RAG fails at the retrieval layer. Here’s the architecture that fixes it.
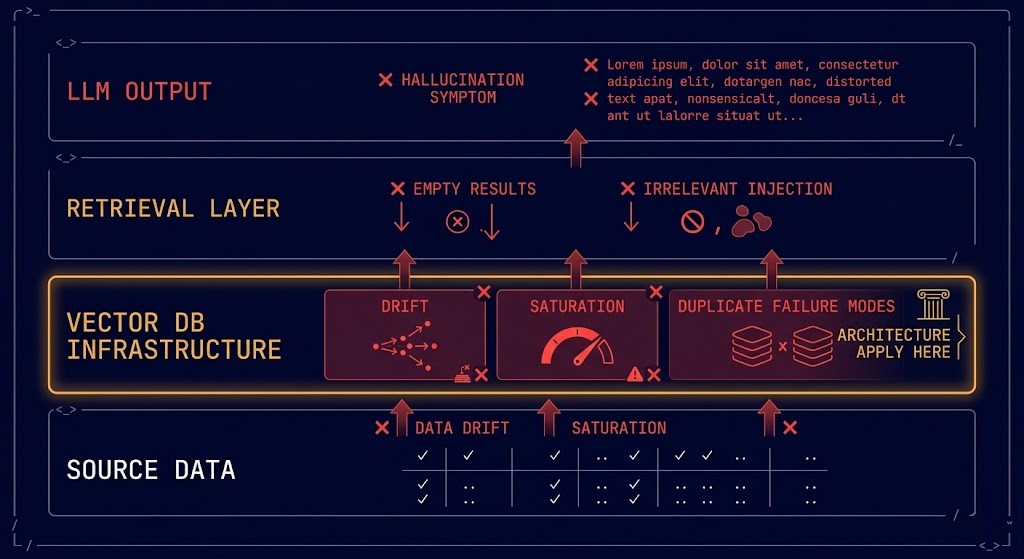
Most RAG failures are diagnosed at the wrong layer.
The team looks at the LLM output — hallucinated, irrelevant, outdated — and assumes the model is the problem. They swap embedding models, tune prompts, upgrade to a larger LLM. The outputs improve slightly. The problem persists.
The actual failure is in the retrieval infrastructure. The vector index is drifted. The ingestion pipeline is producing duplicate embeddings. The node handling high-similarity queries is saturated while adjacent nodes sit idle. The chunking strategy that worked at 10,000 documents is producing noise at 10 million.
RAG is not an AI problem. It is an infrastructure problem with an AI symptom.
This page treats vector databases as what they actually are: distributed storage systems with specific replication, indexing, sharding, backup, and operational requirements — that happen to serve AI retrieval workloads. The AI context is real and important. The infrastructure design comes first.
Why Vector Databases Fail in Production
Vector databases fail for infrastructure reasons, not AI reasons. The failure taxonomy is consistent across deployments:
| Failure Mode | Root Cause | Production Impact |
|---|---|---|
| Index Drift | Source data updated without re-embedding | Retrieval returns stale or irrelevant results silently |
| Ingestion Duplicates | Non-idempotent pipeline reprocesses documents | Retrieval noise from duplicate vectors skews similarity scores |
| Node Saturation | Query load not distributed across shards | High-similarity queries pile onto single nodes while others idle |
| Embedding Model Mismatch | Index built with model A, queries run with model B | Zero retrieval accuracy — vectors exist in different semantic spaces |
| Backup Blindspot | Index treated as ephemeral, not backed up | Full re-embedding required after node failure — hours or days of downtime |
| Chunk Strategy Drift | Chunking parameters changed post-initial-index | Index contains mixed chunk sizes, retrieval quality degrades unpredictably |
The pattern mirrors the infrastructure failure taxonomy in Modern Infrastructure & IaC — configuration drift, manual operations, and untested recovery paths. The database technology is different. The failure modes are structurally identical.
What Vector Databases Actually Are
Vector databases are not search engines with an AI interface. They are distributed storage systems with specific operational characteristics that most infrastructure teams haven’t encountered before.
