Backups Fail at Restore Time Because Restore Is Underdesigned

Restore design failure is not a technology problem — it is an architecture problem, and most organizations discover this at the worst possible moment.
02:14 AM. The restore completes successfully. 03:07 AM. Nobody can log in. 04:11 AM. DNS is still pointing at the failed environment. 05:03 AM. Certificates are missing. 06:22 AM. The application owner confirms the system is still unusable.
The backup worked exactly as designed. Recovery didn’t.
That gap — between a completed restore and a functioning application — is not a backup failure. It is what happens when an organization builds a protection architecture and assumes a recovery architecture will emerge from it automatically.
What Backup Programs Actually Design
Every mature backup program has a designed architecture. Retention schedules are documented, immutability tiers are defined, air gap topologies are diagrammed, replication targets are configured, RPO windows are contracted, and backup job success rates are monitored daily. The backup dashboard shows green.
What it does not show is whether the organization can recover.
Every metric in a backup program measures protection — not recoverability. Backup vendors build technology that captures and stores data reliably. They do not build recovery architecture. That discipline belongs to data protection architecture — and in most enterprises, it has been left unbuilt.
Most organizations can explain their backup architecture in detail. Few can draw their recovery architecture on a whiteboard.
What Restore Actually Requires
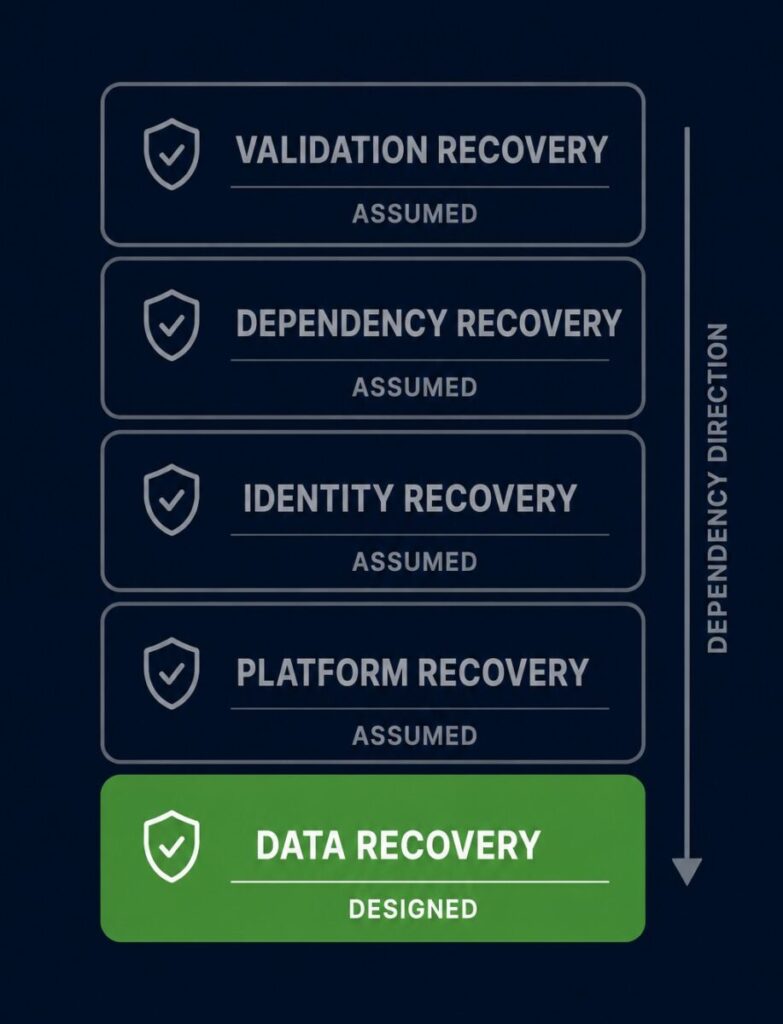
Restore is not a single operation. It is a sequenced execution across five dependency layers, each of which must be intentionally designed, explicitly sequenced, and independently validated before the layer above it will function.
