The Skills Gap Is the Real VMware Exit Risk
The vmware skills gap that stalls migrations is not a certification problem. It is not a headcount problem. It is an operating model problem — and most VMware exit plans never model it.
When an organization exits VMware, the platform changes. The operating model — the accumulated behavior, toolchain fluency, and institutional memory built over a decade of running vSphere — does not automatically migrate with it. That gap between what your team knows how to operate and what the target platform requires is where VMware exits actually fail. Not in the architecture. Not in the licensing math. In the people who have to run it on Day 91.
This post is about that gap. What it actually consists of, how it surfaces as failure, and what a migration plan looks like when it accounts for operational replacement — not just platform replacement.
The Licensing Shock Was the Distraction
Broadcom’s acquisition of VMware triggered the largest infrastructure platform re-evaluation in a decade. The pricing changes were real, the cost increases were significant, and the urgency was legitimate. For many organizations, the economics of staying became untenable quickly.
But the speed of that trigger created a problem. Organizations moved fast on platform evaluation and fast on migration planning — and the evaluation criteria were almost entirely technical and financial. Can the target platform run our workloads? What does the TCO look like at three years? When can we start?
The question that got skipped: what does it cost to operate the target platform at depth?
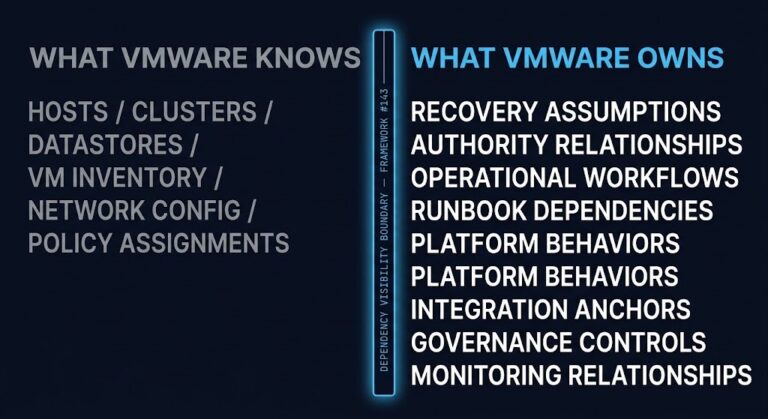
That is a different question from whether the platform can run the workloads. It is a question about the operational knowledge your team carries — and whether that knowledge transfers. The VMware Licensing Cost Model captures the financial trigger well. What it cannot capture is the operational replacement cost that sits on the other side of the migration timeline.
The vmware skills gap showed up later, in the organizations that completed migrations technically and then discovered their teams were operating at novice level on a platform they now owned in production.
What VMware Experience Actually Bought You
The phrase “VMware skills” undersells what is actually at stake.
VMware skills sounds like a certification. It sounds like something you can address with a training budget and a few weeks of lab time. That framing is part of why the gap gets underestimated in migration planning.
What VMware experience actually represents is accumulated operational capital — five distinct components, each one erased the moment you move to a platform the team has never run under production pressure.
When you exit VMware, you are not just replacing a hypervisor. You are exiting ten years of learned operational behavior. That is what needs to be replaced — and it cannot be replaced with a training course.
The Four Failure Modes
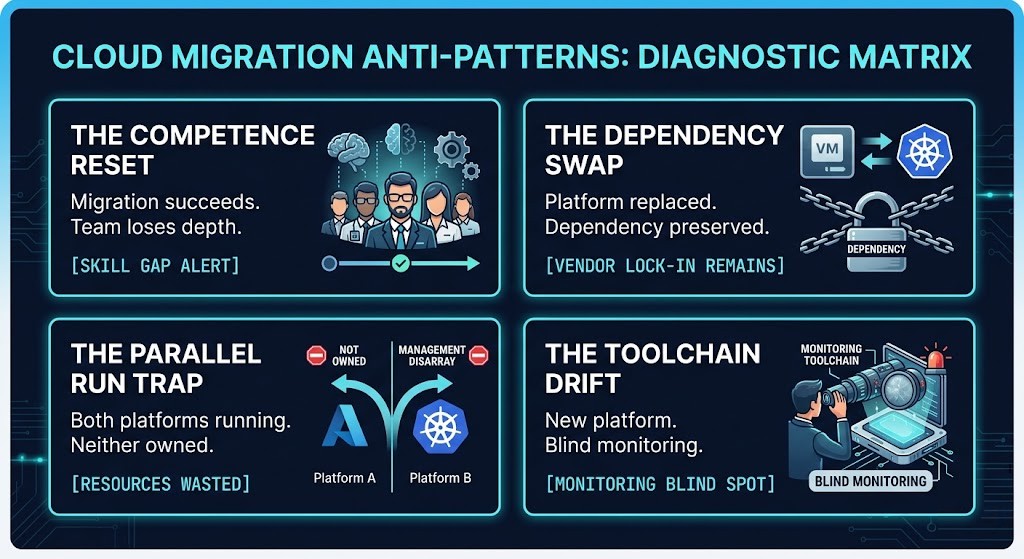
The vmware skills gap does not surface as a single failure. It surfaces through four distinct patterns that appear in post-migration reviews with enough consistency to treat them as a framework.
