DISTRIBUTED AI FABRICS
AI DOES NOT SCALE ON COMPUTE. IT SCALES ON THE FABRIC BETWEEN IT.
Distributed AI is not limited by compute. It is limited by how fast memory can be shared across nodes.
When you run a training job across hundreds of GPUs, the model doesn’t live in any one GPU’s memory — it’s reconstructed, synchronized, and updated across all of them on every pass. The network fabric connecting those GPUs isn’t a transport layer. It is the distributed memory bus. When it introduces latency or drops a packet, your GPUs stall, your training slows, and your cost per gradient update climbs. Every architectural decision downstream — topology, protocol, hardware selection — is ultimately a decision about how efficiently that bus operates
Most infrastructure teams approach AI clusters the way they approach general workloads: provision compute, attach networking, configure storage. That sequence works for applications built to tolerate network variance. It fails for distributed AI training because the assumptions are wrong. Gradient synchronization cannot adapt. A single delayed node stalls the entire synchronization cycle. A dropped packet triggers retransmission that amplifies congestion exponentially. The fabric must eliminate variability, not recover from it.
This pillar covers the full distributed AI fabrics stack — physics, protocols, topology, cost, failure modes, and Day 2 operational reality. It covers when you need a purpose-built fabric, which kind, and when standard networking is sufficient. The goal is an architectural framework you can actually use — matched to your cluster size, workload type, team expertise, and budget. For the broader AI infrastructure context this page sits within, see the AI Infrastructure Architecture hub
The AI Fabric Illusion
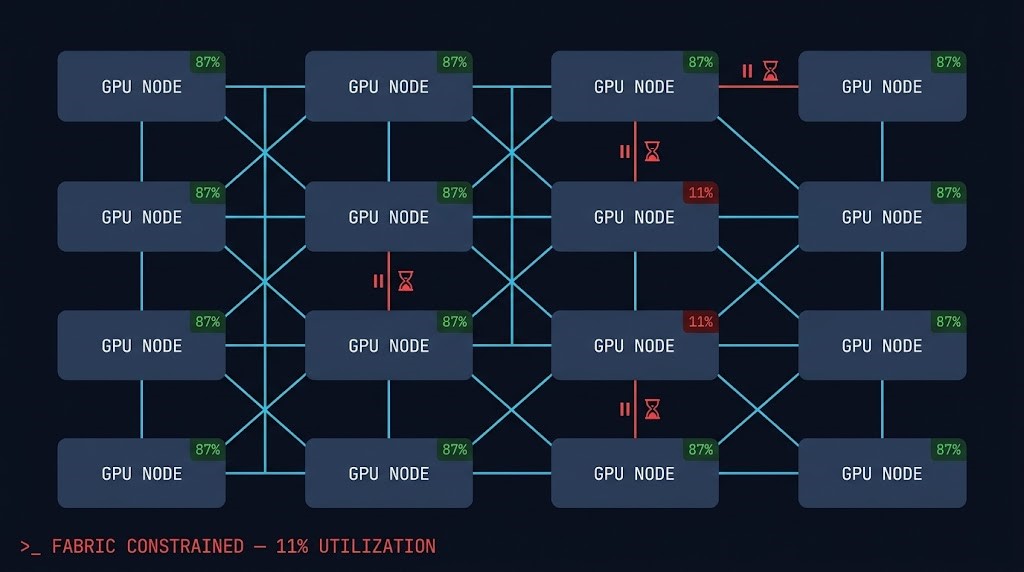
Teams think AI scale is about GPUs. It’s about moving data between GPUs fast enough to matter. Raw FLOPS are only realized when gradient synchronization completes within the synchronization window. A fabric that can’t keep pace converts purchased compute into idle silicon — and you pay for that idle silicon at full price
In clusters beyond 16 nodes, network saturation limits effective scaling before compute saturation does. Adding more GPUs to a fabric-constrained cluster increases cost without increasing throughput. And because P99 latency — not average latency — governs distributed training, a single slow synchronization event sets the pace for the entire cluster. 512 GPUs run at the speed of the slowest one.
Compute capacity is only realized when gradient synchronization completes on time. A slow fabric converts purchased FLOPS into idle silicon — at full hourly cost.