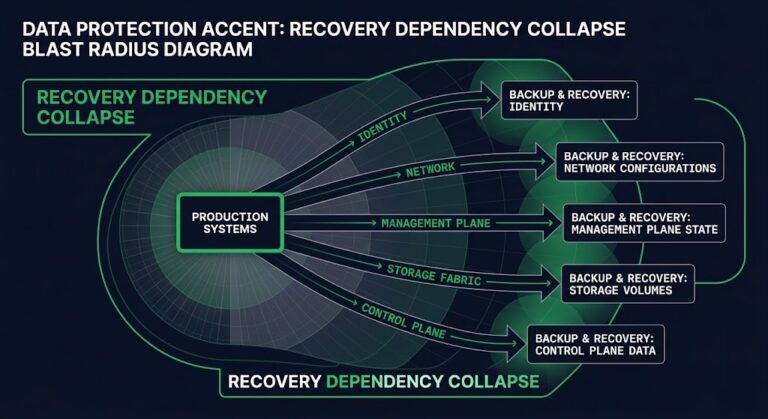
Identity and dependency services are often shared recovery prerequisites for dozens of applications simultaneously. The patterns that surface in Disaster Recovery Authority — authority gaps and coordination failures under real incident conditions — trace directly back to this: recovery sequences that assume shared services are available without verifying they were designed to recover first. A single Active Directory failure can block fifty workload recoveries across infrastructure that would otherwise restore cleanly. This reframes restore from a per-application operation into a recovery system architecture problem.
The five layers:
01 — DATA RECOVERY
Can the data be read, deduplicated, decrypted, and staged to the target environment? This is the only layer most organizations explicitly design. Backup tooling handles it. Success here is necessary but not sufficient.
02 — PLATFORM RECOVERY
Is the compute, storage, and hypervisor layer ready to receive the restored workload at scale? Snapshot dependencies, replica consistency, and storage fabric readiness are platform questions. Data recovery cannot proceed if the platform isn’t prepared to host it.
03 — IDENTITY RECOVERY
Can authentication and authorization function before applications start? Directory services, IdP configuration, service account availability, MFA provider connectivity — these must be sequenced ahead of workload recovery, not alongside it. Restoring a workload into an environment where identity isn’t functional produces a system that runs but cannot be used. This is why your identity system is your biggest single point of failure — and recovery sequences that treat it as an afterthought pay for it in hours, not minutes.
04 — DEPENDENCY RECOVERY
DNS resolution, certificate availability, secrets manager accessibility, service endpoint routing, and API integration reachability — these must be explicitly sequenced and confirmed operational before dependent workloads can function. DNS failover that was never tested against the recovery network topology is a dependency failure waiting to happen. Secrets managers, SaaS identity providers, and API-dependent integrations have expanded the recovery dependency surface faster than most recovery architectures have evolved.
05 — VALIDATION RECOVERY
Who confirms the application is operationally functional — not just running? Validation recovery requires a defined success state, an accountable application owner, and a runbook that answers the question before the incident begins. Without it, recovery has no finish line.
Recovery does not proceed upward automatically. Every layer must be intentionally designed, sequenced, and validated.
None of these layers come with a backup product.
Framework #153 — The Restore Design Gap
As the restore path is the most neglected part of backup design — a pattern that shows up consistently across enterprise environments — this framework names why: there is a structural gap between what organizations design and what recovery actually requires.