|
The Competence Reset
Migration succeeds. Team loses depth.
The migration project closes. Day 2 operations begin. The team is operating at novice level on a platform they now own in production. The skills gap was not a migration deliverable — it was assumed to close on its own.
|
The Dependency Swap
Platform replaced. Dependency preserved.
The gap gets filled by an SI or MSP. The migration completes. Operational knowledge never transfers in-house. VMware dependency is replaced by vendor dependency — typically at higher per-incident cost.
|
|
The Parallel Run Trap
Both platforms running. Neither fully owned.
Parallel operation delays the skills gap while doubling operational complexity. Two platforms, two monitoring stacks, two incident response patterns. The cognitive load increases exactly when the team needs capacity to build fluency.
|
The Toolchain Drift
New platform. Blind monitoring.
The architecture decision — “we will use [monitoring platform]” — is documented. The calibration work that makes it operationally meaningful is never scoped. Alerts lose context. Runbooks lose trust. Operators can see something is wrong. They cannot see what.
|
Each failure mode is a different expression of the same unmodeled risk. The migration plan accounted for platform replacement. It did not account for the operational model that ran on top of it.
The Competence Reset
The migration succeeds. The platform is running. Workloads are live. And then Day 2 operations begin — and the team is operating at novice level on a platform they now own in production.
This is the most common failure mode and the most underestimated. The migration project was scoped, executed, and closed. The skills gap was not a migration project deliverable. It was assumed to close through normal operation.
It does not close through normal operation at production pace. It closes through deliberate investment in platform fluency — which takes longer than the migration did, and which compounds every incident that occurs while the team is still building that depth. What that normalization actually looks like in practice on AHV — the operational reorientation, the runbook audit, the escalation path rebuild — is mapped in detail in Nutanix AHV Operations: What Changes After VMware Migration.
The Competence Reset does not mean the migration was wrong. It means the migration plan was incomplete.
The Dependency Swap
The organization exits VMware. It does not exit dependency.
The vmware skills gap gets filled — by a systems integrator, a managed service provider, or a vendor professional services engagement. The migration completes. Workloads are running. But the operational knowledge never transferred in-house. The team can keep the lights on. They cannot diagnose, tune, or architect at depth. Any non-routine operation requires external engagement.
The Dependency Swap is a legitimate short-term bridge. It becomes a failure mode when it is treated as a destination. Organizations that close the migration project while still dependent on external operational knowledge have not completed an exit. They have swapped one dependency for another — and typically at higher per-incident cost than the VMware licensing they were trying to escape.
The Parallel Run Trap
Running both platforms simultaneously is a rational risk management response to the skills gap. Keep VMware operational while the team builds fluency on the target platform. Migrate workloads progressively. Reduce exposure as confidence grows.
The trap is that parallel operation does not close the skills gap — it delays it while doubling operational complexity. The team is now managing two platforms, two monitoring stacks, two incident response patterns, and two sets of vendor relationships. The cognitive load increases precisely at the moment when the team needs capacity to build new platform fluency.
Parallel runs have a place in migration sequencing. They work as a transition mechanism with a defined end date. They fail when they become indefinite — extending Broadcom licensing exposure while preventing the operational commitment that actually builds platform depth.
The Toolchain Drift
Skills do not fail in abstraction. They fail through tooling.
The team’s operational effectiveness on VMware was not just about knowing the platform. It was about knowing the platform through a specific toolchain — vCenter, vROps, Veeam, the monitoring dashboards, the alert thresholds, the runbooks. That toolchain was calibrated to VMware behavior over years of operation.
