Ransomware Recovery Time Is an Architecture Problem, Not a Backup Problem
Ransomware recovery architecture is where most enterprise resilience programs break down — not because organizations lack backups, but because they never designed systems that could be rebuilt under pressure.
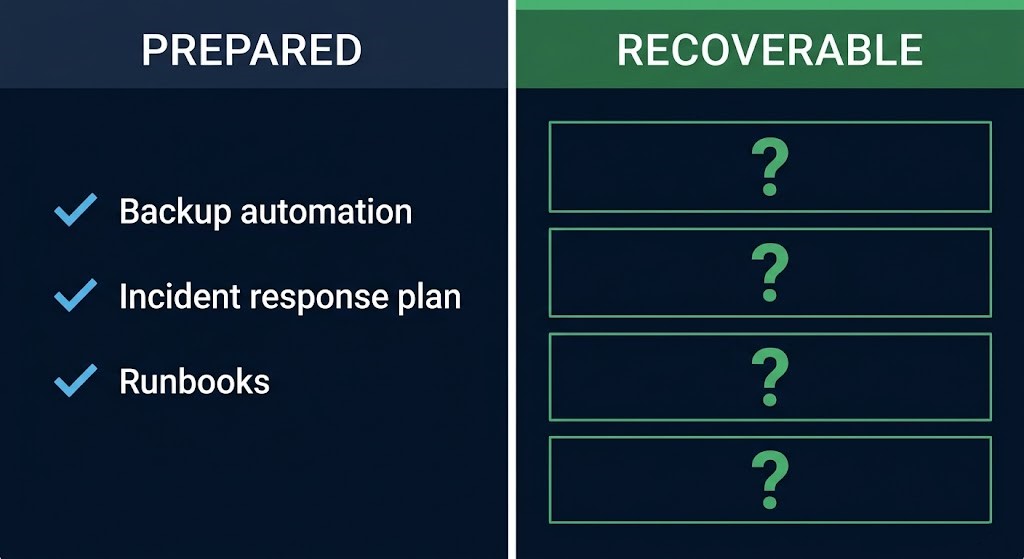
Most organizations have backups. Most have runbooks. Many have incident response plans on file and backup automation running on schedule. And yet, when ransomware hits, recovery still takes days — or fails entirely.
That gap isn’t a tooling problem. It isn’t a vendor problem. It’s an architecture problem. And most organizations won’t discover it until they’re in the middle of an active incident, trying to reconstruct systems with their normal tooling unavailable and their documented procedures pointing at an environment that no longer exists.
Recovery time isn’t determined on the day of the incident. It’s determined by the architecture decisions made long before it.
The Illusion of Preparedness
The industry data is instructive. The majority of enterprise organizations have invested meaningfully in recovery capabilities: incident response procedures, backup automation, isolated recovery environments, and immutable storage. On paper, resilience looks better than it ever has.
And yet recovery failures continue. Organizations with mature backup programs still report multi-day restoration windows. Teams with documented runbooks find themselves improvising when systems fail in sequences the runbooks didn’t anticipate.
The gap isn’t preparation. It’s execution under failure conditions.
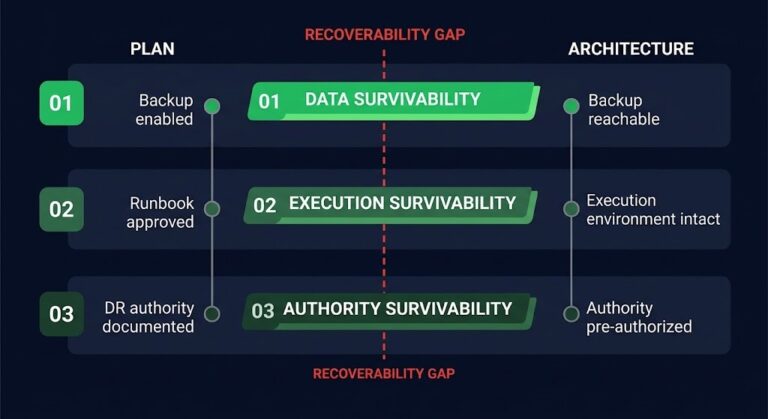
Preparedness and recoverability are not the same thing. A backup strategy tells you what data you have. A recovery architecture tells you whether you can actually reconstruct systems when the environment you depend on to do the recovery is itself compromised or unavailable.
Most organizations have optimized the first. Very few have designed for the second.
