AWS CLOUD ARCHITECTURE
The Planet-Scale Control Plane. Service Depth Over Simplicity.
AWS cloud architecture operates as a programmable control plane at planetary scale — abstracting compute, storage, networking, and identity into a globally distributed API fabric.
That distinction matters architecturally. Organizations that treat AWS as “infrastructure in someone else’s building” consistently underperform on cost, security, and resilience. They over-provision EC2 instances the way they sized physical servers. They treat VPCs like VLANs. They run IAM like Active Directory. The mental model carries forward, and the mental model is wrong.
AWS rewards architects who engage with its actual design: a service composition model where the control plane handles the operational overhead of infrastructure at scale, and you handle the architectural decisions that determine how that infrastructure behaves under load, under attack, and under budget pressure. The depth of the AWS service catalogue — over 200 services across compute, storage, networking, databases, AI, and security — is not a feature list. It is a set of building blocks. Knowing which ones to use, in which combination, for which workload class is the actual skill.
This Amazon AWS cloud strategy architecture guide covers exactly that decision — how the AWS control plane works, where the shared responsibility boundary sits, how hybrid connectivity is built deterministically, and where AWS is the right answer versus where the economics point elsewhere.
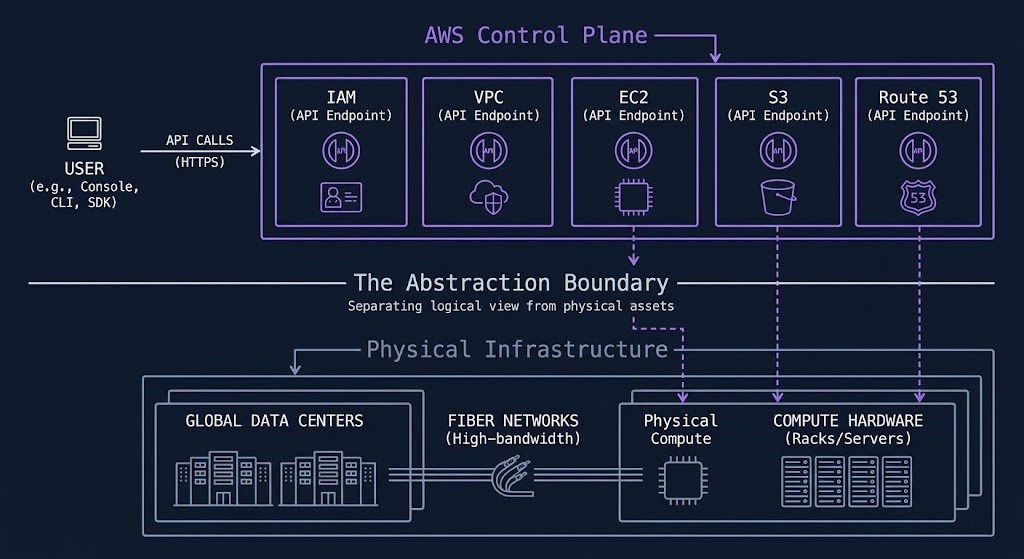
What AWS Cloud Architecture Actually Is
The distinction between a control plane and an infrastructure provider is not semantic — it changes how you architect.
A traditional infrastructure provider gives you hardware. You manage capacity, redundancy, and lifecycle. AWS inverts that model. The physical layer — servers, networking hardware, power, cooling, physical security — is AWS’s operational problem. What you manage is the logical layer: how services are configured, how identity is governed, how traffic flows, how data is classified and protected.
Every resource on AWS is an API endpoint. An EC2 instance is not a server — it is an API call that returns compute capacity. An S3 bucket is not a file system — it is an API-addressable object store with configurable durability, access policy, and lifecycle rules. An IAM role is not a user account — it is a programmable identity that can be assumed by any service, human, or machine with the right policy attached.
This design means that AWS environments are defined by their configuration decisions, not their hardware decisions. A misconfigured IAM policy is not a hardware failure — it is a policy failure. An S3 bucket exposed to the public internet is not a platform vulnerability — it is an access control decision that was made wrong. Most AWS security incidents trace back to this layer, not to AWS’s physical infrastructure.
The architectural implication: designing for AWS requires the same rigor applied to policy, identity, and configuration that traditional infrastructure architects apply to hardware selection and physical topology. The blast radius of a wrong decision is wider — and propagates faster.
AWS Global Architecture
AWS operates 33 geographic Regions globally, each containing a minimum of three physically separate Availability Zones. The Regions are independent failure domains — a full Region outage does not propagate to another Region. The AZs within a Region are connected by low-latency, high-bandwidth private fiber links, but they are housed in separate physical facilities, on separate power grids, with independent flood zones and physical security perimeters.