On the target platform, the toolchain changes. New monitoring tools. New alert definitions. New runbook assumptions. The team is not just learning a new hypervisor — they are rebuilding the entire operational visibility layer from scratch.
The Toolchain Drift is particularly dangerous because it is invisible in migration planning. The architecture decision — “we will use [monitoring platform]” — is made and documented. The calibration work required to make that monitoring platform operationally meaningful is not scoped, not scheduled, and not treated as a migration deliverable.
The result: operators who are technically running the new platform but operationally blind on it. They can see that something is wrong. They cannot see what. This is the operational layer where Control Plane Dependency Drift becomes a daily operational cost — the management surface the team no longer understands well enough to diagnose under pressure. The identity continuity problem compounds this further — The VM That Survived the Migration But Lost Its Identity documents exactly how a team operating with degraded toolchain visibility misses the identity gap entirely until restore day.
What a Skills-Aware Exit Actually Requires
A migration plan that accounts for operational replacement looks different from a migration plan that accounts for platform replacement. The sequencing matters — and it starts before platform selection is made, not after.
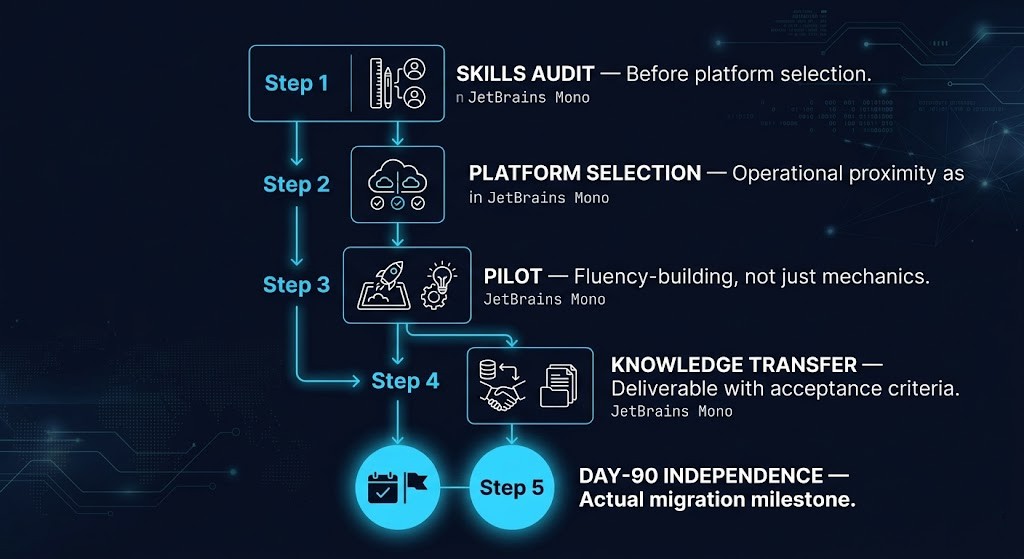
Not Every Exit Costs the Same
The vmware skills gap is not an argument against leaving VMware. The licensing economics are real and the Broadcom trajectory is clear. The argument is more specific than that: not every exit destination carries the same operational cost, and platform selection decisions that ignore that delta are making an incomplete tradeoff.
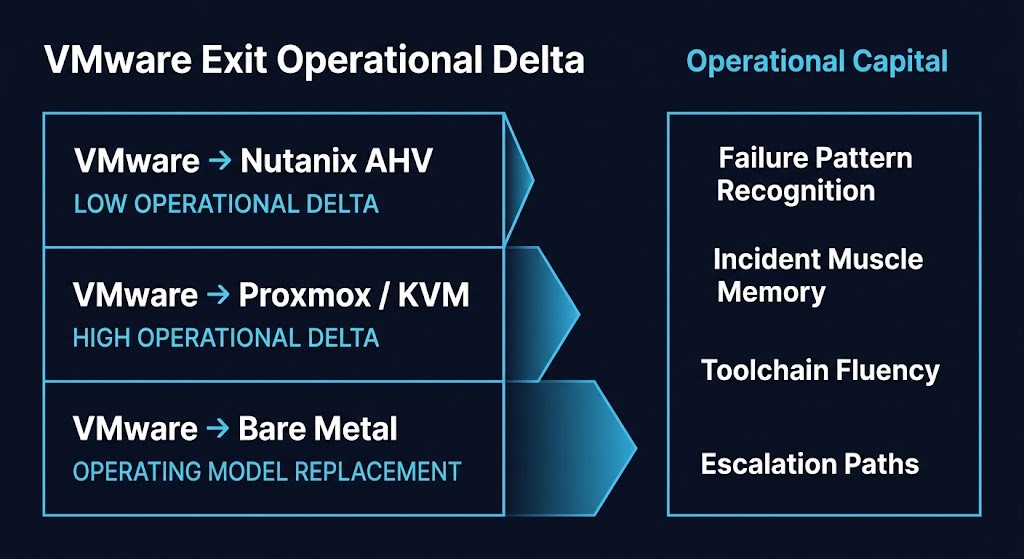
The VMware Exit Operational Delta varies significantly by destination:
VMware → Nutanix AHV represents the lowest operational delta of the common exit paths. The HCI model is familiar. The management plane is abstracted. The operational patterns — cluster management, failure handling, storage behavior — have meaningful overlap with what a VMware team already knows. The Nutanix vs VMware post-Broadcom decision framework covers this in detail.
