Nutanix AHV Operations: What Changes After VMware Migration
The operational friction begins after the migration succeeds. Workloads are running. Clusters are stable. Teams declare victory — then discover that platform relocation and operational normalization are two different problems. This post begins where migration stabilization ends. If you are still in the cutover phase, start with the VMware to Nutanix migration Day-2 operations guide, or review the full VMware Migration Strategy track for the broader execution architecture. What follows is the operational layer that activates after the workloads have already moved.
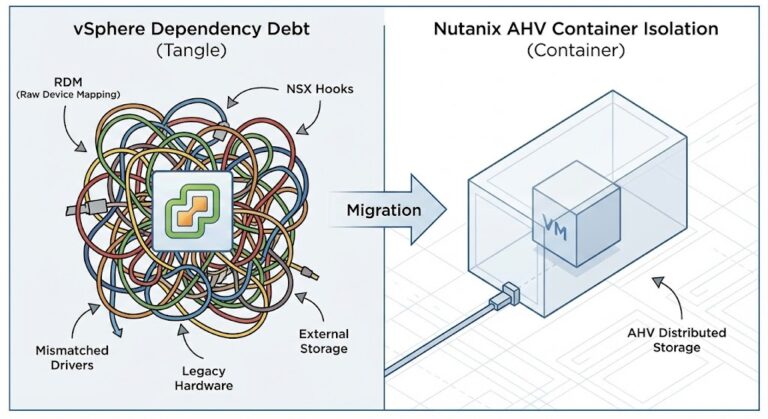
Nutanix AHV operations look familiar on the surface. There are still clusters, VMs, storage policies, and replication workflows. The terminology carries over just enough to create confidence — and that confidence is where most post-migration operational debt originates. Teams that have spent years building VMware operational reflexes carry those reflexes into a Nutanix AHV operations environment that works on different assumptions. The platform changed. The instincts did not.
AHV Changes the Operational Center of Gravity
In VMware environments, the operational center of gravity — the platform, interface, or workflow where infrastructure teams instinctively orient first during failure investigation, escalation, or recovery — sits at the hypervisor layer. Engineers go to vCenter. They check ESXi host state. They look at vSAN health. The mental model is hypervisor-first, and the operational workflows are built around it.
AHV moves that center of gravity. Prism becomes the primary operational surface. The HCI model integrates compute, storage, and networking into a single platform abstraction — which means the hypervisor layer is no longer where most operational questions get answered. It is one layer below where the work actually happens. Teams trained to descend immediately into the hypervisor often find themselves investigating at the wrong level, because the platform surface has shifted higher in the stack.
This is not a tooling difference. It is an architectural orientation difference. VMware operations tend to be silo-oriented — compute teams, storage teams, and network teams operating against separate tool sets with separate escalation paths. AHV operations consolidate those disciplines into a platform-centric model. That consolidation is one of AHV’s operational advantages, but only after teams have adjusted to it. Before that adjustment completes, the consolidation creates disorientation in operators who expect the familiar separation. The HCI architectural shift that eliminates the storage handshake is the same shift that eliminates the operational silos — and both require reorientation.

VMware Operational Assumptions That Break
The most difficult operational transitions are the ones that look familiar on the surface. AHV environments still run clusters, VMs, storage, and replication workflows — but the operational assumptions underneath those systems are different enough that inherited VMware instincts can create friction long after the migration completes. This is operational muscle memory working against the team. The reflex that served an engineer well in a vCenter-centric environment will orient them incorrectly in a Prism-centric one. The skills gap that drives VMware exit risk is the same gap that surfaces as operational friction after the exit completes.
| VMware Operational Assumption | AHV Operational Reality |
|---|---|
| Hypervisor-centric workflows — investigate at the ESXi layer first | Platform-centric workflows — Prism is the operational authority |
| Separate storage operations with dedicated tooling | HCI-integrated storage — no separate storage operations layer |
| Tool fragmentation across compute, storage, and network domains | Operational consolidation — Prism Central covers the integrated surface |
| Existing runbooks transfer cleanly to the new platform | Many operational patterns require rewrite — not just tool substitution |
| Traditional cluster failure domain assumptions apply | Failure domain behavior differs — AHV cluster resilience operates differently |
| vCenter as the operational authority and escalation anchor | Prism Central as operational authority — different escalation topology |

The runbook assumption is the most operationally expensive row in that table. Teams frequently attempt to map VMware runbooks directly onto AHV procedures, substituting Prism screens for vCenter screens and assuming the underlying logic transfers. It often does not. The failure modes are different. The remediation steps are different. The verification checkpoints are in different locations. What looks like a familiar procedure may resolve to the wrong outcome because the platform it was written for no longer matches the platform it is being applied to. The execution physics that govern how ESXi and AHV handle workloads differently are precisely what make direct runbook transfer unreliable.
