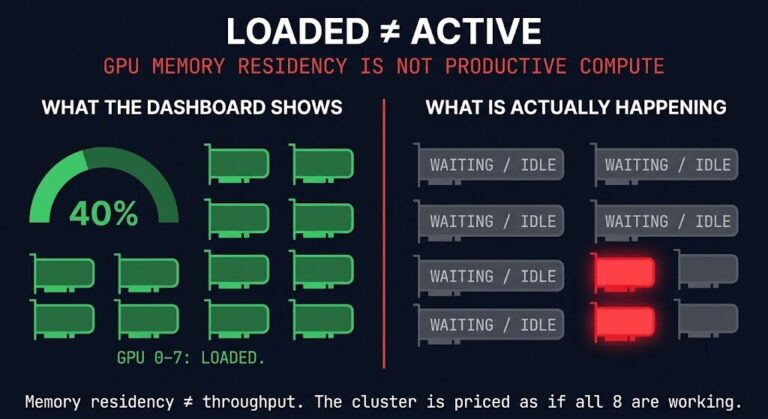
The CPU Is Back in the Stack — and Nobody Budgeted for It
The CPU never left the stack. It was reclassified — quietly, and incorrectly — as support compute. Something that fed the GPU, scheduled around the GPU, and otherwise stayed out of the way while the GPU did the “real” work. That classification held for exactly as long as AI workloads were big, monolithic training and inference jobs with predictable shapes. It does not hold for agentic systems. In agentic architectures, the CPU is back in the stack as the thing that decides what runs, in what order, with what authority, and what happens when two agents want the same resource at the same time. That’s not a support role. That’s the coordination substrate the entire system depends on — and almost nobody has budgeted infrastructure for it.
The Xeon Supply Constraint Is a Symptom, Not the Story
The current round of Xeon supply tightness — allocation delays, lead times stretching well past prior quarters, hyperscalers reportedly prioritizing their own fleets — is being read in most coverage as a GPU-adjacent story: CPUs are the “host” side of accelerated nodes, and host-side shortages are slowing GPU deployment. That framing isn’t wrong, exactly. It’s incomplete in a way that matters.
The Xeon constraint is a symptom because it’s surfacing a dependency that was already there and already growing — it just wasn’t visible as long as host CPUs were treated as commodity infrastructure you’d over-provision without thinking about it. Agentic workloads changed what the host CPU is doing. It’s no longer just shuttling data to the accelerator and handling network I/O. It’s running the orchestration layer — the agent loop, the tool-call routing, the policy checks, the memory and context management — for systems that didn’t exist eighteen months ago at any meaningful scale. The supply shock didn’t create this dependency. It exposed it, the way a drought exposes which trees had shallow roots.
Agentic Systems Reverse the Infrastructure Ratio
For the first wave of generative AI — large training runs, batch inference, single-model serving — the infrastructure ratio was straightforward: GPU does almost all the work, CPU does almost none of it. Provisioning followed that ratio. You sized the accelerator fleet first and treated the host layer as an afterthought, because the host layer’s job was small and largely fixed regardless of model size.
Agentic systems break that ratio, and they break it in a direction nobody planned for. An agent loop isn’t one inference call — it’s a sequence of inference calls interleaved with tool calls, retrieval calls, state updates, policy evaluations, and routing decisions, where the number of those interleaved steps scales with task complexity, not with model size. Every one of those steps runs on the CPU side of the architecture. As agentic systems take on longer-horizon, multi-step, multi-agent tasks, the volume of CPU-bound coordination work grows — and it grows faster than the GPU-bound execution work it’s coordinating. The ratio that justified “CPU is an afterthought” provisioning doesn’t just shift. It inverts.
The First AI Wave Was GPU-Centric
It’s worth being precise about why the GPU-centric framing made sense for as long as it did, because the contrast is what makes the inversion legible.
Training runs are GPU-bound by construction — the entire point of the hardware is to push as much matrix math through the accelerator as possible, and host-side work exists almost entirely to keep the GPU fed. The provisioning conversations of the last two years — fabric physics at 800G for 100k-GPU clusters, GPU cluster architecture for private LLM training, GPU scheduling inside Kubernetes — were all, correctly, about the accelerator as the scarce resource and the bottleneck to design around.
