Most AI Control Planes Have a Single-Region Failure Domain
The cloud spent fifteen years teaching architects to think in availability zones, regional redundancy, and distributed failure domains. The assumption embedded in that training is that compute is fungible — that a workload running in us-east-1 can shift to us-west-2 without architectural consequence. For stateless web tiers, that assumption holds. For AI control plane architecture, it does not.
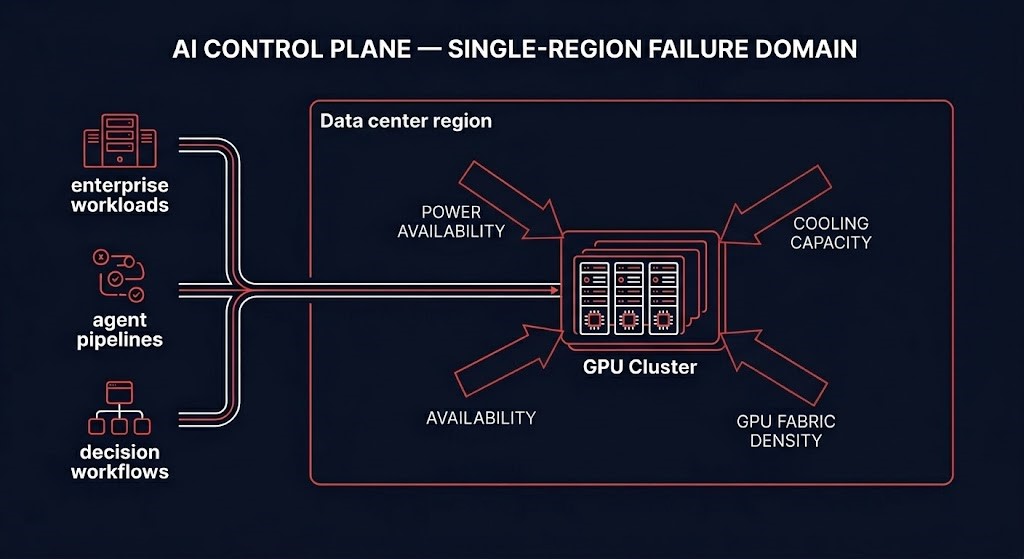
Most enterprise AI control planes have a single-region failure domain. Not because of poor planning, but because the infrastructure AI inference depends on cannot be distributed the same way traditional cloud workloads can. The physics are different. The placement economics are different. And the failure mode when that region disappears is categorically different from anything the availability zone model was designed to address.
AI Control Plane Architecture Depends on Infrastructure That Doesn’t Scale Like Cloud Infrastructure
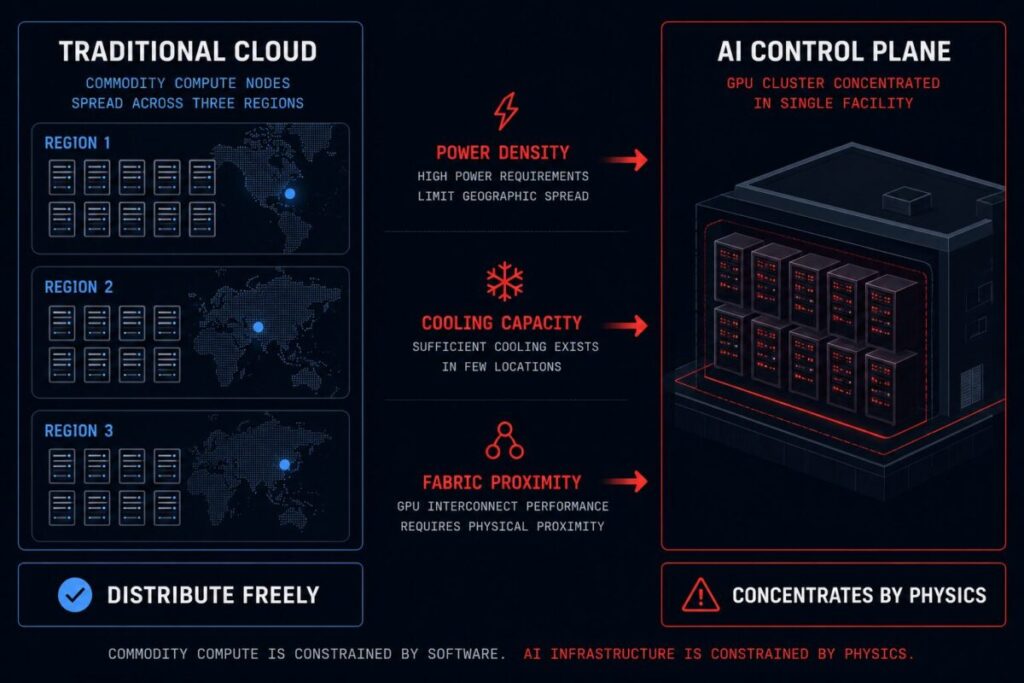
The standard availability model works because commodity compute is interchangeable. A web server running in one region can be replaced by an identical web server in another. Load balancers distribute traffic. DNS failover redirects requests. The architecture is deliberately stateless, deliberately redundant, and deliberately distributed precisely because nothing about the underlying hardware makes distribution expensive.
AI infrastructure architecture operates under a different set of physical constraints — ones that make the regional distribution model significantly harder to apply and significantly more expensive to maintain.
The contrast is structural:
| Traditional Cloud Workloads | AI Control Plane | |
|---|---|---|
| Compute type | Commodity CPU, interchangeable | H100/B200 GPU clusters, specialized and supply-constrained |
| State | Stateless or easily replicated | Model checkpoints, KV cache, inference state — large, slow to move |
| Network requirement | Standard VPC networking | 400G–800G InfiniBand or RoCE fabric for inter-GPU communication |
| Power density | Standard rack density | 30–100kW per rack — specialized facility requirement |
