vSphere Lifecycle Management Is a Governance Problem, Not a Patching Problem
Most vSphere environments run lifecycle management as a patching workflow. VUM baselines, remediation windows, critical CVE triage. The operational rhythm is update-focused, and by that narrow measure it mostly works — systems stay supported, vulnerabilities get addressed, and the team can report green status on compliance dashboards.
The architectural problem is that vSphere lifecycle management governs something far larger than patch state. It governs what upgrade paths remain available, which migration tooling can run, which integrations remain valid, and what exit options the organization still has. When those decisions accumulate without a governance owner, the virtualization platform doesn’t drift visibly. The environment stays operational. The Lifecycle Governance Horizon quietly collapses.
What vSphere Lifecycle Management Actually Controls
Patch state is the visible surface. Beneath it, vSphere lifecycle management governs the compatibility envelope that determines what the platform can do next.
That envelope covers: ESXi host firmware and driver versions, the vCenter-to-ESXi version compatibility matrix, third-party integration validity (backup agents, security tooling, network monitoring, automation connectors), NSX version compatibility bounds, vSAN upgrade path eligibility, and plugin compatibility across the vSphere ecosystem. Each layer has its own versioning clock. None of them are managed by the patching workflow — and none of them are visible to the teams treating vSphere as a control plane dependency rather than a managed platform.
The consequence is subtle but compounding: an environment can be fully current on critical security patches while simultaneously carrying driver versions that block migration tooling, backup agents that cannot be upgraded without an ESXi host upgrade first, and an NSX release that sits outside the compatibility matrix for the intended migration target.
Supported Upgrade Paths
Most administrators think about lifecycle management as maintaining supportability — keeping the platform within VMware’s support window and applying critical patches on schedule. VMware’s upgrade model creates a second responsibility that the patching workflow doesn’t address: preserving upgrade eligibility.
A platform can be fully supported today while simultaneously narrowing the set of future transitions available to it. ESXi upgrade paths are sequential. Version skips are not supported. An environment running 6.x cannot go directly to 8.x — the upgrade sequencing requires each major version step to be traversed in order. Deferred upgrade cycles don’t just create remediation work. They create mandatory intermediate steps that add weeks to any planned transition before the transition itself can begin.
Lifecycle governance exists to preserve those future paths before they become constraints — not to maintain currency for its own sake.
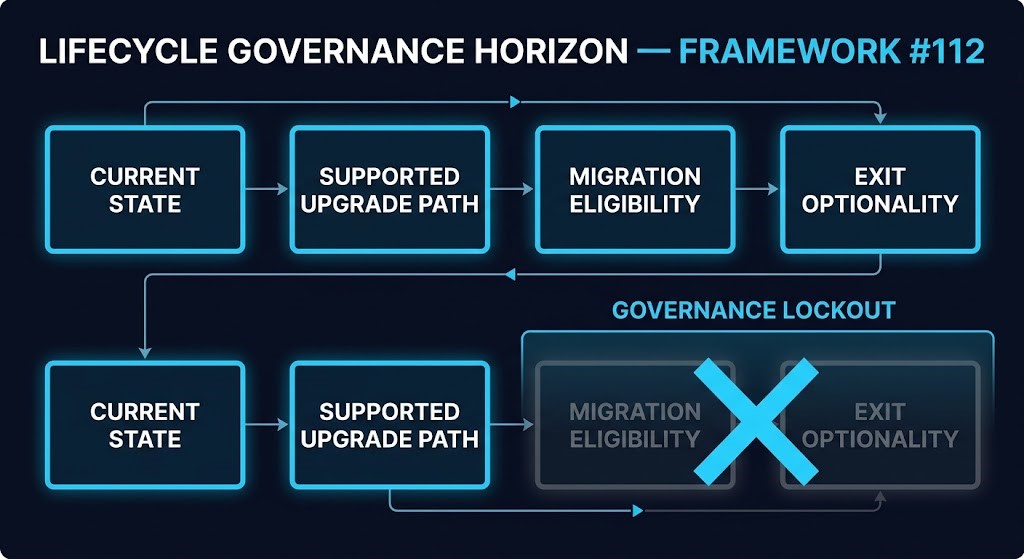
Framework #112 — The Lifecycle Governance Horizon

FRAMEWORK #112 — LIFECYCLE GOVERNANCE HORIZON
The future window during which a platform can execute a planned transition, upgrade, migration, or strategic change without requiring unplanned remediation work first.
