Ansible & Day 2 Ops Architecture
Terraform provisions. Ansible governs. The boundary between them is where most infrastructure environments lose control.
Day 2 operations architecture is the governance model for infrastructure after provisioning ends — and it is the layer that most IaC strategies treat as an afterthought and most cloud-native adoption patterns claim to have eliminated. Neither assumption holds under production conditions.
Terraform ends at the API. Ansible begins at the running system. The gap between those two statements is where most enterprise infrastructure governance fails — not because organizations lack tooling, but because they have never explicitly defined which tool owns what after provisioning completes.
Day 2 operations are the operational lifespan of infrastructure after it exists. Not the creation of a VM, a Kubernetes node, or a managed database — but everything that happens to it from that moment forward: configuration management, patch distribution, certificate rotation, compliance remediation, secrets injection, controlled restarts, and the accumulation of runtime mutations that no provisioning tool tracks. This is the domain that Ansible was built to govern. It is also the domain that most IaC strategies treat as an afterthought, and that most cloud-native adoption patterns claim to have eliminated.
The transition from Terraform provisioning to Day 2 operations is also where inherited debt surfaces. Environments that were provisioned without a full governance model — incomplete pipeline authority, inconsistent drift detection, module version pins never enforced — don’t arrive at Day 2 clean. They arrive carrying the accumulated state divergence that Terraform never detected and nobody documented. The Day 2 Operations Debt You Inherited From Terraform covers the specific debt categories that enter the operational domain at that boundary.
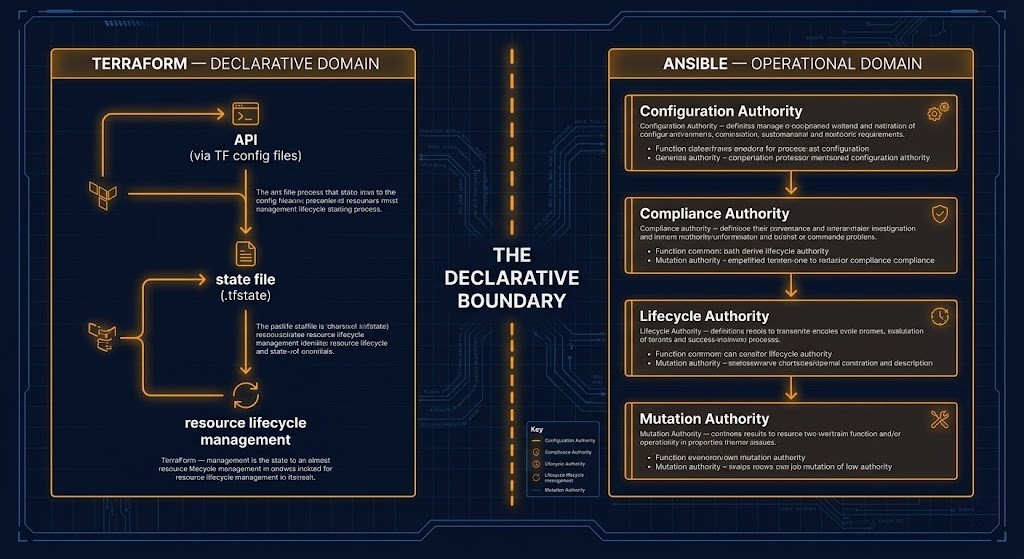
The distinction that matters most is not Terraform versus Ansible. It is declarative versus operational. Terraform governs declared infrastructure state — the desired end state expressed in .tf files and enforced through the Reconciliation Triangle. Day 2 operations govern runtime reality after infrastructure begins changing under production conditions. The moment services patch, certificates rotate, nodes drift, workloads rebalance, or operators intervene manually, the environment exits the purely declarative model and enters the operational mutation layer. That transition — from declarative provisioning to runtime operational state — is what this page calls the Declarative Boundary. It is the architectural line that every infrastructure governance model must locate explicitly, because everything on one side of it follows IaC governance rules and everything on the other side follows Day 2 operational authority rules.
The Declarative Boundary is not a Terraform limitation. It is a structural property of infrastructure at runtime. No provisioning tool — Terraform, Pulumi, CloudFormation, or any successor — can govern the operational state of a running system with the same determinism it applies to resource creation. The operating system accumulates state. Certificates expire. Kernel parameters drift. Packages fall behind patch cadence. Services require controlled restarts to activate configuration changes. These are not failure modes. They are the operational physics of production infrastructure. The question is not whether they happen. It is whether you have an authority model governing them when they do.
Ansible is that authority model. This page covers how it works architecturally — the Day 2 Authority Model, the Declarative Boundary, inventory as a trust architecture problem, AWX as the operational control plane, and the failure modes that occur when Day 2 governance is absent, partial, or split across competing authorities.
What Day 2 Operations Architecture Actually Is
Day 2 operations architecture is the governance model for infrastructure after provisioning ends. The term “Day 2” is borrowed from operational lifecycle frameworks — Day 0 is design and planning, Day 1 is initial provisioning, Day 2 is everything that follows. In practice, Day 2 is where infrastructure spends the overwhelming majority of its operational life. The provisioning event is a moment. Day 2 is months or years of accumulated runtime state, configuration drift, patch cycles, certificate expirations, operator interventions, and mutation events that no provisioning tool was designed to track.
Ansible’s core architectural property is idempotency — the guarantee that running the same playbook against the same system multiple times produces the same result as running it once, provided the system is already in the desired state. This is what makes Ansible safe at Day 2 in a way that scripts are not. A script run against an already-patched system may re-run a package upgrade, restart a service unnecessarily, or overwrite a configuration that an operator modified for a legitimate reason. An idempotent Ansible task checks current state before acting — it only executes the change if the system is not already in the desired state. The idempotency model is not a convenience feature. It is the property that makes automated Day 2 operations safe to run on a cadence rather than only when a human decides conditions are right.
