Cost-Aware Model Routing in Production: Why Every Request Shouldn’t Hit Your Best Model

- → Part 1: AI Inference Is the New Egress: The Cost Layer Nobody Modeled [Live]
- → Part 2: Your AI System Doesn’t Have a Cost Problem. It Has No Runtime Limits. [Live]
- → Part 3: Cost-Aware Model Routing in Production: Why Every Request Shouldn’t Hit Your Best Model [You are here]
- → Part 4: Inference Observability — What to Track Before the Bill Arrives [Coming soon]
Your system isn’t expensive because your models are expensive.
It’s expensive because every request defaults to the most capable model you have.
That’s not a cost problem. That’s a routing problem. And most systems don’t have a routing layer at all.
Parts 1 and 2 of this series established why inference cost emerges from behavior, not provisioning, and why execution budgets are the enforcement mechanism that dashboards and alerts can never be. Part 3 is the decision layer that sits upstream of both: model routing. The control that determines which model handles each request — and why getting that wrong is the most expensive architectural default in production AI systems today.
The Missing Layer
Every inference request is an implicit classification problem: How much intelligence does this request actually require?
Most architectures never answer that question. There is no decision layer between request and model. A request arrives. The model handles it. The model is always the same model — your best one, your most capable one, your most expensive one. A simple keyword lookup gets the same compute as a multi-step reasoning task. A yes/no validation call gets the same token budget as a complex synthesis. The architecture has no mechanism to distinguish them, so it doesn’t.
This is the gap that model routing closes. Not by using cheaper models — but by using the right model for each request, determined at runtime, before the inference call is made.
Execution budgets from Part 2 control how much a system can run. Routing controls what it runs on. These are complementary controls. Neither substitutes for the other.
Routing Is A Classification Problem
Model selection is not a deployment decision. It is a runtime decision — a classification problem your architecture needs to solve for every request, continuously, at production scale.
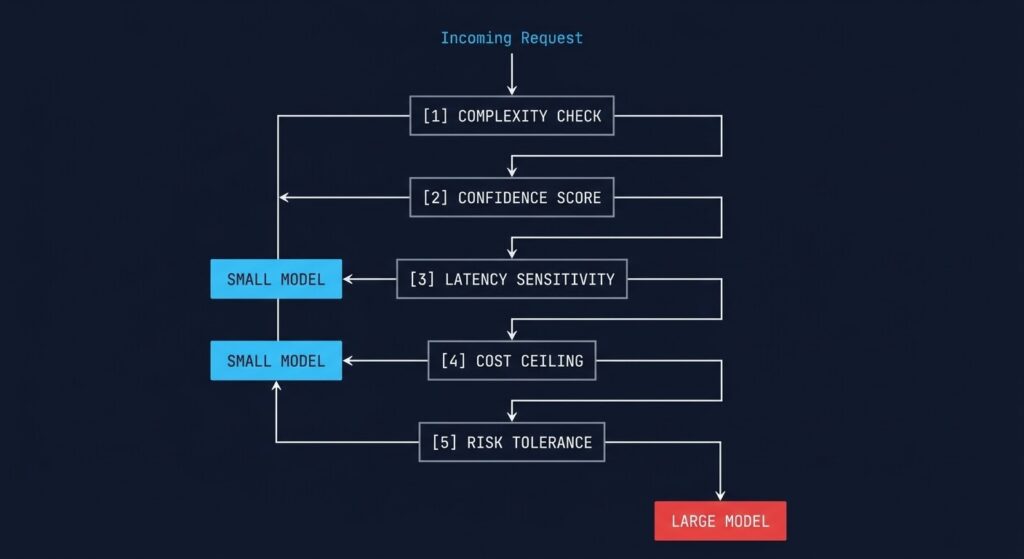
The routing classifier evaluates each request across five dimensions before an inference call is made:
Token count, query depth, ambiguity signal. A short, well-formed lookup with bounded context is not the same problem as an open-ended synthesis with multiple constraints. Complexity is measurable before the model sees the request. Route on it.