Each deferred lifecycle cycle narrows downstream nodes. Governance Lockout occurs when the Lifecycle Governance Horizon collapses to zero — no planned transition can begin without unplanned remediation first.
Each node in this model is a decision gate, not a status readout. The platform doesn’t fail when a node closes — it just loses the option that node represented. Deferred upgrade cycles don’t push the Current State node backward in isolation. They collapse nodes 02, 03, and 04 sequentially, without any visible signal at the operational layer.
This is why environments that pass every compliance check and every security scan can still arrive at a migration project completely unprepared. Compliance validates patch state. The Lifecycle Governance Horizon measures something the patching workflow was never designed to track.
How Patching Teams Inherit Governance Debt
Version skew across ESXi clusters is the most visible symptom. In most environments it’s not a security failure — the critical CVEs have been patched, the hosts are within support bounds. It’s a governance failure: nobody owns the policy for what version the platform should be at, and nobody has defined the maximum tolerable skew.
The result is architectural fragmentation masquerading as operational normalcy. Cluster A runs 8.0 U2. Cluster B runs 7.0 U3 because it was excluded from the last remediation window due to a workload freeze. Cluster C runs 7.0 U1 because nobody remembered to lift the exception after the freeze ended eighteen months ago. Each cluster is individually “supported.” The environment as a whole has no defined version policy.
When a migration project kicks off and needs to run discovery tooling against the full estate, the compatibility matrix has to be reconstructed from scratch — because nobody modeled it at policy definition time. That reconstruction is the governance debt arriving as a project cost — the same pattern that surfaces in compute architecture governance when density policies are absent.
The patching team didn’t create this problem. They inherited an environment where nobody had defined what governance-driven lifecycle management looks like. Their job was to keep systems supported. Nobody told them that “supported” is a threshold condition, not a governance program.
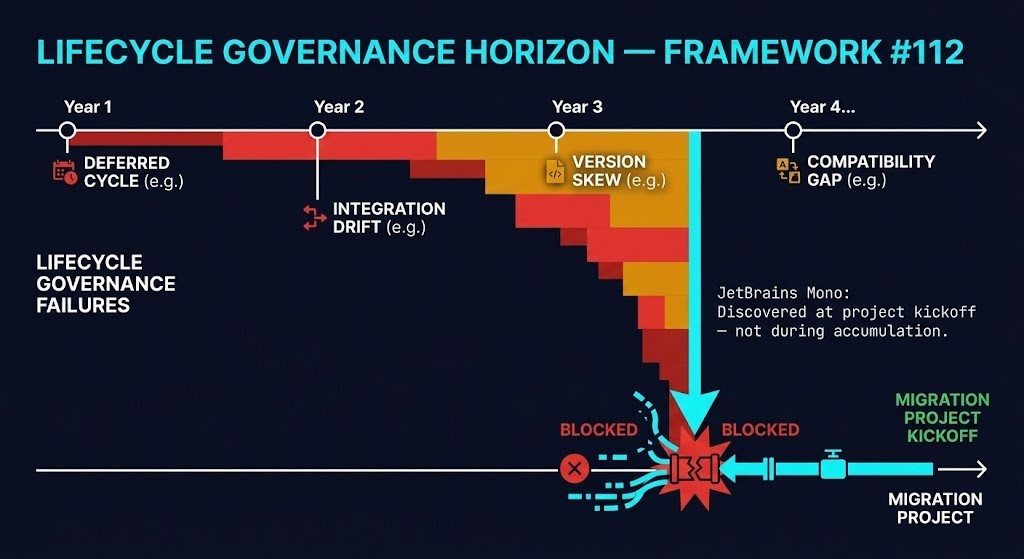
Lifecycle Decisions Compound Quietly
One deferred upgrade cycle is manageable. The environment drifts one version behind policy, the remediation window gets scheduled, it closes. No lasting damage.