Ansible is also agentless — it communicates with managed nodes over SSH (or WinRM for Windows) without requiring a persistent agent process on the target. This eliminates agent version management, agent upgrade coordination, and the security surface of a long-lived privileged process on every managed host. The trade-off is that agentless operation requires SSH key governance, inventory accuracy, and network reachability at execution time. Neither model is categorically superior — the choice is between agent management overhead and SSH governance overhead, and the correct answer depends on the operational environment.
The Declarative Boundary is the architectural line where Terraform’s governance model ends and Ansible’s begins. On the Terraform side of that line, infrastructure state is declared, version-controlled, policy-checked, and reconciled against a state file. On the Ansible side, infrastructure is a running system accumulating operational history — patches applied, certificates rotated, configurations adjusted, services restarted. Terraform cannot reach across that boundary and govern a running system’s configuration state. Ansible cannot reach across it in the other direction and manage cloud resource lifecycle with the same determinism Terraform applies to API-level provisioning. The boundary is not a deficiency in either tool. It is the structural property of infrastructure that makes both tools necessary — and that makes day 2 operations architecture a distinct discipline rather than an extension of IaC.
Why Day 2 Became Harder in Cloud-Native Infrastructure
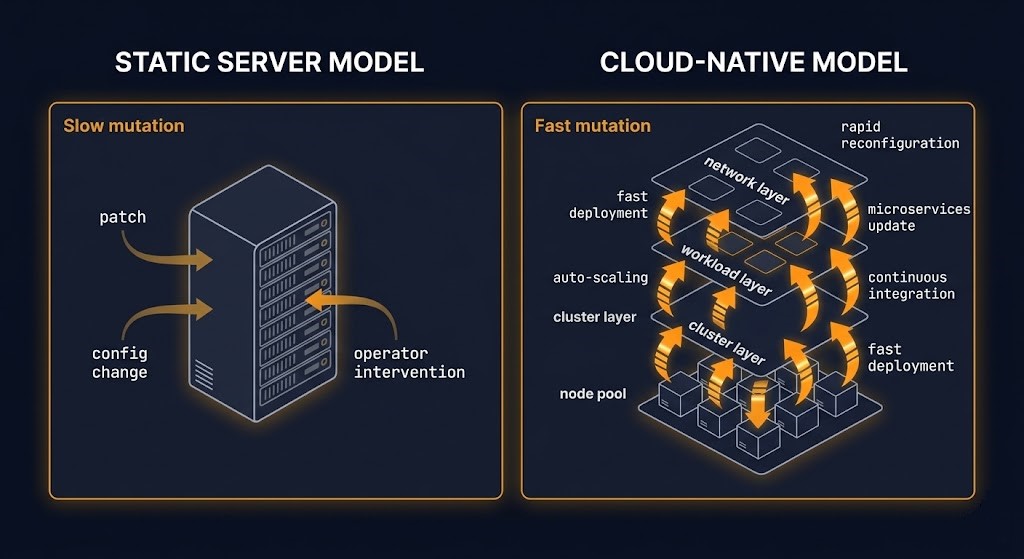
The conventional assumption when organizations adopt cloud-native architectures — Kubernetes, immutable images, autoscaling infrastructure, ephemeral workloads — is that Day 2 operational complexity decreases. Immutable images mean no in-place patching. Autoscaling means no manual capacity management. Container orchestration means no configuration drift on long-lived servers. The assumption follows naturally: if infrastructure is ephemeral and declaratively managed, day 2 operations architecture becomes a legacy concern.
That assumption is wrong, and understanding why it is wrong is prerequisite to understanding why day 2 operations architecture matters more in cloud-native environments, not less.
The static-server model had a simple Day 2 problem. A server provisioned in 2018 still exists in 2024. Over six years it accumulates patches, configuration changes, operator interventions, and runtime mutations. The challenge is managing that accumulation — detecting drift, enforcing compliance, rotating certificates, maintaining operational consistency across a fleet that changes slowly but constantly. Day 2 governance in this model is operationally intensive but architecturally simple: you have long-lived systems, you know where they are, and day 2 operations architecture can be modeled as a single coherent layer managed on a defined cadence.
The cloud-native model has a fragmented Day 2 problem. The infrastructure surface area did not shrink — it exploded across more layers and began changing faster than the static model ever did. Consider what Day 2 actually covers in a mature Kubernetes environment:
- Worker node OS layer — kernel parameters, kubelet configuration, containerd configuration, node-level certificates, OS patch cadence, security hardening profiles
- Kubernetes control plane — etcd backup cadence, API server configuration drift, scheduler policy changes, admission controller state
- Cluster-level configuration — RBAC policy drift, NetworkPolicy state, PodSecurityAdmission configuration, namespace-level resource quotas
- Application configuration — ConfigMap state, Secret rotation, Helm values drift, operator CRD configuration
- Infrastructure beneath the cluster — cloud provider node groups, load balancer configuration, storage class parameters, network policy at the VPC layer
Immutable images eliminated in-place application patching. They did not eliminate OS-level node management, control plane configuration governance, or the accumulation of runtime state at every layer above the image boundary. Autoscaling eliminated manual capacity decisions. It introduced node replacement at a rate that makes manual Day 2 operations on individual nodes impractical — which means automation is not optional but mandatory. Ephemeral workloads eliminated long-lived application servers. They concentrated the operational management burden at the node, cluster, and platform layers instead.
Day 2 operations did not disappear in cloud-native environments. They fragmented across more layers and began changing faster than any human-managed operational process can track. This is why day 2 operations architecture — a governed, automated, auditable model for the operational mutation layer — is the prerequisite capability for cloud-native infrastructure operated at enterprise scale.
The Day 2 Authority Model
The Day 2 Authority Model is the governance framework that defines where Ansible’s operational authority applies, what it governs within each domain, and what the failure mode looks like when that authority is absent. It is the structural core of day 2 operations architecture for Ansible-managed environments. It has four layers, each representing a distinct operational domain with its own trigger conditions, execution authority, and risk profile.