The infrastructure primitives:
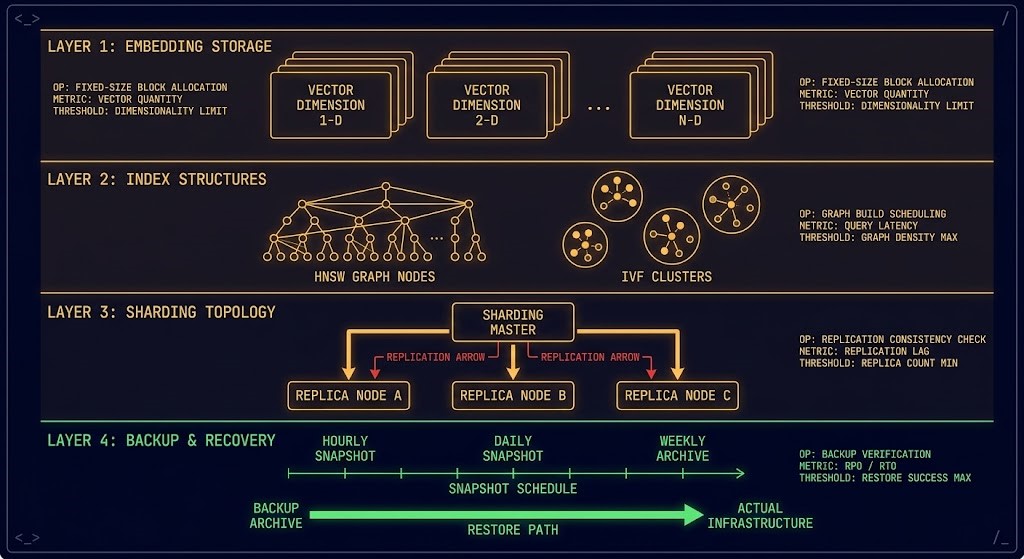
Embedding storage — high-dimensional floating point vectors (typically 768 to 1536 dimensions) stored in structures optimized for approximate nearest neighbor (ANN) search. Not rows. Not objects. Mathematical representations of meaning.
Index structures — the data structures that make ANN search tractable at scale. HNSW (Hierarchical Navigable Small World) for high-recall low-latency. IVF (Inverted File Index) for memory-efficient clustering. PQ (Product Quantization) for compression at the cost of precision. Each is a different trade-off between recall, latency, and cost — not an AI decision, an infrastructure decision.
Sharding and replication — the same distributed systems problems as any horizontally scaled database. How do you distribute vectors across nodes? How do you replicate for availability? What happens to query consistency during node failure or shard rebalancing? These questions have the same operational weight as they do for Elasticsearch or Cassandra.
Persistence and backup — vector indexes are expensive to rebuild. A 100 million vector index with 1536 dimensions takes hours to rebuild from source documents. The data protection architecture principles apply directly — backup is not optional, recovery must be tested, and RPO/RTO targets must be defined before the first production deployment.
Indexing Physics — The Speed vs Accuracy Trade-off
Vector search is an approximation problem. Searching billions of high-dimensional points in real-time is computationally intractable without approximation — and every approximation algorithm makes a trade-off between recall, latency, and memory cost.
This is not an AI accuracy question. It is an infrastructure design question.
IaC & Infrastructure Deployment
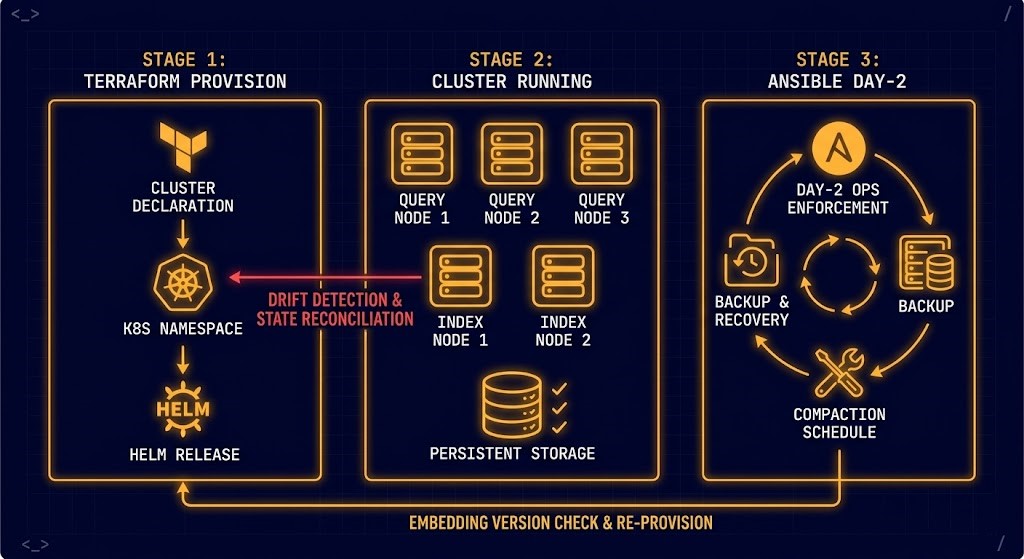
Vector databases are infrastructure. They should be deployed, configured, and managed with the same IaC discipline as any other production system.
