Inference Routing Is Becoming an Infrastructure Placement Problem
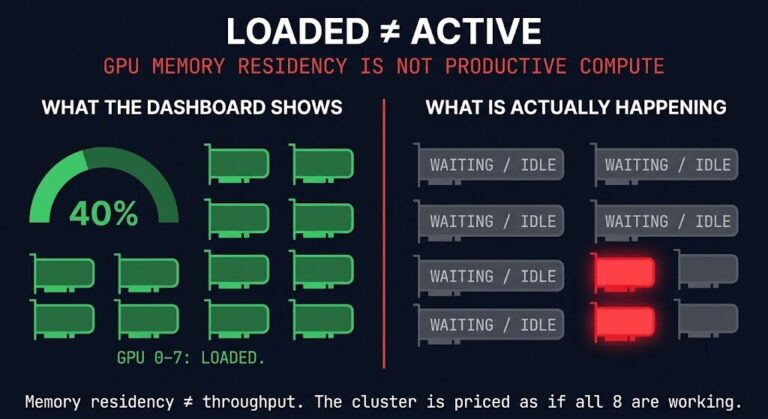
The request arrives. The model answers. For most teams, everything in between is invisible — a gateway rule, a load balancer entry, maybe a classifier someone wrote three months ago. That worked when inference meant one cluster and one model family. The execution environment was fixed, so the routing decision was trivial.
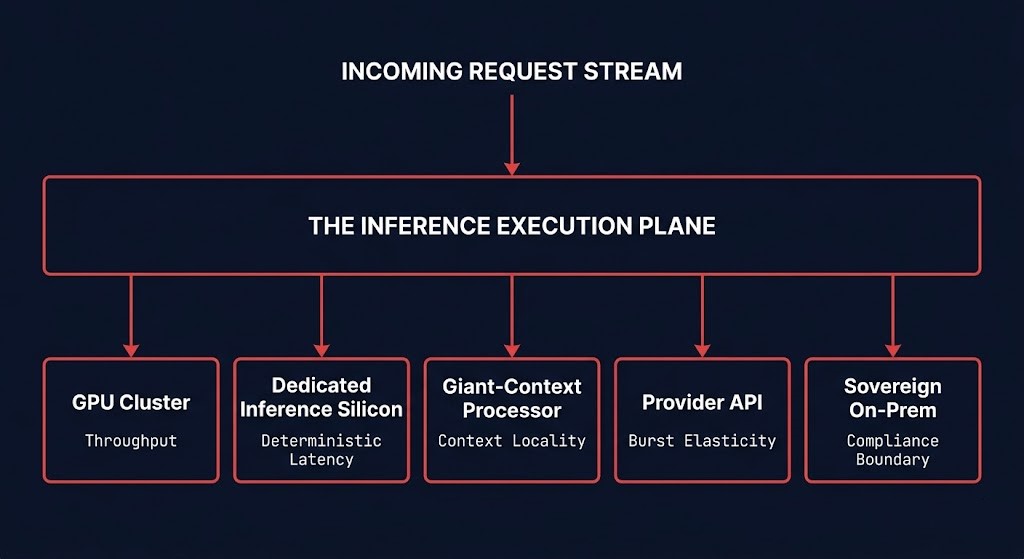
That assumption is gone. Enterprise inference now spans GPU clusters, dedicated inference silicon, giant-context processors, provider APIs, and sovereign on-premises substrates — each with different physics, different cost models, and different failure domains. Every routing decision is now implicitly a placement decision. And the application layer was never designed to make it correctly. That accumulation by default is the same pattern that produces AI control plane sprawl across the inference layer — routing logic, orchestration runtimes, and observability pipelines that exist in production with no defined operational owner because nobody classified them as infrastructure requiring governance.
Inference placement orchestration is the discipline of governing those decisions at the infrastructure level — where the signals, the authority, and the system visibility actually exist.
THIS POST IS NOT ABOUT MODEL SELECTION
Cost-aware model routing asks: which model should answer this request? Infrastructure-aware inference placement asks: where should this request execute — on which substrate, under which topology, within which latency and sovereignty constraints? Those are no longer the same problem. The first is covered in Cost-Aware Model Routing in Production. This post covers the second.
The Routing Frame Is Obsolete
The API gateway inherited inference routing the same way it inherited everything else — by default, because it was already in the path. When inference ran on a single cluster against a single model family, that was fine. The gateway forwarded the request. The cluster handled it. Routing was endpoint selection, and endpoint selection was trivial because there was essentially one endpoint.