Ransomware Recovery Architecture: What Actually Works
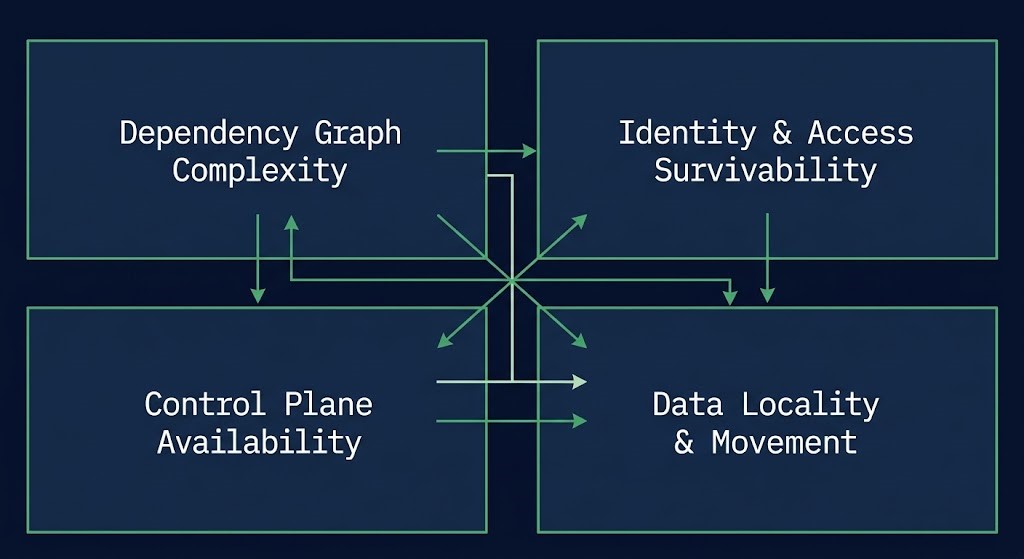
The standard framing of RTO — recovery time objective — treats recovery time as a function of backup frequency and SLA targets. It isn’t. Recovery time is the sum of everything your architecture depends on to execute a restore. That includes four layers most teams never explicitly model.
Dependency graph complexity. Before a single system can come back online, every upstream dependency that system requires must also be online first. In complex environments, those dependency chains are rarely documented accurately. Authentication services, configuration management databases, certificate authorities, logging infrastructure — these are invisible prerequisites that extend recovery time dramatically when they’re not sequenced into the recovery plan.
Identity and access survivability. Can your team authenticate during a recovery? If your identity provider is hosted in the same environment that was compromised, the answer may be no. If your privileged access management system requires network connectivity to a segment that’s been isolated, you may find yourself locked out of the systems you’re trying to restore. Identity architecture is the most undermodeled single point of failure in enterprise infrastructure — and it becomes a hard blocker in a ransomware recovery scenario.
Control plane availability. Recovery requires orchestration. In a VMware environment, that’s vCenter. In Kubernetes, that’s the control plane. In cloud environments, that’s the management plane APIs. If the control plane is compromised, unavailable, or deliberately isolated as part of your own incident response, you cannot execute automated recovery workflows. You’re reduced to manual, sequential, error-prone procedures — which is exactly the wrong mode for a high-pressure recovery situation.
Data locality and movement constraints. Where is the backup data, and how fast can it physically move? Backup storage in a geographically distant region introduces restore-time egress constraints that weren’t visible during design. Cloud egress costs are a known architectural tax — but egress bandwidth limits are a harder constraint. A 10TB restore across a 1Gbps pipe takes more than 22 hours under ideal conditions. Realistic conditions are not ideal.
Recovery time is the sum of all four. Not the backup speed. Not the SLA target.
Backups Are Not Recovery
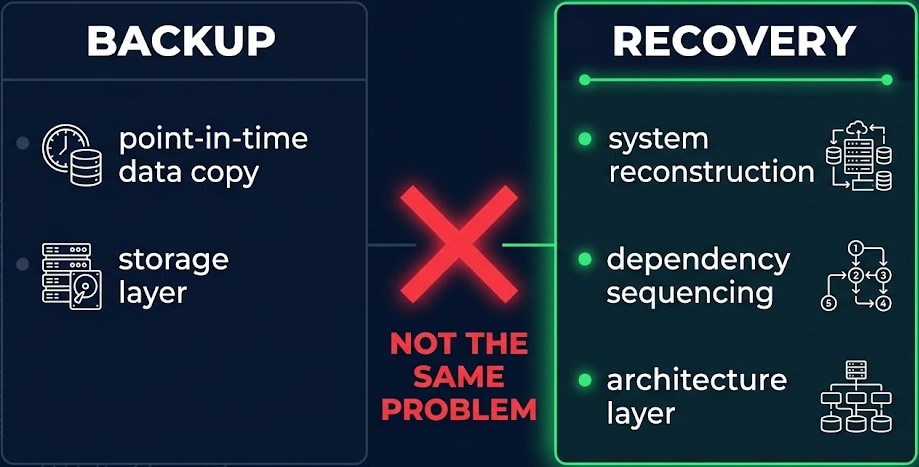
A backup is a point-in-time copy of data. Recovery is the reconstruction of a functioning system. These are different problems, and solving one does not solve the other.