Beyond 16 nodes, fabric saturation limits scaling before compute does. More GPUs on a constrained fabric increases cost without increasing throughput.
Tail latency variance — not average latency — governs distributed training. In a 512-GPU AllReduce, the slowest synchronization event sets the pace for all 512.
The AI Fabric Stack
Distributed AI infrastructure is a layered system where every layer above depends entirely on the layer below. Most teams design top-down — orchestration first, networking as an afterthought. Fabric-constrained clusters are almost always the result. The correct model is bottom-up: the transport layer determines how fast data moves between nodes, and everything above it — protocols, collectives, scheduler decisions — operates within the ceiling that layer sets.
What Makes AI Fabric Different from Enterprise Networking
Enterprise networking is engineered for tolerance. TCP recovers from packet loss, retransmits dropped data, and adapts to congestion through backpressure. These are correct design choices for workloads where individual connections are independent and a delayed packet delays one user — not an entire cluster. Distributed AI training has none of those properties. Every node in an AllReduce is coupled. A delay on one node’s gradient update delays the entire synchronization round. Best-effort networking doesn’t degrade gracefully under training load — it collapses non-linearly.
Traffic pattern is the second structural difference. Enterprise workloads generate North-South traffic. AI training generates almost entirely East-West — simultaneous all-to-all gradient exchanges across every GPU pair. A 256-GPU job doesn’t generate 256 independent flows. It generates an all-to-all pattern where every node is simultaneously sending and receiving gradient data from every other node. Any oversubscription at the aggregation layer becomes an AllReduce bottleneck immediately
Failure semantics are where the real cost lives. A link failure in enterprise networking causes a service degradation. In distributed training, a single link failure or sustained latency spike can invalidate hours of computation. Gradient synchronization requires all participating nodes to complete their exchange before any node advances to the next step. One degraded node holds the entire job. At $50,000/hour cluster cost, network reliability isn’t an availability concern — it’s the primary cost control mechanism.
Training vs Inference: The Fabric Decision Has Split
The distributed AI fabrics question isn’t one question — it’s two. Teams that conflate them overspend on inference infrastructure and underspend on training infrastructure simultaneously. GTC 2026 formalized what architects had been modeling as an abstract choice: training and inference are now separate hardware procurement decisions, each with distinct fabric requirements. For the full breakdown of what that hardware split means for cluster procurement, see the training/inference infrastructure split confirmed at GTC 2026.
The inference side of that split introduces a second architectural layer that the fabric decision doesn’t address: placement orchestration. Dedicated inference silicon distributed across edge nodes, regional racks, and cloud endpoints means routing decisions carry a geographic and cost-per-token dimension that training infrastructure never had. Where inference runs — not just what model runs — is now a first-class infrastructure decision. See Inference Routing Is Becoming an Infrastructure Placement Problem for the placement architecture that sits above the inference fabric layer.
| Dimension | Training | Inference |
|---|---|---|
| Traffic Pattern | All-to-all gradient synchronization — every node to every node, simultaneously | Request/response — user-initiated, independent flows |