The compounding starts at cycle two.
| Deferred Cycles | Outcome | What It Looks Like |
|---|---|---|
| 1 | Manageable | Remediation scheduled, minor version gap, no downstream impact |
| 2 | Annoying | Integration drift begins — backup agents require coordinated upgrade, driver versions diverge |
| 3 | Expensive | NSX version outside target compatibility matrix, migration tooling floor not met, hardware generation audit required |
| 4 | Governance Lockout | No planned transition can begin without unplanned remediation work first |
Governance Lockout is the point at which a planned platform transition can no longer begin without unplanned remediation work first. Governance Lockout occurs when the Lifecycle Governance Horizon collapses to zero.
The examples that get teams to cycle four are never dramatic. Unsupported NIC firmware that blocks migration tooling agent installation. Backup agents that require an ESXi upgrade before they can be brought to a version compatible with the migration target’s protection stack. NSX releases that are outside the compatibility window for the intended destination platform. Hardware generation flags that disqualify hosts from the target supported matrix. None of these appear as outages. None trigger alerts. All of them appear as project blockers during the kickoff sprint of a transition that was supposed to take three months.
The four-cycle model is a compression. Environments that defer across multiple major version cycles — which is common in large estates with conservative change management — can reach Governance Lockout in two cycles and not discover it until the migration project makes it visible.
Why Exit Projects Discover the Problem Too Late
The pattern repeats consistently enough to be instructive.
Example one. An organization reaches a Broadcom renewal event and decides to exit the VMware stack. The migration team begins planning. Discovery reveals: vCenter at a version below the floor required by the migration tooling, ESXi hosts at versions that require an intermediate upgrade before the migration agent can be installed, backup stack at a version incompatible with the intended protection model at the destination platform. The project cannot start. Pre-work — estimated at four to six weeks — wasn’t in the timeline or the budget.
Example two. An organization decides to standardize on VCF. Internal architecture review begins. Discovery reveals: NIC firmware versions outside the VCF hardware compatibility matrix, driver versions that require coordinated host upgrades before VCF can be deployed, one hardware generation across three clusters that is no longer on the VCF supported hardware guide. Roadmap slips by a quarter.
In both cases, the projects were well-planned by the people who planned them. The failure predated the projects by years. The migration project didn’t fail. The lifecycle governance program failed — because in most cases it never existed as a governance program. For a structured look at what governance-aware VMware migration sequencing requires before a project starts, the Migration Strategy Track covers the full upgrade eligibility model. It existed as a patching workflow, and patching workflows don’t track upgrade eligibility, migration readiness, or exit optionality.
By the time the gap becomes visible, the Lifecycle Governance Horizon has already collapsed. The remediation work is real, it is time-consuming, and it was entirely preventable.
Broadcom Didn’t Create the Problem. It Exposed It.
Broadcom compressed VMware’s support lifecycle windows, restructured entitlement bundles, and accelerated the upgrade obligation timeline for organizations that had been managing “two versions behind” as an acceptable operating position. Those changes were real, and their impact on enterprise budget cycles was significant.
But the architectural insight isn’t about Broadcom. It’s about what the Broadcom event made visible.
Organizations with mature lifecycle governance programs experienced Broadcom as a planning event. They had documented version policies, named owners for upgrade eligibility, and a compatibility matrix that was maintained and reviewed. When the support lifecycle windows compressed, they updated their policies and accelerated schedules that were already defined. The disruption was commercial, not architectural.
Organizations without lifecycle governance experienced Broadcom as a crisis. The compressed support windows exposed version debt that had accumulated across multiple deferred cycles. The forced upgrade obligation collided with environments that had no defined upgrade path, no compatibility modeling, and no policy owner. The response had to be architectural remediation work before commercial decisions could even be made.
The difference wasn’t Broadcom. It was whether the organization had a governance program that had been preserving optionality before the forcing function arrived. Lifecycle governance that worked under VMware’s old support model needs a policy reset under the new one — but it needs that reset because the framework exists and can be updated, not because it needs to be built from scratch under crisis conditions.
