Beyond the Hyper-scaler: Why AI Inference is Moving to the Edge (and How to Architect It)
The NVIDIA-Groq deal confirms what infrastructure architects have suspected for eighteen months: centralized cloud is struggling with AI inference edge workloads. Real-time inference at scale — thousands of devices, sub-20ms latency requirements, metered connectivity — breaks the hyperscaler model. This post covers the decision framework, financial reality, and architecture pattern for moving AI inference to the edge in 2026.

The Decision Framework: When to Leave the Cloud
We shouldn’t make architectural shifts based on hype. We must make them based on physics and economics.
If you are debating between hosting your model on AWS SageMaker versus committing to an AI inference edge deployment, use this comparison guide.
| Factor | Stay in the Cloud (Hyperscaler) | Move to the Edge |
| Data Gravity | Data originates in the cloud (e.g., Web traffic, CRM logs). | Data originates on-premise (e.g., Cameras, LIDAR, Sensors). |
| Latency Needs | > 200ms is acceptable (Human interactions). | < 20ms is mandatory (Machine reactions). |
| Connectivity | High-bandwidth fiber is guaranteed. | Intermittent (Maritime, Oil & Gas) or Metered (5G/Satellite). |
| Privacy | Data can be anonymized and moved. | Data must stay on-site (Strict GDPR, HIPAA). |
| Updates | You retrain the model hourly. | You update the model weekly or monthly. |
Field Note: The biggest mistake I see teams make is underestimating the “Egress Tax.” I recently audited a manufacturing client streaming high-definition video to Azure for defect detection. They were spending $12,000/month on bandwidth to find just 3 defects. We moved the model to a local edge device (a $500 one-time cost), and their monthly operational costs dropped to near zero. “Before you commit to a cloud-first strategy, calculate whether an AI inference edge deployment changes the math — then consult our Field Guide to Cloud Egress and Data Gravity to understand the hidden costs of moving data.
The Financial Reality: CapEx vs. OpEx
This is the most important section to share with your finance leadership.
Let’s look at a real-world scenario: An Intelligent Retail store with 50 cameras analyzing foot traffic 12 hours a day.
Option A: Cloud Inference
- The Cost: You pay for bandwidth to upload 50 video streams. Then, you pay a “serverless” fee for every image processed.
- The Result: You will likely spend $15,000 – $20,000 per month. If your traffic spikes, your bill spikes.
Option B: Edge Inference
- The Cost (CapEx): You buy 5 Edge Servers with decent GPUs. This is a one-time purchase of roughly $10,000.
- The Cost (OpEx): You pay a small monthly fee for management software (like Nutanix or VMware Edge), roughly $500/month.
- The Result: You achieve a Return on Investment (ROI) in Month 1. After that, your inference is essentially free, costing only electricity.
Architect’s Warning: While serverless seems cheaper initially, there is always a tipping point where convenience becomes a liability. Run your numbers through our Low-Code vs Serverless: Refactoring Cliff Calculator to see exactly when you should switch from Pay-As-You-Go to fixed infrastructure.
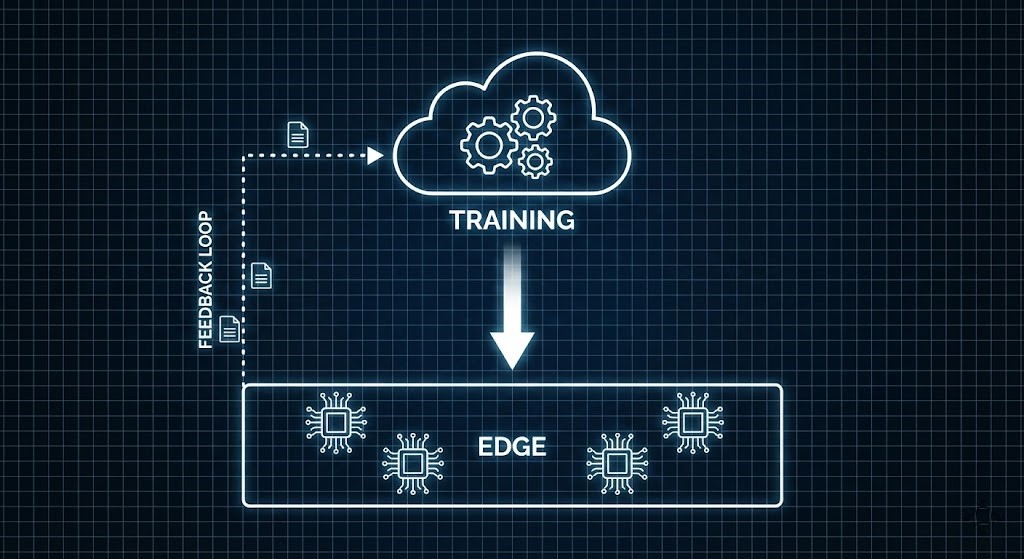
Architecture Pattern: The “Split-Brain” Pipeline
You do not need to abandon the cloud completely. The most resilient AI inference edge architecture specializes how each layer is used rather than replacing one with the other. The most robust architecture I have deployed follows a “Loop” pattern:
- Core (Cloud): This is the training ground. Your massive datasets live here. You use high-power compute to build your models.