| Primary Sensitivity | Latency + bandwidth — both must be deterministic and sustained | Latency + cost — P99 matters for UX, throughput per dollar governs design |
| Fabric Requirement | Extreme — lossless, sub-2µs P99, non-blocking at full bisection | Selective — high-speed Ethernet often sufficient at most scales |
| Coupling | Tightly coupled — one slow node stalls all nodes | Loosely coupled — individual requests are independent |
| Failure Impact | Cluster-wide — one network event can invalidate hours of compute | Request-scoped — failed requests retry independently |
| Verdict | Training requires a fabric. | Inference selectively justifies one. |
InfiniBand Architecture: Where Determinism Still Wins
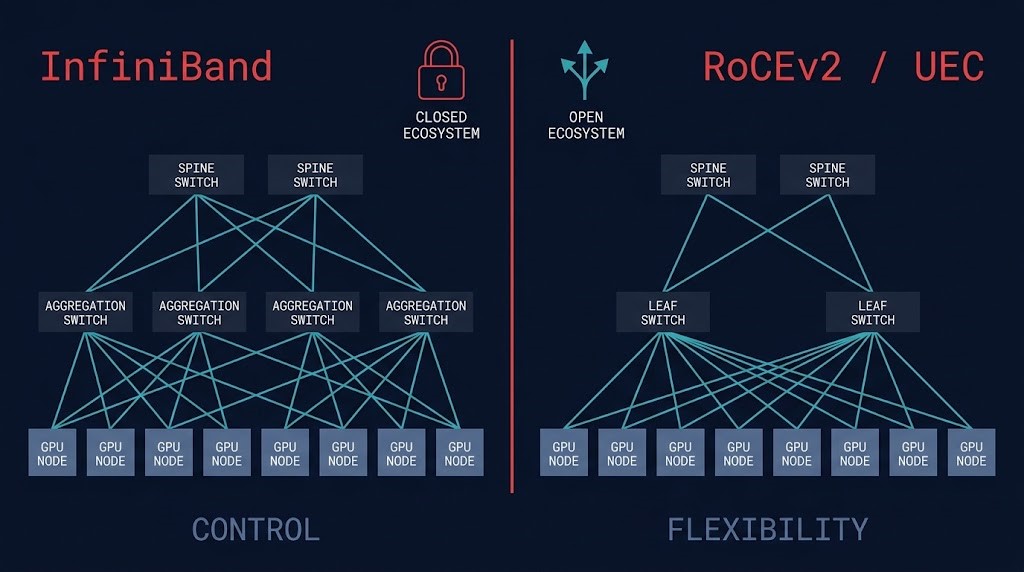
InfiniBand is not faster Ethernet. It is a different network philosophy — a purpose-built interconnect designed from first principles for tightly coupled synchronous compute. Its credit-based flow control operates at the hardware level: a sending node can’t transmit unless the receiving node has confirmed buffer availability. This eliminates packet loss at the source rather than recovering from it downstream. The result is natively lossless behavior, sub-microsecond latency, and native NCCL optimization — the combination that made it the default for HPC and large-scale AI training for nearly two decades.
The architectural case for InfiniBand remains strongest at large-scale dedicated training clusters where deterministic performance is the primary metric and the team has the specialized knowledge to operate it. The NVIDIA GPU stack — H100, InfiniBand NIC, Quantum-2 switch, NCCL — is vertically integrated and tested as a system. That integration delivers real, measurable performance gains on large-scale AllReduce workloads. For the full InfiniBand vs RoCEv2 decision breakdown including the Broadcom 2026 deployment data, see the InfiniBand vs RoCEv2 analysis.
The counterargument is architectural, not performative. InfiniBand’s integration is also its constraint. Selecting InfiniBand for the GPU fabric means simultaneously selecting NVIDIA NICs, NVIDIA switches, and a management plane that doesn’t interoperate cleanly with non-NVIDIA hardware. For organizations with multi-vendor GPU roadmaps, sovereign data requirements, or mixed accelerator plans, the tightly coupled stack creates dependencies that outlast any individual hardware generation. The question isn’t whether InfiniBand performs — it does. The question is what you’re committing to beyond the fabric itself.
RoCEv2 and the Ethernet Path: Control vs Flexibility
This is not a protocol choice. It is a bet on control versus flexibility. RoCEv2 brings RDMA semantics to standard Ethernet — kernel bypass, zero-copy data movement, CPU offload — without the closed ecosystem dependency. The hyperscalers moved first and decisively: AWS, Google, and Microsoft have all built their AI backend fabrics on Ethernet-based architectures. Broadcom’s Q1 2026 data confirmed approximately 70% of new AI deployments are selecting Ethernet-based fabric. That number isn’t a market trend — it’s the hyperscaler infrastructure bet becoming the industry default
The Ultra Ethernet Consortium is the structural signal behind that data. Backed by AMD, Broadcom, Cisco, HPE, Intel, Meta, and Microsoft, the UEC is engineering InfiniBand’s native capabilities — in-sequence delivery, congestion control, multipath routing — directly into the Ethernet standard. The performance gap is closing from below. For the full analysis of why Ethernet is winning and what the UEC roadmap means for private cluster procurement, see the InfiniBand vs RoCEv2 breakdown published in March 2026.