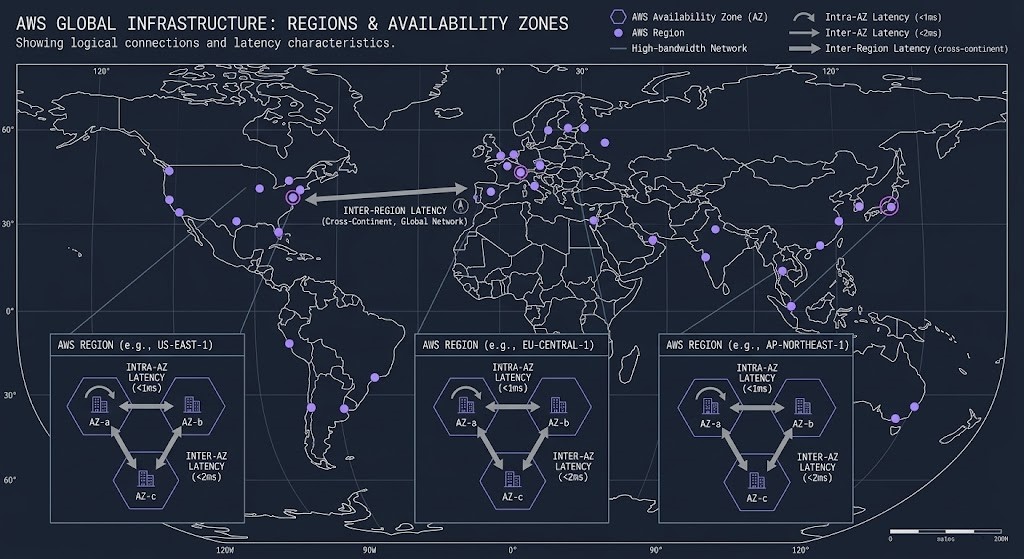
The AZ model has a specific architectural consequence that most teams underestimate until their first cross-AZ bill arrives: traffic between AZs within the same Region is not free. AWS charges for cross-AZ data transfer at $0.01/GB in each direction. For microservice architectures with high inter-service call volumes, or databases with synchronous cross-AZ replication, that cost is not negligible. The architecture decision of which services go in which AZ is both a resilience decision and a cost decision.
The 33 Regions are not interchangeable. Regulatory requirements constrain Region selection for data sovereignty workloads. Latency physics constrain Region selection for latency-sensitive applications. Service availability varies by Region — not every AWS service is available in every Region, and newer services often launch in us-east-1 first with a multi-month lag before broader availability. Designing a multi-Region architecture requires mapping your service dependencies against what is actually available where you intend to run.
Local Zones extend AWS infrastructure to metropolitan areas outside the standard Region footprint, providing single-digit millisecond latency to end users in those locations. Wavelength Zones extend AWS compute to the edge of carrier 5G networks. These are not general-purpose infrastructure — they are purpose-built for specific latency profiles. If your use case doesn’t require sub-10ms latency at the edge, the standard Region/AZ model is the right architecture.
The AWS Architecture Stack
Before examining individual services, the four-layer model that organizes the Amazon AWS cloud strategy architecture is worth establishing explicitly. Every AWS environment operates across these layers, and the decisions made at each layer constrain what’s possible at the layers above.
The layers are interdependent. An identity decision — which IAM role has which permissions — determines what the compute layer can do with the data layer. A network decision — whether a subnet is public or private — determines how the compute layer is reachable. A data decision — which Region stores the primary copy — determines the latency physics for the compute layer accessing it.
Architects who treat these layers as independent configuration choices rather than interdependent system decisions build environments that are technically functional but operationally brittle.
Core Building Blocks
The AWS service catalogue exceeds 200 services. Most production environments run on a much smaller set of primitives. These are the five that every AWS architecture rests on.
IAM — Identity as the Primary Firewall
AWS Identity and Access Management is not an authentication system bolted onto the side of AWS. It is the central authorization layer for every API call in the platform. Every action — launching an EC2 instance, reading an S3 object, creating a VPC subnet — is an IAM authorization decision. If the policy says no, the action is denied regardless of network position.
The architectural implication is significant: a correctly configured IAM layer reduces the blast radius of a network compromise to near zero. An attacker who penetrates a VPC but carries no valid IAM credentials cannot read data, cannot launch instances, cannot modify infrastructure. IAM is not a best practice in AWS environments. It is the structural security mechanism.
Most AWS breaches do not involve compromised AWS infrastructure. They involve overpermissioned IAM roles, publicly accessible S3 bucket policies, or leaked credentials. The identity perimeter is where the actual risk lives — not the network perimeter. For the governance automation that enforces IAM policy at scale, see the Zero Trust & Governance section below.
VPC — Network Isolation as Architectural Primitive
A Virtual Private Cloud is a logically isolated network environment within the AWS fabric. Unlike a VLAN, a VPC has its own routing table, its own Internet Gateway (or not), its own NAT configuration, and its own DNS resolution. VPCs do not share routing by default — two VPCs in the same account cannot communicate without explicit peering or Transit Gateway attachment.
VPC design is one of the most consequential early architectural decisions in an AWS environment. The CIDR block chosen at creation cannot be changed. The subnet topology determines which resources can reach each other. Security Groups — stateful, instance-level firewall rules — enforce east-west traffic control within the VPC. Network ACLs provide stateless subnet-level controls.
The most common VPC architectural mistake is undersizing CIDR blocks at account creation, creating IP exhaustion problems as the environment grows. The second most common is not establishing VPC peering or Transit Gateway topology before deploying multi-account environments — retrofitting network topology into a running environment is significantly more disruptive than designing it correctly at the start.
