Multi-Cloud Doesn’t Prevent Outages — It Makes Them Cascade

Part 1 of the Rack2Cloud’s Cloud Fragility Series
Why your redundancy strategy might actually be a hidden detonator for a cross-cloud blackout.
Most multi-cloud environments aren’t a strategy — they’re the accumulated result of provider selections that were never made with a framework. Understanding what each provider’s architecture actually optimizes for, and where the tradeoffs land, is what separates deliberate multi-cloud from accidental complexity. The Cloud Provider Decision Framework: AWS vs Azure vs GCP covers the five axes that make a single-provider selection defensible — and multi-cloud intentional rather than inherited.
The False Promise of the Second Cloud
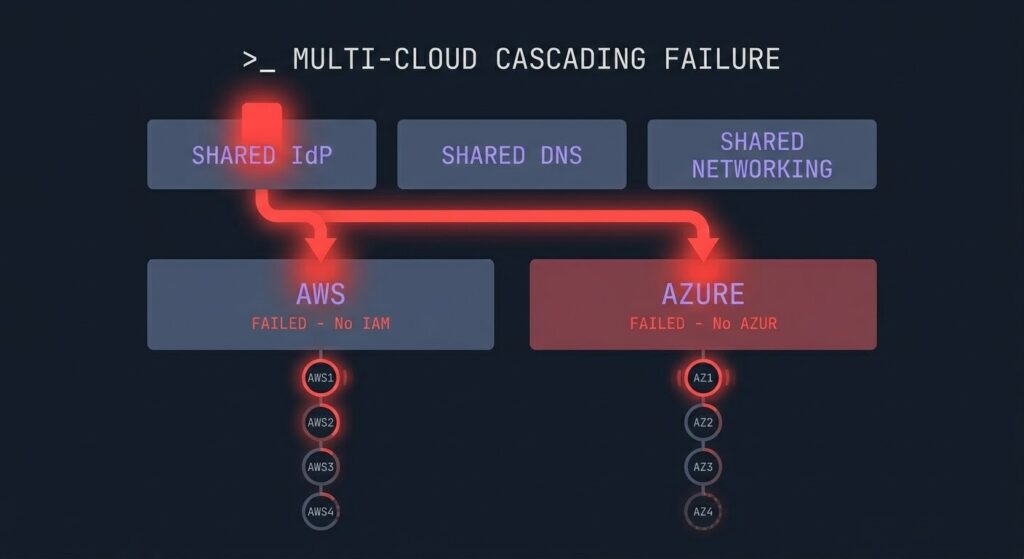
For years, the boardroom directive has been simple: ‘We can’t afford a single point of failure. If AWS goes down, we failover to Azure.’ In 2026, multi-cloud cascading failure has become the outcome that strategy produces — not the one it prevents. Architecturally, this sounds like common sense. But in 2026, we’ve entered the era of the “Shared Choke Point.” True Multi-Cloud is an illusion if the two clouds are tethered by the same DNS provider, the same Identity system, and the same networking shortcuts.
When one provider stutters, the “failover” logic often triggers a surge that takes down the healthy provider. This isn’t redundancy; it’s a Cascading Failure.
The Hidden Dependency Chain
Most architects focus on the “compute” (the VMs and Containers). But the compute is just the tip of the spear. The “Cascade” happens in the shadows:
- The Identity Handshake: If your AWS and Azure environments both trust the same Okta or Azure AD tenant, an authentication delay in one can paralyze the “failover” process in the other. (See our deep dive on Cloud Provider HA Strategy).
- The Interconnect Bottleneck: Using the public internet for cross-cloud traffic is a recipe for non-deterministic failure. As we noted in our Modern Networking Logic guide, the “Public Internet is not an SLA.”
- The Metadata Storm: When Cloud A fails, Cloud B is suddenly hit with 100% of the traffic, often triggering rate-limits on APIs and Load Balancers that were never stress-tested for a “cold start” of that magnitude.
The Identity Handshake: A Hidden Failover Detonator
The most dangerous “invisible” link in a multi-cloud stack is the Identity Handshake. Most architects treat Identity (SAML/OIDC) as a utility, but in a crisis, it becomes a binary switch.