VMware → Proxmox/KVM represents a higher operational delta. The technology is capable and the economics are compelling, but the operational model is materially different. Less abstraction, more manual tuning, fewer guardrails. Teams moving from managed vSphere to KVM are not just learning a new platform — they are taking on operational responsibility that VMware previously handled for them. The Proxmox vs Nutanix vs VMware comparison maps this delta explicitly.
The operational delta on the Proxmox path also includes assumption carry-forward that is distinct from skills depth. Teams with strong Linux fundamentals still hit production failures driven by VMware operating model assumptions — about snapshot behavior, storage cache semantics, and cluster communication — that survive the skills transition intact. The Proxmox Migration Assumptions That Break at Cutover separates the skills gap from the assumption gap on the Proxmox path.
Both gaps — skills and assumptions — depend on a prior visibility problem. The dependency surface that determines operational delta cannot be read from configuration state alone. VMware estates accumulate licensing exposure, integration authority, and behavioral assumptions over years with no canonical record. Before the operational delta can be modeled accurately, that surface has to be recovered. VMware Licensing Pressure Created a Dependency Audit Problem is where that recovery work is scoped.
VMware → bare metal is not a platform migration. It is an operating model replacement. The Lift-and-Shift to KVM Fallacy covers exactly why teams that treat this as a platform swap consistently underestimate what they are taking on. The Bare Metal Orchestration Strategy Guide describes the operational depth that bare metal actually requires. A VMware team that takes this path is not building on existing operational capital. They are starting over.
VMware → Kubernetes as the exit ramp is a different category entirely. It is not a hypervisor replacement — it is an operating model replacement at the workload layer. The Kubernetes VMware Exit Ramp covers when this path makes sense and what the operational transition actually requires.
The operational delta is a selection criterion. Teams that have it explicitly modeled make better platform decisions. Teams that discover it post-migration are managing the consequences of an incomplete evaluation.
A VMware skills gap that would be manageable on a high-proximity destination becomes a serious operational risk on a low-proximity one. Model the delta before you commit to the destination.
The full sequence that follows destination selection — translating execution physics, mapping failure domains, porting policy logic, and building the governance
normalization layer that closes the operational maturity gap — is what the VMware Migration Strategy Track covers across its five clusters, with Cluster 05
specifically addressing the post-cutover normalization window where the skills gap compounds fastest.
If you want to assess where your team’s operational readiness actually sits before committing to a migration path, the Migration Readiness Assessment is the right starting point.
Before you commit to a destination platform, know where your team’s operational depth actually sits. The Migration Readiness Assessment maps your current VMware operational capital against your target platform’s requirements — and identifies the gaps that will surface under incident pressure.
Review the Assessment →Architect’s Verdict
The vmware skills gap is the migration risk that does not appear in the TCO model, does not show up in the architecture review, and does not announce itself until the migration project is closed and the team is operating the new platform under production pressure.
It surfaces as slow incident response. As escalations to vendors for operations that should be routine. As monitoring that generates alerts nobody knows how to interpret. As runbooks written for VMware that no longer apply. As a team that technically completed a migration but operationally regressed.
The underlying problem is consistent: the migration plan modeled platform replacement. It did not model operating model replacement. Those are different projects with different timelines, different deliverables, and different definitions of done.
Most VMware exit plans budget for licensing, hardware, and migration services. The ones that fail forgot to budget for operational replacement.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session