Rubrik vs Cohesity: The Enterprise Decision Framework
Most enterprise backup evaluations do not stall because one platform fails technically. The rubrik vs cohesity decision stalls because both pass — and then the evaluation committee realizes it has been asking the wrong question.
Both platforms cleared restore testing. Both cleared immutability review. Both satisfy ransomware posture requirements. Both have credible cloud support stories. Both will pass your compliance checklist.
At that point, most teams keep comparing features because that is the only framework they have. They are not comparing products anymore. They are choosing an operating model — and they have not named it that way yet.

Why Enterprise Backup Evaluations Stall at the Final Decision
The stall is diagnostic. It tells you exactly what the evaluation missed.
Feature comparisons produce feature winners. If your evaluation is still unresolved after both platforms cleared technical review, the evaluation was not testing the right things. What remains is not a technical question. It is an organizational one: can your team describe the operating model it is actually built to run at two in the morning when the recovery platform is what is failing?
Most teams cannot answer that cleanly. The evaluation stalls because the real decision — which operating model fits your organization — was never surfaced as a criterion. The Backup Architecture Strategy Guide covers how most organizations arrive at this point without a decision framework to resolve it.
DIAGNOSTIC QUESTION
“Can you describe the operating model your organization is actually built to run at 2 AM — when the recovery platform itself is what is failing?”
That question narrows the decision faster than any feature matrix. The platform your team can honestly answer that question around is usually the correct platform.
Before licensing, features, or recovery SLAs, there is a more useful test.
THE OPERATING MODEL TEST
01 — AUTHORITY
Where does operational authority need to live when production is degraded?
02 — COST TRAJECTORY
Which cost trajectory can your finance model defend at 3x current data volume?
03 — REPLACEMENT COST
What is your true replacement cost — not the platform, but everything built around it?
Whichever platform your organization can answer those three questions around more honestly is usually the correct platform. The rest of this post works through each question in depth.
The Licensing Model Is Really a Cost Trajectory Decision
The licensing mechanics are not the point. The point is that licensing determines how cost compounds as your environment scales — and the two platforms compound differently.
Rubrik’s subscription model is front-loaded and predictable. You know what you are buying. The per-terabyte or per-workload pricing is visible at procurement, the support is bundled, and the three-year number is defensible to a CFO before the contract is signed. There is less flexibility in how you configure consumption, but the predictability is real.
Cohesity’s model is more flexible on entry. Deployment options and pricing structures give procurement teams more leverage early in the contract. The tradeoff is variability over time. As your data estate grows — unstructured data expansion, new workload types, additional sites — the cost trajectory becomes harder to model with precision. More flexibility early means more variability later. The architectural comparison of how each platform scales is covered in detail in the Rubrik vs Cohesity backup architecture post — this section is specifically about cost consequence, not scaling mechanics.
The enterprise question is not which platform is cheaper today. It is which cost curve your finance team can model and defend when the storage estate grows forty percent and the CFO asks why the number changed. A predictable cost that is slightly higher is easier to defend than a variable cost that is lower on day one but harder to project at renewal.
DIAGNOSTIC QUESTION
“When your data estate doubles and you go back to your CFO, which platform’s cost trajectory is easier to explain?”
If your organization runs a formal FinOps function, Rubrik’s predictability typically integrates more cleanly into chargeback modeling and capacity planning cycles. If your organization has strong procurement flexibility and a team that actively manages vendor relationships, Cohesity’s model gives you more negotiating surface. Neither is correct in the abstract. Both are correct depending on how your organization manages vendor cost over time.
The Control Plane Decision Matters More Than the Backup Engine
The architecture differences between these platforms — SpanFS, node clustering, scale-out internals — are documented elsewhere. This section is about operational consequence, not internals.