Where Operators Look First Changes
Observability orientation is one of the subtler shifts in Nutanix AHV operations after migration — and one of the more disorienting ones. The question is not only which tools operators use, but where they look first, which signals they trust, and what normal looks like on the new platform.
On vSphere, operators develop a calibrated sense of normal. They know what healthy ESXi host metrics look like, what vSAN latency patterns are acceptable, what vCenter event logs signal a problem worth escalating versus a routine state transition. That calibration is earned over time. It is also non-transferable. AHV surfaces different telemetry, reports through different signal paths, and defines normal differently. An operator watching Prism dashboards with VMware-calibrated intuitions is reading an instrument panel they have not yet learned to interpret. Prism Central’s operational visibility model is purpose-built around cluster-level health rather than host-level metrics — a fundamental reorientation from vCenter’s approach. The CVM resource overhead patterns that influence AHV performance signals are a direct example — they have no vSphere equivalent and require separate calibration.
The troubleshooting path changes as well. VMware failure investigation often starts with a descent — check the host, check the datastore, check the vSwitch. AHV failure investigation frequently starts higher: check Prism Central’s health summary, check cluster-level alerts, then descend into node-specific diagnostics if the platform-level view has not already isolated the issue. Teams that start by descending into AHV node-level diagnostics before consulting the platform view are adding investigation steps the architecture was designed to eliminate.
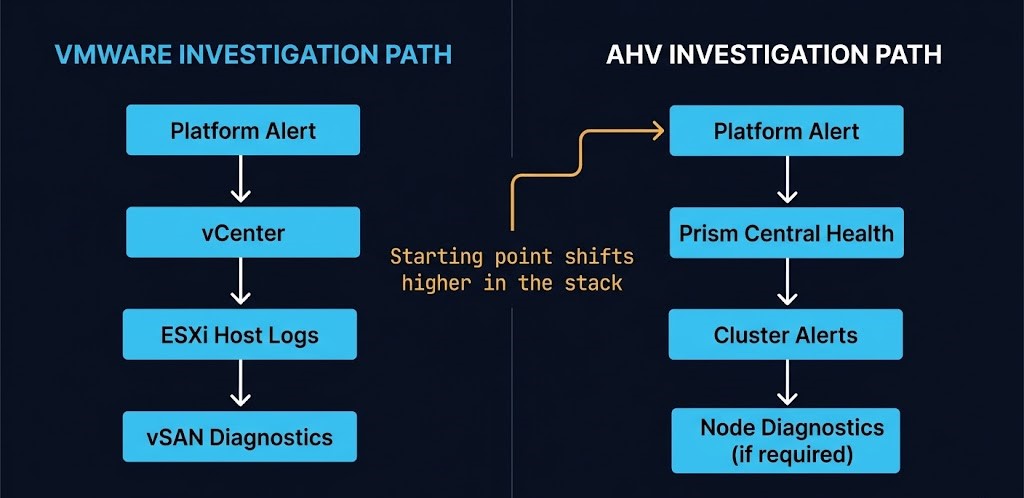
Escalation reflexes also shift. What constitutes an operator-owned issue versus a Nutanix support engagement is a different boundary than the VMware equivalent. Teams that inherited clear escalation definitions need to rebuild those boundaries for the AHV context. Nutanix support severity definitions and engagement models differ from VMware GSS in meaningful ways — understanding those boundaries before an incident is part of operational readiness. The organizational memory of who to call and when is part of operational normalization, and it is frequently overlooked in migration planning.
Day-2 Operations Become the Real Migration
Most migration projects are planned around workload movement. The project scope covers assessment, dependency mapping, wave planning, cutover execution, and stabilization. Those phases are well-documented, well-tooled, and well-understood. What most migration project plans do not scope — or scope insufficiently — is that Nutanix AHV operations normalization is a separate and parallel effort. The identity and configuration issues that surface post-migration are one visible symptom of this gap; operational assumption debt is the less visible but larger one. The full operational and architectural context for this transition is mapped in the HCI Failure-State Architecture specialization track.
Operational retraining is a time investment, not a one-time event. Engineers need exposure to the new platform’s failure behaviors before they will trust their own judgment in an incident. That confidence builds through normal operations — through routine troubleshooting, through minor events that get resolved without escalation, through gradual recalibration of what normal looks like. It cannot be compressed into a training session before go-live.
Tooling adaptation extends further than most teams anticipate. Scripts written against vSphere APIs do not port cleanly to AHV. Monitoring configurations tuned for ESXi metrics require re-mapping against Prism-sourced telemetry. Automation built around vCenter workflows may have no direct AHV equivalent and needs to be rebuilt from the operational intent up, not adapted from the implementation down. Each of these is a discrete project, not a configuration change. Teams that experienced migration stutter during high-I/O cutovers often discover this tooling gap in the same window — the cutover phase surfaces what the normalization phase has to clean up.