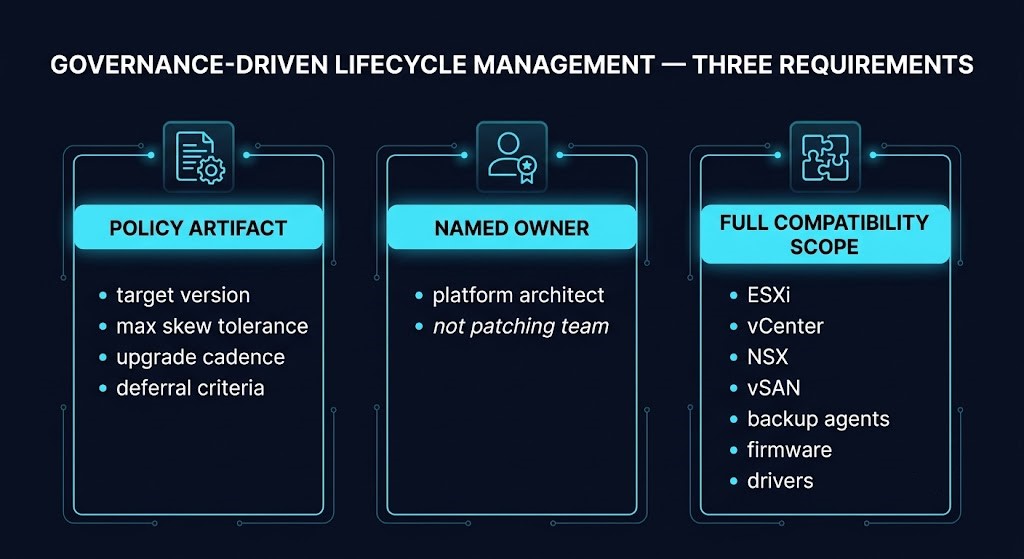
What Governance-Driven vSphere Lifecycle Management Looks Like
The shift from patching workflow to governance program requires three things that patching workflows don’t have: a policy artifact, a named owner, and a scope boundary that covers the full compatibility stack.
Policy artifact. A written document that defines: the target version for each platform layer, the maximum tolerable version skew across clusters, the upgrade cadence, and the criteria for an approved deferral. Without a written policy, “current” is whatever the most recent remediation window touched.
Named owner. Not the patching team. The platform architect or infrastructure governance function. The patching team executes against the policy. The governance owner defines acceptable version state, models upgrade path eligibility forward, and owns the decision to approve deferrals and document the rationale.
Full compatibility scope. ESXi, vCenter, NSX, vSAN, backup agents, security tooling, network monitoring, hardware firmware and drivers — treated as a coordinated unit with a single compatibility matrix, not as independently managed stacks with separate lifecycles. The upgrade path modeling runs against the full stack at policy definition time. Not at remediation time.
Two additional practices close the gap between governance definition and governance execution:
A deferral record — every deferred upgrade cycle requires a written rationale, a named approver, and a documented expiry date for the exception. Deferrals that never expire become permanent version gaps.
Periodic exit readiness checks — a documented assessment, run at minimum annually, that confirms migration tooling eligibility is maintained against the current version state. If it isn’t, the governance owner knows before the migration project team does.
DIAGNOSTIC — GOVERNANCE PROGRAM OR PATCHING WORKFLOW?
Who defines acceptable version skew across your environment?
Who owns migration readiness for the platform — not who patches it, but who owns upgrade eligibility?
Who approves lifecycle deferrals and records the rationale?
When did your environment last have a documented target state with a named owner?
If those questions don’t have answers, the environment is being maintained rather than governed.
Architect’s Verdict
Most organizations believe lifecycle management exists to keep the platform current. In reality, it exists to preserve future options.
The version running today determines which upgrades, migrations, integrations, and exit strategies remain available tomorrow. The patching workflow addresses the first responsibility. It doesn’t address the second. Those are different functions, and conflating them produces environments that are operationally sound and strategically constrained at the same time.
Patching is an operational activity. Lifecycle management is a governance function.
Lifecycle debt rarely appears as an outage. It appears as lost optionality.
By the time an organization discovers its Lifecycle Governance Horizon has collapsed, the transition it wanted to make is already delayed by work it never planned to do. The VMware Exit Engineering Hub covers the full readiness model for organizations at that point. The governance debt that lifecycle management leaves behind is the first condition in a three-framework chain that ends with the dependency surface becoming invisible — — a progression that has a direct IaC-layer parallel: when policy review cycles are skipped inside a GitOps pipeline, Policy Intent Drift produces the same governance lockout at the policy layer that deferred upgrade cycles produce at the platform layer. The renewal decision most organizations think they’re making today was actually decided incrementally, years earlier, in exactly this pattern of deferral.
SERIES: VMware Exit Architecture
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session