That same framing carried into early inference deployment, and it’s part of why GPU utilization itself became a visible problem — when the accelerator is the thing you’ve spent your budget and your design effort on, idle GPU cycles are the failure mode everyone is watching for, the dynamic behind GPU utilization becoming the new cloud waste crisis. Tools built around that era — including the Inference Saturation Analyzer and the GPU Cost Analyzer — were built to answer exactly that question: is the accelerator the constraint, and is it being used efficiently. They’re still correct tools for the workloads they were built for. The problem is that agentic workloads aren’t entirely those workloads anymore, and a tool that only watches the GPU side won’t see the constraint that’s forming on the other side of the architecture.
The CPU Becomes the Governance Layer
Here’s the inversion stated plainly: in agentic AI infrastructure, AI infrastructure architecture now treats the CPU’s job as no longer support the GPU. The CPU’s job is to govern the system — to decide what the GPU (and every other resource in the system) is allowed to do, in what sequence, under what constraints, and with what record of why.
“Governance layer” can sound like a branding exercise if it isn’t tied to something concrete, so here’s what it actually means in terms of cycles spent.
What the CPU Actually Governs in Agentic Systems
Task orchestration and agent sequencing. Every agentic system has to decide which agent or sub-task runs next, in what order, and whether a given step is even allowed to proceed given the current state of the task. That decision logic — the agent loop’s control flow — runs on the CPU, for every step, for every agent, continuously.
Memory and context arbitration. Agents don’t share a single, simple context window the way a single-model inference call does. Multiple agents and multiple steps are reading from and writing to shared memory, vector stores, and context state, and something has to arbitrate which writes win, what gets retrieved for which step, and when context gets pruned or summarized. That arbitration is CPU-bound coordination work, and it scales with the number of agents and the depth of the task, not with model size.
Cross-agent synchronization and conflict resolution. When two agents (or two steps of the same agentic task) want the same resource — a tool, a piece of state, a write lock on shared memory — something has to resolve that conflict according to policy, not according to whichever request happened to arrive first. That’s the runtime control plane in its most literal sense, and it’s the architectural territory the AI Infrastructure pillar’s governance work has been mapping for months: the Network Is the AI Control Plane framework, the Runtime Authority Vacuum, and the broader Agentic AI Has a Control Plane Problem thesis are all describing pieces of this same CPU-bound governance surface from different angles.
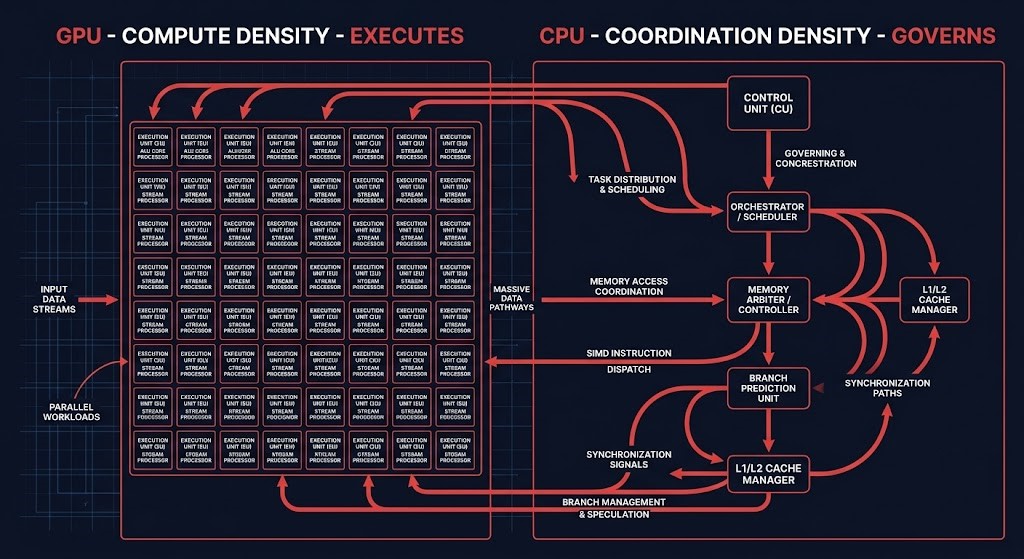
This is the structural inversion. Compute Density — how much infrastructure executes the work — used to be the entire story, because the work was simple enough that coordinating it was nearly free. Coordination Density — how much infrastructure is required to govern the work — was always nonzero, but it was small enough to ignore. Agentic systems don’t make coordination work appear out of nothing. They make coordination work the dominant cost — which is precisely the load the Governance & Runtime Control stage is built to address, and which, left unplanned, drives the failure modes covered in System Survivability Architecture.