EC2 — Compute Abstraction, Not Virtual Servers
EC2 instances are compute capacity on demand. The mental model of EC2 as a “virtual server” is technically accurate but architecturally misleading. A virtual server implies persistent state, manual management, and fixed capacity. EC2 at architectural scale implies ephemeral capacity, Auto Scaling groups, launch templates, and instance lifecycle automation.
The Nitro System — AWS’s custom hypervisor stack — underpins all modern EC2 instance types and provides near-bare-metal performance by offloading networking, storage I/O, and security functions to dedicated hardware. For performance-sensitive workloads, understanding the Nitro architecture matters: Nitro instances provide hardware-enforced isolation between customer workloads and the hypervisor, minimizing the traditional hypervisor attack surface by offloading virtualization functions to dedicated hardware.
Graviton processors — AWS’s ARM-based custom silicon — now power the majority of AWS’s performance-per-dollar compute offerings. Graviton4-based instances deliver up to ~40% better price-performance depending on workload type. For new deployments without hard x86 dependencies, the default compute choice should be Graviton, not Intel. The Lambda GenAI architecture case study at Rack2Cloud — AWS Lambda for GenAI: The Definitive Architecture Guide — demonstrates the Graviton performance advantage on inference workloads specifically.
S3 — Object Storage as Architectural Backbone
S3 is the foundational storage primitive for AWS architectures. 11 nines durability is achieved through cross-facility replication within a region, no capacity ceiling, configurable storage tiers from Standard to Glacier Deep Archive, and an access control model that can be as open as a public website or as locked as a private encryption vault.
The architectural trap with S3 is treating it as a simple file store. S3 is a cost-variable storage fabric — every request has a cost, every byte transferred out of S3 has a cost, and the choice of storage class determines retrieval time, retrieval cost, and storage cost simultaneously. An architecture that puts the wrong data class in the wrong S3 tier, or that makes high-frequency API calls to a cold archive tier, generates costs that are invisible until the monthly bill arrives.
S3 Intelligent-Tiering automates storage class transitions based on access patterns — a genuine cost control mechanism for datasets with unpredictable access. For workloads with predictable access patterns, explicit lifecycle policies that move objects to Glacier or Deep Archive after defined aging windows consistently outperform manual cost management.
Route 53 — DNS as Infrastructure
Route 53 is AWS’s authoritative DNS service and the entry point for global traffic routing. Health-check-based failover, geolocation routing, latency-based routing, and weighted routing policies make Route 53 a traffic management layer, not just a name resolution service. Multi-Region architectures that require automatic failover depend on Route 53 health checks detecting endpoint failure and rerouting traffic without manual intervention. DNS TTL strategy — how long resolvers cache records before re-querying — directly affects failover speed and must be part of the resilience design, not an afterthought.
Shared Responsibility Model
The AWS Shared Responsibility Model divides security obligations into two domains: what AWS secures, and what you secure.
AWS is responsible for the security of the cloud: the physical data center infrastructure, the hardware lifecycle, the hypervisor layer, the network fabric connecting AWS facilities, and the managed service software stack for services like RDS, DynamoDB, and Lambda. AWS does not give customers access to this layer because customers do not need to — and should not — manage it.
Customers are responsible for security in the cloud: guest OS patching on EC2 instances, application-level security, data encryption at rest and in transit, network traffic filtering via Security Groups and NACLs, and — critically — identity and access management configuration. This is where the vast majority of AWS security incidents originate.
- Physical data center intrusion
- Hypervisor layer vulnerability
- Hardware supply chain compromise
- AWS network fabric failure
- Managed service platform vulnerability
- Overpermissioned IAM roles
- Public S3 bucket misconfiguration
- Leaked access keys in source code
- Unpatched EC2 guest OS
- Missing encryption on sensitive data
The practical consequence of this model is that the security posture of an AWS environment is entirely within the customer’s control. AWS cannot prevent a misconfigured S3 bucket from being public. AWS cannot prevent an overpermissioned IAM role from being exploited. The platform provides the controls — bucket policies, IAM policy simulators, AWS Config rules, Security Hub findings — but applying them is the customer’s operational responsibility.
For regulated workloads, the shared responsibility model has additional implications. Compliance frameworks (SOC 2, HIPAA, PCI-DSS) require documented evidence of both layers of control. AWS provides compliance documentation for its own layer via AWS Artifact. Customer-layer compliance — encryption configuration, access logging, vulnerability management — requires customer documentation and automation.
Hybrid Connectivity
Most enterprise AWS deployments are not greenfield cloud-only environments. They are hybrid architectures — AWS workloads that need to communicate with on-premises systems, existing data centres, or other cloud environments. AWS provides three deterministic connectivity models for hybrid integration, each with distinct latency, cost, and operational profiles.