That architecture encoded an assumption that no longer holds: that the execution environment is fixed. Once inference spans multiple substrate types, the routing decision stops being about which model handles the request and starts being about which execution environment the request enters. Those are materially different problems.
An API gateway that was designed to balance HTTP traffic across homogeneous nodes is not equipped to arbitrate between a GPU cluster optimized for throughput, a dedicated inference accelerator optimized for deterministic low latency, and a provider API optimized for burst elasticity. The decision variables — physics, cost tier, latency class, failure domain, sovereignty boundary — exist at the infrastructure layer. The gateway doesn’t see them.
The teams that recognize this shift early won’t be scrambling to retrofit placement logic into application code when they add their second substrate type. The ones that don’t will discover the problem the hard way: through latency variance they can’t explain, cost anomalies that don’t map to request volume, and sovereignty violations that the application registered as successful responses.
Inference Placement Orchestration Requires a New Architectural Layer
What’s needed is a formal definition of what has been informally accumulating as scattered decisions across application code, gateway configs, and ad-hoc infrastructure policy.
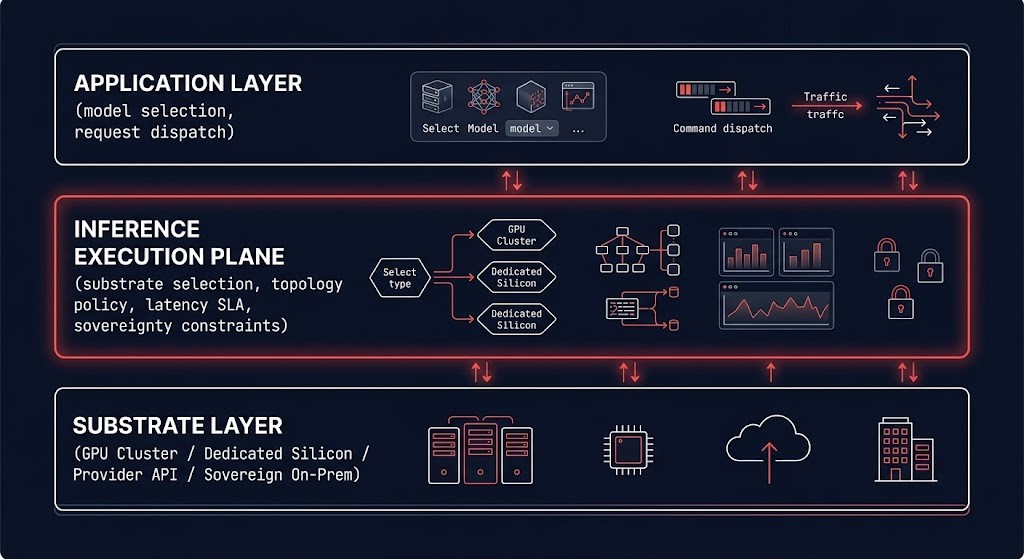
The Inference Execution Plane is the infrastructure layer responsible for substrate selection, topology awareness, latency SLA enforcement, and execution cost assignment across heterogeneous inference substrates. It is not a product category. It is an architectural function — the placement authority layer that governs where inference workloads execute and under what constraints.
This distinction matters: the Inference Execution Plane is not the inference platform. It is not Kubernetes for AI, inference middleware, or orchestration tooling. Those systems manage the lifecycle of inference services. The Execution Plane governs the placement decisions that determine which service handles which workload, under which infrastructure conditions, within which policy boundaries.
The function exists in every multi-substrate inference deployment today. The problem is that it’s distributed across systems that weren’t designed to own it — application routers with no infrastructure telemetry, gateway configs that hardcode substrate assumptions, and team boundaries that give application engineers authority over decisions that require infrastructure visibility.
Formalizing the Inference Execution Plane as an explicit architectural layer is the first step toward placing that authority correctly.
Multi-Substrate Inference Is a Physics Problem Disguised as an API Problem
The most common misread of the inference routing problem is that it’s a software problem — better classifiers, smarter gateways, more granular routing rules. That framing misses the underlying issue.
Multi-substrate inference is fundamentally a physics problem. Each substrate class carries materially different execution characteristics that determine whether a given request belongs there:
| Substrate | Optimized For | Governing Constraint |
|---|---|---|
| GPU cluster | Throughput, parallel batch | Memory bandwidth, tensor parallelism |
| Dedicated inference silicon (Groq-class) | Deterministic low latency | Fixed execution timing, queue depth |
| Giant-context processors (Cerebras-class) | Large context windows | On-chip SRAM locality |
| Provider API | Burst elasticity | External rate limits, egress cost |
| Sovereign on-premises | Compliance boundary | Jurisdiction, air-gap policy |
These aren’t performance tiers. They’re architecturally distinct execution environments with different physics. Routing a latency-sensitive synchronous request to a throughput-optimized GPU cluster doesn’t just affect response time — it enters a different queuing model, a different memory locality regime, and potentially a different failure domain. The request may succeed. The infrastructure cost of that success may be invisible to the application.