| Regional distribution cost | Low — spin up identical instance | High — duplicate specialized hardware, fabric, and facility investment |
The result is that AI inference infrastructure concentrates. Not because architects made a bad decision, but because the hardware, power, and networking requirements make distribution prohibitively expensive except at hyperscaler scale — and even hyperscalers don’t distribute GPU clusters the same way they distribute commodity compute.
The Concentration Problem Nobody Modeled
Three forces drive GPU cluster concentration, and none of them appear on architecture diagrams:
Power availability. A modern GPU training or inference rack draws 30–100kW. A cluster of 1,000 H100s requires roughly 3–10MW of dedicated power with redundant delivery and cooling. That level of power infrastructure exists in a small number of purpose-built facilities. Architects don’t choose the region because of latency or compliance — they choose it because it has the power.
Cooling capacity. GPU clusters require high-density cooling: direct liquid cooling, rear-door heat exchangers, or purpose-built cold aisle containment at densities that standard enterprise data centers and most hyperscaler standard zones cannot support. The facilities that can support it are not evenly distributed.
GPU fabric density. InfiniBand and high-speed RoCE fabrics require physical proximity. The GPU-to-GPU interconnect performance that makes large-model inference viable depends on short cable runs and low-latency switching. You cannot distribute a GPU fabric across two availability zones the way you distribute a web tier — the physics of the fabric prevent it.
The outcome of these three forces is that AI inference infrastructure ends up concentrated in whichever facility has the power, cooling, and fabric capacity to support it. That facility is in a region. That region has a failure domain. And the network architecture that connects that cluster to the rest of the stack becomes the single path through which everything AI-dependent flows.
This is not a misconfiguration. It is the architectural consequence of building on hardware that the standard distribution model was never designed to address.