Restoring data gets you data. It does not get you a running application, a configured service, a working network stack, a valid certificate chain, or an authenticated environment. All of those things must also be reconstructed — in the right sequence, against a potentially compromised or partially destroyed infrastructure, under time pressure, by a team operating under stress.
Crash-consistent backups are not database backups. Object lock is not an air gap. A runbook is not a tested recovery path. These distinctions matter enormously when the difference between them is measured in days of downtime.
The backup is the data layer. Ransomware recovery architecture is the system layer. Most failures happen at the system layer. The recoverability gap names the specific failure of mistaking one for the other: a backup that passes every completion check and still hasn’t been proven to produce a working recovery.
Where Recovery Actually Breaks
Backup exists. Team cannot access the environment to use it. Identity provider is compromised or isolated. PAM is unavailable.
Resolution: Decoupled identity architecture with offline break-glass credentials stored outside the blast radius.
Restoring System A fails because System B isn’t running. System B can’t start because System C isn’t running. Nobody modeled the dependency order before the incident.
Resolution: Dependency graph documented and tested in DR exercises — not just assumed in runbooks.
Backups appear isolated. The control plane can still reach them. Ransomware traverses the management network. The “air gap” was logical, not physical. Blast radius expands.
Resolution: True control plane isolation — the recovery environment has no network path to production management.
Documented recovery steps reference systems, IPs, and credentials that no longer match the current environment. Infrastructure changed. Runbooks didn’t.
Resolution: Recovery procedures version-controlled and validated against actual infrastructure on a defined cadence.
Data is intact and accessible. The restore still takes 72 hours. Deduplication ratios don’t reverse at restore speed. Rehydration bottlenecks kill RTO before data even moves. Storage-to-compute mismatch, network saturation, single-threaded restore jobs against a multi-TB dataset.
Resolution: Restore performance modeled and tested — not assumed based on backup write speed.
This is why organizations with backups still fail to recover on time. The backup is intact. The architecture around it isn’t.
The Recovery Architecture Model
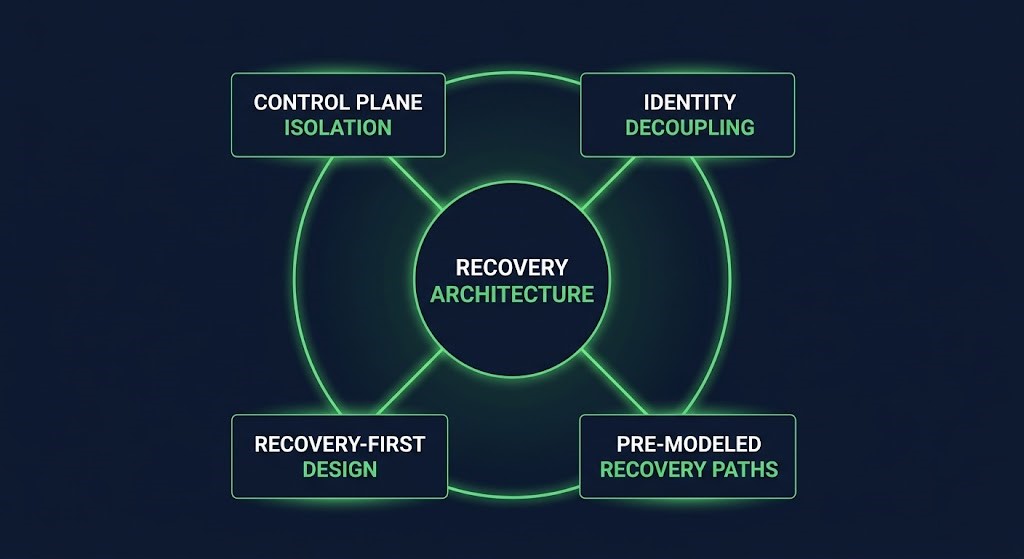
The shift from critique to solution requires moving from backup design thinking to recovery design thinking. Four principles separate architectures that recover under pressure from architectures that fail during recovery.
Isolation of control planes. The recovery environment must be operationally independent from the production environment. This means a separate orchestration layer — whether vCenter, Kubernetes control plane, or cloud management APIs — that has no network dependency on the compromised environment. Control plane isolation is the principle that determines whether you can execute recovery workflows at all. If you cannot issue commands during recovery, you are not recovering. You are hoping.
Identity decoupling. Break-glass access credentials must exist outside the identity infrastructure that was compromised. This is not about having a second copy of Active Directory. It is about having a defined authentication path that does not depend on any component within the blast radius. A compromised identity layer is a complete recovery blocker when it isn’t explicitly designed around.