THE DAY 2 AUTHORITY MODEL — FOUR GOVERNANCE LAYERS
01 — CONFIGURATION AUTHORITY
Desired operational state of the running system — OS-level configuration, package state, service state, file permissions, sysctl parameters, kernel tuning. The domain Ansible was designed to own. Configuration Authority runs on a cadence and enforces that every managed system matches its declared configuration profile, regardless of what manual changes or package upgrades have accumulated since the last run.
02 — COMPLIANCE AUTHORITY
Enforced operational integrity — CIS benchmark profiles, security hardening standards, regulatory compliance baselines. Compliance Authority runs on a detection-and-remediation loop: scheduled scans surface drift from the compliance baseline, Ansible playbooks remediate detected violations. Unlike Configuration Authority (desired state), Compliance Authority operates against a defined security standard that the organization has committed to maintain. The failure mode is not misconfiguration — it is undetected baseline deviation that accumulates into audit failure or exploitable exposure.
03 — LIFECYCLE AUTHORITY
Certificate rotation, secrets injection, patch cadence management — the operational events that occur on a time-based schedule rather than a change-driven trigger. Lifecycle Authority is the most failure-prone Day 2 domain in practice because its events are predictable, automatable, and yet still managed manually in most organizations. Certificate expiry is known weeks in advance. Patch windows are calendar-driven. Secrets rotation schedules are policy-defined. The failure mode is not unpredictability — it is an operational model that relies on human memory and manual execution for events that automation handles more reliably at every scale above a handful of systems.
04 — MUTATION AUTHORITY
Controlled runtime change — the Day 2 layer that most infrastructure governance models never explicitly design for. Rolling restarts to activate configuration changes without downtime. Node drain and cordon sequencing for Kubernetes maintenance. Application parameter updates to running services. Runtime tuning adjustments under production load. Controlled failover testing. Incident remediation automation. Mutation Authority is distinct from Configuration Authority because it governs change events, not steady state. It is the operational layer where the consequences of failure are most immediate and most visible — a rolling restart sequenced incorrectly takes down a service.
The four-layer model maps against what Ansible actually executes in production environments. Configuration Authority and Compliance Authority run on scheduled cadences — daily, weekly, or on-demand during compliance review cycles. Lifecycle Authority runs on calendar triggers or expiry-detection signals. Mutation Authority runs on operational events — deployments, maintenance windows, incident response, and planned change events. The governance requirement is different for each layer, which is why a single “run Ansible on a schedule” approach is architecturally insufficient as a day 2 operations architecture. Each layer needs its own trigger model, its own approval and RBAC controls in AWX, and its own rollback posture. The Sovereign Drift Auditor tool surfaces existing drift state that pre-dates implementing any of these layers — a useful baseline scan before building the governance model.
| Layer | What Ansible Governs | Primary Trigger | Failure If Absent |
|---|---|---|---|
| Configuration Authority | OS state, package state, service state, kernel parameters | Scheduled cadence | Configuration decay — systems drift from declared profile silently |
| Compliance Authority | CIS baselines, hardening profiles, regulatory standards | Scheduled scan + deviation trigger | Undetected compliance drift — audit failure or exploitable exposure |
| Lifecycle Authority | Certificate rotation, secrets injection, patch cadence | Calendar / expiry signal | Manual rotation failures — TLS outages, expired credentials, unpatched CVEs |
| Mutation Authority | Rolling restarts, drain/cordon, runtime tuning, remediation | Operational event trigger | Uncontrolled change execution — service disruption, split-state environments |

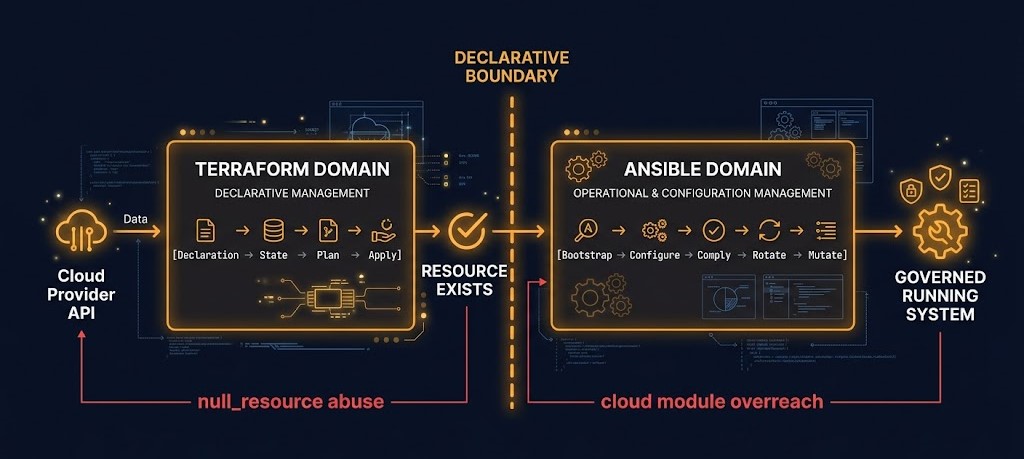
The Declarative Boundary — Where Terraform Ends and Ansible Begins
The Terraform & IaC Architecture sub-page introduced the IaC Control Plane Model and the Reconciliation Triangle — the three-node relationship between declared state, recorded state, and actual infrastructure that every IaC governance failure traces back to. The Declarative Boundary is the architectural complement to that model: the line at which Terraform’s declarative governance stops and Ansible’s day 2 operations architecture begins.
