Serverless AI Inference Without Kubernetes: GCP Cloud Run, Azure Flex, and the Exit Strategy
Serverless AI inference has crossed a threshold most architects didn’t expect this early: you can now run production GenAI workloads — GPU-accelerated, scale-to-zero, without a single YAML manifest — on GCP Cloud Run and Azure Flex Consumption. For the last three years, running a custom model meant building and operating a Kubernetes cluster. That tradeoff no longer holds.
AWS Lambda was useless for this. You can’t fit a modern PyTorch model in the zip limit, the cold starts are 10 seconds, and there is no GPU access. So we forced our teams to manage EKS control planes just to run a stateless inference endpoint.
That ends now.
While AWS is still selling “Provisioned Concurrency” band-aids, Google (Cloud Run) and Azure (Flex Consumption) finally solved the actual problem: Serverless GPUs.
I can now deploy a container that scales to zero, mounts a GPU, and wakes up instantly—without touching a single YAML file. Here is why I am deleting my inference clusters.
Serverless AI Inference: How GCP and Azure Closed the Cold Start Gap
The tradeoff for architects used to be simple: Simplicity or Performance. You couldn’t have both. AWS Lambda gave us simplicity but no GPUs and painful cold starts for Python. SageMaker gave us GPUs but brought 3 AM operational headaches and massive idle costs — and neither solved the fundamental AI inference cost architecture problem.
Google and Microsoft just quietly opened a third path. With GCP Cloud Run + GPUs and Azure Functions Flex Consumption, we can finally deploy AI workloads that scale to zero without the 10-second cold-start penalty—and without touching a single Kubernetes manifest.

The Benchmarks: Engineering EvidenceTo understand the lower-level compute physics
We ran the same Python-based RAG agent across the new serverless generation. To understand the lower-level compute physics of these cold starts, see our module on Architectural Learning Paths.
| Platform | Compute Model | Cold Start (Ready) | GPU Access | Best For |
| AWS Lambda | CPU/Firecracker | ~3–8s (Large deps) | ❌ No | Lightweight Logic |
| GCP Cloud Run | Container/L4 GPU | ~5–7s | ✅ NVIDIA L4 | Raw Inference |
| Azure Flex | Serverless / VNet | ~2–4s | ❌ No* | Enterprise Integration |
Azure Flex Consumption does not currently support direct GPU attachment, but its Always Ready instances and VNet integration make it the superior “Nervous System” for connecting to Azure OpenAI (GPT-4o).
Model Performance on Cloud Run (NVIDIA L4 – 24GB VRAM)
| Model (4-bit Quantized) | Tokens/sec (Throughput) | VRAM Usage | Latency (TTFT) |
| Llama 3.1 8B | ~43–79 t/s | ~5.5 GB | <200ms |
| Qwen 2.5 14B | ~23–35 t/s | ~9.2 GB | <350ms |
| Mistral 7B v0.3 | ~50+ t/s | ~4.8 GB | <150ms |
The Breakthrough: Azure Functions Flex Consumption
Microsoft’s “Flex” plan is a direct response to the Python performance gap. Unlike the old Consumption plan, Flex introduces Always Ready instances and Per-Function Scaling.
Why architects care:
- VNet Integration: You can finally put a serverless function behind a private endpoint without paying for a $100/mo Premium Plan.
- Concurrency Control: You can set exactly how many requests one instance handles (e.g., 1 request at a time for memory-heavy AI tasks).
- Zero-Downtime Deployments: Flex uses rolling updates, meaning your AI agent doesn’t “blink” when you push new code.
