AI Infrastructure Architecture
Fabric-Bound. Memory-Constrained. Cost-Compounding. Traditional Cloud Assumptions Don’t Apply.
AI infrastructure is not a software problem with a hardware footnote. The decisions that determine whether your AI systems scale, stay within cost bounds, and survive production load are infrastructure decisions — made before the first model is deployed, and largely irreversible once the architecture is set.
That distinction matters operationally. Organizations that treat AI infrastructure as a scaled-up version of their existing virtualization environment consistently underperform on GPU utilization, inference cost, and training throughput. They provision GPU clusters the way they sized VM farms. They run inference workloads on training hardware. They hand inference cost to FinOps without giving FinOps the instrumentation to see behavioral spend. The mental model carries forward — and the mental model is wrong.
AI infrastructure rewards architects who engage with its actual physics: a fabric-bound, memory-constrained system where P99 latency governs distributed training performance, where inference cost is driven by agent behavior not GPU utilization, and where the boundary between the control plane and the data plane is where most production failures originate. The depth of the problem — silicon, fabric, storage, inference, operations, cost — is not a feature list. It is a set of interdependent engineering constraints. Understanding which ones govern your workload class is the actual skill.
This guide covers exactly that decision — how the AI infrastructure stack is structured, where the shared responsibility boundary sits in GPU environments, how training and inference diverge as separate infrastructure problems, and where cloud AI is the right answer versus where the economics and physics point toward private infrastructure.
The Infrastructure Layer Most Teams Get Wrong
Most teams get AI infrastructure wrong in the same four ways. They treat inference like a scaled-down training workload — same hardware, same cost model, same operational playbook. They underestimate the fabric and pay for it in P99 latency spikes and gradient synchronization stalls. They let FinOps own AI cost without giving FinOps the instrumentation to see behavior-driven spend. And they build for training, then discover that inference operations are an entirely different discipline with entirely different failure modes.
The result is GPU clusters sitting at 40% utilization while inference bills compound silently, and production training jobs stalling not because the GPUs are slow — but because the storage layer collapsed under checkpoint I/O. These are not hardware failures. They are architecture failures. And they are preventable.
What AI Infrastructure Actually Is

The distinction between the control plane and the data plane is not semantic — it changes how you architect, how you debug, and where you spend operational energy.
The architectural implication is direct: control plane failures are configuration failures — wrong scheduler settings, missing execution budgets, misconfigured routing policies. Data plane failures are physics failures — fabric P99 violations, checkpoint throughput bottlenecks, memory bandwidth exhaustion. They require different instrumentation, different debugging approaches, and different remediation paths. Conflating them produces incidents that are expensive to diagnose and impossible to prevent.
The Fabric Is the System
In a distributed training cluster, the network is not infrastructure supporting the compute. The network is the system. GPU compute without a deterministic fabric is not a training cluster — it is a collection of expensive hardware waiting for the network to resolve contention events.
The physics are unforgiving. In distributed training, all nodes must complete their gradient calculation before the next training step can begin. A single delayed packet on a single node does not slow that node — it stalls the entire cluster. 511 GPUs finish in 10ms. One GPU waits 15ms for a congested switch buffer to drain. The training step does not advance until all 512 nodes are synchronized. At scale, this is not an edge case. It is the default behavior of a fabric that was not designed for AI.
The solution is not faster hardware. It is deterministic architecture: symmetric leaf-spine topology with zero oversubscription, ECN over PFC for congestion signaling, deterministic buffer allocation sized for microburst absorption, and adaptive routing that re-paths around failure without creating new congestion. The full fabric architecture — RDMA, InfiniBand vs RoCEv2, and the networking invariants that must be enforced through IaC — is mapped in Distributed AI Fabrics. The LP stage that sequences fabric architecture within the broader AI infrastructure maturity model is A2 — Fabric Architecture
The AI Infrastructure Stack — Layer by Layer
AI infrastructure is a stack, not a platform. Each layer has distinct physics, distinct failure modes, and distinct cost implications. Optimizing one layer without understanding its dependencies produces local improvements and systemic bottlenecks.
