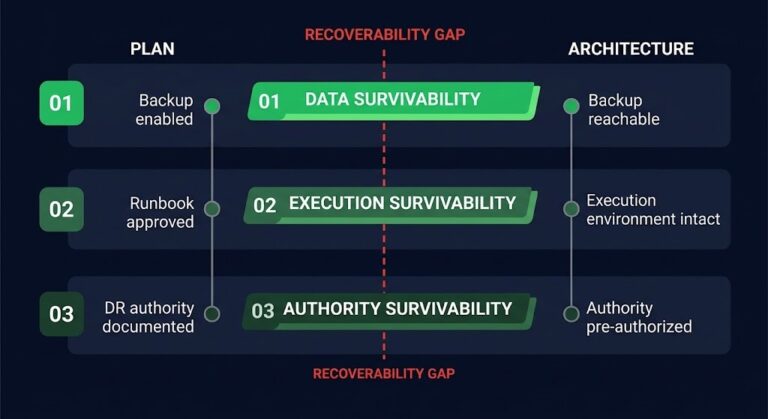
Framework #122 — Recovery Dependency Collapse
Recovery Dependency Collapse occurs when backup infrastructure survives logically but fails operationally because the dependencies required to access it did not survive the incident.
The distinction matters precisely. The backup exists. The data is there. The retention policy ran correctly. The repository is intact. None of that is the failure. The failure is that the identity layer required to authenticate, the network path required to reach it, the management plane required to run recovery jobs, or the control plane required to authorize access — did not survive the same event the backup was designed to outlast.
FRAMEWORK #122 — RECOVERY DEPENDENCY COLLAPSE
- The failure mode in which backup and recovery infrastructure shares enough production dependencies that a single incident can degrade both primary operations and recovery capability simultaneously.
- Not a backup job failure. Not an RPO miss. A structural collapse in which the backup exists and cannot be used.
- Recovery Dependency Collapse is realized when the dependency required to access the backup does not survive the event that triggered recovery.
⚠ ARCHITECTURE FAILURE
Backup infrastructure that shares production dependencies is not a fallback. It is a delayed failure. The question is not whether the backup exists. The question is whether it survives the event that made it necessary.
This failure mode is not detectable from standard backup monitoring. Completion rates, retention compliance, and RPO alignment all measure whether backups are being created. None of them measure whether the infrastructure required to use those backups survives a real failure event.
The Five Dependency Paths That Create It
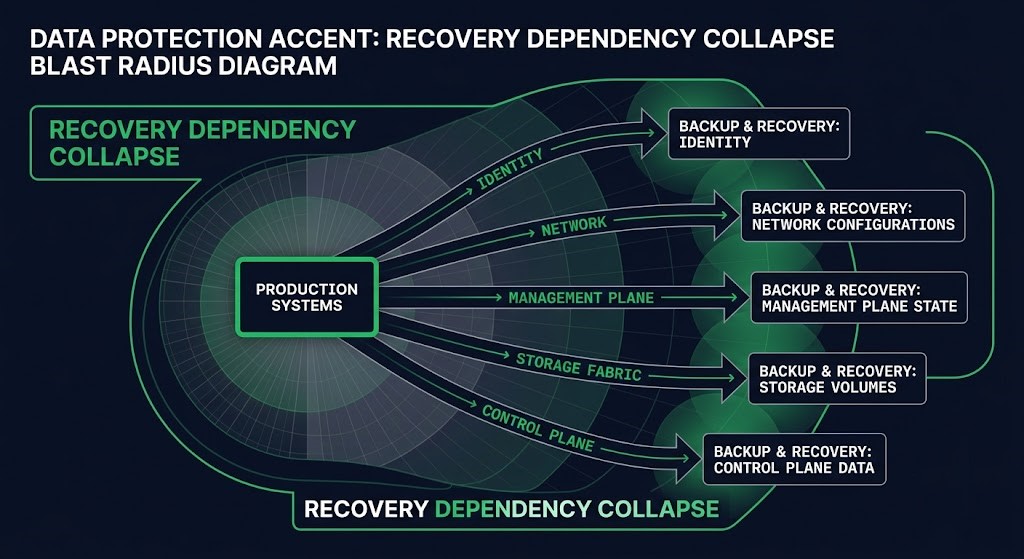
Recovery Dependency Collapse is not a single failure. It is a structural condition realized through specific dependency chains. Five paths are the most common vectors through which backup infrastructure gets pulled inside the production blast radius.