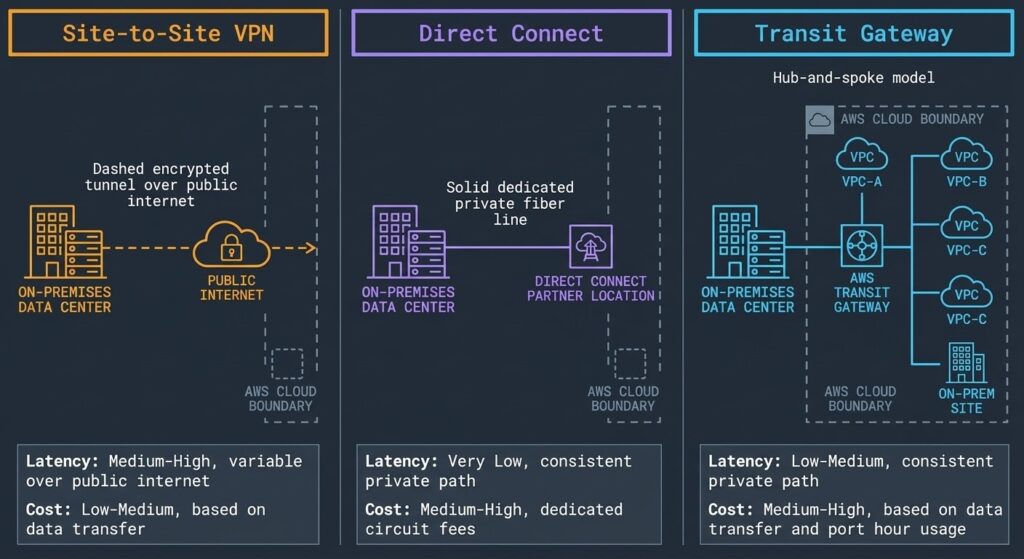
| Model | Latency Profile | Bandwidth | Use Case | Cost Model |
|---|---|---|---|---|
| Site-to-Site VPN | Variable — public internet path | Up to 1.25 Gbps per tunnel | DR standby, low-volume hybrid, backup Direct Connect path | Low — hourly connection + data transfer |
| Direct Connect | Deterministic — dedicated private fiber | 1 Gbps to 100 Gbps | Production hybrid, high-throughput data transfer, latency-sensitive workloads | High — port fee + data transfer, long provisioning lead time |
| Transit Gateway | Low — AWS backbone routing | Up to ~50 Gbps per VPC attachment depending on architecture | Multi-VPC, multi-account, hub-and-spoke enterprise networking | Medium — attachment fee + data processing charge |
Site-to-Site VPN is the fastest hybrid connectivity to provision — hours, not weeks — and carries no dedicated infrastructure requirement. It uses IPsec tunnels over the public internet, which means latency is non-deterministic and bandwidth is capped. For production workloads with consistent high-throughput requirements, VPN is not the right primary path. It is the right standby path for Direct Connect failover.
Direct Connect provides a dedicated private fiber connection between an on-premises environment and an AWS Direct Connect location. The public internet is not in the data path. Latency is deterministic. Bandwidth options range from 1 Gbps to 100 Gbps. The trade-off is lead time — provisioning a Direct Connect circuit takes weeks to months depending on the colocation facility — and cost. Direct Connect makes economic sense when the combination of deterministic latency requirements and data transfer volume exceeds the crossover point versus VPN or public internet. For the full egress cost model, the Cloud Repatriation Calculus covers the data transfer cost analysis that should precede any connectivity architecture decision.
Transit Gateway is the routing hub for complex multi-VPC and multi-account environments. Rather than building a full mesh of VPC peering connections — which becomes operationally unmanageable beyond 10–15 VPCs — Transit Gateway acts as a central hub that all VPCs and on-premises connections attach to. A single Transit Gateway can support thousands of VPC attachments and route between them via centrally managed route tables. For enterprise-scale AWS environments with multiple accounts, multiple VPCs, and on-premises connectivity, Transit Gateway is not optional — it is the architecture. The AWS Control Tower vs Azure Landing Zone comparison at Rack2Cloud — AWS Control Tower vs Azure Landing Zone — covers how Transit Gateway fits into multi-account landing zone architecture in detail.
Identity federation is the other pillar of hybrid architecture that most connectivity guides underemphasize. If AWS IAM and on-premises identity (Active Directory, Okta, Azure AD) are not federated through SAML 2.0 or OIDC, you end up with two separate identity systems that drift over time. Federated IAM means that the same identity governance that applies on-premises applies in AWS — roles, groups, and access policies are consistent across both environments without duplicating the identity store.
Cost Physics
AWS cost is not a billing problem. It is an architecture problem.
The monthly invoice is the output of architectural decisions made weeks or months earlier — instance type selection, storage tier choices, data replication strategy, cross-AZ and cross-Region traffic patterns. By the time the bill arrives, most of the cost is locked in. FinOps teams that focus on post-deployment optimization are working at the wrong point in the cycle. The FinOps Architecture: Why Cloud Cost Is Now a Design Constraint post covers the shift-left approach to cost governance that changes when cost enters the design decision.
Compute Economics
EC2 pricing operates across three purchasing models that most environments use in combination. On-Demand pricing — pay by the second for what you run — carries a significant premium over committed capacity. Reserved Instances commit to one or three years of capacity in exchange for discounts of 30–60% over On-Demand. Spot Instances use spare AWS capacity at discounts of 70–90% over On-Demand, with the trade-off that AWS can reclaim capacity with a two-minute warning.