If a smaller model can handle this request with high confidence, escalation is waste. Confidence scoring — running a lightweight classifier before the primary model — is one of the most effective cost controls in production routing systems. When the small model is confident, it runs. When it isn’t, it escalates. The drift risk lives here: a routing system that cannot distinguish confident from uncertain outputs will silently degrade quality over time without surfacing any signal.
A real-time user-facing response and an overnight batch processing pipeline have completely different cost tolerances. Real-time paths may require faster, smaller models even at quality trade-off. Async pipelines can absorb a larger model’s latency without UX impact. Routing that ignores latency sensitivity will either over-optimize cost at the expense of UX, or under-optimize cost on workloads that never needed the premium model in the first place.
Per-request, per-session, and per-workflow budget caps — the enforcement architecture from Part 2 — feed directly into the routing decision. If a session is approaching its cost ceiling, the routing layer should shift toward smaller models regardless of complexity. The budget is a first-class routing input, not an afterthought.
User-facing responses carry different correctness requirements than internal pipeline steps. A customer-visible output demands higher accuracy; an intermediate classification step in a batch workflow may tolerate lower precision in exchange for lower cost. Speed, correctness, and cost form a trade-off triangle — routing is the mechanism that resolves it per request, not once at deployment time.
Routing Patterns
These are not optimizations. These are decision strategies.
Attempt with the smallest viable model. Escalate only on low confidence or failure. Default pattern for cost reduction.
Lightweight classifier scores the request before the primary model sees it. Route based on the score.
Different models for different task types: retrieval, reasoning, formatting, validation. Each model sized for its task, not the hardest possible task.
Run a small model first to filter or classify. Only pass qualified requests to the expensive model. Cuts cost on high-volume pipelines without changing output quality on the cases that matter.
Infrastructure Patterns
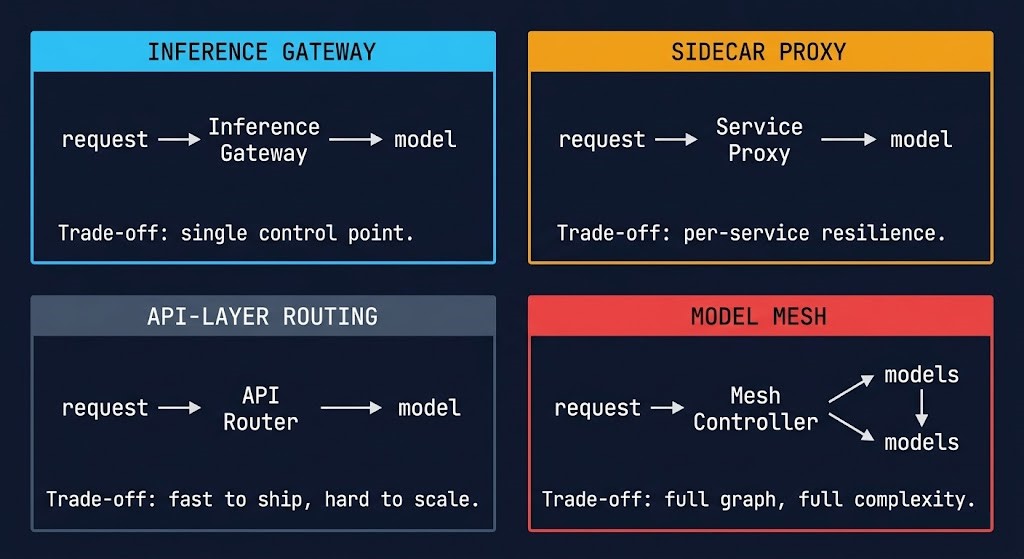
Routing logic needs a place to live. Four infrastructure patterns cover most production deployments, trading control granularity against operational complexity:
Centralized routing at a single control point. All inference requests pass through the gateway before reaching any model. Easiest to instrument, easiest to enforce policy changes globally, highest blast radius if it fails. The right pattern for organizations that want unified routing policy across all workloads.