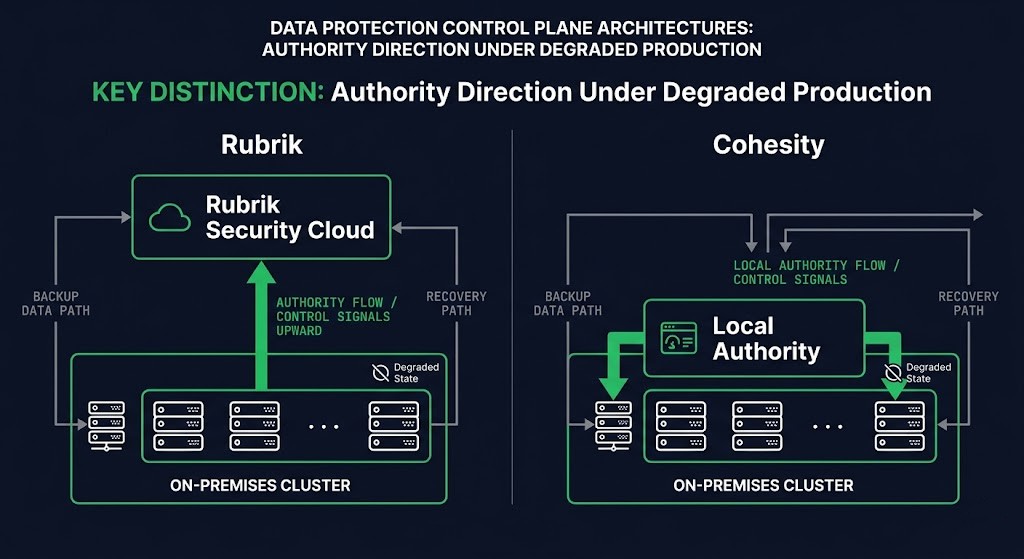
The question that matters for enterprise selection is not which engine is architecturally superior. It is: where does authority live when production is degraded?
With Rubrik, management authority moves upward. The control plane lives in Rubrik Security Cloud, a SaaS layer that provides centralized visibility, policy enforcement, and threat detection across all clusters. When something goes wrong, Rubrik’s telemetry is available to the vendor before it is fully available to your team. That is an advantage in diagnosis speed and a constraint in local autonomy.
With Cohesity, authority stays closer to the cluster. The management plane can run on-premises with SmartFiles and DataProtect operating under local control. Your team retains operational authority without a dependency on a vendor-managed SaaS layer. That is an advantage in environments where SaaS connectivity is constrained — sovereign infrastructure, air-gapped environments, or organizations with policy positions against cloud-managed control planes.
This is not a SaaS-versus-on-premises preference. It is a control-plane dependency decision. The Data Protection Architecture pillar covers this distinction at the architectural layer — but for platform selection, the operational consequence is what matters. For environments where ransomware recovery and control plane survivability intersect, the Rubrik vs Cohesity ransomware protection post covers how each architecture holds under attack pressure specifically.
⚠ COMMON MISTAKE
Evaluating control plane architecture as a feature preference rather than a sovereignty and operational dependency decision. If your recovery runbook requires local authority when the WAN is degraded, the platform whose control plane depends on external connectivity is not a viable option — regardless of its feature set.
For organizations operating in regulated environments, sovereign infrastructure, or hybrid-disconnected architectures, Cohesity’s local control plane is not a feature preference — it is a compliance and operational requirement. For organizations with full cloud connectivity, mature SRE practices, and a preference for vendor-managed observability, Rubrik’s SaaS control plane reduces operational overhead in ways that matter at scale.
Integration Surface Is Where Lock-In Actually Forms
The backup platform itself is relatively easy to replace. A migration project, a parallel run, a cutover window. Painful, but scoped.
What is not easy to replace is everything built around it.
Consider a team eighteen months into a Rubrik deployment. The security operations team has built SIEM alerting workflows that parse Rubrik threat hunt events and feed them into Splunk. The SOAR platform has automated playbooks that call Rubrik’s API to isolate a VM snapshot during an active incident. The compliance team generates weekly evidence reports from Rubrik’s audit logs that feed directly into the GRC platform. The recovery runbook references specific Rubrik API endpoints and recovery orchestration logic that took three months of incident response iteration to stabilize.