The architectural rule: steady-state workloads that run 24/7 should be Reserved. Batch workloads that are fault-tolerant and stateless should be Spot. Variable workloads that scale with demand but must always be available should use a blend of Reserved baseline plus On-Demand or Spot for burst.
Graviton processors deliver approximately 40% better price-performance than equivalent x86 instances for most workload types. For new deployments, the default compute selection should be Graviton unless there is a specific x86 binary dependency.
Egress Economics
Data transfer out of AWS is metered — per gigabyte, every time, with no volume discount that eliminates the structural cost at scale. The egress model has three tiers: data transfer between AZs within a Region ($0.01/GB each direction), data transfer between Regions (varies by Region pair, typically $0.02–$0.08/GB), and data transfer to the public internet ($0.09/GB for the first 10 TB/month in most Regions).
Architectures that create unnecessary data movement — microservices in different AZs chattering frequently, databases replicating synchronously across Regions, reporting pipelines pulling data from cloud storage to on-premises analytics tools — generate egress costs that compound with scale. The Shim Tax analysis documents exactly how these hidden costs compound in hybrid architectures. The 2026 IPv4 and Egress Tax post covers the specific cost increases that hit cross-AZ architectures in 2026.
VPC PrivateLink keeps traffic between AWS services on the AWS backbone rather than routing it through public internet paths. S3 Gateway Endpoints eliminate data transfer charges for traffic between EC2 instances and S3 within the same Region. These are not optional optimizations for cost-conscious environments — they are correct architectural defaults.
Data Gravity & Service Coupling
Data gravity is the architectural force that makes compute migrate toward data rather than the other way around. The larger a dataset becomes, the more expensive and slower it is to move — and the more services accumulate around it, the more tightly coupled those services become to the location of the data.
On AWS, data gravity creates architectural lock-in that is more durable than any contractual obligation. A petabyte-scale dataset in S3 is functionally immovable within a planning cycle — not because of licensing, but because of physics. Egress charges at that scale are significant, transfer time is measured in weeks, and every service that has built access patterns against that dataset’s location must be re-pointed or rebuilt.
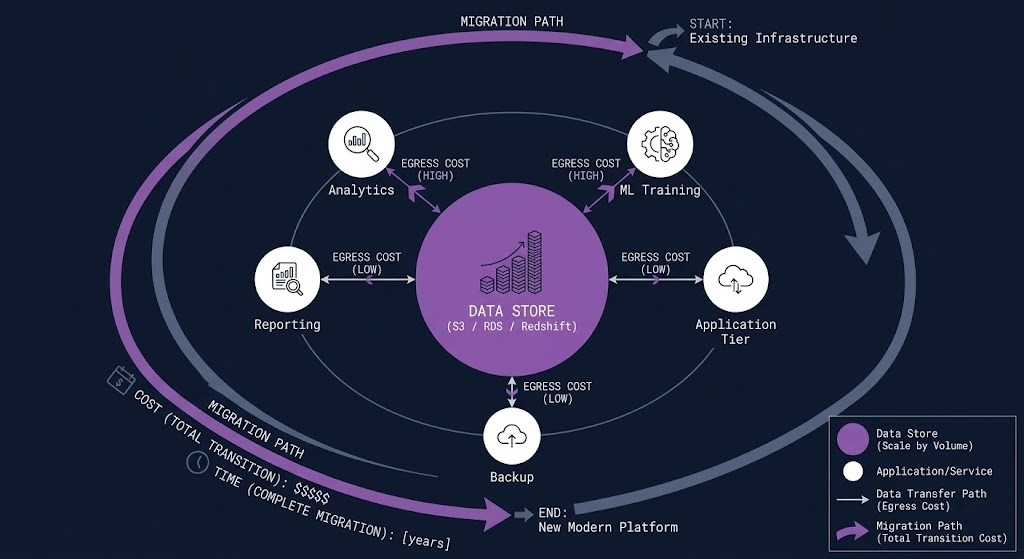
The service coupling dimension of data gravity is less discussed but equally important. AWS services are designed to integrate with each other — S3 feeds Athena, Athena queries feed QuickSight dashboards, QuickSight dashboards pull from Redshift, Redshift loads from S3. Each integration is efficient and cost-effective within AWS. Each integration is also a coupling point that makes the dataset harder to move without rebuilding the services that depend on it.
This is not a criticism of AWS’s integration model — it is an accurate description of the architectural consequence. The decision to land a dataset in AWS is often the decision to run the workloads that depend on it in AWS for the foreseeable future. Architects who understand this make the placement decision deliberately, with the full cost model in view. Architects who don’t understand it discover it when the repatriation calculation arrives.
For workloads where data sovereignty requirements, egress economics, or AI infrastructure costs make cloud placement untenable at scale, the Cloud Repatriation Calculus provides the break-even model.
Zero Trust & Governance
Zero Trust architecture on AWS is not a product. It is a set of design principles applied consistently across the identity, network, and data layers.