The honest caveat is operational. RoCEv2 requires Priority Flow Control (PFC) and Explicit Congestion Notification (ECN) configured correctly at every switch to simulate the lossless behavior InfiniBand delivers natively. Misconfigured PFC produces pause storms — a congestion cascade where a single overloaded port triggers pause frames that propagate fabric-wide, halting throughput within seconds. A misconfigured RoCEv2 fabric isn’t merely worse than InfiniBand — it actively destroys training job stability. RoCEv2 offers flexibility. That flexibility must be staffed accordingly.
RDMA and GPUDirect: The Physics of Zero-Copy at Scale
Without RDMA, moving gradient data between GPU nodes requires traversing GPU memory → CPU → kernel → network stack → wire → kernel → CPU → destination GPU. Each transition adds latency and consumes CPU cycles. At 100GB/s fabric speeds, the CPU simply can’t process data movement fast enough to keep the network saturated. RDMA eliminates the CPU from the data path entirely — the NIC reads directly from memory and writes directly to remote memory, bypassing the kernel on both ends. The result: consistent sub-microsecond latency with near-zero CPU overhead. For the deterministic networking physics that underpin this, see the deterministic networking for AI infrastructure analysis.
GPUDirect RDMA extends this further by allowing the NIC to read directly from GPU HBM — bypassing system RAM entirely. This eliminates the GPU-to-system-RAM copy, reducing transfer latency by another 30–40% and removing a significant source of memory bandwidth contention. The cost connection is direct: faster gradient synchronization means fewer idle GPU cycles per training step, which means lower cost per gradient update across the full training run. Every architectural decision that reduces RDMA latency has a measurable dollar value at sustained training scale.
Topology: What Your Cluster Size Actually Dictates
Fabric topology isn’t an aesthetic choice — it’s a mathematical constraint derived from cluster size, traffic pattern, and bisection bandwidth requirements. The wrong topology for your cluster scale produces a fabric-constrained environment regardless of how good the underlying hardware is
Standard for Mid-Scale Training
Three-tier spine-leaf-access. Non-blocking bisection when correctly provisioned. Well-understood operationally. The default from 64 to ~4,000 GPUs. Spine switches become cost-dominant at large scale.
NVIDIA’s Architecture for GPU-Dense Nodes
Separates intra-node (NVLink/NVSwitch) from inter-node fabric. Each GPU connects to a dedicated switch rail — ensuring intra-node traffic never competes with inter-node AllReduce bandwidth. Dominant in H100/H200 NVL designs.
Hyperscale — When Cost-per-Port Is the Constraint
Groups of fully-connected switches joined by inter-group links. Reduces switch and cable count at scale vs fat-tree. Adaptive routing mandatory to avoid hotspots. For why 800G still fails at 100k-GPU scale, see the GPU fabric physics analysis.
Cost Physics of Distributed AI Fabrics
The most expensive GPU cluster is the one waiting on the network. A 256-GPU cluster running at 40% effective utilization due to fabric-induced synchronization stalls is generating 60% idle GPU cost. The fabric investment that brings utilization from 40% to 85% — better interconnects, corrected PFC/ECN thresholds, added buffer capacity — pays for itself in recovered compute time. Most fabric upgrade decisions become obvious once the math is written down. For the broader cost architecture of AI inference workloads, the AI inference cost architecture post maps the full cost structure.
InfiniBand carries a real hardware premium over Ethernet at equivalent port speeds. That premium is frequently justified at large-scale dedicated training clusters — deterministic fabric performance delivers GPU utilization numbers that close the cost gap through recovered compute time. It breaks down in two cases: clusters under 64 GPUs where the performance gap doesn’t materialize at workload scale, and inference clusters where InfiniBand’s all-to-all optimization provides no benefit over standard high-speed Ethernet. Over-specifying fabric for inference is one of the most common and expensive mistakes in AI infrastructure planning.
The failure cost is the most underestimated line item. A training job that fails due to a network event loses all computation since the last checkpoint. On a cluster burning $50,000/hour with 15-minute checkpoints, a single network-induced failure during a 6-hour run can cost over $450,000 in unrecovered compute. Job checkpointing isn’t an operational nicety — it’s a fabric failure cost mitigation strategy.