Terraform — Milvus cluster provisioning:
hcl
# Declare vector DB infrastructure state
resource "kubernetes_namespace" "milvus" {
metadata {
name = "milvus-production"
labels = {
environment = "production"
managed-by = "terraform"
}
}
}
resource "helm_release" "milvus" {
name = "milvus"
namespace = kubernetes_namespace.milvus.metadata[0].name
repository = "https://milvus-io.github.io/milvus-helm/"
chart = "milvus"
version = "4.1.0"
set {
name = "cluster.enabled"
value = "true"
}
set {
name = "replicaCount.queryNode"
value = "3"
}
set {
name = "replicaCount.indexNode"
value = "2"
}
# Persistence — never deploy vector DBs without it
set {
name = "minio.persistence.enabled"
value = "true"
}
set {
name = "minio.persistence.size"
value = "500Gi"
}
}
# Drift on any of these values surfaces on next terraform plan
# Recovery = terraform apply, not manual console interventionThe Terraform & IaC guide covers the state enforcement principles that make this deployment reproducible — the same terraform apply that builds the initial cluster rebuilds it identically after a failure.
Ansible — Day-2 index maintenance:
yaml
# Enforce vector DB operational state
- name: Vector DB Day-2 Operations
hosts: milvus_nodes
become: true
tasks:
- name: Verify index compaction schedule
cron:
name: "milvus-compaction"
minute: "0"
hour: "2"
job: "/usr/local/bin/milvus-compaction.sh"
state: present
- name: Enforce backup schedule
cron:
name: "vector-index-backup"
minute: "30"
hour: "1"
job: "/usr/local/bin/backup-milvus-index.sh"
state: present
- name: Validate embedding model version consistency
command: python3 /opt/milvus/check-embedding-version.py
register: embedding_check
failed_when: embedding_check.rc != 0
changed_when: false
# Run weekly — idempotent by design
# Same playbook on a correctly configured node = no changes
# Same playbook on a drifted node = drift correctedThe Ansible & Day-2 Ops guide covers the operational enforcement patterns. The same principles that govern OS patching and service configuration govern vector DB lifecycle management — scheduled, automated, idempotent.
The GitOps for bare metal post extends this to physical infrastructure — if your vector DB runs on dedicated hardware rather than Kubernetes, the same SDLC discipline applies.
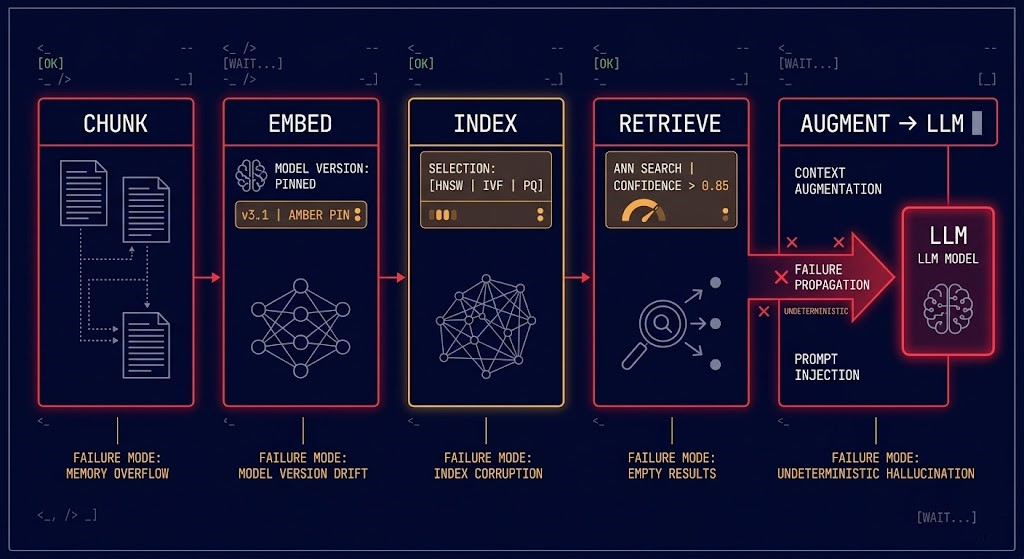
RAG Pipeline Architecture
RAG is an operational pipeline. Most failures occur long before the LLM is ever called. The vector database is the infrastructure layer that determines whether the pipeline produces deterministic results or probabilistic noise.