This is what separates inference placement from the training/inference hardware split that became visible at GTC 2026. Hardware fragmentation didn’t create the placement problem — it made it unavoidable. When a single GPU cluster handled everything, substrate arbitration didn’t matter. Once training and inference silicon diverge, and dedicated inference accelerators enter the stack, every request carries an implicit substrate assignment. The question is whether that assignment is made deliberately or by default.
Deterministic networking becomes relevant here at a layer most teams haven’t reached yet: when the interconnect itself is part of the inference execution path, fabric topology becomes a placement input. The request isn’t just selecting a substrate — it’s selecting a path through an interconnect fabric with its own latency characteristics, congestion domains, and saturation thresholds.
The fabric constraints that make this a physics problem — east-west bandwidth, oversubscription ratios, congestion domains, and the Execution Locality Boundary — are covered in the Fabric Architecture stage of the AI Architecture Learning Path.
This is workload arbitration. Calling it routing undersells the problem.
The cost consequence of getting that arbitration wrong is already measurable. CAST AI’s 2026 production data across 23,000 clusters puts average enterprise GPU utilization at 5% — scheduling, placement, and fragmentation compounding into structural waste. The placement problem isn’t theoretical. It’s on the invoice. Full breakdown: GPU Utilization Is Becoming the New Cloud Waste Crisis.
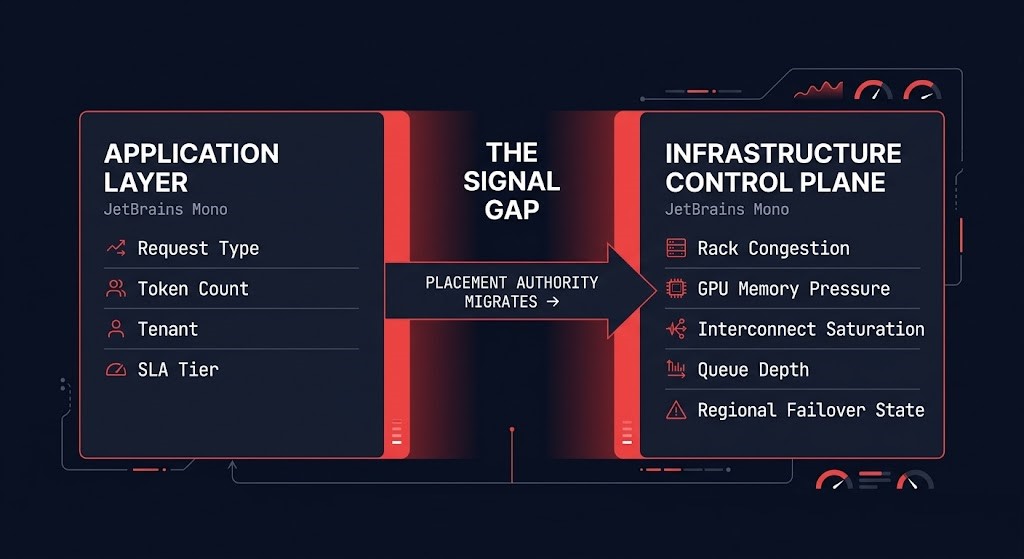
Application Routers Are Blind to Infrastructure Signals
The practical consequence of application-layer routing is a structural information gap. Application routers are optimized for what they can observe. Infrastructure signals are outside their observability boundary entirely.
The two signal sets don’t overlap:
THE SIGNAL GAP
- Application-visible: request type, token count, tenant identity, SLA tier, model preference
- Infrastructure-visible: rack congestion, GPU memory pressure, interconnect saturation, inference queue depth, east-west traffic load, regional failover state, reserved vs. burst substrate allocation, power and cooling headroom
The application router optimizes locally against the signals it can see. The infrastructure absorbs the cost of decisions made without the signals it holds. On a single substrate, this gap is manageable — there’s little to arbitrate. On multi-substrate deployments, it becomes a structural failure mode.