The June 1 Azure Incident Was Evidence, Not the Cause
On June 1, 2026, a power incident at Microsoft’s East US facility took down Azure Copilot for an extended period across a significant portion of the enterprise customer base. The recovery was slower than a standard regional failover would suggest — restoration was bottlenecked by the time required to bring storage clusters online and rehydrate model checkpoints, not just by restoring power.
That detail matters. The failure exposed two properties of AI infrastructure that the standard regional failover model doesn’t account for:
Model rehydration is not fast. Restoring a large language model inference endpoint is not like restarting a web server. It requires loading multi-gigabyte to multi-terabyte model checkpoints from storage, validating weights, re-establishing inference cluster state, and warming the KV cache before the endpoint can serve production traffic. Under the pressure of a regional failover — when the remaining regions are simultaneously absorbing redirected load — that process takes hours, not minutes.
GPU clusters don’t distribute evenly. The East US facility housed a disproportionate concentration of the GPU infrastructure dedicated to Copilot. When that capacity disappeared, remaining regions were overwhelmed. The load balancer redirected traffic to infrastructure that wasn’t sized to absorb it, because the cluster wasn’t designed for regional redundancy — it was designed for the facility that had the power and cooling to run it.
Azure didn’t create the concentration problem. The physical requirements of AI inference infrastructure created it. Azure’s architecture revealed it under failure conditions. The distinction matters because the same failure domain exists in every enterprise AI deployment that followed the same placement economics.
AI Inference Doesn’t Degrade Gracefully — It Loses Capability
This is the failure mode that the availability zone model was never designed to address, and it’s worth stating precisely.
⚠ THE FAILURE MODE NOBODY NAMES
Traditional infrastructure failure produces degraded capacity — the system still functions, just slower or with reduced throughput. AI infrastructure failure produces capability loss — the system stops functioning entirely for the workloads that depend on it. That is a categorically different failure class, and it requires a categorically different survivability model.
When a web server region fails, search still works — slower. When an e-commerce region fails, the site still loads — slower. The architecture degrades gracefully because the capability is distributed across remaining capacity.
When the region hosting your AI inference cluster fails, the AI agent loses access to the model entirely. It does not serve slower responses — it serves no responses. The workflow that depended on it does not slow down — it stops. For enterprises that have embedded AI into production automation, approval workflows, or decision pipelines, that is not a performance degradation. It is a capability outage with no graceful fallback unless one was explicitly architected.
The observability gap compounds this: most enterprises don’t know which production workflows depend on a single-region AI endpoint until that endpoint is gone. AI inference observability was built to surface cost and latency signals — the dependency mapping that would identify which systems have no fallback path is rarely in place before the first incident forces it.
When the Region Disappears, Governance Has No Answer
Governance and runtime control is the stage where the Runtime Authority Vacuum (#123) is formally defined: the condition in which AI systems are operating without explicit architectural authority over their own governance decisions. When a region fails, the vacuum becomes immediately visible — and the questions it exposes are governance questions, not infrastructure questions.
01 — WHO DECIDES FAILOVER?
When the primary AI region goes down, who has the architectural authority to redirect inference workloads — and to where? If that decision requires a human approval chain to activate, how long does that chain take relative to how long the business can operate without AI-dependent workflows?
02 — WHO AUTHORIZES DEGRADED MODE?
Degraded mode for an AI-dependent workflow means the workflow continues without the AI component — with human decision-making substituting for automated inference. Who has the authority to activate that mode? Is there a documented degraded-mode playbook, or is the answer discovered under incident pressure?
03 — WHO DISABLES AGENT EXECUTION?
Autonomous agents that cannot reach their inference endpoint don’t gracefully pause — they fail in undefined states. Who has the authority to disable agent execution across the affected workflows, and how is that authority exercised when the AI infrastructure that would normally execute the command is the thing that’s unavailable?
04 — WHO ACCEPTS REDUCED AUTOMATION?