Pre-modeled recovery paths. A recovery path is not a list of steps in a document. It is a sequenced, tested execution model that accounts for dependency ordering, timing constraints, and failure states at each step. The difference between a runbook and a recovery path is whether someone has actually run it — under conditions that simulate failure — and verified that it produces a running system on the other side. RTO reality is only visible through recovery drills, not through planning documents. A recovery path also requires defined disaster recovery authority — explicit ownership of who can declare each phase complete, approve failover, and release production systems. Without that authority chain documented and tested alongside the technical path, the recovery stalls at the human decision layer even when the infrastructure is ready.
Recovery-first design. Systems designed to be rebuilt recover faster than systems designed to be preserved. This means infrastructure-as-code for configuration state, immutable base images for compute, decoupled data from application tiers, and dependency graphs that are explicit rather than assumed. Configuration drift is the enemy of recovery-first design — every undocumented change is a variable that will surface under pressure and slow reconstruction.
The Cost Reality
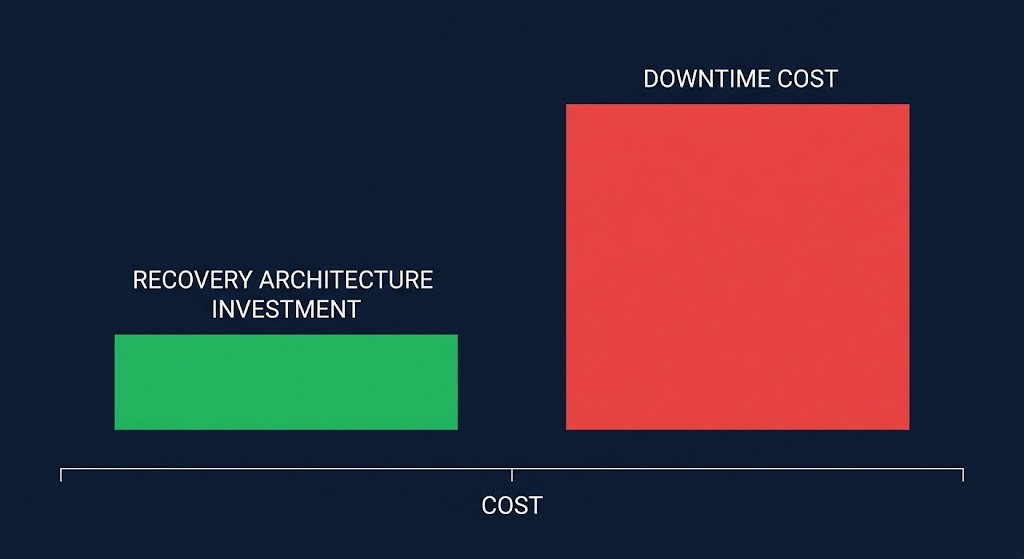
Faster ransomware recovery architecture is not free. Isolated control planes require additional infrastructure. Identity decoupling requires operational discipline. Pre-tested recovery paths require time investment on a regular cadence.
But slow recovery is far more expensive. Downtime costs at enterprise scale are measured in tens or hundreds of thousands of dollars per hour for revenue-generating systems. Data movement costs during a recovery across region or cloud boundaries can rival months of backup storage spend. The reputational, regulatory, and legal exposure from extended outages often exceeds the direct infrastructure cost by an order of magnitude.
The organizations that treat recovery as a cost constraint rather than an insurance policy make different architectural decisions. They invest in recovery path testing. They model dependency graphs. They design identity survivability explicitly. And when ransomware hits, they recover in hours rather than days.
The cost of a recoverable architecture is paid once. The cost of an unrecoverable architecture is paid at the worst possible moment.
Architect’s Verdict
The organizations that recover fastest from ransomware didn’t buy better backup tools. They designed systems that could survive being rebuilt.
Ransomware recovery architecture has four hard dependencies: the complexity of your dependency graph, the survivability of your identity layer, the availability of your control plane, and the physics of your data movement. None of these are backup vendor decisions. All of them are architecture decisions.
The preparation gap in ransomware recovery isn’t lack of investment. Most organizations have invested significantly in backup capabilities. The gap is between backup completeness and recovery architecture completeness — between having the data and being able to reconstruct the systems.
Recovery time is decided before the incident. You don’t discover your recovery time during the attack. You discover the consequences of your architecture.
If your recovery plan hasn’t been run end-to-end under simulated failure conditions, it isn’t a recovery plan. It’s a hypothesis. That hypothesis gets tested formally in Data Protection — Maturity Stage 4 — Ransomware Survival Architecture, which evaluates exactly this gap — dependency graph, identity survivability, control plane availability, data movement — against six weighted authority domains rather than a single pass/fail drill.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session