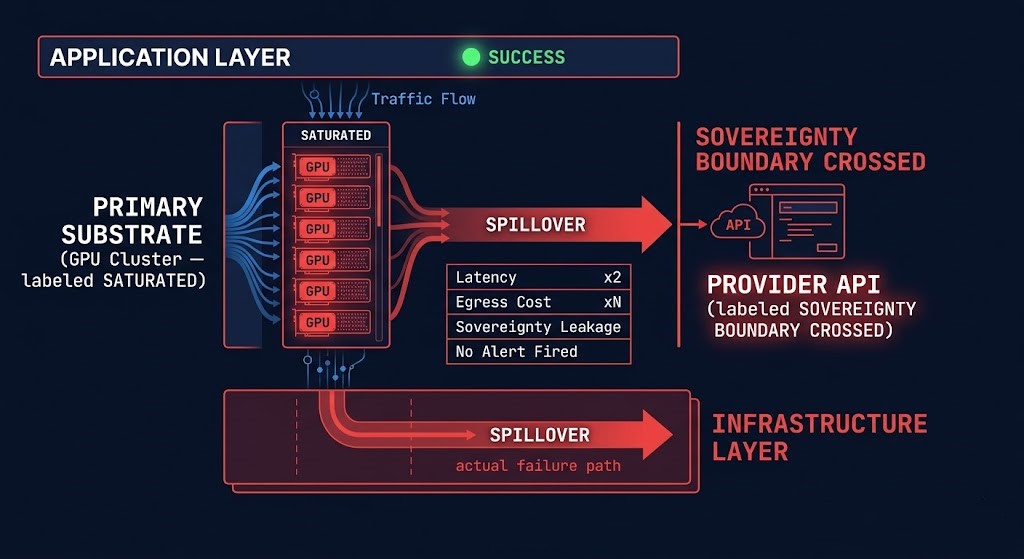
Locality Collapse is the formal name for what happens when this gap goes unaddressed. It is the loss of topology-aware execution locality caused by routing systems that optimize for endpoint availability rather than infrastructure placement efficiency. The consequences compound as the substrate footprint grows: hidden cross-zone bandwidth amplification, interconnect congestion from misrouted workloads, latency variance that doesn’t track request complexity, sovereignty leakage from spillover that the application never flags, and egress multiplication from cross-region routing that was never modeled.
The most acute expression of Locality Collapse is inference spillover: the primary substrate saturates, the router spills traffic to the next available endpoint — typically a provider API — and the application layer registers a successful response. From the application’s perspective, the request resolved. From the infrastructure’s perspective, a sovereignty boundary may have been crossed, egress cost multiplied, latency doubled, and the spillover event went completely unlogged because the routing system had no model of substrate boundaries. The failure was invisible because the success metric was wrong.
Placement Authority Migrates to the Infrastructure Control Plane
The core problem is not that application teams lack visibility into infrastructure signals. It’s that application code has no mechanism to arbitrate shared infrastructure scarcity — and multi-substrate inference creates exactly that condition.
When inference runs on shared GPU infrastructure, placement decisions affect every tenant on the cluster. An application router making substrate assignments without infrastructure telemetry cannot know whether it is consuming reserved capacity, triggering burst allocation, contributing to interconnect saturation, or pushing a congested substrate further into degradation. These are infrastructure governance problems. Solving them requires infrastructure authority.
WHAT APPLICATION TEAMS CANNOT OWN
- Cross-region execution decisions
- GPU tier consumption across tenants
- Sovereignty boundary traversal
- Congestion avoidance across shared fabric
- Interconnect utilization policy
- Reserved vs. burst substrate allocation
- Power-aware placement under capacity constraints
The correct owner is the infrastructure control plane. The implementation patterns vary — topology-aware placement engines, inference schedulers with live infrastructure telemetry feeds, policy-aware substrate brokers — but the architectural principle is consistent: placement decisions require the global infrastructure visibility that only the platform layer holds.
This is the same migration that has happened at every prior layer of infrastructure complexity. The CI/CD pipeline became the infrastructure control plane for configuration and deployment. The CLI became a governance surface when agentic systems started consuming it. Inference placement is following the same arc — authority is migrating to the layer that has the system visibility to exercise it responsibly. The cluster-level mechanisms that make infrastructure-layer placement authority operational — scheduler configuration, admission control, resource policy, and heterogeneous cluster governance — are the architectural layer directly above this one. The Runtime & Cluster Orchestration stage of the AI Architecture Learning Path covers how placement authority gets implemented in practice once it’s been assigned to the infrastructure control plane.