The Industry Is Measuring the Wrong Resource
If coordination is now the dominant cost in agentic systems, the metrics that govern capacity planning, cost allocation, and SLA design should reflect that. They don’t. Almost every metric in production AI observability today is a Compute Density metric — a measurement of GPU-side execution — and almost none of them measure the CPU-side coordination work that’s now driving the constraint.
| Tracked (Compute Density) | Untracked (Coordination Density) |
|---|---|
| GPU utilization % | Orchestration calls per task |
| Tokens generated per second | Agent loop iterations per task |
| Model inference latency | Memory/context arbitration latency |
| GPU memory occupancy | Cross-agent lock contention / wait time |
| Accelerator cost per inference | CPU cycles spent on policy evaluation per request |
| Training throughput (samples/sec) | Tool-call routing overhead per agent step |
None of the right-hand column shows up in a standard GPU cluster dashboard. None of it shows up in a typical cloud cost allocation report, because it’s CPU time on host nodes that were provisioned as “infrastructure overhead” rather than as a workload in their own right. You cannot manage a constraint you don’t instrument, and right now, almost nobody is instrumenting this one.
Why Capacity Models Haven’t Caught Up
Capacity planning models inherit their structure from whatever the dominant cost driver was when they were built, and the dominant cost driver — for the entire first wave of AI infrastructure — was the accelerator. That assumption is load-bearing in ways that aren’t obvious until agentic workloads start breaking it.
| Old Capacity Model (Compute-Centric) | New Capacity Model (Coordination-Aware) |
|---|---|
| Size accelerator fleet first; host nodes follow a fixed ratio | Size coordination layer independently — it scales with task complexity, not model size |
| Host CPU sized for I/O and feeding the accelerator | Host CPU sized for orchestration, arbitration, and policy load |
| Headroom planning based on GPU utilization trends | Headroom planning includes orchestration-call growth per agent task |
| Cost allocation maps to GPU-hours | Cost allocation must split GPU-hours from coordination-hours |
| Scaling triggers: accelerator queue depth | Scaling triggers: agent loop latency, lock contention, context arbitration backlog |
This is also where the cost-visibility problem connects directly to economics. The Cloud Strategy pillar’s work on cost visibility and cost control has already established that the organizations with the worst cost surprises are the ones with the least visibility into where spend is actually accruing — not how much they’re spending overall, but which layer of the architecture is consuming it. Coordination Density is about to become the largest unaccounted-for line item in AI infrastructure spend, for exactly that reason: it’s real cost, accruing on real hardware, that nobody’s capacity model has a column for yet.
The Next Constraint Won’t Look Like the Last One
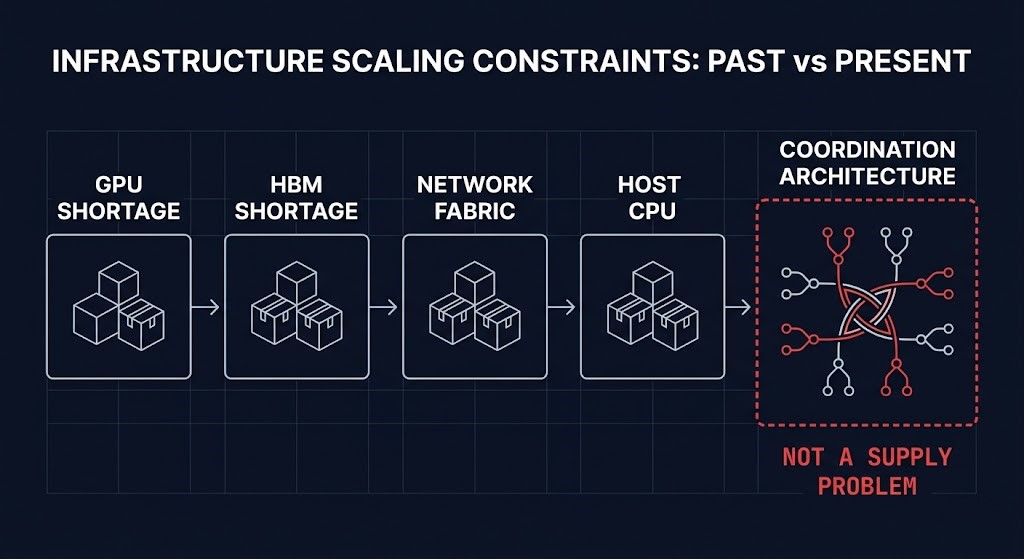
Every capacity constraint in AI infrastructure so far has looked like a hardware shortage — GPUs, then HBM, then network fabric, now host CPUs. The pattern has trained an entire industry to ask “which component is scarce?” as the first and sometimes only capacity question.