Governance and process updates accumulate quietly. Change management procedures that reference vCenter configuration items need revision. Capacity planning models built on vSphere metrics require recalibration for HCI resource contention math. Post-migration capacity models also need to account for a shifting hardware procurement baseline — bare-metal cloud acquisition is now faster and cheaper for many workload profiles than on-prem hardware refresh cycles, which changes how much headroom you need to carry on-cluster. DR runbooks that assume vSphere Replication or Site Recovery Manager behavior need rewriting against Nutanix Async and NearSync replication patterns. None of these are technically complex problems — but they are organizationally distributed, and organizations that declare migration complete at workload cutover often discover them piecemeal through operational incidents rather than through intentional normalization work.
The workload can cut over in a weekend. The operational layer takes months.

What Mature Nutanix AHV Operations Teams Do Differently
Teams that have successfully normalized Nutanix AHV operations after VMware migration share a recognizable pattern. They do not treat operational normalization as a phase that follows migration — they treat it as a parallel workstream that begins before cutover and extends well past it.
They stop assuming runbooks transfer before testing them. Mature teams audit every operational runbook against AHV behavior before declaring it valid. The question is not whether the steps look similar — it is whether they produce the correct outcome on the new platform. Runbooks that have not been validated against AHV failure modes are liabilities, not assets.
They treat every monitoring signal as unverified until it has been validated in the new environment. Existing monitoring configurations get treated as starting points, not finished configurations. Alert thresholds, normal-range definitions, and escalation triggers are all reviewed against AHV’s telemetry model before being relied on in production. Borrowed VMware alert thresholds applied to AHV metrics produce either alert fatigue or blind spots — both are operationally expensive.
They rebuild escalation paths explicitly rather than inheriting them by default. Who owns what changes after platform transition. The internal boundary between what the infrastructure team resolves independently and what gets escalated to Nutanix support is not the same boundary that existed with VMware. Mature teams define this explicitly, document it, and use real incidents to refine it — rather than discovering the boundary under pressure during a severity event.
They redefine failure domains before relying on intuitions built for a different platform. AHV cluster resilience behaves differently from vSphere HA and vSAN fault tolerance. What constitutes a survivable failure, how the platform responds to node loss, and what operator intervention is required during a partial cluster failure are not assumptions that should be carried forward from VMware experience without validation. The rolling maintenance and upgrade physics on AHV are a practical example of where these assumptions get tested earliest. When those assumptions are wrong under real load, the result follows the pattern described in The Degradation Ladder — incremental constraint accumulation that looks manageable until the cluster can no longer absorb the next failure.
They rebuild automation from operational intent, not from vSphere implementation. Automation that was written to work around vSphere constraints, compensate for vCenter behaviors, or interface with VMware-specific APIs represents implementation logic tied to a platform that no longer exists in the environment. Attempting to adapt it to AHV often produces more complexity than building from the operational requirement directly. Mature teams identify this category of automation early and budget for replacement, not adaptation.
They recalibrate capacity planning for HCI math. VMware environments running vSAN taught capacity planning in one model. Nutanix HCI capacity math — replication factor, compression and deduplication savings, CVM overhead, node failure headroom — produces different numbers from different inputs. Capacity plans built on vSphere assumptions applied to an AHV cluster will be wrong, and they will be wrong in ways that are not immediately obvious until the cluster approaches a limit the model did not accurately predict.
They rethink DR workflows against the new platform’s replication model. Recovery objectives that were validated against vSphere Replication or Site Recovery Manager behavior may not hold against Nutanix replication. RPO, RTO, and failover sequencing all need re-validation in the new environment. Nutanix Leap and async replication operate on different protection domain constructs than SRM — teams that assume DR continuity without re-testing are carrying operational assumptions that have not been verified against the platform those assumptions now need to be true on.
Architect’s Verdict
The hardest part of VMware exit projects is rarely the migration itself. It is the operational transition that follows. Infrastructure can move quickly. Operational assumptions usually cannot.
What makes this transition difficult is not the learning curve on a new platform — it is the false familiarity that slows that learning down. AHV is close enough to VMware that teams do not immediately recognize when their inherited reflexes are producing the wrong orientation. The operational center of gravity has shifted. The instincts have not. That gap is where post-migration operational debt accumulates: in runbooks that were never re-validated, in monitoring configurations that were borrowed rather than rebuilt, in escalation paths that were assumed rather than defined, and in capacity models that were adapted from a platform that is no longer present. The failure patterns that surface first after VMware exit are almost always operational rather than technical — and they trace back to this gap.
Organizations that treat Nutanix AHV operations normalization as a parallel workstream — not a post-project cleanup task — close that gap faster and with less incident-driven discovery. The investment is not in the platform. It is in the operational layer built on top of it.
Related Reading
Building the operational foundation for AHV? The Virtualization Deterministic Operations learning path covers the governance and observability patterns that support long-term platform stability.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session