The Authority Layer series frames this as an infrastructure governance principle: control plane authority follows system complexity. Inference placement is one of the clearest current examples of that principle in motion. The application layer accumulated placement authority by default, not by design. As substrate complexity makes that authority untenable, it migrates to the platform layer — either deliberately, through architectural decisions made now, or reactively, after the first multi-substrate production failure forces the issue. The network layer is where that authority migration is now most visible. As inference workloads distribute across substrates, the fabric connecting them — the east-west bandwidth, the interconnect topology, the congestion domains — becomes an active participant in placement decisions. The network is becoming the AI control plane: the layer where routing authority, telemetry, and policy enforcement are converging as substrate complexity makes application-layer placement untenable.
Inference Placement Is the New Load Scheduling
The transition inference placement is undergoing has a direct precedent in infrastructure history — and the precedent is instructive because every organization that went through it did so reluctantly, then permanently.
VMs needed schedulers. When virtual machines proliferated, placement decisions — which host, which cluster, which resource pool — moved out of manual admin processes and into infrastructure-layer schedulers. DRS, SDRS, affinity rules. The application team didn’t own host placement. The platform layer did.
Containers needed orchestrators. When containers scaled beyond what manual placement could manage, Kubernetes took over bin packing, resource negotiation, and topology-aware scheduling. Again: application teams don’t own node placement. The orchestrator does.
Inference workloads now need topology-aware execution scheduling. The pattern is identical. The execution environments have fragmented. The placement variables — substrate physics, interconnect topology, sovereignty policy, cost tier — exceed what application-layer routing can manage with the signals available to it. The function needs to move.
What’s different this time is the compression. The transition from VMs to schedulers took years. The transition from containers to orchestrators took years. The hardware substrate split in inference happened over months, driven by dedicated silicon entering production alongside GPU clusters at a pace that enterprise planning cycles weren’t designed to absorb. The teams that wait for the transition to feel necessary will be retrofitting placement logic into production systems under pressure.
The AI Gravity & Placement Engine captures some of this reasoning for workload placement decisions — substrate selection based on workload characteristics is a problem that exists today, not in a future architecture.
The speed of that compression also means early placement decisions don’t stay provisional. The latency-versus-cost tradeoffs embedded in initial substrate assignments harden into architectural constraints before most organizations have had a chance to deliberately evaluate them. AI Placement Decisions Harden Into Architecture examines what that calcification looks like — and what it costs to reverse.
The Invisible-Until-Scale Failure Mode
Single-substrate inference deployments hide placement problems. The topology is simple, the substrate is fixed, and the routing decision space is small. When something goes wrong, the failure is usually visible — a saturated cluster, a latency spike, a cost anomaly that maps directly to request volume.
Multi-substrate deployments expose placement problems as distributed systems problems. The failure mode isn’t a discrete event. It’s variance accumulation.
The first symptoms are almost never outages. They’re measurement anomalies: latency jitter that doesn’t track request complexity, inconsistent token throughput across nominally identical requests, degraded tail latency that looks like infrastructure noise, regional quality divergence that only appears in percentile metrics, inference queue oscillation that smooths out before anyone investigates. By the time the failure mode is clearly legible as a placement problem, it has typically been accumulating for weeks.
This is the same pattern documented in autonomous systems drift — gradual degradation that produces no single alerting event until the accumulated variance crosses a threshold. Inference observability at the execution layer, not just the model output layer, is the prerequisite for catching this early. Without placement-level telemetry, the variance looks like noise. With it, the pattern is identifiable. Observability at the execution layer — the telemetry that makes placement dysfunction visible before it compounds — is the operational discipline covered in Operations & LLMOps Architecture. That stage maps the full LLMOps and cost observability layer that turns placement signals into actionable governance.
The specific failure sequence in multi-substrate deployments: a degraded inference node stays in the routing pool because the application router has no infrastructure health signal — only endpoint availability. Traffic continues flowing to a substrate that is congested, throttled, or queued deep. The application sees elevated latency and assumes model load. The infrastructure knows the substrate is saturated. The routing system has no mechanism to act on that knowledge because the signal doesn’t cross the application/infrastructure boundary.
Architect’s Verdict
Inference routing is following the same arc as every other placement problem in enterprise infrastructure. It starts in the application layer because that’s where the first workload lives and the first engineer with a deadline made a decision. It stays there until the complexity of shared infrastructure, heterogeneous substrates, and cross-boundary policy makes application-layer authority untenable.
The organizations that scale AI infrastructure successfully will not be the ones with the best models. They will be the ones that turn inference placement into an infrastructure discipline before scale forces it on them — before the second substrate type enters production, before the first sovereignty incident, before the first multi-tenant GPU contention event exposes the placement logic that was never designed to handle it.
The ones that don’t will eventually discover they built a distributed infrastructure scheduler inside application code — without the telemetry, the placement policy, or the authority to operate it correctly.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session