- The Bridge (CI/CD): Once a model is ready, we shrink it (quantization) and package it into a container (Docker). This often involves moving data between object storage and block storage at the edge—a process detailed in our Storage Learning Path.
- Edge (Inference): The container is pushed to the edge devices. The analysis happens locally.
- The Feedback Loop: We only upload “interesting” data—like low-confidence predictions or anomalies—back to the cloud to improve the model.
The Tech Stack Visualization:
| Layer | Technology Examples | Function |
| Orchestration | K3s, Azure Arc, AWS Greengrass | Manages the software on the device. |
| Runtime | ONNX Runtime, TensorRT | Runs the AI model efficiently. |
| Compute | NVIDIA Jetson, Coral TPU, Groq LPU | Hardware that accelerates the math. |
| Messaging | MQTT, NATS.io | Lightweight communication back to the cloud. |
Tools Engineers Love
Don’t guess at your architecture—calculate it.
Edge devices storing local compliance data — CCTV footage, sensor logs, audit trails — need ransomware-resistant storage before that data ever touches the cloud. Size your immutable storage architecture and cost it out before you commit to a deployment model.
→ Estimate Edge Storage CostEdge devices storing local compliance data — CCTV footage, sensor logs, audit trails — need ransomware-resistant storage before that data ever touches the cloud. Size your immutable storage architecture and cost it out before you commit to a deployment model.
→ Estimate Edge Storage CostQ: What is the minimum latency requirement that justifies moving AI inference to the edge?
A: The practical threshold for AI inference edge deployments is sub-20ms response requirements. Cloud inference round-trips — including network transit, queue time, and processing — typically land between 80–300ms depending on region proximity. Any workload requiring machine-speed reactions (robotics, real-time defect detection, autonomous systems) cannot tolerate that latency floor. Human-interaction workloads above 200ms are generally safe to keep in the cloud.
Q: Does edge AI inference require dedicated hardware accelerators?
A: Not always, but accelerators dramatically change the economics. General-purpose edge compute (x86 with no GPU) can handle lightweight models under 100MB. For computer vision or transformer-based inference, hardware accelerators like NVIDIA Jetson, Coral TPU, or Groq LPU reduce both latency and power consumption by 10-40× compared to CPU-only inference. The ROI calculation should include power cost at the edge — particularly for high-density deployments.
Q: How do you handle model updates across distributed edge inference nodes?
A: The CI/CD bridge layer handles this. Models are quantized, containerized, and pushed via a GitOps pipeline — the same pattern used for application updates. Tools like Azure Arc, AWS Greengrass, and K3s with Flux or ArgoCD manage the distribution. The critical operational requirement is rollback capability: edge devices in intermittent connectivity environments need a known-good model version to revert to if an update fails mid-deployment.
Q: What happens to edge inference nodes when connectivity to the cloud is lost?
A: A properly architected edge inference deployment continues operating autonomously during connectivity loss — this is a primary design requirement, not an edge case. The node processes locally, stores “interesting” data (anomalies, low-confidence predictions) in a local buffer, and syncs to the cloud when connectivity is restored. The failure mode to avoid is any inference path that requires a cloud API call to complete — that’s a hybrid that inherits the worst of both models.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session