Every workflow that falls back to manual operation increases load on human decision-makers. Who in the organization has the authority to accept that load redistribution — and who communicates it to the affected business units? This is a governance decision. Most organizations have no one assigned to it until the incident forces the question.
These four questions are not answered by infrastructure design. They are answered by governance architecture — explicit assignment of authority, documented degraded-mode playbooks, and pre-authorized activation paths that don’t depend on the AI infrastructure they’re governing. The Runtime Authority Vacuum exists precisely because most organizations embedded AI into production before answering them.
This is not an AI-specific problem. It is the same authority-concentration and shadow-control-plane pattern that Control Plane Architecture (CS4) addresses at the cloud strategy level — undefined ownership of the systems that govern infrastructure, generalized across any domain where control plane authority was never explicitly assigned.
Not Every AI Workload Deserves Multi-Region Survivability
The obvious response to a single-region failure domain problem is: build multi-region AI. That response is correct for some workloads and wrong for most.
Multi-region AI inference requires duplicating specialized hardware, fabric, and facility investment across at least two facilities with the power and cooling to support it. At current GPU economics — H100 on-demand rates up roughly 48% year-over-year, B200 availability on waitlists through mid-2026 — that is not a universally viable architecture. It is an architecture that should be applied selectively, based on workload criticality.
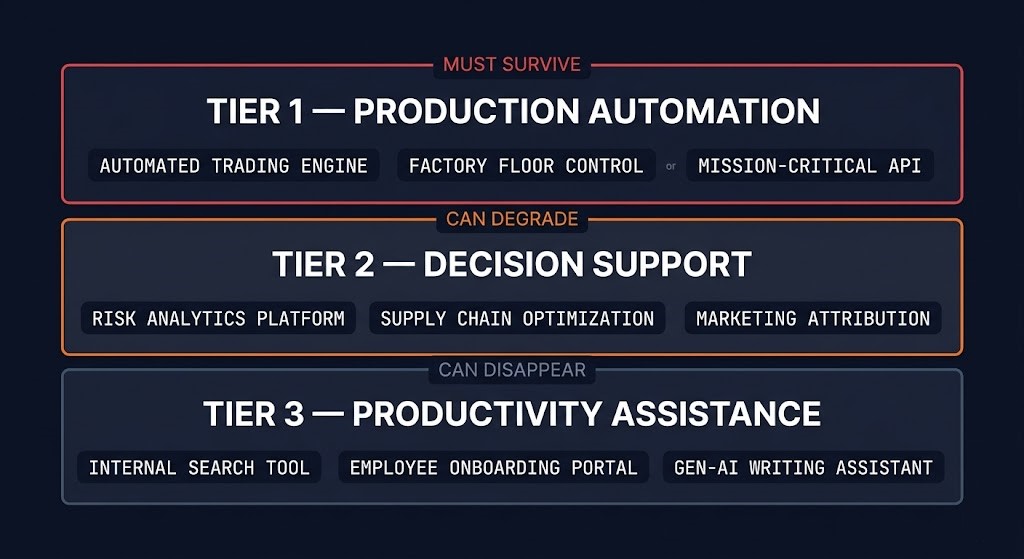
| Tier | Workload Type | Examples | Survivability Requirement |
|---|---|---|---|
| Tier 1 | Production automation | Autonomous agents, approval pipelines, execution authorization | Must survive regional failure — multi-region or explicit degraded-mode fallback required |
| Tier 2 | Decision support | Analysis, summarization, recommendation engines feeding human decisions | Can degrade — humans can substitute; document the degraded-mode workflow |
| Tier 3 | Productivity assistance | Copilot-style drafting, search augmentation, code completion | Can disappear — inconvenient but not operationally critical; no survivability architecture required |
Most enterprises have not done this classification. Tier 1, Tier 2, and Tier 3 workloads are running on the same inference infrastructure with the same single-region failure domain, because no one assigned architectural criticality before the infrastructure was provisioned. The classification work is not expensive. It is a governance exercise that should have happened before the first production AI workflow went live — and that can still be done before the first regional failure forces it.