Training vs Inference — Two Different Infrastructure Problems
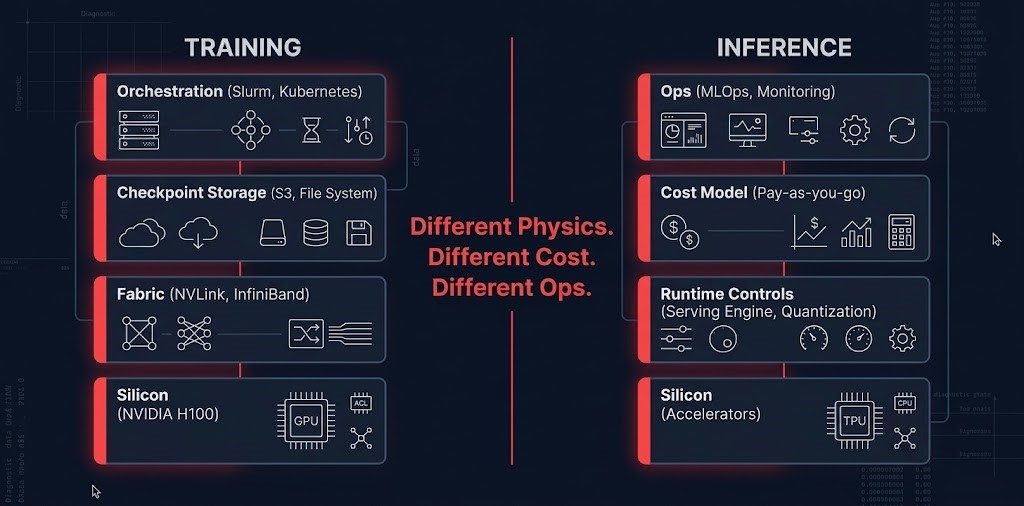
Training and inference are not versions of the same workload. They have different physics, different cost models, and different failure modes. The fact that both have historically run on GPUs was a convenience of early AI infrastructure — not an architectural design choice.
Running both workloads on shared GPU hardware was the norm when AI infrastructure was experimental. At production scale, that model produces two predictable outcomes: training jobs that stall because inference workloads consume shared GPU memory, and inference bills that compound because GPU utilization — which looks healthy — is no longer the cost signal. The GTC 2026 hardware split formalized this separation at the silicon level.
AI Execution Models — Choosing the Right Path
Not all AI workloads require the same infrastructure model. The execution decision determines cost structure, operational overhead, latency profile, and scaling behavior. Defaulting to GPU clusters for every AI workload is the infrastructure equivalent of defaulting to EC2 for every cloud workload.
| Workload Type | Execution Model | Why | Avoid |
|---|---|---|---|
| Training (large models) | Dedicated GPU cluster | Predictable throughput, fabric control | Shared cloud clusters at scale — fabric contention kills utilization |
| Inference (high volume) | Optimized inference endpoints | Cost + latency control | Raw GPU hosting — no token-level cost governance |
| Low-latency inference | Edge / colocated inference | Physics — data gravity | Cross-region inference calls — latency is structural |
| Batch inference | Async pipelines | Cost efficiency | Real-time infra for non-latency-sensitive work |
| RAG workloads | Vector DB + colocated inference | Retrieval locality | Remote embeddings — egress compounds per retrieval call |
Shared Responsibility in AI Infrastructure
AI infrastructure responsibility does not split the way cloud infrastructure responsibility splits. The vendor provides the hardware layer. You are responsible for everything that determines whether that hardware produces value — or produces a bill.
- →GPU hardware availability and physical health
- →Base networking fabric and physical interconnect
- →Managed runtimes (where applicable)
- →Physical security and hardware lifecycle
- →Driver availability and firmware updates
- →Model efficiency and batching strategy
- →Prompt and token design — every token is a cost event
- →Inference routing and model selection logic
- →Execution budget enforcement and cost control logic
- →Data placement, gravity management, and egress control
The practical consequence: most AI infrastructure cost failures are not vendor failures. They are execution layer failures — unbounded inference loops, missing batching strategy, remote embeddings paying egress on every retrieval call, token ceilings that were never defined. The vendor gave you the hardware. What you do with it is entirely within your control.