Organizations and Service Control Policies form the governance foundation for multi-account AWS environments. AWS Organizations groups accounts into Organizational Units (OUs), and Service Control Policies attached to OUs define the maximum permissions available in those accounts — guardrails that even account-level IAM administrators cannot override. An SCP that prevents any IAM action from creating public S3 buckets applies to every account in the OU, regardless of what individual IAM administrators do. This is preventative governance at scale, not detective governance after the fact.
AWS CloudTrail provides an immutable audit log of every API call made in every account. Every IAM action, every EC2 state change, every S3 object access — logged, timestamped, and shipped to S3 for long-term retention. CloudTrail is the forensic foundation for incident response, compliance auditing, and operational anomaly detection. Environments without CloudTrail enabled in all Regions are flying blind.
VPC PrivateLink eliminates the public internet from the traffic path between services. Instead of routing traffic from a VPC to an AWS service (S3, DynamoDB, API Gateway) through an Internet Gateway, PrivateLink routes traffic through the AWS backbone via a private endpoint in the VPC. For regulated workloads where data must not traverse the public internet, PrivateLink is not optional.
AWS KMS provides customer-managed encryption key management. The distinction between AWS-managed keys and customer-managed keys matters in regulated environments: with AWS-managed keys, AWS controls the key lifecycle. With customer-managed KMS keys, the customer controls key rotation, key deletion, and key policy. For workloads with strict data sovereignty or regulatory requirements, customer-managed KMS keys are the correct default.
AWS Config and Security Hub provide continuous compliance monitoring — Config rules evaluate resource configurations against defined policies and flag drift in real time. Security Hub aggregates findings from GuardDuty, Inspector, Macie, and Config into a single security posture view. Together they provide the detective controls layer that SCP guardrails cannot cover.
The governance architecture for multi-account AWS environments — how Control Tower, Organizations, and Landing Zone accelerators fit together — is covered in detail in the AWS Control Tower vs Azure Landing Zone analysis.
Compute Decision Tree
The most consistent source of AWS overspend and operational debt is defaulting to EC2 for workloads that are better served by a different compute abstraction. The compute decision is not a preference — it is an architectural choice with cost, operational, and scaling consequences.
| Workload Type | Right Abstraction | Why | Avoid |
|---|---|---|---|
| Legacy apps, full OS control | EC2 | Requires specific kernel, OS config, or third-party agent that doesn’t containerize cleanly | Over-provisioned instance families; always evaluate Graviton first |
| Microservices, containers | EKS / ECS | Orchestrated scaling, portability, and service mesh capabilities not available on bare EC2 | Self-managed Kubernetes on EC2 unless team has deep K8s operational capability |
| Event-driven, short execution | Lambda | Zero infrastructure management, sub-second billing, automatic scaling to zero | Long-running processes, GPU workloads, or anything requiring persistent connection state |
| Containers without EC2 management | Fargate | Container execution without node pool management — reduced attack surface, no OS patching | High-throughput, cost-sensitive workloads — Fargate carries a premium over EC2-backed EKS |
| Large-scale batch, HPC | AWS Batch + Spot | Managed job queuing with Spot integration — significant cost reduction for fault-tolerant jobs | On-Demand for batch — stateless batch jobs are the ideal Spot workload class |
| AI inference (small models) | Lambda + Graviton | SLM inference on Graviton5 with Lambda Durable Functions — no idle GPU cost, sub-500ms cold start achievable | GPU instances for inference workloads that don’t require GPU throughput — cost is disproportionate |
The compute decision determines more than instance cost — it determines operational overhead, scaling behavior, security surface area, and the team skills required to operate the environment. An EKS cluster is not a Lambda function with more buttons. They require different operational models, different observability stacks, and different incident response capabilities.
Migration Patterns
Migration to AWS is not a single motion. It is a portfolio of decisions applied workload-by-workload based on the risk, value, and architectural complexity of each application. The 6-R framework provides the decision vocabulary.
Rehost (Lift & Shift) moves a workload to EC2 with minimal changes. The risk is low, the speed is high, and the cloud benefit is limited — you’ve moved the operational overhead from on-premises hardware to an EC2 instance, but you haven’t leveraged managed services, you haven’t improved the scaling model, and you’re still managing the OS. Rehost is appropriate when the goal is data centre exit speed, not cloud optimisation. It is a starting point, not a destination.
Replatform makes targeted optimisations during migration — moving a self-managed MySQL installation to RDS, or moving a batch job to Spot instances — without changing the application architecture. The risk is moderate, the operational benefit is immediate, and the migration complexity is manageable. Replatform is where most organisations find the best ratio of migration effort to cloud benefit.
Repurchase replaces a custom-built or self-managed application with a SaaS equivalent — migrating from a self-hosted CRM to Salesforce, or from self-managed email infrastructure to Microsoft 365. The migration motion is data migration and user cutover, not infrastructure migration. Repurchase eliminates the infrastructure entirely rather than moving it.
Refactor redesigns the application architecture to be cloud-native — decomposing a monolith into microservices, replacing scheduled batch jobs with event-driven Lambda functions, replacing a relational schema with a DynamoDB model. The effort is highest, the cloud benefit ceiling is highest, and the risk is proportional. Refactor makes sense for core business applications with long lifecycles where the cloud-native architecture will be maintained for years.