The AI Infrastructure layer — GPU orchestration, LLM serving, inference cost optimization — sits above this pipeline. See: AI Infrastructure Architecture and AI Inference Cost Architecture.
Failure Domains & Data Governance
Vector database failure domains follow the same design principles as any distributed system — with one additional failure mode unique to AI retrieval: silent accuracy degradation.
A failed Postgres node produces an error. A drifted vector index produces wrong answers that look correct. The infrastructure failure mode is invisible at the application layer until someone notices the AI outputs are subtly wrong — which may take days or weeks in production.
The three failure domains requiring explicit design:
Index availability domain — which nodes hold which shards, and what happens to query routing when a node fails. The same shard placement and replication factor decisions that govern Elasticsearch topology govern vector DB topology. A 3-node cluster with RF=2 can survive one node failure. A 3-node cluster with RF=1 cannot. This is not an AI decision.
Ingestion pipeline domain — the pipeline that processes new documents, generates embeddings, and updates the index. If this pipeline fails mid-run, does the index end up in a partially updated state? Is the ingestion idempotent — can it be re-run safely after failure? The Kubernetes PVC stuck volume pattern is a concrete example of what happens when persistent storage failure propagates into an ingestion pipeline.
Embedding model governance domain — the version control and change management process for embedding models. Changing the embedding model invalidates the entire index. This is a planned operational event that requires the same change management discipline as a database schema migration. It should be version-controlled, tested in staging, and executed with a rollback plan. The RPO/RTO framework applies — how much index staleness is acceptable, and how fast must reindexing complete after a model upgrade?
Namespace isolation and access control — without metadata-based access control, a RAG query from one user or tenant can retrieve context from another. This is both a data governance failure and a security failure. The same identity plane separation that protects backup infrastructure protects vector DB namespaces — credentials that can query across namespace boundaries are a data leak waiting for a query to trigger it.
Infrastructure Maturity Model
Most production vector DB deployments operate at Stage 1 or Stage 2. Most production RAG failures are Stage 1 and Stage 2 infrastructure problems.
Decision Framework — Platform Selection
No single vector database is correct for every workload. The selection criteria are infrastructure criteria, not AI criteria.
| Requirement | Architecture Decision | Risk if Wrong |
|---|---|---|
| Low latency (<50ms p99) | HNSW index, in-memory, dedicated query nodes | Latency SLA violations under load |
| Billion-scale vectors | Horizontally sharded standalone DB (Milvus, Weaviate) | Index rebuild time measured in days, not hours |
| Data sovereignty / air-gap | Self-hosted standalone DB, no managed service | Managed services (Pinecone) introduce data residency risk |
| Multi-tenant isolation | Namespace-per-tenant with separate credentials | Cross-tenant data leakage via unrestricted queries |
| Frequent document updates | Idempotent ingestion pipeline + scheduled compaction | Duplicate vectors accumulate, retrieval quality degrades |
| Cost-sensitive scale | PQ compression + tiered storage (hot HNSW / cold IVF) | Over-provisioned RAM for cold vectors that rarely get queried |
Vector databases sit at the intersection of Modern Infrastructure and AI Infrastructure. The pages below cover both execution paths — the infrastructure disciplines that make vector DB systems production-grade, and the AI layers that consume them.
Architect’s Verdict
The teams that build reliable RAG systems aren’t the ones with the best LLMs. They’re the ones who treated the vector database as production infrastructure from day one.
That means IaC provisioning before the first document is indexed. Backup schedules before the first production query. Idempotent ingestion pipelines before the first reprocessing run. Namespace isolation before the first multi-tenant deployment. Embedding model version pinning before the first model upgrade.