The Cost Architecture Problem
AI infrastructure cost breaks every forecasting model built for traditional cloud. Training cost is a bounded CapEx analog — you plan for it, it arrives once, you move on. Inference cost is compounding OpEx that accumulates through behavior, not provisioning.
The teams getting blindsided are not doing anything wrong operationally. They are using the wrong cost model. FinOps dashboards built for EC2 reservation optimization cannot see token consumption rates, retry storm frequency, or RAG pipeline chunk count changes — all of which drive inference cost independently of GPU utilization. When the quarterly bill arrives 40% over forecast, the infrastructure looks fine. The cost driver is behavioral, and it lives above the infrastructure layer.
The full cost architecture — GPU locality, data gravity, cross-zone inference cascades, and execution budget enforcement — is the subject of the AI Inference Cost Series. If you are building AI infrastructure and have not modeled inference cost as a behavioral property, that is the starting point. The autonomous systems drift post maps what happens to inference cost when runtime controls are absent — small deviations that compound into large bills with no single identifiable cause.
AI Observability — What Actually Breaks
Standard infrastructure observability was built for failure detection. AI infrastructure requires drift detection — a different instrumentation model that catches problems before they appear on a bill or an incident report.
The instrumentation that catches these signals requires per-request token consumption tracked over time, model call counts per workflow, retry rate trends by agent, context utilization percentages across request cohorts, and output characteristic distributions. Most teams aggregate at the wrong level — total spend per day instead of cost per request per workflow — which hides the drift signal inside volume noise. The Learning Path stage that maps the full governance instrumentation model — signal surfaces, authority boundaries, and runtime enforcement — is A6 — Governance & Runtime Control.
The Inference Inflection — What GTC 2026 Changed
GTC 2026 formalized the training/inference split at the hardware level. For the first time, NVIDIA shipped dedicated inference silicon — the Groq 3 LPX rack, built around LPUs rather than GPUs — alongside the Vera Rubin NVL72 training rack as a first-class platform component.
The practical implication: the separation of concerns that architects have been modeling as an abstract design decision is now a hardware procurement decision. Training infrastructure and inference infrastructure are separate systems, from the silicon up. Teams still running inference on training hardware are working against the architecture the industry has formally adopted. The full implications for cost model, runtime controls, and infrastructure planning are in The Training/Inference Split Is Now Hardware.
When AI Belongs in Cloud vs On-Prem
The cloud vs on-premises decision for AI infrastructure is not a philosophical preference. It is a workload physics and economics decision that changes as utilization stabilizes and data volumes grow.
- [+]Burst training — unpredictable GPU demand without capital commitment
- [+]Experimentation — model selection still in flux, utilization unpredictable
- [+]Low utilization phases — GPU idle time makes cloud economics favorable
- [+]Global distribution requirements — multi-region inference serving
- [+]Steady inference workloads — GPU utilization above 60–70% consistently
- [+]Data sovereignty — regulatory or security constraints prohibit cloud control planes
- [+]Large stable datasets — data gravity makes compute migration more expensive than hardware
- [+]Predictable high-utilization training — owned GPU delivers better price-performance above the break-even threshold
The break-even threshold for most AI workloads is approximately 60–70% consistent GPU utilization over a 12–18 month horizon. Below that, cloud economics win. Above it, owned infrastructure typically delivers better price-performance — and the repatriation calculus shifts decisively. The Sovereign Infrastructure pillar covers the full control plane independence requirements for on-premises AI deployments.