Retire decommissions workloads that are no longer needed. Migration assessments consistently reveal 10–20% of the application portfolio that can be retired rather than migrated — reducing both migration complexity and ongoing operational cost.
Retain keeps workloads in their current environment. Not every workload belongs in AWS. Workloads with high migration friction, recent hardware investment, strict data sovereignty requirements, or economics that favour on-premises should be retained deliberately — not as a failure of cloud strategy, but as a correct placement decision. The cloud repatriation framework applies the same rigour to this decision that the migration framework applies to workloads moving in.
Migration without a workload-by-workload classification against the 6-R framework produces cloud sprawl — a mix of under-optimised EC2 instances, abandoned experiments, and orphaned storage that accumulates cost without delivering proportional value.
When AWS Is The Right Call
Workloads with unpredictable demand spikes, global user bases, or burst compute requirements that would require significant over-provisioning on dedicated hardware. AWS’s Auto Scaling and global Region footprint are the structural advantages here.
New products and platforms that need to reach production in weeks, not quarters. The managed service catalogue — RDS, ElastiCache, SQS, EventBridge — eliminates the infrastructure bootstrap time that would otherwise consume the early development cycle.
Applications with sub-second RTO/RPO requirements across geographic failure domains. Building equivalent multi-Region resilience on private infrastructure requires a capital and operational investment that few organisations can justify outside specific regulated industries.
Early-stage AI workloads where GPU utilisation is unpredictable, model selection is still in flux, and the cost of idle private GPU hardware exceeds the cloud premium. Once utilisation stabilises above 60–70%, the repatriation calculus changes.
When To Consider Alternatives
Workloads with jurisdictional requirements that prohibit shared public cloud infrastructure — regardless of Region locking and dedicated hardware options. Some regulatory frameworks explicitly require customer-owned infrastructure with no shared tenancy at any layer.
Workloads with stable, predictable compute profiles at high utilisation — where Reserved Instance pricing still exceeds the equivalent on-premises hardware cost over a three-to-five year lifecycle. The break-even analysis should precede the architecture decision, not follow it.
Organisations deeply invested in Microsoft Entra ID, Active Directory, and the Microsoft identity ecosystem. Azure’s native Entra integration removes the federation complexity that AWS requires when Microsoft identity is the organisational standard.
Organisations building Kubernetes-native data platforms where GKE’s Autopilot, BigQuery integration, and Vertex AI represent a more cohesive stack than the equivalent AWS assembly. GCP’s Kubernetes lineage produces genuinely different operational defaults than EKS.
Decision Framework
| Scenario | AWS Verdict | Why |
|---|---|---|
| Global SaaS product, variable traffic | Strong Fit | Region footprint, Auto Scaling, and managed service depth match the operational model exactly |
| Data centre exit, speed is the priority | Strong Fit | Rehost path is well-understood, tooling is mature, Reserved Instances reduce long-term cost |
| AI inference, early-stage, unpredictable GPU demand | Strong Fit | On-demand GPU without capital commitment; re-evaluate when utilisation stabilises above 60% |
| Microsoft-first enterprise, Entra ID as identity standard | Evaluate Azure First | Native Entra integration removes federation complexity; AWS requires explicit SAML/OIDC configuration |
| Kubernetes-native data platform, BigQuery investment | Evaluate GCP First | GKE Autopilot and BigQuery integration represent a more cohesive stack than EKS + Redshift equivalents |
| Stable, high-utilisation workload, 5yr lifecycle | Model Before Committing | Run the break-even analysis — Reserved Instance pricing may exceed equivalent on-premises TCO at this profile |
| Jurisdictional data sovereignty, no shared tenancy | Private Infrastructure | Dedicated Host and Nitro isolation may not satisfy frameworks requiring customer-owned hardware at all layers |
You’ve seen how AWS is architected. The pages below cover what sits beside it — competing platforms, hybrid connectivity, cost governance, and the infrastructure disciplines that determine where AWS belongs in your environment.
Architect’s Verdict
AWS architecture is not about mastering the service catalog. It is about understanding where the shared responsibility boundary sits, how IAM governs the control plane, and which architectural patterns break under production load when the orchestration layer is under contention.
IAM is the control plane of your AWS architecture — not a security checklist. Every AWS service interaction, every cross-account access, every Lambda execution, every data pipeline operation flows through IAM. Organizations that treat IAM as a post-deployment security task rather than a first-class architectural design layer build systems that pass security audits and accumulate silent control plane drift. When IAM policies sprawl, when role assumptions chain across accounts, when permissions are granted at the boundary rather than at the resource level, the control plane becomes the constraint. IAM drift is harder to fix than infrastructure drift because it governs access to the infrastructure layer itself.
VPC topology determines failure domain boundaries more than any other AWS design decision. A poorly architected VPC creates blast radius coupling, egress cost accumulation, and latency floors that cannot be fixed without re-architecting the network layer from scratch. Organizations that design VPC topology for capacity rather than isolation discover the cost of that decision when a security incident requires network segmentation and the architecture cannot support it without downtime. Subnet design, routing table complexity, and NAT gateway placement all compound into operational overhead that grows with every new workload. VPC topology is not configuration. VPC topology is the foundation the rest of the architecture sits on.