None of that is the backup platform. All of that is the integration surface that formed around it — and all of it has to be rebuilt if you replace the engine. The same dynamic applies with immutability architecture: the storage-layer controls are straightforward to migrate; the verification workflows, retention policies, and compliance evidence chains built on top of them are not.
This dynamic is the same with Cohesity. The DataProtect API ecosystem, the DataHawk threat intelligence integrations, the custom reporting pipelines into ticketing systems — these accumulate over time in ways that are invisible on the day of procurement. The Veeam vs Commvault comparison illustrates how this integration debt compounds across platform transitions in enterprise environments — the same principle applies here.
The replacement cost question from the Operating Model Test is really this: how many of those integrations will your team have built by year two, and how many of them depend on platform-specific APIs or data structures that do not translate cleanly to a competing platform?
Evaluate the integration surface before you evaluate the platform. Map the SIEM connections, the SOAR automations, the compliance pipelines, the recovery orchestration dependencies. The platform with the integration ecosystem that fits your existing stack is the platform that will cost less to own over five years — regardless of which one wins on features or licensing today.
Support Is an Incident-Timeline Decision
Support quality is not a static feature. It is not something you can evaluate from a checklist or a G2 review. It matters differently depending on when the recovery platform fails — and recovery platforms fail at the worst possible moment.
The question is not “which vendor has better support.” The question is: at what point in the incident can your team no longer afford to wait on the vendor?
First 30 minutes: fast diagnosis matters most.
In the first thirty minutes of an incident involving the backup platform, you need to understand what is wrong before you can act. Rubrik’s SaaS-side telemetry and centralized logging give the vendor visibility into cluster state before your team has finished reading the alerts. That matters. Rubrik’s support response in the acute phase consistently trends faster in community feedback, and the architecture explains why — the vendor has more visibility, earlier, by design.
Hour 1–4: escalation velocity matters most.
In the following hours, the question shifts from diagnosis to resolution. This is where escalation path quality, support ownership clarity, and the ability to reach an engineer with direct product knowledge become the real differentiators. Cohesity receives more mixed community feedback in this window — not because the platform is less capable, but because local teams face more variability in support consistency and escalation response at this phase.
Hour 6+: local autonomy matters most.
Beyond the first response window, the equation shifts again. If vendor response slows or the issue is not fully resolved, the platform your team can operate around becomes the safer platform. Local cluster access, documented recovery procedures that do not require vendor involvement, and engineering familiarity with the underlying system all matter here. Cohesity’s architecture gives teams more local operational autonomy in this phase — which is an advantage if your team has the depth to use it. The ransomware recovery metrics post covers how recovery time outcomes vary across platforms when the conditions at each phase of an incident are not met.
DIAGNOSTIC QUESTION
“At what point in the incident does your team’s ability to wait on the vendor run out?”
The support decision is an honest assessment of your team’s operational depth. If you have strong in-house platform expertise and a team that can troubleshoot at the cluster level, local autonomy matters more than early vendor visibility. If you have a lean team managing a multi-site estate, centralized vendor visibility in the acute phase likely matters more than local autonomy at hour six.