Terraform owns resource lifecycle at the provider API level: creating a Compute Engine VM, defining a Kubernetes node pool, provisioning an RDS instance, managing an S3 bucket’s access policy. These are API calls. Terraform’s governance model — declaration, state reconciliation, plan-time policy enforcement, pipeline-only execution — applies cleanly to API-level operations because the cloud provider API is stateless from Terraform’s perspective. You declare a resource. The provider either creates it or reports its current configuration. Terraform reconciles the difference.
Ansible owns the running system inside the resource Terraform created: the OS configuration of that VM, the kernel parameters of that Kubernetes node, the application configuration deployed to that instance, the certificate installed on that service endpoint. These are not API calls. They are changes to the runtime state of a live system that accumulates operational history independently of any provisioning tool. Terraform cannot read the contents of /etc/sysctl.conf. It cannot verify that a service is running with the correct configuration file. It cannot detect that an operator manually modified a package version during an incident two weeks ago. Ansible can.
The failure modes that occur when this boundary is collapsed — when teams try to use one tool for both domains — are predictable and expensive.
Terraform null_resource abuse is the most common collapse pattern on the Terraform side. The null_resource block allows arbitrary shell commands to be executed as part of a Terraform run. Teams use it to run configuration scripts, install packages, bootstrap services, and perform operations that belong in Ansible playbooks. The result is Terraform state that contains references to shell scripts whose effects are untracked, unidempotent, and invisible to the Reconciliation Triangle. The state file records that the null_resource executed. It records nothing about what the script actually did to the system, whether it succeeded completely, or whether subsequent runs would produce the same result.
Ansible cloud module overreach is the complementary failure on the Ansible side. Ansible has cloud provider modules — amazon.aws.ec2_instance, google.cloud.gcp_compute_instance, azure.azcollection.azure_rm_virtualmachine — that can create cloud resources directly. Teams that use these modules for provisioning are running infrastructure creation outside the IaC Control Plane Model: no state file, no policy-as-code enforcement, no signed plan artifact, no pipeline attribution. The resource exists in the cloud. It does not exist in Terraform state. It is invisible to the governance model and invisible to drift detection.
The “just use one tool” trap is the architectural position that produces both failure modes: the belief that either Terraform or Ansible can be extended to cover the full operational lifecycle. Neither can. The Declarative Boundary is real. Respecting it means accepting that a governed infrastructure estate requires both tools, operating in their respective domains, with an explicit governance model on each side of the line. The Infrastructure as a Software Asset post covers the mental model shift that makes this boundary intuitive rather than arbitrary.
| Dimension | Terraform | Ansible |
|---|---|---|
| Governance model | Declarative desired state | Idempotent operational convergence |
| Authority domain | Cloud provider API — resource lifecycle | Running system — configuration and operational state |
| State model | .tfstate — structured provider state | No persistent state — idempotency is the safety guarantee |
| Execution trigger | Pipeline-only apply on code change | Scheduled cadence, event trigger, or AWX job |
| Drift detection | terraform plan diff against state file | --check mode against running system |
| Failure if used outside domain | null_resource abuse — untracked mutations | Cloud module overreach — resources outside IaC governance |
| Handoff point | Resource provisioned and reachable | Post-provisioning bootstrap playbook executes |
Inventory Architecture and the Trust Boundary
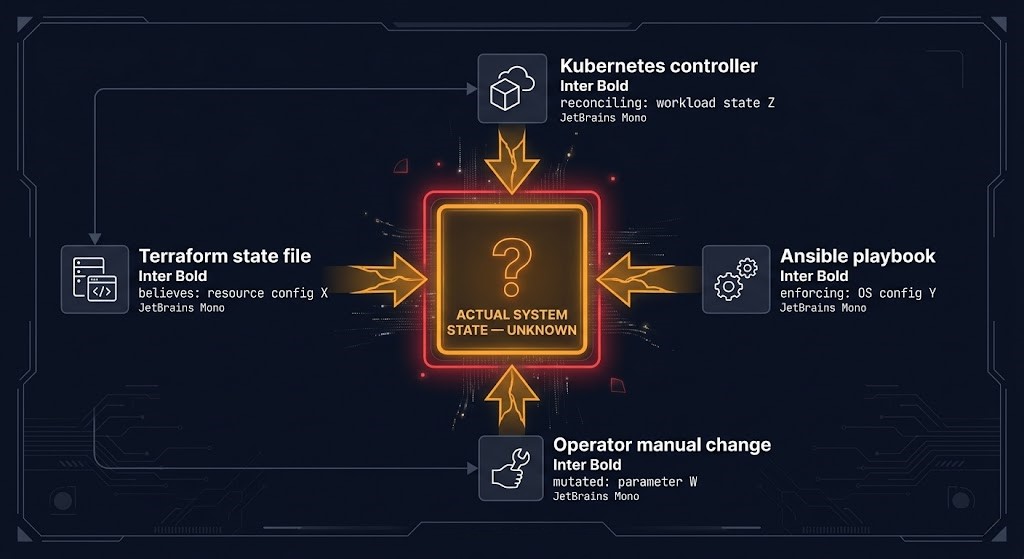
Ansible’s inventory is the authoritative list of systems that playbooks execute against. It is also one of the most underspecified components of most Ansible deployments — treated as an operational convenience rather than the architectural trust boundary it actually is.
Inventory is a trust boundary. The host or group a playbook targets determines its blast radius, its execution authority, and its privilege scope. A playbook that manages OS-level configuration with root privileges, executed against the wrong inventory group, is not a misconfiguration. It is a privilege escalation event — potentially touching production systems that were not intended targets, running operations that were designed for staging, or executing changes that have not been tested against the actual infrastructure profile of the targeted hosts. Inventory governance is a security architecture problem, not an operational convenience problem. This framing connects directly to the Shadow Control Plane argument — every uncontrolled execution path against ungoverned inventory is an undocumented state mutation.
Static inventory — a manually maintained hosts file or YAML inventory structure — is a governance failure at any scale above a handful of systems. It diverges from actual infrastructure state immediately after the first autoscaling event, node replacement, or cloud resource modification. By the time a team is running Ansible against a fleet with any meaningful change velocity, static inventory is incorrect, and incorrect inventory is a blast radius problem waiting for the next playbook run.