THE FIVE DEPENDENCY PATHS
- Identity — Backup platform authenticates against the same Active Directory or IdP as production. Domain controllers encrypted or unavailable means backup access is gone.
- Network — Backup traffic traverses the same switching fabric, the same firewall rules, the same segments as production traffic. A network-layer failure or segmentation attack takes both paths simultaneously.
- Management Plane — Backup orchestration runs on the same hypervisor cluster, the same vCenter instance, the same management VM stack as the workloads being protected. Hypervisor compromise or management plane failure makes backup jobs unrunnable.
- Storage Fabric — Backup repositories sit on the same SAN or NAS fabric, the same storage controllers, the same underlying hardware as production storage. A storage-layer event propagates directly into the backup tier.
- Control Plane — The most frequently missed dependency in modern environments. Backup SaaS platforms become inaccessible when the cloud IdP is unavailable. Cloud backup policies are managed through the same cloud account being recovered. Backup orchestration depends on the same API authority layer that the incident has compromised. Recovery tooling requires access to a vCenter instance that is no longer reachable.
The control plane dependency deserves particular attention. In cloud-native and hybrid environments, recovery increasingly depends on access to an API authority layer rather than physical infrastructure. Losing access to the cloud account — through compromised credentials, locked IAM policies, or an unavailable IdP — can be functionally equivalent to losing access to the backup itself. Modern ransomware operations understand this. Attacks on identity and control plane infrastructure before touching production data are now a documented pattern, not an edge case. The backup data survives. The authority layer required to access it does not.

Why Backup Audits Miss This Entirely
Most backup audits are scoped to the data layer. They verify that jobs completed, that retention policies ran, that RPO targets were met. These are the right metrics for evaluating whether backups exist — and the wrong metrics for evaluating whether recovery remains possible.
| What Backup Audits Measure | What They Don’t Measure |
|---|---|
| Backup job completion rate | Recovery authority under failure conditions |
| Retention policy compliance | Dependency independence from production infrastructure |
| RPO alignment | Backup platform survivability during an incident |
| Repository capacity and health | Control plane availability at the moment recovery is declared |
| Deduplication and compression ratios | Identity layer recoverability without production IdP |
The gap is structural. Auditing whether backups exist is a different scope from auditing whether recovery is possible. Very few organizations run the second audit. The dependency graph — which systems the backup infrastructure relies on, and whether those systems share the failure condition the backup was designed to survive — is almost never examined as a recovery concern.
What Architectural Isolation Actually Requires
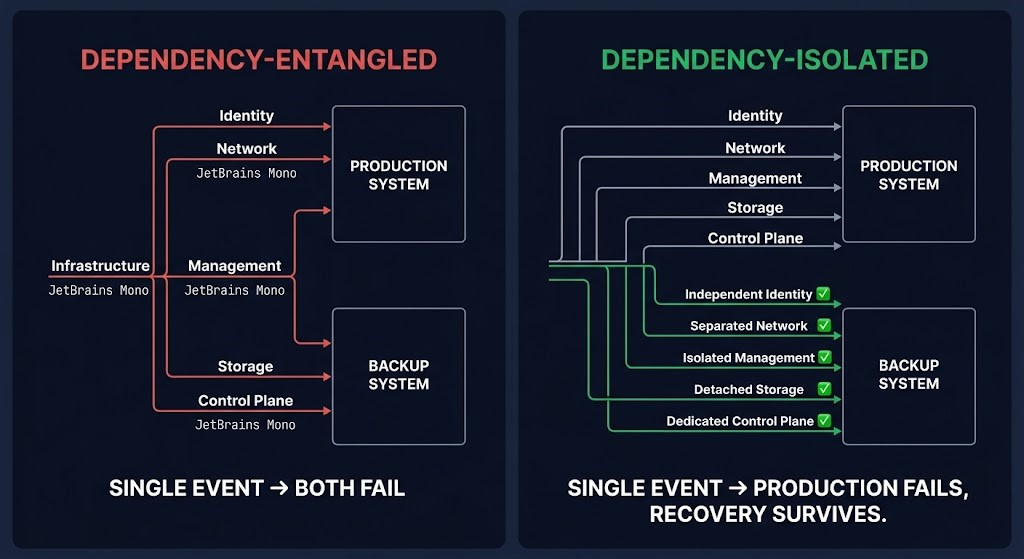
Isolation is not measured by where a system resides. Isolation is measured by what it depends on.