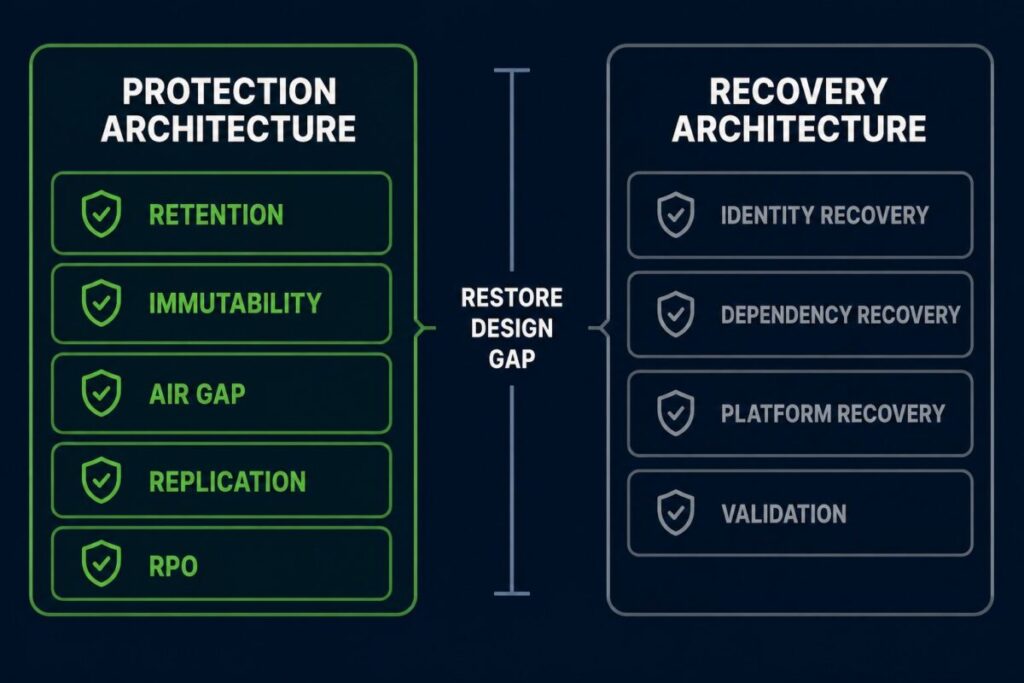
FRAMEWORK DEFINITION — #153 RESTORE DESIGN GAP
The period between successful data recovery and verified operational recovery. The larger the gap, the greater the difference between protection architecture and recovery architecture.
Protection Architecture — designed, tested, measured, and monitored. SLAs exist. Budget exists. Tooling exists.
Recovery Architecture — assumed. Runbooks (if they exist) describe data recovery, not operational recovery.
Organizations spend months designing protection. They spend hours — or nothing at all — designing recovery. That asymmetry is not a resourcing failure. It is a classification failure. Protection and recovery are treated as the same discipline. They are not.
Backup architecture answers the question: can we capture the data?
Recovery architecture answers the question: can we restore operations?
Those are different problems with different owners, different dependencies, and different design requirements. Treating the first as a proxy for the second is where the gap opens.
The Most Dangerous Restore Outcome
A restore can be technically successful and operationally failed simultaneously. This is not a theoretical edge case — it is the most common restore failure mode in enterprise environments.
TECHNICAL SUCCESS / OPERATIONAL FAILURE
- VM powered on ✓
- Database mounted ✓
- Application process running ✓
- Users cannot authenticate
- APIs returning connection errors
- Certificates expired in the restored vault
- Dependency services unreachable from the recovered network segment
The backup tooling reports success because backup tooling measures what it controls — data capture and restore. It has no visibility into identity state, certificate validity, DNS resolution, or API reachability. Those exist outside its scope.
Architects routinely mistake technical recovery for operational recovery. The incident dashboard shows the restore completed. The business is still down. Both statements are true — which is exactly why the incident isn’t over after restore: the restore is the beginning of operational recovery, not the end of it.
Where Restore Failures Actually Occur
Data recovery at Layer 1 almost never fails. Backup technology is reliable at its core function. Failures accumulate in the layers above it — and they accumulate in predictable patterns.

01 — DATA LAYER (RARELY FAILS)
Data restores complete. The backup technology performs as designed. This is where organizations focus almost all of their testing effort — and it is almost never where recovery stalls.
02 — PLATFORM LAYER (COMMON)
The hypervisor or storage platform was not prepared to receive a restore at full incident scale. Snapshot tree inconsistencies surface. Replica targets lack capacity. Storage fabric connectivity from the recovery network segment was never validated. The data arrives but has nowhere functional to land.