AI Fabric Failure Modes: From Degradation to Collapse
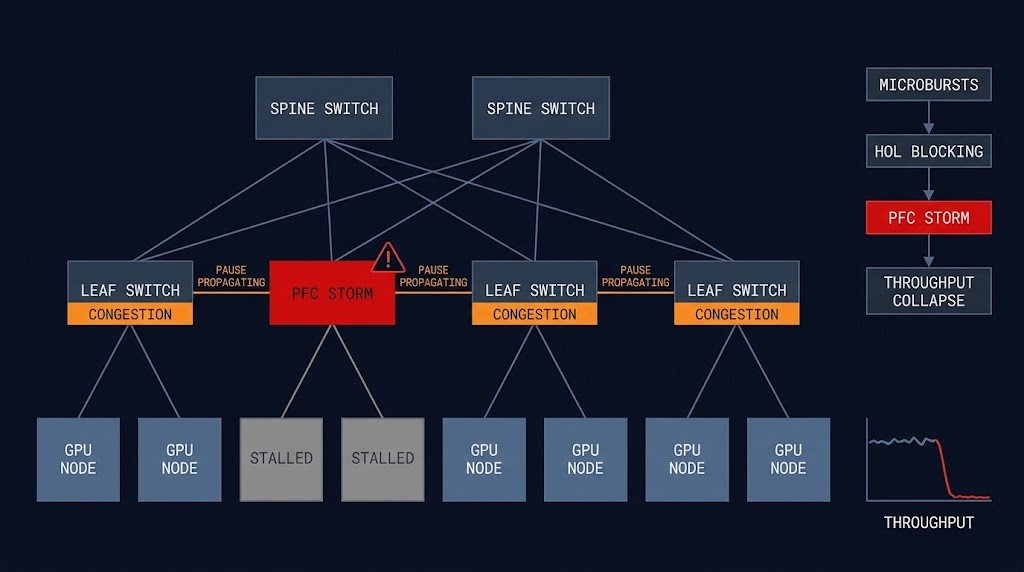
AI fabric failures present as performance degradation rather than connectivity loss. They’re often silent at the monitoring layer while causing significant training slowdown. Standard bandwidth metrics show healthy utilization while training throughput collapses. Understanding the failure progression is prerequisite to designing a fabric that can actually be operated in production.
Short-duration traffic spikes exceeding switch buffer capacity during AllReduce peaks. Undetectable in average metrics — manifest as subtle P99 latency increases. At 512 GPUs, a 5µs increase per round compounds to visible training slowdown within hours.
A single congested flow at the head of a switch queue blocks all flows behind it regardless of their destination. One delayed gradient flow blocks subsequent flows destined for healthy nodes. GPU utilization drops cluster-wide from a single link’s congestion event — while monitoring reports clean link utilization.
PFC pause frames designed to prevent buffer overflow propagate backwards through the fabric when a congested port continuously issues them. Upstream switches receive pause signals and issue their own. The cascade spreads hop-by-hop until a majority of fabric traffic is paused from a single downstream event. Detection requires per-port PFC counter monitoring — invisible in standard bandwidth dashboards.
Buffer exhaustion triggers packet drops at line rate. On RDMA, drops require connection-level recovery — the RDMA connection re-establishes, pending operations retry, the gradient synchronization round restarts. From the training job’s perspective the cluster appears to be running. GPU utilization shows non-zero values. Training progress has stopped. The first visible signal is often a loss curve that stops moving — by which point significant compute cost has already been wasted. This failure mode is the architectural argument for dedicated AI fabric observability tooling, not general network monitoring.
Operating AI Fabrics in Production: Day 2 Reality
Designing the fabric is hard. Operating it is harder. The performance characteristics of a distributed AI fabric are not static properties of the hardware — they’re the emergent result of continuous configuration management, firmware alignment, and operational discipline. Most organizations that deploy high-performance AI fabrics at scale spend more engineering time on Day 2 operations than on the initial design.
PFC and ECN tuning is the highest-leverage operational task on a RoCEv2 fabric. PFC pause thresholds must be calibrated to the buffer depth of each switch — too low and legitimate traffic triggers unnecessary pauses, too high and the pause signal arrives after buffer overflow has already occurred. ECN marking thresholds need to reflect the load levels typical of your training workloads, not vendor defaults calibrated for general data center traffic. These are not set-once configurations. They require re-evaluation whenever cluster density changes or training job sizes scale significantly.