Dynamic inventory solves the staleness problem but introduces its own governance requirements. Dynamic inventory plugins query cloud provider APIs, Kubernetes node lists, or CMDBs at playbook execution time to build a current host list. This eliminates staleness. It introduces dependency on the API’s response accuracy, inventory caching behavior, and the group naming conventions that determine which hosts a given playbook targets. The governance requirements for dynamic inventory:
- Credential scope — the service account or API credential querying the inventory source must have minimum necessary permissions. An inventory credential with broad read access to cloud provider APIs is a credential that, if compromised, exposes the full infrastructure topology.
- Group naming conventions — host groups are the blast radius boundary. Group naming must be deterministic, environment-scoped (dev/staging/prod as explicit group hierarchy), and governed by the same review process as any other infrastructure configuration change.
- Caching policy — stale cached inventory runs playbooks against a host list that does not reflect current infrastructure state. Cache TTL must be sized against the environment’s change velocity. High-autoscaling environments need short cache TTLs or cache invalidation on scaling events.
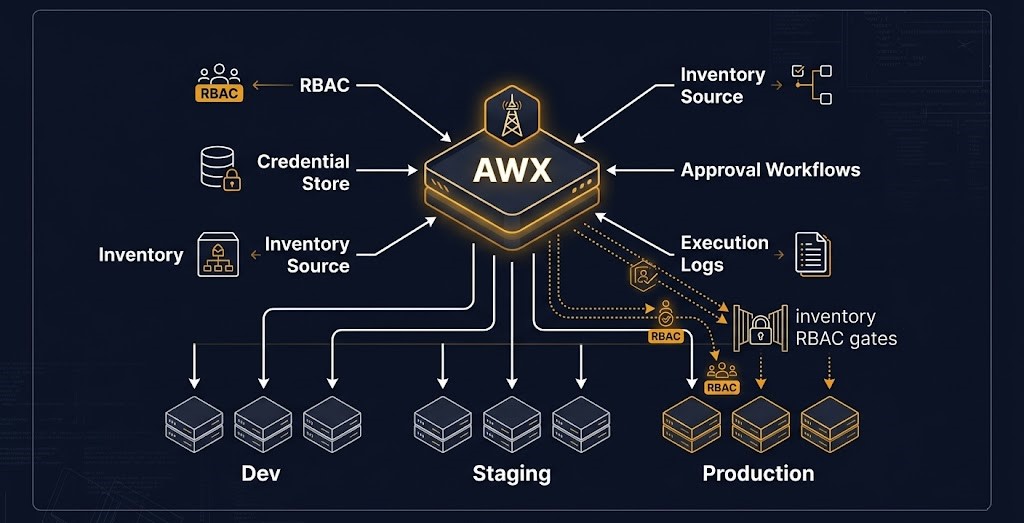
- AWX as the inventory governance layer — the correct day 2 operations architecture does not allow engineers to execute playbooks against dynamic inventory from their local terminals. AWX enforces that playbook execution happens against the inventory source it has access to, under the RBAC controls that determine which users can run which playbooks against which host groups.
AWX and Ansible Automation Platform — The Operational Control Plane
Ansible CLI is not an operational control plane. It is a local execution tool. An engineer running ansible-playbook from their terminal against a production inventory is the Day 2 equivalent of running terraform apply locally in production — ungoverned, unlogged, unattributed, and potentially unchecked against any policy. Without a control plane, day 2 operations architecture exists only on paper. The Pipeline Bypass failure mode in Terraform has an exact parallel in Ansible: playbook bypass, where a configuration change executes directly from a developer workstation without passing through any governance layer.
AWX is the open-source project that turns Ansible from a tooling system into an operational control plane. Ansible Automation Platform (AAP) is the Red Hat commercial product built on AWX. The architectural contribution of both is identical: they provide the governance layer that makes Ansible’s execution authority auditable, attributable, and RBAC-controlled.
What AWX provides that the CLI cannot:
Role-Based Access Control defines who is permitted to run which playbooks against which inventory. A developer may have permission to run application restart playbooks against their team’s services. They do not have permission to run OS hardening playbooks against production nodes. A compliance engineer has permission to run CIS benchmark remediation against all environments. They do not have permission to modify playbook definitions. RBAC at the playbook-execution layer is not a convenience — it is the mechanism that prevents Mutation Authority from being exercised by anyone with an SSH key and a terminal.
Execution authorization and approval workflows allow high-risk playbooks to require explicit approval before execution. A rolling restart across a production service cluster, a certificate rotation on a primary service endpoint, or a compliance remediation that modifies kernel parameters — all of these can be configured to require approval from a second operator before AWX executes the job. This is the Day 2 equivalent of the signed plan artifact in Terraform’s policy-as-code model.
Credential isolation keeps SSH keys, vault tokens, and service account credentials inside AWX’s credential store rather than distributed across developer workstations, environment variables, and CI/CD pipeline configurations. Credentials are injected into job execution at runtime without being exposed to the executing user. This eliminates the credential sprawl failure mode — covered in the Failure Modes section — where SSH keys and vault passwords distribute across the organization without a central revocation point.
Immutable execution logs record every playbook run: who triggered it, when, against which inventory, which playbook version, what changed on each host, what failed, and the full task-level output. This is the Day 2 audit trail — and in a mature day 2 operations architecture it is the evidentiary foundation for compliance reporting and incident forensics. In the absence of AWX, Ansible leaves no persistent record of what executed, what changed, and why. For compliance-regulated environments, the execution log is the evidence that the Compliance Authority layer operated correctly. For incident response, it is the first resource that tells you what changed on a system in the 48 hours preceding a failure — directly complementing the Kubernetes Day-2 diagnostic loops for node-level investigation.