Multi-AZ deployment is not automatic resiliency. It is the starting point for resiliency — and only if the orchestration layer, the data synchronization layer, and the state management layer are all engineered to survive AZ loss. Organizations that enable multi-AZ on RDS, deploy application instances across AZs, and call the architecture “highly available” without testing actual AZ failover under load build systems that look resilient and fail the first time an AZ actually goes down. The failure mode is not the AZ loss. The failure mode is the state synchronization layer that was never validated, the connection pool that was never tuned for cross-AZ latency, and the orchestration timeout that was never tested under degraded conditions.
Cross-AZ data transfer cost is not a rounding error. It is a structural cost dimension that compounds with every service-to-service call, every database replication event, every cache invalidation. Organizations that architect for multi-AZ resiliency without modeling cross-AZ transfer cost build systems that remain within budget during normal operations and blow past cost forecasts the moment traffic scales or failure triggers replication spikes. The cost is not in the compute. The cost is in the data movement.
AWS rewards architects who model the shared responsibility boundary as the design constraint, treat IAM as the control plane foundation, and validate resiliency assumptions under actual failure conditions rather than theoretical SLA maximums. The service catalog is broad, but the architecture discipline required to use it well is narrow.
You’ve Mapped the Control Plane.
Now Pressure-Test Your Architecture.
IAM posture, VPC topology, compute selection, egress exposure — understanding how AWS works is the first step. Validating that your specific environment is architected correctly is the one that actually matters. That’s where the triage session starts.
AWS Architecture Audit
Vendor-agnostic review of your AWS environment — IAM policy structure, VPC topology, compute selection, egress exposure, and cost model. No AWS partner alignment. The right architecture for your workloads, not the right architecture in general.
- > IAM posture and blast radius assessment
- > VPC topology and egress cost model
- > Compute selection and Reserved Instance strategy
- > Hybrid connectivity and Direct Connect readiness
Architecture Playbooks. Field-Tested Blueprints.
Field-tested blueprints from real AWS environments — IAM failures, egress traps, VPC topology mistakes, and the compute selection patterns that separate cost-controlled architectures from runaway bills. No vendor marketing. Just architecture depth.
- > AWS Cost & Egress Physics
- > IAM Architecture & Zero Trust Patterns
- > Landing Zone & Control Tower Architecture
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What makes AWS different from Azure and GCP for enterprise infrastructure?
A: Amazon AWS cloud strategy architecture centers on service depth and global Region footprint as its primary differentiators. With over 200 services and 33 Regions, AWS has the broadest coverage for enterprise workload classes — from legacy EC2-based migrations to serverless AI inference on Graviton. Azure’s differentiation is enterprise identity integration through Entra ID. GCP’s differentiation is Kubernetes-native architecture and data analytics depth. The right choice depends on your workload profile, identity standards, and existing vendor relationships.
Q: How does AWS handle data sovereignty and regulated workloads?
A: AWS provides several isolation mechanisms for regulated workloads: Region locking via SCP prevents data from leaving a specified Region at the control plane level. AWS Dedicated Hosts provide single-tenant bare-metal instances with no hardware sharing. AWS GovCloud provides US-only infrastructure with additional compliance certifications for government workloads. Customer-managed KMS keys ensure the customer controls the encryption lifecycle. For workloads requiring no shared infrastructure at any layer, these controls may still not satisfy certain regulatory frameworks — review against your specific compliance requirements before deployment.
Q: What is the most common AWS cost mistake?
A: Cross-AZ traffic charges on high-throughput microservice architectures. Teams that spread services across multiple AZs for resilience — correctly — without accounting for the inter-AZ data transfer cost generate significant unplanned spend. The fix is AZ-affinity for latency-sensitive, high-call-volume service pairs, combined with explicit architecture review of cross-AZ replication requirements.
Q: When does AWS Reserved Instance pricing stop making economic sense?
A: When the equivalent on-premises hardware cost over the same commitment period — including staffing, power, cooling, and hardware refresh — falls below the Reserved Instance price for equivalent compute. For most organisations this calculation favours AWS for variable or unpredictable workloads. For stable, high-utilisation workloads with predictable three-to-five year lifecycles, the break-even analysis should be run explicitly before the commitment.
Q: How should hybrid AWS architectures handle identity federation?
A: Through SAML 2.0 or OIDC federation between the on-premises identity provider (Active Directory, Okta, Azure AD) and AWS IAM Identity Center. Federation means users authenticate once through their existing identity system and receive temporary AWS credentials scoped to their IAM roles. Separate AWS-native user accounts that are manually kept in sync with the on-premises directory create governance drift and are the source of orphaned access after employee offboarding.
Q: How does AWS compare to on-premises for AI workloads?
A: For training workloads with unpredictable GPU demand and frequent model iteration, AWS provides on-demand access without capital commitment. For inference workloads with stable demand profiles, the economics shift at approximately 60–70% GPU utilisation — above that threshold, owned GPU infrastructure typically delivers better price-performance than on-demand cloud GPU pricing. The Graviton Lambda path for small language model inference changes this calculation for SLM use cases specifically — sub-500ms cold starts on Graviton at Lambda pricing is competitive with on-premises inference costs for many enterprise use cases.