LLM Ops vs. DevOps: Managing the Lifecycle of Generative Models in Production

The incident ticket looked fine.
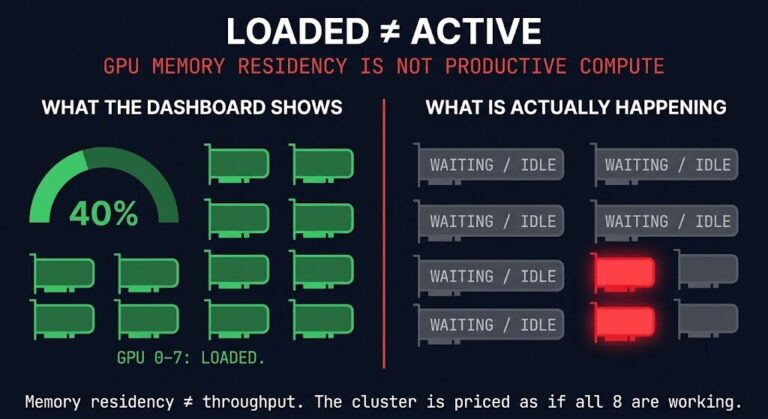
- CPU: 40% (Healthy)
- Latency: 250ms (p95)
- Error Rate: 0.01%
- Uptime: 99.99%
For years, every dashboard told us the same thing: the system was flawless.
But the support queue told a different story. Suddenly, the chatbot was handing out 90% discounts that didn’t even exist.
No crashes, no slowdowns, and no error messages.
It was just… wrong.
We checked everything. The model hash matched the release. The vector index checksum lined up with the snapshot. Retrieval latency hadn’t budged in a month. We even redeployed the same container twice before it hit us: the container isn’t the whole system.
Here’s the real problem with AI engineering: we’re using tools built for predictable systems, but AI doesn’t play by those rules.
The Big Shift: From Execution to Decision
DevOps is all about making sure things run the same way, every time.
In a deterministic system, if you send the same request, you always get the same answer. If you don’t, something’s broken.
But LLMs aren’t like that.
Probabilistic systems don’t promise the same answer every time—they promise an answer that’s good enough.
It’s not just input and output anymore. It is :
Input + Weights + Context + Temperature → Outcome DistributionAll mixing together to produce a range of possible replies.
You can have a system that’s healthy, fast, and still totally wrong. You’re not just versioning code. You’re juggling prompt formats, retrieval databases, model parameters, and user quirks.
Running an LLM in production? It’s more like wrangling a distributed database than spinning up a typical API.
Why Containers Don’t Save You
Containers lock down execution. LLMs depend on information.
A container snapshot nails down the code, the runtime, all the dependencies. But it doesn’t guarantee what the model knows or how it ranks answers.
You can perfectly replay the runtime and still get a different answer. That’s where DevOps ends and LLM Ops begins — and where agentic systems introduce an entirely new governance problem on top of it.
Five New Headaches in Production
1. Behavioral Drift — The Silent Outage
With regular systems, code doesn’t change unless you ship something new. LLMs? They can start acting differently out of nowhere. New docs in your database, users asking questions a new way, context windows colliding, ranking tweaks, randomness in sampling—it all adds up.
You’re not watching uptime anymore. You’re watching meaning itself.
2. Dataset Versioning Is Schema Migration
In regular software, code is king. In AI, data is the program.
Swap out the embedding model or tweak preprocessing, and the whole vector space shifts. Suddenly, nearest neighbors aren’t so near—even if the original documents didn’t change. Re-embedding is basically a database migration.
This isn’t just about deployment risk. It’s about the risk of the system itself mutating under your feet. This is why you need a Logic Gap for your training data—to ensure you can always revert to a clean state.
3. Evaluation Pipelines Replace Test Suites
Old-school testing? You check if the response matches what you expected
assert response == expected
LLM testing? You score the answer and see if it’s “good enough.”
score(response) ≥ acceptable_threshold
Two answers might both be “correct” but mean very different things in practice. If your support bot says “refund may be possible” instead of “refund approved,” that’s not just a wording change—that’s a financial decision.
Production LLMs need golden datasets, adversarial prompts, judge models, regression scoring. If you’re not constantly evaluating, you’re not really deploying software—you’re just sampling from possible behaviors.
4. Rollbacks Take Days, Not Seconds
With containers, rolling back is easy. Just swap to the last image.