Scheduled job management implements Lifecycle Authority cadences without requiring cron jobs, external schedulers, or manual operator initiation. Certificate rotation schedules, patch window automation, and compliance scan cadences run as AWX scheduled jobs — logged, monitored, and alertable on failure.
The decision between AWX (open source, self-hosted) and AAP (commercial, Red Hat supported) is not primarily a features decision. The feature sets are closely aligned. The decision is about support model and governance posture. AWX requires self-managed infrastructure, community support, and organizational responsibility for upgrades and availability. AAP provides enterprise support, predictable upgrade paths, and integration with Red Hat’s broader automation ecosystem. For organizations that have already evaluated the Terraform versus OpenTofu question on licensing grounds, AAP’s Red Hat commercial licensing is worth explicit evaluation — it is not open source in the same sense as AWX.
The Human Layer in Day 2 Operations
The Day 2 Authority Model describes the technical governance architecture for day 2 operations. What it does not describe — and what most configuration management guides systematically ignore — is the human failure mode that produces the most persistent and most expensive Day 2 governance problems in practice.
Day 2 operational failures are not primarily technical. They are organizational. The systems that degrade most severely under production pressure are not the ones with the weakest tooling. They are the ones where the operational authority model was never made explicit, and where human behavior in the absence of a governance model accumulated into architectural debt that no playbook can fully remediate.
Three named anti-patterns describe how human behavior becomes permanent infrastructure state:
“Emergency access becomes permanent architecture.” An incident occurs at 2am. An operator SSHs directly into a production node, modifies a configuration file, restarts a service, and resolves the incident. No playbook is updated. No documentation is written. The system is now running a configuration that exists nowhere in version control, is invisible to Ansible’s desired state model, and will be overwritten the next time a configuration authority playbook runs — potentially re-introducing the very condition that caused the incident. The emergency fix was correct. The absence of a model for capturing and formalizing it is the failure. Every unrecorded emergency change is a future incident waiting for the next configuration push. This anti-pattern is the human-layer manifestation of the Shadow Control Plane problem — undocumented state mutations that bypass every governance layer simultaneously.
“Every manual fix creates undocumented desired state.” Operators develop intuitions about how specific systems need to be configured to run correctly. Those intuitions are not written down. They are not captured in playbooks. They exist as tribal knowledge — the specific sysctl values that make a particular database node stable under load, the package version pinned because a newer version produced intermittent failures, the cron job added three years ago by an engineer who left the organization. When these systems are touched by automation that does not know about these manual adjustments, the result is configuration regression. The automation is executing correctly against its declared desired state. The declared desired state does not reflect the operational reality that the system has accumulated over years of manual management.
“The environment operators remember is not the environment automation sees.” This is the compound failure mode that results from the first two anti-patterns operating over time. Operators have a mental model of their infrastructure — which systems have which configurations, what was changed when, what the quirks of specific nodes are. Automation has a different model — what the playbooks declare, what the last successful run enforced, what the AWX execution log records. In environments without a governed Day 2 model, these two models diverge continuously. The most dangerous operational moments are when an operator makes a decision based on their mental model of the environment while automation is concurrently enforcing a different model — and neither the operator nor the automation knows the other is acting.
The governance response to all three anti-patterns is the same: formalize the operational memory layer. Emergency fixes must have a documented path to playbook update. Tribal knowledge must be captured in role variables, group variables, and host-specific overrides that are version-controlled and peer-reviewed. The execution log in AWX must be the authoritative record of what the automation model enforces — and deviations from it must surface as explicit governance decisions, not silent accumulation. Without this formalization, day 2 operations architecture exists as tooling without governance, and tooling without governance degrades faster than no tooling at all.
Failure Modes — Where Day 2 Governance Breaks
Day 2 governance failures follow predictable patterns. The seven below represent the failure modes observed most consistently across Ansible deployments at enterprise scale — each traceable to a specific gap in the Day 2 Authority Model. Understanding them is the fastest way to audit an existing day 2 operations architecture for where governance is absent or bypassed.
Ansible and Kubernetes — Day 2 at the Node Layer
Kubernetes already contains its own reconciliation engine. The control plane continuously reconciles desired workload state — declared in manifests, Helm values, and operator CRDs — against actual cluster state. Using Ansible to mutate Kubernetes-managed objects directly introduces a competing configuration authority with no deterministic conflict resolution model: Ansible enforces one desired state, the Kubernetes controller enforces another, and the system oscillates between them depending on which automation runs last. Understanding this is essential to any day 2 operations architecture that spans both Ansible and Kubernetes layers.
Ansible’s role in Kubernetes Day 2 is node-level, not workload-level. The boundary is precise:
- Ansible owns: Worker node OS configuration, kernel parameters for container networking (
net.ipv4.ip_forward,net.bridge.bridge-nf-call-iptables, and related), containerd daemon configuration, kubelet configuration parameters that require node-level file changes, node-level TLS certificate management, OS patch application and kernel upgrades, node drain/cordon sequencing for controlled maintenance, and security hardening profiles applied to the node OS. - Helm and Kustomize own: Application workload configuration, Kubernetes resource manifests, cluster-level RBAC, ConfigMap and Secret values for applications.
- Kubernetes operators own: Managed service lifecycle within the cluster — the PostgreSQL operator manages PostgreSQL configuration, the cert-manager operator manages certificate objects, the cluster autoscaler manages node pool scaling.
The node drain and cordon use case is where Ansible’s Mutation Authority integrates most directly with Kubernetes operations. A controlled node maintenance window — patching the OS, upgrading the container runtime, rotating node certificates — requires draining workloads before the maintenance operation and uncordoning the node after validation. Ansible orchestrates this as a coordinated sequence: cordon the node via the kubernetes.core.k8s_drain module, execute the maintenance operations, validate node readiness, uncordon. The Kubernetes API controls the workload scheduling layer throughout. Ansible controls the timing and sequencing of the maintenance event and the node-level changes. Neither tool is operating in the other’s domain.