Firmware and driver alignment is the failure mode teams discover late. The performance stack — GPU driver, CUDA, NCCL, RDMA NIC firmware, switch firmware — has specific compatibility matrices that aren’t always clearly documented by any single vendor. A NCCL update that improves AllReduce performance may expose a bug in older NIC firmware. A switch firmware update that fixes a PFC storm bug may introduce an ECN regression. AI fabric operations requires treating the full stack as a system with tested upgrade paths — not independent components on independent schedules. The AI inference cost series covers what to track at the model layer before the bill arrives — fabric observability is its infrastructure counterpart.
Sovereign and Private Cluster Fabric Design
Private and sovereign AI cluster fabric design introduces constraints that hyperscaler architectures don’t face. When training data can’t leave a controlled perimeter — for regulatory compliance, data sovereignty, or competitive sensitivity — the fabric must operate without cloud-based management planes, vendor telemetry callbacks, or external licensing dependencies. For the full architecture of sovereign AI infrastructure and the control plane independence requirements fabric design must satisfy, see the sovereign AI on private infrastructure analysis.
Fabric hardware selection for private clusters carries an additional dimension: supply chain and long-term supportability. InfiniBand’s NVIDIA dependency becomes a concentration risk in sovereign deployments where procurement flexibility matters. RoCEv2 over standard Ethernet — with qualified vendors including Arista, Cisco, and Juniper — provides procurement flexibility InfiniBand cannot. For air-gapped environments, InfiniBand Subnet Managers must run fully on-premises without UFM cloud connectivity, and Ethernet fabric management must operate without vendor cloud dashboards. Both are achievable, but they require deliberate configuration to eliminate external dependencies that the default tooling assumes.
When Distributed AI Fabric Is the Right Call
16+ GPU clusters running foundation model training or large-scale fine-tuning with synchronous gradient exchange. The all-to-all communication pattern requires lossless, sub-2µs P99 fabric to sustain GPU utilization above 80%. This is where fabric investment directly determines cost per trained model.
On-premises or sovereign AI infrastructure where cloud GPU rental economics don’t apply and training jobs run continuously. At sustained cluster utilization above 60%, the fabric investment pays back through recovered compute time faster than the capital cost of cloud GPU alternatives.
Molecular dynamics, climate modeling, CFD simulations — any workload where collective communication patterns require synchronous all-to-all data exchange. The same fabric physics that govern AI training govern HPC collectives. The architectural requirements are identical.
Once training jobs span multiple racks, inter-rack latency becomes the synchronization bottleneck. NVLink handles intra-node. NVSwitch handles intra-rack. The inter-rack fabric is where InfiniBand or RoCEv2 earns its cost — and where standard Ethernet’s limitations first become measurable.
When to Consider Alternatives
At 8 GPUs or fewer, NVLink intra-node bandwidth dominates. AllReduce is primarily intra-node and inter-node fabric carries only a fraction of gradient traffic. High-speed 100G Ethernet is sufficient. InfiniBand or RoCEv2 RDMA adds cost without meaningful performance benefit at this scale.
Inference traffic is request/response. Individual requests are independent — a slow response doesn’t stall other requests. High-speed Ethernet (100G–400G) is appropriate for most inference deployments. Deploying InfiniBand for inference is over-engineering that doesn’t recover its cost premium in performance gains.
Fine-tuning on pre-trained models with small batch sizes, embedding generation pipelines, and preprocessing workloads generate loosely coupled compute patterns that tolerate network variance. If jobs don’t require synchronous gradient exchange across many nodes, the strict requirements of a dedicated AI fabric don’t apply.
RoCEv2 requires deep expertise in PFC/ECN configuration, congestion debugging, and fabric-specific monitoring. InfiniBand requires HPC networking specialists. If neither is available, a well-configured high-speed Ethernet fabric operated by a competent network team will outperform a misconfigured InfiniBand or RoCEv2 deployment every time.