With LLMs, rollback means rebuilding the whole state. You have to restore vector snapshots, ingestion queues, caches, conversation memories, even reinforcement signals. And once bad behavior slips into your logs and training data, there’s no simple undo button. Now it’s not rollback—it’s recovery. It’s also why the boundary governing what reaches the model in the first place matters as much as the recovery plan — a problem covered in depth in Kubernetes Is Not an LLM Security Boundary.
5. Semantic Observability
Traditional monitoring checks if the system’s up and running. LLM monitoring asks, “Is the system making the right decisions?”
- Old metrics: p95 latency, error rates, CPU usage, throughput.
- New metrics: hallucination rate, policy violations, grounding scores, intent resolution.
One tells you if the system’s alive. The other tells you if it’s thinking straight.
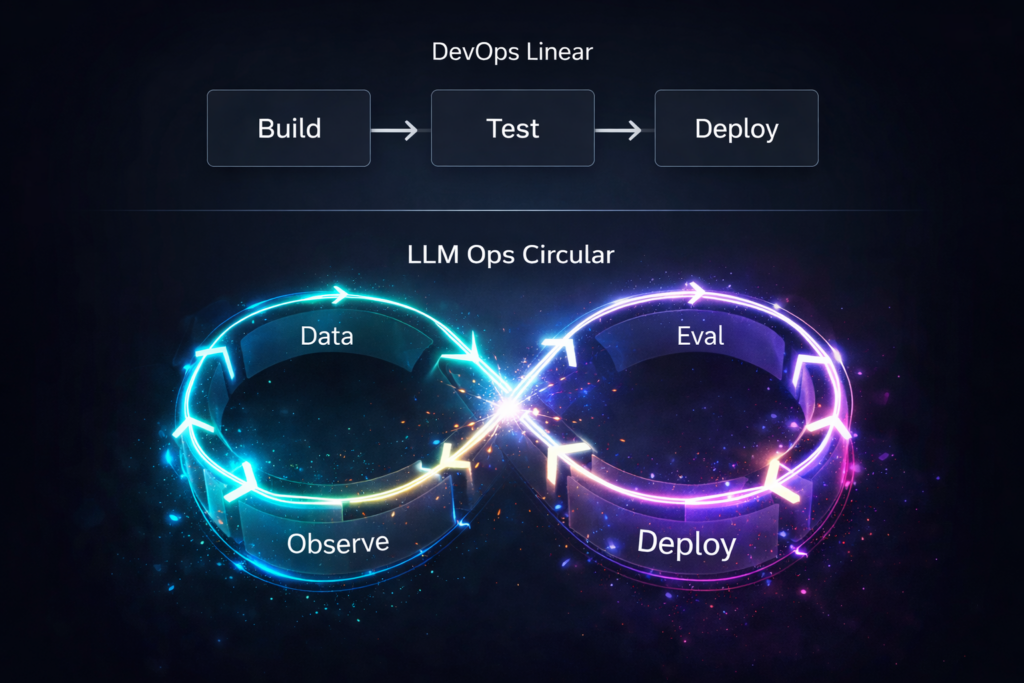
The LLM Lifecycle
- DevOps goes:
Build → Test → Deploy → Monitor
- LLM Ops looks more like:
Data → Train → Evaluate → Deploy → Observe → Feedback → Retrain
↑ continuous loop ↑
Deployment isn’t the end. It’s just the beginning of watching your system evolve.
What This Means for Infrastructure
The model is unpredictable. The infrastructure can’t be. Reliability depends on being able to reproduce everything, down to the tiniest detail.
Reproducibility Layer
If you ever need to explain a weird answer months later, you’ll need the model hash, prompt version, retrieval snapshot ID, sampling parameters, preprocessing version—all of it. Without that, you can’t audit anything.
Storage Is Now About Time
You’re not just storing files. You’re storing history.
You need point-in-time vector snapshots, dataset lineage, evaluation playback, and the ability to rebuild deterministically. These AI platforms? They’re not just about compute anymore. They’re about tracking every moment in time.
The Verdict: The New Reliability Split
Over the next decade, reliability engineering separates into two domains:
| Discipline | Guarantees |
| DevOps | Execution correctness |
| LLM Ops | Decision correctness |
DevOps solved whether software runs. LLM Ops exists because now it must also reason acceptably. Generative AI isn’t magic. It’s a system where correctness is no longer binary—and that changes everything.
“The hard problem is no longer deployment. The hard problem is preserving behavior.”

Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session