For Day-2 Kubernetes operations at the cluster level — RBAC drift remediation, admission controller configuration, etcd backup verification — the Kubernetes Day-2 Operations guide covers the four diagnostic loops that surface the most common production failure patterns. The CI/CD control plane post establishes the pipeline authority model that governs how cluster-level changes reach production through the same governance discipline that applies to infrastructure changes.
When to Use Ansible vs When Not To
| Scenario | Ansible Fit | Rationale | Consider Instead |
|---|---|---|---|
| OS configuration management at scale | Strong | Idempotent modules, agentless execution, RBAC via AWX — the domain Ansible was built for | — |
| Cloud resource provisioning | Weak | No state file, no plan enforcement, no policy-as-code — resources exit IaC governance | Terraform / OpenTofu |
| Kubernetes workload deployment | Weak | Kubernetes has its own reconciliation engine — Ansible creates competing configuration authority | Helm, Kustomize, ArgoCD |
| Certificate rotation automation | Strong | Lifecycle Authority domain — handles detection, rotation, service reload, and validation as a coordinated sequence | — |
| Compliance remediation (CIS, STIG) | Strong | Compliance Authority domain — idempotent remediation runs that enforce baselines across heterogeneous fleets | — |
| Application deployment to VMs | Moderate | Valid for configuration deployment to long-lived VMs; less appropriate for containerized applications | Helm for K8s workloads |
| Network device configuration | Strong | Network modules (Cisco IOS, Arista EOS, Juniper Junos) — agentless model fits network device Day 2 | — |
| Secrets injection at runtime | Strong | Lifecycle Authority domain — Ansible + HashiCorp Vault or AWS SSM is a well-established pattern | — |
| Rapid prototyping | Weak | Playbook overhead not justified for one-time exploratory work | Direct SSH, cloud console |
| Kubernetes node maintenance | Strong | Mutation Authority domain — drain/cordon sequencing, node OS operations, kubelet cert rotation | — |
Day 0 vs Day 2. Ansible is architecturally weak at Day 0 provisioning — resource creation, dependency resolution, and lifecycle management at the cloud provider API level. It is architecturally strong at Day 2 — the operational convergence and mutation layer that follows. A mature day 2 operations architecture built on Ansible requires the teams that run it to resist the temptation to extend it into the Terraform domain, and instead invest in making it excellent within the Day 2 Authority Model it was designed to govern. The Enterprise Compute Logic sub-page covers the compute tier that Configuration and Mutation Authority primarily operate against.
The Day 2 Authority Model does not operate in isolation. The infrastructure it governs was provisioned by an IaC control plane, runs on compute and networking layers it must manage, and feeds into platform engineering models that depend on reliable Day 2 execution. The pages below cover each adjacent layer.
YOU’VE READ THE MODEL.
NOW VALIDATE WHETHER YOUR GOVERNANCE HOLDS.
Most infrastructure teams have Ansible. Far fewer have the Day 2 Authority Model wrapped around it — explicit authority boundaries, AWX as the operational control plane, governed Lifecycle Authority cadences, and a rollback posture for Mutation Authority operations. An Operational Governance Assessment maps your current Day 2 estate against the model and surfaces where the authority layers are absent, partial, or operating without governance visibility.
Operational Governance Assessment
A vendor-agnostic review of your Day 2 operations model against the Day 2 Authority Model — Configuration, Compliance, Lifecycle, and Mutation Authority coverage; AWX or AAP control plane posture; inventory trust boundary architecture; Declarative Boundary placement between Terraform and Ansible; and human-layer governance gaps. Whether you’re building the model from scratch or auditing an existing estate, the assessment surfaces where Day 2 governance holds and where it doesn’t.
- > Day 2 Authority Model coverage assessment
- > Declarative Boundary and Terraform/Ansible handoff review
- > AWX/AAP control plane and credential governance audit
- > Lifecycle Authority cadences and rotation pipeline validation
Architecture Playbooks. Field-Tested Blueprints.
Field-tested Day 2 governance blueprints — certificate rotation pipeline failures, AWX RBAC architecture patterns, inventory blast radius incidents, and the Mutation Authority scenarios that reveal whether your operational control plane actually holds under production pressure.
- > Day 2 governance and Ansible architecture patterns
- > AWX operational control plane design
- > Certificate rotation and Lifecycle Authority failures
- > Split authority drift and remediation case studies
Zero spam. Unsubscribe anytime.
Architect’s Verdict
Ansible is not a provisioning tool. It is not a Terraform competitor. It is not an alternative to Kubernetes-native configuration management. It is the Day 2 authority layer — the operational governance model for the runtime lifespan of infrastructure that provisioning tools create and platform layers consume. Day 2 operations architecture is not a Ansible feature set. It is the governance model you build around the tool: explicit authority boundaries, an operational control plane, governed Lifecycle Authority cadences, and a rollback posture for every Mutation Authority operation. The teams that operate reliably at scale are not the ones that chose Ansible over some other configuration management tool. They are the ones that defined the Declarative Boundary explicitly, built a governance model on each side of it, and treated day 2 operations as a first-class architectural concern rather than a gap between provisioning and incident response.
The Day 2 Authority Model — Configuration, Compliance, Lifecycle, and Mutation Authority — is not a theoretical framework. It is the operational reality of every production infrastructure estate, whether governed or not. In environments without an explicit day 2 operations architecture, all four layers still exist. They are just ungoverned: configuration decays without remediation, compliance drift accumulates without detection, certificates expire because no one automated the rotation, and runtime mutations execute without rollback posture. The question is not whether Day 2 operations happen. It is whether they happen with governance or without it.