The Distributed AI Fabric Decision Framework
The fabric decision is a cluster-characterization exercise. Your workload type, cluster scale, and team operational expertise jointly determine the viable options. For a complete cluster architecture reference covering hardware stack selection from GPU through storage, see the GPU cluster architecture for private LLM training guide and the H100 cluster operations guide.
| Cluster Scale | Workload Type | Team Expertise | Recommended Fabric |
|---|---|---|---|
| <8 GPUs | Training or inference | Any | Standard 100G Ethernet — NVLink dominates, inter-node fabric is not the constraint |
| 16–64 GPUs | Active training | Ethernet ops team | RoCEv2 over 200G/400G Ethernet with PFC/ECN tuning — performance gain justifies complexity |
| 64–1,000 GPUs | Sustained training | Specialized AI/HPC networking team | InfiniBand HDR/NDR or RoCEv2 — IB if operational simplicity preferred; RoCEv2 if team expertise is present |
| 1,000+ GPUs | Foundation model training | Dedicated fabric engineering team | InfiniBand NDR (NVIDIA-committed) or RoCEv2 with UEC-compliant hardware — team expertise and vendor strategy determine the call |
| Any scale | Inference only | Any | High-speed Ethernet (100G–400G) — dedicated AI fabric is over-engineering for request/response |
| Any scale | Sovereign / air-gapped | Any | RoCEv2 preferred for procurement flexibility — IB viable if NVIDIA-only stack is acceptable |
The fabric is the network backplane. The pages below cover what runs on top of it — inference architecture, model operations, and retrieval — and what sits below it in the silicon layer.
Architect’s Verdict
The distributed AI fabrics decision is not a technology selection. It’s a cluster characterization exercise — and most teams get it wrong by starting with vendor literature rather than workload physics. Define the workload type first. Determine the cluster scale. Assess team operational capacity. Only then does the fabric choice become tractable. Teams that open with InfiniBand vs RoCEv2 have already skipped the steps that make the answer obvious
The industry direction is clear. Ethernet-based RDMA is becoming the default for new AI infrastructure at every scale outside of NVIDIA-committed, large-scale dedicated training clusters. The UEC is closing the performance gap systematically. The hyperscalers have voted with their infrastructure spend. For most organizations building private AI clusters in 2026 — particularly those with multi-vendor GPU roadmaps, sovereign data requirements, or Ethernet-trained ops teams — RoCEv2 is the architecturally sound default. The caveat is real: RoCEv2 requires disciplined PFC/ECN configuration and fabric-specific monitoring. Understaffed operations teams should weigh InfiniBand’s operational simplicity seriously before committing to RoCEv2’s flexibility.
The most expensive mistake in distributed AI fabric design isn’t choosing the wrong protocol. It’s treating the fabric as infrastructure plumbing rather than the primary performance constraint of the entire cluster. GPU utilization, training throughput, cost per training run, and job reliability are all direct functions of fabric quality. The fabric is not where you cut the budget. It’s the architectural layer that determines whether your GPU investment is productive or idle. Design it first.
You’ve Chosen the Fabric.
Now Validate It Won’t Stall Your Training Jobs.
PFC/ECN configuration, topology selection, RDMA NIC alignment, and congestion management — distributed AI fabric decisions that look correct in procurement stall training jobs in production. The triage session validates whether your fabric architecture can actually sustain the AllReduce bandwidth your cluster requires.
AI Fabric Architecture Audit
Vendor-agnostic review of your distributed AI fabric — InfiniBand vs RoCEv2 decision validation, PFC/ECN configuration correctness, topology selection against your cluster scale, RDMA NIC and switch firmware alignment, and the congestion management gaps that silently degrade GPU utilization.
- > InfiniBand vs RoCEv2 decision validation
- > PFC/ECN configuration and congestion management audit
- > Topology selection and bisection bandwidth review
- > RDMA and GPUDirect configuration validation
Architecture Playbooks. Every Week.
Field-tested blueprints from real AI fabric deployments — PFC storm incident analysis, InfiniBand vs RoCEv2 production comparisons, GPU cluster AllReduce performance diagnostics, and the fabric operational patterns that keep distributed training jobs running at full GPU utilization.
- > AI Fabric Architecture & Failure Mode Analysis
- > InfiniBand vs RoCEv2 Production Comparisons
- > GPU Cluster Utilization & Cost Architecture
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What is a distributed AI fabric and why does it matter?
A: A distributed AI fabric is the high-speed interconnect layer that connects GPU nodes in a training cluster, enabling the synchronous gradient exchange required for distributed training. It matters because the fabric — not the GPUs — is typically the primary performance constraint in multi-node AI training. A fabric-constrained cluster can have GPU utilization as low as 40–60%, meaning you’re paying for compute you’re not using. The fabric determines whether your GPU investment is productive or idle.