A backup system on a dedicated physical server that authenticates against the same Active Directory domain as production is not isolated. A cloud backup repository in a separate region that is accessed through the same cloud account being recovered is not isolated. Physical separation, geographic distribution, and logical naming conventions do not constitute isolation if the dependency graph remains shared.
Genuine isolation requires that each of the five dependency paths is independently survivable:
Identity isolation — Backup platform service accounts are separate from production identity. Local authentication fallback exists that does not depend on the production IdP. MFA is not routed through the same identity infrastructure that is under attack.
Network isolation — Dedicated backup VLAN or out-of-band management path exists that does not traverse production switching fabric. Backup traffic is not dependent on the same firewall rules that govern production traffic.
Management plane isolation — Backup orchestration is not hosted on the same hypervisor cluster it protects. The management VM stack for backup operations is independent of the management infrastructure for production workloads.
Storage isolation — Backup repositories sit on a separate storage domain. Immutable storage targets are logically or physically air-gapped from the production storage fabric. The storage controllers that serve backup repositories are not shared with production.
Control plane isolation — Backup SaaS credentials are stored independently from production cloud IAM. Cloud account access for recovery operations is separate from the account being recovered. API authority for backup orchestration does not share the same authorization layer as the infrastructure under incident. Where possible, a dedicated recovery account with scoped permissions exists outside the primary organizational IAM boundary.
These five isolation domains describe the architecture of the backup platform itself. A related but distinct question is whether the people and processes authorized to operate that platform survive the same incident the isolation work was designed to outlast. A backup system can be architecturally isolated across identity, network, management plane, storage, and control plane — and recovery can still stall if the engineers who know how to run it are unreachable, or if the approvals required to authorize recovery actions depend on systems inside the blast radius. Recovery Platform Architecture, the second stage in the Data Protection & Resiliency Learning Path, picks up where dependency isolation leaves off — testing whether the platform and the authority required to operate it remain functional together under the failure conditions an organization is most likely to face. Dependency isolation and platform authority both assume a clean-failure model — infrastructure lost, not infrastructure actively opposed. Whether that isolation holds against an adversary who specifically targets these five dependency paths is the separate question Data Protection — Maturity Stage 4 — Ransomware Survival Architecture evaluates directly.
The Data Protection & Resiliency Learning Path covers the full architectural progression from dependency isolation through sovereign recovery architecture.
Replication Is Not Isolation
Cross-region replication solves a geographic distribution problem. It does not touch the dependency graph.
Replication increases distance. Isolation reduces dependency. These are not the same architectural objective.
An organization can replicate backup data to three geographic regions and still have every one of those repositories dependent on the same cloud account, the same IdP, the same API authority layer. The data is geographically distributed. Recovery Dependency Collapse is still fully present. The blast radius follows the dependency graph, not the network topology.
Both replication and isolation are required. Neither substitutes for the other. Geographic redundancy addresses what happens if a data center is unavailable. Dependency isolation addresses what happens when the authority structures required to access the data are unavailable. The second failure mode is more common in adversarial events, and almost always less prepared for. Understanding where the blast radius ends is necessary but not sufficient. When recovery is declared, a second architectural gap opens: the restore process itself. Backups that survive the blast radius still fail at restore time when restore architecture has never been designed — five dependency layers beyond data recovery that most environments leave entirely assumed. A third gap sits alongside both: a backup that has never had its recovery validated carries the same false confidence, regardless of whether the dependency graph is isolated or the restore layers are designed.
For a detailed examination of why replication strategies fail to address resilience at the dependency layer, see Cross-Region Replication Is Not Resilience.
Architect’s Verdict
Backups are evaluated as a data protection system. Job completion rates, retention policies, RPO alignment — these are the right measures for whether data is being preserved. They are the wrong measures for whether recovery is architecturally possible.
Recovery is a dependency architecture problem. The data exists. The question is whether the authority structures, network paths, management surfaces, and control plane access required to reach it survived the same event that triggered recovery. Those things are not measured by backup monitoring. They are not verified by backup audits. They are not visible in job completion dashboards. They are only discovered when recovery is declared and the dependency chain fails in sequence.
The question is not whether the backup exists. The question is whether it survives the event that made it necessary.
Infrastructure that shares the failure condition it was designed to survive is not recovery infrastructure. It’s a second victim.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session