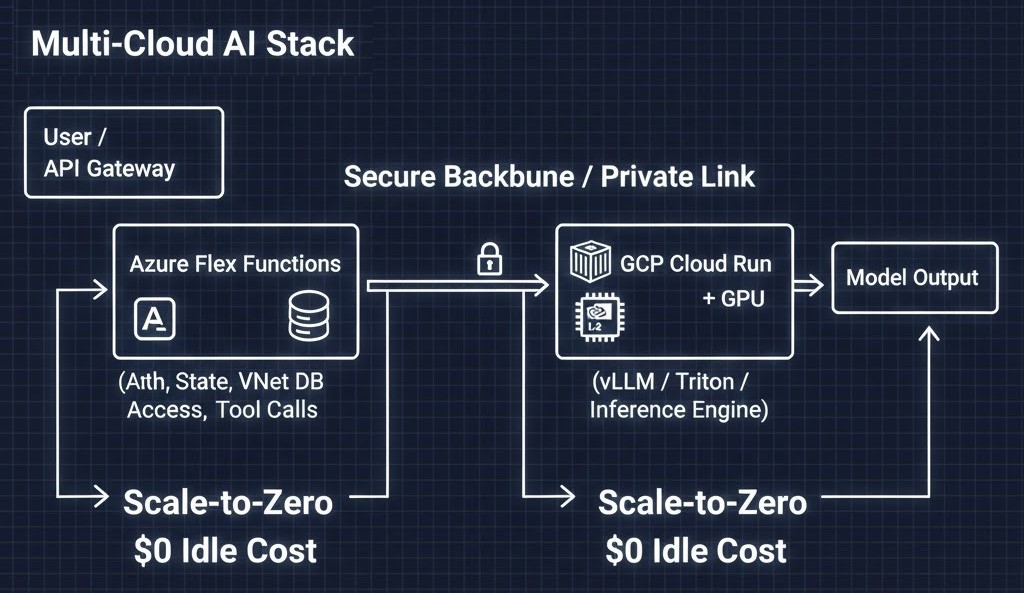
Reference Architecture: The Multi-Cloud AI Stack
To build production-grade AI, you no longer need to manage a cluster. I’m moving toward a “Brain and Nerves” split using two different clouds to maximize cost-efficiency and performance.
[User/API]
|
[Azure Flex Functions]
| (Auth, State, DB Access, Tool Calls)
|
[Private Link / Secure Backbone]
|
[GCP Cloud Run + GPU]
| (vLLM / Triton / Inference Engine)
|
[Model Output]The Flow:
- Orchestrator (Azure Flex): Handles user auth, state (Durable Functions), and VNet-secured database lookups.
- Inference (Cloud Run + GPU): Azure calls GCP to perform heavy reasoning on NVIDIA L4s.
- Scale-to-Zero: Both platforms vanish when the request is done, resulting in $0 idle cost.
Failure Modes: What Breaks First?
Senior architects know “Serverless” isn’t magic. Here is what I actually had to debug:
- Azure Initialization Timeout: If your Python app takes >30s to start (e.g., loading a 2GB model), Azure Flex will just kill the instance. You’ll see a generic
System.TimeoutException. - GCP Quota Limits: Cloud Run GPU quotas default to zero. If you don’t request an increase, your deployment will fail silently.
- Memory Bloat: Azure Flex has a ~272 MB system overhead. Account for this in your sizing or you’ll be hit with endless OOM restarts.
Cost Behavior: The CFO Perspective
This is built on our core Architectural Pillars—market-analyzed and TCO-modeled.
- The Old Way: ~$150+/month per region just to keep a GPU “warm” on a cluster.
- The Serverless Way: Pay only for the milliseconds the agent is actually thinking.
- The Break-even: If your agent runs for only 10 minutes per hour, serverless is ~80% cheaper than a reserved instance.
The Rack2Cloud Migration Playbook
Don’t start with a cluster. Evolve into one.
- Phase 1: Prototyping (AWS Lambda / Azure Consumption) — Move fast, ignore cold starts, focus on the prompt.
- Phase 2: Orchestration (Azure Flex Consumption) — Secure your data with VNets and stabilize Python latency.
- Phase 3: Cost/Privacy Optimization (GCP Cloud Run + GPU) — Move inference off expensive APIs and onto your own private L4 containers.
- Phase 4: Repatriation (On-Prem / Bare Metal) — Once your monthly inference bill exceeds $5,000, exit the cloud using our Cloud Repatriation ROI Estimator.
Architect’s Verdict
The Kubernetes-or-nothing era for AI inference is over — but not uniformly. GCP Cloud Run with GPU is the right call when you need raw inference performance on NVIDIA L4 hardware without cluster management overhead. Azure Flex is the right call when enterprise networking, Durable Functions state management, and VNet-secured database access are the actual constraints.
The mistake is treating these as competing platforms. They are complementary execution surfaces — and the multi-cloud split architecture covered above reflects what production serverless AI inference actually looks like when you optimize for both cost and capability rather than picking one cloud and accepting its tradeoffs.
The calculus shifts at scale. Below roughly $5,000/month in inference spend, serverless wins on cost and operational simplicity. Above that threshold, the repatriation math starts working — and [bare metal inference architecture](/bare-metal-orchestration-strategy-guide/) becomes worth modeling. The exit strategy from Kubernetes isn’t a final destination. It’s a phase in the infrastructure lifecycle.
Additional Resources:
This post is the architecture. These are the deeper dives.
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