03 — IDENTITY LAYER (FREQUENT — HIGH IMPACT)
Active Directory or the IdP was not sequenced ahead of workload recovery. SSO tokens are invalid against the restored directory state. Service accounts are missing or mapped to credentials that no longer exist in the restored environment. Dozens of workloads stall waiting for authentication infrastructure that was never prioritized in the recovery sequence.
04 — DEPENDENCY LAYER (FREQUENT — CASCADING)
DNS is still resolving to the failed environment. Certificates are missing from the recovered secrets vault — they were not included in the backup scope. API integrations are routing to endpoints that do not exist in the recovery topology. Each dependency failure extends the outage independently, and they compound.
05 — VALIDATION LAYER (SILENT FAILURE)
Nobody defined what “recovered” looks like. The application owner is unavailable or cannot determine whether the application is functioning correctly without days of investigation. Recovery has no declared finish line, so it extends indefinitely — or gets declared complete before it actually is.
The pattern is consistent across incidents: Layer 1 succeeds, Layers 2 through 5 stall, and the hours between the restore completion and operational recovery are spent discovering design gaps that existed for years.
Why Restore Design Failure Persists
Four structural reasons explain why the Restore Design Gap remains a chronic condition across enterprise environments rather than a solved problem.
Backup vendors measure and report on backup success — not restore readiness. Every dashboard metric, every SLA, every automated alert is scoped to capture operations. Restore readiness generates no alert when absent and produces no report when undesigned. It is invisible to the tooling organizations rely on for assurance.
DR tests validate data recoverability — not operational recoverability. The annual DR test proves Layer 1 works. It rarely tests identity recovery sequencing, dependency validation, or application owner confirmation workflows under realistic incident conditions. Your DR test passed. The assumptions didn’t. That post covered how assumptions embedded in DR plans fail under incident pressure — the Restore Design Gap is the design failure underneath those assumptions.
Recovery architecture has no owner. The backup team owns protection. The application team owns the application. Infrastructure owns the platform. Nobody owns the cross-layer recovery sequence that connects a completed data restore to an operationally functional application. That accountability gap is not a people problem — it is an architecture governance problem.
Recovery success is rarely measured. Backup success is measured daily, with automated reporting and SLA tracking. Recovery success — the time from incident declaration to confirmed operational recovery across all five layers — is measured at most once per year, and often not at all. Organizations optimize what they measure most frequently. The measurement asymmetry explains the investment asymmetry.
Closing the Gap
Three architectural decisions, in the right sequence.
First: define recovery success before anything else. What does “recovered” mean for each workload? Not “data restored” — operationally recovered. Who declares it? Against what criteria? This definition must exist before recovery architecture can be designed, because the architecture is the system for achieving a defined end state. Without the definition, design has no target.
Second: map recovery dependencies per workload, not per backup job. The unit of recovery is the application, not the dataset. Identify every dependency each workload requires to function — identity services, DNS resolution, certificate availability, secrets access, API endpoint routing — and determine the sequencing and readiness conditions for each. This map is the foundation of recovery architecture. It does not come from a backup vendor.
Third: design recovery architecture as a first-class artifact. Not a runbook addendum, not an assumption embedded in a DR plan — a designed system with explicit sequencing, declared ownership per layer, validated readiness conditions, and a documented finish line. Protection architecture gets this treatment. Recovery architecture must receive the same.
The Recovery Architecture Foundations LP stage covers the structural model for crossing the Recovery Design Boundary — the point at which recovery behavior is designed rather than discovered at incident time.
Architect’s Verdict
Backup architecture protects data. Recovery architecture restores operations. Most organizations invest heavily in the first and assume the second will emerge automatically.
It does not. It stalls at identity. It fails at dependencies. It ends without a declared finish line because nobody designed one. The data protection architecture discipline has matured significantly on the protection side and almost not at all on the recovery side.
Recovery design is not a backup tool feature. It is an architecture discipline — one that most enterprises haven’t built yet, and discover they need at 3 AM.
If your recovery documentation ends where your data restore ends, you haven’t designed recovery. You’ve designed backup.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session