The next constraint won’t look like that, because it isn’t a hardware shortage at all. It’s an architectural one. You can buy more CPUs. What you can’t buy is a coordination architecture that doesn’t need to scale non-linearly as agentic systems take on more agents, longer task horizons, and more cross-agent dependencies. The constraint is the shape of the coordination problem, not the supply of the silicon underneath it — and shape-shaped constraints don’t get solved by procurement.

Framework #132 — Coordination Density
What all of the above systems are converging toward is a single underlying relationship, and naming it is what makes the rest of this tractable.
FRAMEWORK #132 — COORDINATION DENSITY
Compute Density measures how much infrastructure executes work. Coordination Density measures how much infrastructure is required to govern that work — and in agentic systems, the second grows faster than the first.
When Coordination Density isn’t planned for, the system doesn’t fail at the GPU. It fails at the layer that was never measured — and the failure looks like latency, contention, and cost overrun with no obvious cause.
The operational implication is the part worth holding onto: scaling GPU capacity in an agentic system does not scale linearly with the coordination capacity required to govern it. Add agents, add task depth, add cross-agent dependencies, and the orchestration, arbitration, and policy-evaluation load grows faster than the execution load it’s coordinating. Every constraint described above — the Xeon shortage, the GPU-centric tooling, the missing metrics, the lagging capacity models — is a downstream consequence of that one relationship going unmeasured and unplanned for. Coordination Density isn’t a new thing happening to AI infrastructure. It’s the thing that’s been happening, now named.
Architect’s Verdict — Constraint Reclassification
The GPU is a throughput engine. It was never anything else, and nothing about agentic AI changes that. What’s changed is that throughput is no longer the constraint that determines whether the system works. The CPU is the coordination governor — the layer that decides what the throughput engine is allowed to do, in what order, under what policy — and in agentic systems, the coordination governor is now the layer under the most unaccounted-for load in the entire stack.
The real constraint isn’t compute scaling. It’s orchestration scaling. Every team that sized its agentic AI infrastructure the way it sized its training infrastructure — accelerator first, host layer as an afterthought — has a Coordination Density problem it hasn’t measured yet, and the Xeon shortage is just the first place that problem became visible enough to make headlines.
This reclassification has a direct lineage. Coordination Density (#132) is the upstream relationship; everything downstream of it is a consequence of that relationship being acted on, or ignored, by policy and governance systems that weren’t built for it. When policy enforcement can’t keep pace with coordination load that scales non-linearly, you get Policy Intent Drift (#133) — the gap between what governance policy says should happen and what the system, under coordination pressure, actually does. When that drift accumulates across a sovereign or regulated environment, you lose the ability to prove what happened and why — the Sovereignty Evidence Chain (#134) breaks precisely where coordination decisions were made fastest and recorded least. And at the root of both is a question every organization running agentic systems will eventually have to answer directly: who owns the control plane making these coordination decisions, and where does that ownership boundary actually sit — the Control Plane Ownership Boundary (#135), already the architectural center of gravity for Cloud Strategy’s CS4 stage.
The CPU was never gone. It was misclassified. Agentic AI is the workload that makes the misclassification expensive — and Coordination Density is the name for what it costs.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session