Sovereign AI — When the Stack Needs to Stay Private
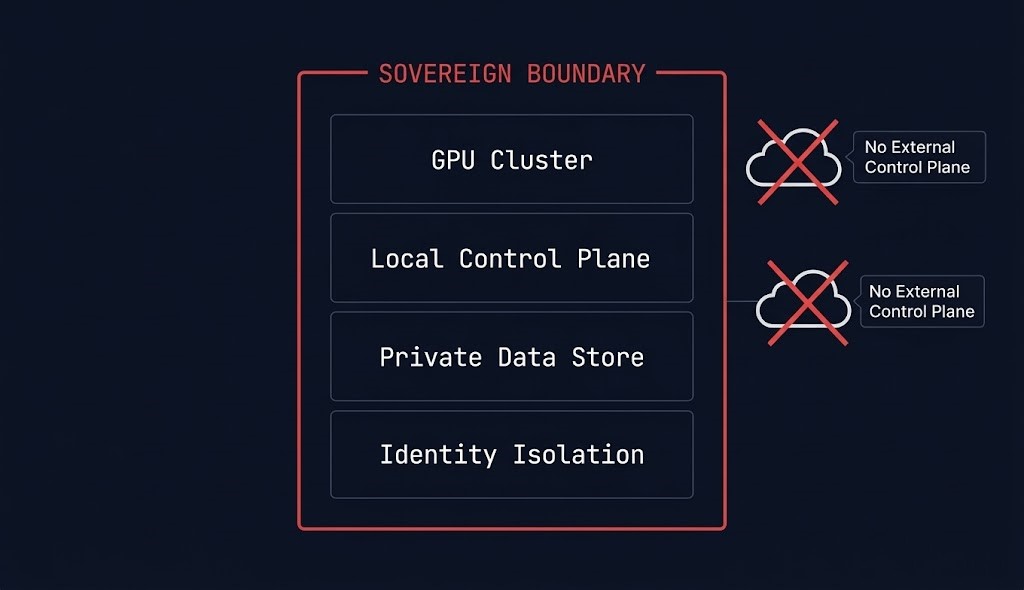
For organizations with regulatory constraints, data residency requirements, or security postures that prohibit SaaS control plane dependency, sovereign AI infrastructure is not an option — it is the architecture. Sovereignty in AI is not about where the model runs. It is about whether the control plane can be reached from outside the sovereign boundary.
Sovereign AI infrastructure requires four things most private GPU deployments do not plan for explicitly: a local control plane that operates independently of external identity providers, GPU cluster governance that does not require cloud console access, data residency enforcement at the storage and retrieval layer, and inference serving that stays within the sovereign boundary. The Vector Databases & RAG architecture covers sovereign vector store design for environments where embedding data cannot leave the private boundary.
Decision Framework

Every AI infrastructure scenario has a right architecture call. Most teams discover it after the bill arrives or after the first production incident. The framework below maps the scenario to the call — before commitment.
| Scenario | Architecture Call | Primary Risk |
|---|---|---|
| Early-stage AI, unpredictable demand | Cloud-first | Inference cost drift without runtime controls |
| Production inference, stable demand | Optimize + hybrid | GPU underutilization on dedicated hardware |
| High-scale inference, GPU util >60% | On-prem GPU cluster | CapEx lock-in if utilization drops |
| RAG-heavy applications | Co-locate compute + vector DB | Retrieval latency and egress if separated |
| Regulated AI, data sovereignty required | Sovereign infrastructure | Operational complexity of private control plane |
You’ve seen how AI infrastructure is architected. The pages below cover the engineering disciplines that sit inside the stack — and the learning path that sequences them from silicon through operations.
Architect’s Verdict
AI infrastructure is systems engineering, not optimization. If you treat a GPU cluster like a scaled-up virtualization farm, you will fail — not dramatically, but quietly, through idle GPUs, stalled training runs, and inference bills that compound past every forecast.
- [+]Model inference cost as behavior — not provisioning
- [+]Engineer the fabric before you buy the GPUs
- [+]Build execution budgets in from day one — not after the first bill
- [+]Treat training and inference as separate infrastructure problems from day one
- [+]Validate storage checkpoint throughput before committing to cluster size
- [!]Treat AI infrastructure like a scaled-up virtualization farm
- [!]Let FinOps own inference cost without workflow-level instrumentation
- [!]Confuse training architecture for inference architecture
- [!]Provision GPU capacity before modeling data gravity and egress
- [!]Deploy agentic inference workloads without execution budget enforcement
The AI Architecture Learning Path is the sequenced reading order for architects building or stress-testing this stack from the ground up.
You’ve Got the Stack.