Q: What is the difference between InfiniBand and RoCEv2 for AI training?
A: InfiniBand is a purpose-built, natively lossless interconnect with hardware-level flow control, sub-microsecond latency, and native NCCL optimization. It delivers deterministic performance at large scale but requires a closed NVIDIA ecosystem. RoCEv2 brings RDMA semantics to standard Ethernet — kernel bypass, zero-copy, CPU offload — with multi-vendor hardware flexibility, but requires careful PFC and ECN configuration to simulate the lossless behavior InfiniBand delivers natively. InfiniBand is a bet on control. RoCEv2 is a bet on flexibility. Broadcom’s Q1 2026 data shows approximately 70% of new AI deployments selecting Ethernet-based fabric — the hyperscaler direction is clear.
Q: Do I need a dedicated AI fabric for inference workloads?
A: No, for most inference deployments. Inference traffic is request/response — individual requests are independent and a slow response doesn’t stall other requests. High-speed Ethernet (100G–400G depending on throughput requirements) is appropriate for most inference clusters. Tensor parallelism in very large model inference creates some inter-GPU communication, but at a fraction of the intensity of training AllReduce patterns. Deploying InfiniBand for inference is over-engineering that doesn’t recover its cost premium in performance gains.
Q: What is a PFC storm and how does it affect AI training clusters?
A: A PFC (Priority Flow Control) storm occurs when a congested switch port continuously issues pause frames to prevent buffer overflow. Those pause signals propagate backwards through the fabric — upstream switches receive the pause and issue their own pause frames, which propagate further upstream. Within seconds, a majority of fabric traffic can be paused from a single downstream congestion event. On RoCEv2 fabrics, a PFC storm can halt most cluster traffic and present as a cluster-wide training stall with no obvious cause in standard bandwidth monitoring. Detection requires per-port PFC counter monitoring. Prevention requires correctly calibrated PFC thresholds for your specific switch buffer depths.
Q: At what cluster size does dedicated AI fabric investment start making sense?
A: The crossover point is typically 16–32 GPUs, depending on model size and training job pattern. Under 8 GPUs, NVLink intra-node bandwidth dominates and inter-node fabric carries only a fraction of gradient traffic — standard 100G Ethernet is sufficient. From 16 GPUs onward, inter-node AllReduce communication becomes the scaling constraint and RoCEv2 or InfiniBand begins delivering measurable utilization improvements. By 64 GPUs running sustained training workloads, the GPU idle cost from a suboptimal fabric typically exceeds the cost of a proper fabric investment within a few months of operation.
Q: What is GPUDirect RDMA and why does it matter for distributed training?
A: GPUDirect RDMA allows a network interface card to read directly from GPU HBM (high-bandwidth memory), bypassing system RAM entirely. In a standard RDMA transfer, data moves from GPU HBM to system RAM, then to the NIC. GPUDirect eliminates the GPU-to-system-RAM copy, reducing transfer latency by 30–40% and removing a significant source of memory bandwidth contention. The practical outcome is direct GPU-to-GPU data movement across the fabric with latency approaching NVLink intra-node speeds on inter-node transfers. At H100 NVL density, GPUDirect RDMA is not an optimization — it is a prerequisite for sustaining the AllReduce bandwidth required for large-scale training.
Q: How should AI fabric design differ for sovereign or air-gapped deployments?
A: Sovereign and air-gapped AI clusters require fabric architectures that operate without cloud-based management planes, vendor telemetry callbacks, or external licensing dependencies. This affects hardware selection: InfiniBand Subnet Managers must run fully on-premises without UFM cloud connectivity, and the default NVIDIA management tooling assumes external connectivity that must be deliberately eliminated. RoCEv2 over standard Ethernet — with multi-vendor switch options from Arista, Cisco, or Juniper — provides procurement flexibility and management plane independence that InfiniBand cannot match. For regulated environments, RoCEv2 is typically the architecturally safer default unless the NVIDIA InfiniBand stack has been explicitly evaluated and cleared for the sovereignty requirements.
The fabric is one layer. The pages below cover what sits beside it — GPU orchestration, inference cost architecture, model deployment, and the broader AI infrastructure disciplines that determine how the full stack performs.