Per-service routing deployed alongside each inference-consuming service. Integrates naturally with Kubernetes service mesh patterns. More resilient than a centralized gateway — a sidecar failure affects one service, not all of them. Higher operational overhead to maintain routing policy consistency across multiple sidecars.
Routing logic embedded directly in application code at the API call layer. Quick to implement, no additional infrastructure. Limited observability — routing decisions are scattered across codebases rather than centralized. Appropriate for early-stage systems. Becomes a liability at scale when routing policy needs to change across dozens of services.
Full routing graph — every model is a node, every routing decision is a traversal. Maximum control and observability. Highest operational complexity. Fabric performance directly affects routing chain latency; deterministic networking becomes a hard requirement at this layer, and fabric choice has measurable cost and latency implications when routing chains cross nodes.
One rule applies to all four patterns: a routing decision made after inference is not control. It’s accounting. Routing that evaluates which model should have handled a request is post-hoc analysis dressed as architecture. The decision must intercept the request before the inference call.
Where It Breaks
Routing systems don’t fail loudly. They fail silently — and expensively.
Misclassification
The routing classifier sends a request to a small model when it needed a large one. Quality drops. The system is technically working — requests are being handled, responses are being returned, no errors are being logged. No alert fires because the system is technically “working.” The degradation is invisible until someone reviews output quality and traces it back to routing decisions made weeks earlier.
Over-Escalation
The routing layer exists but the classifier is too conservative — it escalates almost everything to the expensive model because the cost of a wrong downgrade feels higher than the cost of unnecessary escalation. The system looks correct. The bill says otherwise. Routing exists but saves nothing because the decision threshold was never calibrated against actual quality data.
Latency Amplification
Multi-hop routing chains — request hits classifier, classifier hits pre-screen model, pre-screen escalates to primary model — add cumulative round-trip latency. The cost of latency is real: slower user-facing responses degrade retention, increase retry rates, and generate secondary inference calls from the retry behavior. The routing optimization designed to reduce spend creates a different cost category.
Feedback Loops
A routing system that learns from its own decisions — adjusting thresholds based on observed outcomes — can reinforce bad routing patterns if the signal it learns from is noisy or misaligned. The system optimizes itself into worse decisions. Classifier accuracy degrades over time. Cost creeps up. Quality drifts. And because the system is “learning,” the degradation looks like improvement from the inside.
Observability Gap
If you cannot explain why a model was chosen, you do not control cost. No visibility into routing decisions means no ability to audit misclassification, calibrate escalation thresholds, or detect feedback loop drift. This is not a monitoring problem — it is a control problem. And it connects directly to Part 4: inference observability is the prerequisite for routing that actually works over time.

The Control Layer
Routing and execution budgets are not the same control, but they operate on the same system. Routing decides what runs. Execution budgets decide how much it can run. Together they form the runtime cost control plane for inference.
Routing without budgets optimizes decisions. Budgets without routing constrain behavior. You need both to control cost.
Neither control is sufficient in isolation. A well-tuned routing layer running without step caps and token ceilings will still produce runaway cost events when an agent loop misbehaves. An enforcement stack running without routing will cap spend but burn through the budget on premium compute for requests that never needed it. The enforcement architecture from Part 2 and the routing layer described here are designed to be deployed together. See the AI Infrastructure Strategy Guide for how they fit into the broader inference architecture.
Architect’s Verdict
The teams that reduce inference cost aren’t using cheaper models. They’re making better decisions about when not to use expensive ones.
Routing is not a FinOps optimization you layer on after the bill surprises you. It is the control plane for inference cost — the decision layer that determines what every request costs before the inference call is made. Build it before production. Calibrate the thresholds against real quality data. Instrument every routing decision so you can see what the system is actually doing and why.
The architecture that reduces inference spend at scale doesn’t run smaller models. It runs the right model for each decision, enforces spend limits on how far each decision can cascade, and tracks both well enough to know when either control is drifting.
Inference cost isn’t a model problem. It’s a decision problem.
The AI Infrastructure pillar covers GPU placement strategy, inference architecture, and the cost decisions most teams make too late. Start with the full pillar overview.
Explore AI Infrastructure →Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session