When you federate your clouds—for example, using Okta to gate access to both AWS and Azure—you aren’t just simplifying logins; you are creating a Sync Deadlock. If your Identity Provider (IdP) experiences a regional latency spike, your “Failover Logic” may enter an infinite loop:
- The Auth Loop: Your AWS environment attempts to failover to Azure.
- The Choke Point: Azure requests a fresh token from the IdP.
- The Cascade: The IdP, struggling with the same regional outage as AWS, fails to issue the token.
- The Result: You are “Blind and Bound”—your servers are healthy, but your permissions are locked.
Caption: A typical multi-cloud dependency web where a single IdP failure halts cross-cloud failover.
Architectural Pillars of Resilience
Building a failover strategy that actually works requires moving beyond simple provider SLAs. You must align your stack with the Pillars of Cloud Architecture:
- Reliability: Decouple your management plane from your data plane.
- Security: Implement “Break-Glass” local accounts that bypass federation during a Tier-1 outage.
- Operational Excellence: Use automated drift detection to ensure your Azure “Backup” hasn’t diverged from your AWS “Primary.”
For those looking to master these concepts, our Architectural Pillars and Learning Paths provide the technical foundation for these high-availability designs.
Why SLAs Won’t Save You
Enterprises often hide behind Provider SLAs, assuming a “99.99%” guarantee from two providers equals “eight nines” of uptime. This is a mathematical trap. SLAs are a financial insurance policy, not a technical resilience strategy.
As we’ve argued before, Your Cloud Provider Is a Single Point of Failure; an SLA credit for a 4-hour outage doesn’t recover your lost customer trust or your brand’s integrity.
The Brutalist Reality: From Complexity to Resilience
The answer isn’t “More Cloud.” The answer is Visible Dependencies. If you don’t map exactly where your DNS, Identity, and Traffic Management live, you are just building a more expensive way to fail. We need to stop looking for a “Swiss Army Cloud” and start auditing the Concentration Risk of our current stacks.
Actionable Next Steps for Architects:
- Audit your “Blind Spots”: Does your secondary cloud rely on an API key stored in your primary cloud’s Key Vault?
- Test the “Cold Failover”: Have you ever actually shut down your primary region to see if the secondary can handle the “Thundering Herd”?
- Consolidate Logic, Diversify Infrastructure: Keep your management logic simple, but ensure the physical infrastructure doesn’t share a power grid or a backbone.
If you look across the whole series, there’s a pattern: Modern outages rarely start with compute or storage. They start in the shared control layers.
And as we’ll see in Part 2, Identity is the most dangerous layer of them all.
The Dependency Map You Haven’t Built
Every multi-cloud architecture has a dependency map. Most teams haven’t drawn it. The compute topology is documented — which workloads run where, which regions are active, which databases replicate to which. The shared control layer dependencies almost never are.
The audit is three questions. First: does your secondary cloud use any credential, secret, or API key stored in your primary cloud’s key vault or secrets manager? If yes, a primary cloud failure can revoke your secondary cloud’s ability to operate. Second: have you ever run a cold failover drill — actually disabled your primary region — to see what the secondary does under full production load? Third: does your monitoring and alerting infrastructure share a dependency with the environment it monitors? An observability stack that goes dark when the primary region fails tells you nothing at the moment you need it most.
These are not exotic failure scenarios. They are the standard failure chain in every major multi-cloud incident postmortem from the past three years. The multi-cloud cascading failure pattern is documented, repeatable, and preventable — but only if the dependency map exists before the incident.
Architect’s Verdict
Multi-cloud is a resilience strategy that requires more architectural discipline than single-cloud, not less. The assumption that two providers equals twice the reliability is the most dangerous misconception in enterprise cloud architecture. Two providers sharing one identity system, one DNS provider, and one set of networking shortcuts is not multi-cloud redundancy. It is one blast radius with extra billing.
The multi-cloud cascading failure pattern is not a theoretical edge case. It is the natural outcome of grafting a second provider onto an architecture designed for one, without auditing the shared dependencies that make both providers operationally coupled. The second cloud inherits all the single points of failure of the first — it just costs more.
True multi-cloud resilience requires blast radius isolation at the control layer, not just the compute layer. That means independent identity authorities, DNS that doesn’t share a failure domain with the workloads it serves, and traffic management that has been stress-tested under cold failover conditions. It means treating the management plane with the same redundancy discipline applied to the data plane. Most architectures do the latter and ignore the former. That is where cascades start.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