Now Find Out What’s Burning Your GPU Budget.
GPU utilization, inference cost architecture, fabric constraints, and model serving efficiency — AI infrastructure bills that don’t match what your GPUs are actually producing almost always trace back to architectural decisions made before the cluster was provisioned. The triage session identifies the constraint and the cost model.
AI Infrastructure Audit
Vendor-agnostic review of your AI infrastructure stack — GPU utilization and fabric constraints, inference cost architecture and runtime budgets, training vs inference hardware split, model serving efficiency, and whether your current infrastructure configuration matches your actual workload profile.
- > GPU utilization and fabric constraint diagnosis
- > Inference cost architecture and runtime budget review
- > Training vs inference hardware split validation
- > Model serving efficiency and orchestration review
Architecture Playbooks. Field-Tested Blueprints.
Field-tested blueprints from real AI infrastructure environments — inference cost runaway analysis, GPU cluster fabric failure diagnostics, model serving optimization case studies, and the AI cost architecture patterns that keep production AI systems within budget.
- > AI Inference Cost Architecture & Optimization
- > GPU Cluster Fabric & Utilization Patterns
- > LLM Ops & Model Serving Architecture
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What is AI infrastructure architecture?
A: AI infrastructure architecture is the discipline of designing compute, network, storage, and operations layers specifically for AI workloads — training, inference, and model lifecycle management. It differs from traditional cloud architecture because AI cost is behavioral rather than provisioning-based, AI performance is governed by fabric P99 latency rather than average throughput, and AI operations require runtime controls that standard observability tools cannot provide.
Q: What is the difference between training and inference infrastructure?
A: Training infrastructure is a bounded capital event — large GPU clusters, high-throughput storage, and deterministic fabric for gradient synchronization. Inference infrastructure is continuous operational expenditure — every token and API call adds to the cost, and the cost driver is behavioral, not resource utilization. Running both on shared GPU hardware was practical for early AI deployments; at production scale, the two workloads require separate infrastructure models and separate cost governance.
Q: Why does AI infrastructure fail in production?
A: The most common production failure patterns are fabric-related stalls (P99 latency spikes that halt gradient synchronization during distributed training), storage checkpoint bottlenecks (storage that cannot ingest optimizer checkpoints fast enough, leaving GPUs idle), and inference cost drift (behavioral spend that compounds independently of GPU utilization because no runtime controls exist). None of these are hardware failures — they are architecture failures.
Q: What is an execution budget for AI inference?
A: An execution budget is a runtime constraint that limits how many tokens an agent or workflow can consume, how many model calls it can make, and how many retries it is permitted — enforced at the moment of execution. Execution budgets are the primary mechanism for making inference cost visible and controllable when the cost driver is behavioral rather than provisioning-based.
Q: When does AI infrastructure belong on-premises vs in the cloud?
A: For early-stage AI with unpredictable GPU demand and frequent model iteration, cloud provides on-demand access without capital commitment. The economics shift at approximately 60–70% consistent GPU utilization over a 12–18 month horizon — above that threshold, owned infrastructure typically delivers better price-performance. Data sovereignty requirements and large stable dataset gravity are the other primary drivers of on-premises placement regardless of utilization profile.
Q: What is sovereign AI infrastructure?
A: Sovereign AI infrastructure is a private AI stack designed to operate without external control plane dependency. It requires a local control plane that functions independently of cloud consoles or SaaS identity providers, GPU cluster governance within the sovereign boundary, data residency enforcement at the storage and retrieval layer, and inference serving that does not route through external APIs. Sovereignty in AI is not about where the model runs — it is about whether the control plane can be reached from outside.
Q: How is AI infrastructure cost different from traditional cloud cost?
A: Traditional cloud cost is provisioning-based — you pay for the resources you allocate, and cost scales predictably with utilization. AI inference cost is behavioral — it scales with what your agents decide to do, how many tokens they consume, how often they retry, and how much context they retrieve. GPU utilization can look healthy while inference spend compounds silently through retry storms, RAG pipeline changes, or agentic loop behavior. Standard FinOps tooling cannot see these cost drivers without workflow-level instrumentation.