The human layer is where most Day 2 governance fails in practice. The emergency fix that never made it into version control. The tribal knowledge that exists only in the mental model of operators who may not be available when it matters. The environment that automation sees, which is fundamentally different from the environment operators believe they are managing. AWX addresses the tooling side of this problem. Capturing operational memory in version-controlled playbooks, group variables, and execution logs addresses the organizational side. Both are required.
The Declarative Boundary makes the governance model complete. Terraform owns declared resource state at the provider API level. Ansible owns operational convergence authority for the running systems those resources contain. Kubernetes owns workload reconciliation at the cluster and namespace layer. Each tool governs its domain. None of them governs the others. Where the boundaries are explicit and enforced, the tooling stack is deterministic. Where they collapse — through null_resource abuse, Ansible cloud module overreach, or Kubernetes manifest mutations via Ansible — the result is Split Authority Drift: multiple tools competing for operational authority over the same systems, with no mechanism to resolve the conflict.
The infrastructure that degrades silently is not the infrastructure with the least automation. It is the infrastructure where automation operates without explicit authority boundaries — where every tool can touch everything, where no tool is clearly responsible for anything, and where the question “what state is this system actually in right now?” has no authoritative answer.
Frequently Asked Questions
Q1: What is the difference between Ansible and Terraform for infrastructure management?
A: Terraform governs infrastructure resource lifecycle at the cloud provider API level — declaring desired state, reconciling it against a state file, and enforcing it through a policy-checked pipeline. Ansible governs the operational state of running systems after Terraform provisions them — OS configuration, package state, certificate rotation, compliance enforcement, and controlled runtime mutation. The Declarative Boundary is the architectural line separating their domains: Terraform operates on the declarative provisioning side, Ansible operates on the operational convergence side. Using Terraform for OS-level configuration or Ansible for cloud resource provisioning collapses that boundary and produces governance failures in both tools.
Q2: When should I use Ansible versus Helm for Kubernetes configuration?
A: Ansible owns the Kubernetes worker node OS layer — kernel parameters, containerd configuration, kubelet settings, node-level certificate management, OS patch application, and node drain/cordon sequencing for maintenance operations. Helm owns application workload configuration — Kubernetes resource manifests, Helm chart values, application-layer ConfigMaps and Secrets. Kubernetes operators own managed service lifecycle within the cluster. Using Ansible to deploy Kubernetes manifests or modify Kubernetes API objects directly introduces a competing configuration authority against the Kubernetes reconciliation engine, producing oscillation between the two desired states depending on which automation runs last.
Q3: Do I need AWX or Ansible Automation Platform, or is the Ansible CLI sufficient?
A: For development environments and small-scale operations, the CLI is sufficient. For any production environment where governance matters — and governance matters in every production environment — AWX or AAP provides what the CLI cannot: RBAC over who can run which playbooks against which inventory, execution logs that constitute an audit trail, credential isolation that keeps SSH keys and vault tokens off developer workstations, scheduled job management for Lifecycle Authority cadences, and approval workflows for high-risk Mutation Authority operations. The CLI in production is the Day 2 equivalent of running terraform apply from a local terminal — ungoverned execution that bypasses every control the authority model is designed to enforce.
Q4: How do I prevent Ansible playbooks from affecting the wrong hosts?
A: Inventory governance is the primary control. Explicit environment scoping in inventory group hierarchies — with dev, staging, and production as separate group namespaces that cannot overlap — prevents playbooks designed for one environment from executing against another. AWX RBAC enforces that production inventory is only accessible to production-authorized playbooks and users, removing the ability to target the wrong environment from a developer terminal. Pre-execution inventory validation in AWX job templates can verify the resolved host list before any tasks execute. The underlying principle: inventory is a trust boundary, and blast radius is an inventory design decision made before the first playbook runs.
Q5: What is idempotency and why does it matter for Day 2 operations?
A: Idempotency is the property that running the same operation multiple times produces the same result as running it once, provided the system is already in the desired state. For Day 2 operations executed on a cadence — configuration enforcement runs, compliance remediation scans, patch management playbooks — idempotency is the safety guarantee that makes automation safe to run repeatedly without human review of each execution. A non-idempotent playbook that restarts a service regardless of whether the configuration changed, or that applies a patch that was already applied, produces unnecessary disruption on every run. Ansible’s module library is designed around idempotency — modules check current state before acting. The failure mode is when teams use shell or command tasks in place of idempotent modules, bypassing the safety guarantee the tool provides.
Q6: How does Ansible integrate with HashiCorp Vault or AWS SSM for secrets management?
A: Ansible’s hashi_vault lookup plugin and the community.hashi_vault collection provide native integration with HashiCorp Vault — playbooks can retrieve secrets at execution time without storing them in inventory variables or playbook files. AWS SSM Parameter Store integration uses the amazon.aws.ssm_parameter module and AWS credential injection via AWX’s credential store. The correct architecture in both cases keeps secrets out of playbook repositories entirely: no vault passwords in group_vars, no API tokens in inventory files, no credentials in AWX job template environment variables that are visible to users. Credentials are injected at runtime through AWX’s credential store, retrieved from Vault or SSM during playbook execution, and never persisted in any form that outlives the job run.
Q7: What is the correct Ansible architecture for certificate rotation at scale?
A: A certificate rotation playbook must execute as a coordinated sequence with four mandatory phases: detection (verify the certificate is within the rotation window, not just scheduled blindly), rotation (retrieve the new certificate from the CA or secret store, write it to the correct path), reload (trigger a service handler that reloads the service to present the new certificate — not a separate task, a handler that fires only if the certificate file changed), and validation (connect to the service endpoint and verify it is presenting the new certificate, not the expired one). Post-rotation validation is the step that most rotation pipelines omit, and its absence is the direct cause of the silent rotation failure mode — the certificate is renewed, the service is never reloaded, and the outage occurs weeks later when the old certificate the service is still presenting finally expires. At scale, the entire sequence runs as an AWX workflow job with failure alerting at each phase and automatic rollback if validation fails.