The Decision Matrix
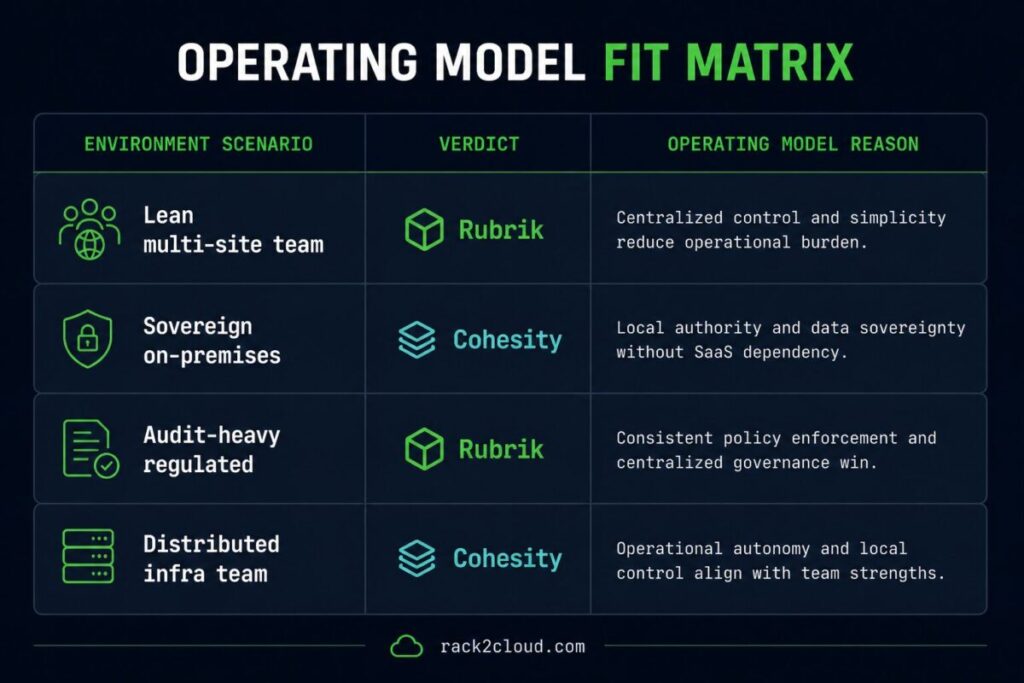
This is not a feature comparison. It is a scenario map. The same platform can be the correct answer for one environment and the wrong answer for a structurally similar one based on operating model fit alone.
| If your environment looks like this | Choose | Why |
|---|---|---|
| Lean ops team, multi-site estate, low tolerance for local troubleshooting burden | Rubrik | Centralized control, SaaS telemetry, and predictable cost trajectory reduce ops overhead at scale |
| Sovereign or on-premises requirement, no SaaS control plane tolerance, strong infra team | Cohesity | Local authority, on-premises management plane, no external dependency |
| Highly regulated, audit-heavy, centralized governance mandate | Rubrik | Consistent policy enforcement, centralized audit log, clean compliance evidence pipeline |
| Distributed infra team with operational autonomy as a design principle | Cohesity | Local cluster control fits the team model and the decision-making structure |
| Active ransomware recovery focus, clean room isolation required | Either — evaluate on control plane survivability | Both platforms support isolation; the decision turns on whether clean room requires on-premises authority or tolerates SaaS dependency |
| Finance team requiring predictable 3-year TCO modeling | Rubrik | Subscription predictability integrates more cleanly into formal cost modeling and chargeback cycles |
The row that matters most is usually the one that describes your ops team — not your workloads. Workloads can be protected by either platform. Operating models cannot be changed at procurement.
Architect’s Verdict
Most enterprises do not choose between backup platforms. They choose between operating models — and only realize it after procurement, when the integration debt starts accumulating and the first serious incident exposes which parts of the decision were never actually made.
Rubrik is the correct choice when operational simplicity is the priority. Centralized control, predictable cost, SaaS-side telemetry, and a support model that gives the vendor early visibility into cluster state all favor organizations with lean teams, multi-site complexity, or a mandate for consistent governance across distributed environments. The tradeoff is upward dependency — authority moves toward the vendor when production degrades.
Cohesity is the correct choice when operational autonomy is the priority. Local cluster control, on-premises management plane, and a support model that keeps troubleshooting authority with your team all favor organizations with strong infra depth, sovereign or disconnected requirements, or a structural preference for keeping operational authority close to the infrastructure. The tradeoff is that the team has to be capable of exercising that autonomy — and at hour six of an incident, that capability is the only thing standing between you and extended downtime.
Choose neither until you know which operating model your organization is actually built to run. The platform that fits your operating model will cost less to own, fail in ways your team can handle, and integrate in ways that do not become technical debt. The platform that does not fit will cost you that lesson at the worst possible time.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session