Multi-cloud failover fails for the same reason this classification gets skipped: the assumption that “we have a second option” substitutes for the architectural work of defining which workloads need it, what the failover path actually looks like, and whether the second option can absorb the load. The answer is usually no until the architecture is explicitly designed around that requirement.
What the Survivability Boundary Requires at Each Maturity Level
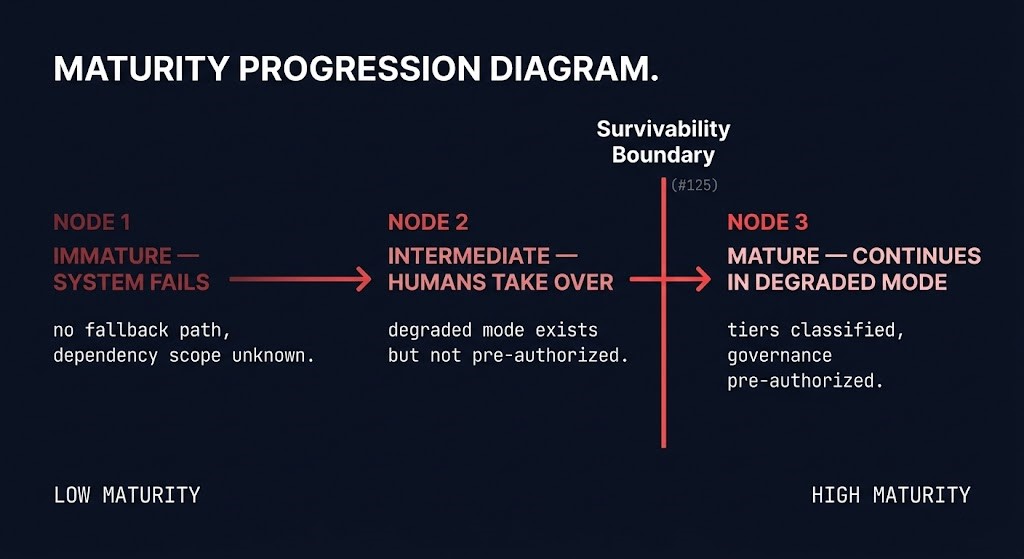
System Survivability Architecture — the Resilient stage of the AI Infrastructure path — defines the Survivability Boundary (#125) as the line between architectures that can continue operating under failure and architectures that cannot. For AI control plane failure specifically, the maturity model maps to three distinct states:
SURVIVABILITY BOUNDARY (#125) — AI CONTROL PLANE MATURITY STATES
- Immature: The system fails. AI-dependent workflows stop. No fallback path exists. Discovery of dependency scope happens under incident pressure.
- Intermediate: Humans take over manually. Degraded-mode playbooks exist but were not pre-authorized. Recovery depends on human escalation chains that were not designed for the load they inherit.
- Mature: The system continues operating in degraded mode. Workload tiers are classified. Tier 1 workloads have explicit survivability architecture. Tier 2 workloads have documented human fallback paths. Tier 3 workloads are accepted as unavailable. The boundary between tiers was drawn before the incident, not during it.
The gap between Intermediate and Mature is not primarily a hardware investment — it is a governance and classification decision. Most organizations are operating at Immature or early Intermediate because the workload classification and degraded-mode authorization work was never done. The hardware investment required to move Tier 1 workloads to genuine multi-region survivability is real and significant. The governance work required to define which workloads are Tier 1 is not.
Architect’s Verdict
The cloud spent fifteen years teaching architects to think in terms of availability zones, regional redundancy, and distributed failure domains. AI infrastructure is reintroducing concentration risk into environments that spent a decade eliminating it.
The question is not whether your AI platform is available today. The question is whether your business still functions when the region hosting its intelligence disappears.
Survivability begins the moment the AI control plane stops responding.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