Do this:
- Deploy vector DBs with Terraform — treat drift on any configuration parameter as an incident trigger
- Pin embedding model versions and treat model upgrades as planned operational events requiring full reindex
- Implement idempotent ingestion — the pipeline must be safely re-runnable after any failure
- Back up the vector index — rebuilding from source takes hours, restoring from backup takes minutes
- Set confidence thresholds on retrieval — if the best match score is below threshold, return “I don’t know” rather than injecting low-relevance context into the LLM prompt
- Monitor retrieved context, not just generated output — observability into what the retriever returns is where failures are actually visible
Avoid this:
- Single-node prototype deployments promoted to production without replication
- Embedding model changes without full reindex — the index and the query embeddings must use the same model
- Ingestion pipelines without idempotency guarantees — duplicate vectors are silent and accumulate
- Treating the vector index as ephemeral — it is a production data asset that requires the same backup discipline as any other
- Skipping namespace isolation in multi-tenant environments — cross-tenant retrieval leakage is a data governance incident
RAG fails at the retrieval layer. The retrieval layer is infrastructure. Design it like it matters — because when it fails, everything above it fails with it.
You’ve Chosen the Vector Store.
Now Validate the Retrieval Architecture.
Embedding model selection, chunking strategy, index configuration, retrieval accuracy, and cost per query — RAG pipelines that work in demos fail in production for reasons that are almost always architectural. The triage session validates whether your retrieval layer is actually answering questions or just looking busy.
Vector Database & RAG Audit
Vendor-agnostic review of your vector database and RAG pipeline — embedding model fit to your data domain, chunking and indexing strategy, retrieval accuracy measurement, query latency profile, and whether a dedicated vector database is actually justified versus pgvector or a simpler alternative.
- > Embedding model and chunking strategy review
- > Vector database selection and cost model validation
- > Retrieval accuracy measurement and gap analysis
- > RAG pipeline latency and cost per query optimization
Architecture Playbooks. Every Week.
Field-tested blueprints from real RAG deployments — overengineered vector database case studies, chunking strategy failures, retrieval accuracy diagnostics, and the embedding architecture patterns that actually improve answer quality rather than just increasing infrastructure complexity.
- > RAG Pipeline Architecture & Retrieval Quality
- > Vector Database Selection & Cost Analysis
- > Embedding Strategy & Chunking Patterns
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: Do vector databases replace relational or NoSQL databases?
A: No — they complement them. Structured business logic, transactions, and relational data belong in traditional databases. The vector store handles semantic retrieval for AI workloads. Most production systems run both in parallel. The microservices architecture guide covers how multiple data stores coexist in a well-designed service mesh.
Q: FAISS vs Milvus vs Pinecone — which do I use?
A: FAISS is a library for single-node workloads — maximum performance, no clustering, no built-in persistence. Milvus and Weaviate are standalone databases built for horizontal scale, replication, and production operations. Pinecone is a managed service — operational simplicity at the cost of data sovereignty and vendor lock-in. For sovereign or regulated environments, self-hosted standalone is the only option. For small-scale or prototype workloads, FAISS is sufficient until you need clustering.
Q: How often do I need to re-embed my data?
A: Whenever the source data changes significantly, and whenever you upgrade the embedding model. Re-embedding is a full reindex operation — it requires the same change management discipline as a database migration. Schedule it, test it in staging, and execute it with a rollback plan. The RPO/RTO framework defines how much index staleness is acceptable and how fast re-embedding must complete.
Q: Can vector DBs run on-premises for sovereign or air-gapped environments?
A: Yes — and for regulated environments, it’s often the only compliant option. Self-hosted Milvus, Qdrant, or Weaviate combined with a locally deployed embedding model and LLM provides full data sovereignty. The Kubernetes cluster orchestration guide covers the deployment architecture for running this stack on-premises.
Q: What’s the right chunk size for RAG?
A: There is no universal answer — chunk size depends on your embedding model’s context window, your document structure, and your query patterns. The operational principle is: chunk size is infrastructure configuration, not a one-time setup decision. It should be version-controlled, testable, and changeable without full reindex when possible. Start with 512 tokens with 50-token overlap and measure retrieval precision before tuning.
Q: How do I monitor a vector database in production?
A: The same way you monitor any distributed database — node health, query latency (p50/p95/p99), replication lag, disk usage, and memory pressure. Additionally: retrieval hit rate (queries returning results above confidence threshold), embedding model version consistency across nodes, and ingestion pipeline lag. The gap most teams miss is monitoring retrieved context quality — not just whether the system returns results, but whether those results are relevant. See the Day-2 failure patterns post for the operational monitoring discipline that applies across distributed systems.