From RAID to Erasure Coding: A Deterministic Guide to Storage SLAs for AI and Analytics

There is a specific kind of silence that fills a data center when a second drive fails during a RAID 6 rebuild. I experienced it firsthand in 2018 during a massive Hadoop cluster migration. We were pushing 20PB of data. A 14TB drive died. The controller started the rebuild, calculating parity bit by bit. Then, at 65% completion—statistical inevitability struck. A latent sector error (URE) on a different drive halted the controller.
We didn’t just lose the volume; we lost three days of compliance logs that, legally, we were required to have.
That failure wasn’t hardware; it was math. If you are still architecting storage for AI, LLM training, or large-scale analytics using traditional RAID, you are building on a mathematical foundation that expired when drives hit 8TB. In the era of 24TB NVMe densities, reliability is no longer about “hot spares”—it is about the physics of network recovery.
This article details the transition from probabilistic RAID protection to deterministic Erasure Coding (EC), and how to calculate the cost of that transition.
Key Takeaways
- The URE Trap: On 20TB+ drives, the probability of an Unrecoverable Read Error during a RAID rebuild approaches 1.0. RAID is now a liability.
- Rebuilds are Network Events: Erasure Coding shifts the rebuild bottleneck from the disk controller to the East-West network fabric.
- The OpEx Tax: EC saves CapEx (raw storage) but increases OpEx (compute cycles for parity), impacting licensing costs.
- Granularity: EC protects data shards ($n+k$), not physical disks, allowing for parallel healing across the entire cluster.
The Physics of Recovery: Why RAID is Dead at Scale
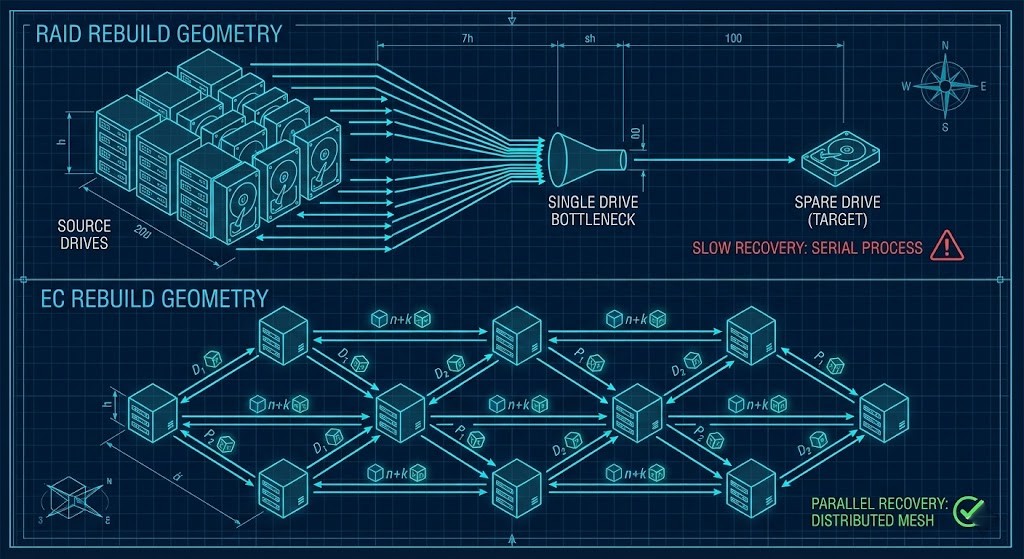
The fundamental problem with RAID in 2026 is the Rebuild Window. RAID protects disks. When a disk fails, the RAID controller must read every remaining bit to reconstruct the data to a single spare drive.
The write speed of that single spare drive is your hard limit. Even with Gen5 NVMe, you are limited by the controller’s ability to calculate XOR parity while serving production I/O.
Here is the reality of the Unrecoverable Read Error (URE):
Enterprise drives typically have a URE rate of 1 sector per $10^{15}$ bits. When you rebuild a 100TB RAID 6 group, you are reading enough bits that hitting a URE is statistically probable. If that happens during a rebuild, the array halts.
If you are architecting a solution for an AI Data Lake where datasets span Petabytes, relying on RAID is not engineering—it is gambling with your career.
Erasure Coding: The $n + k$ Imperative
Erasure Coding (EC) changes the failure domain. We stop caring about the physical medium. We break data into $n$ data fragments and $k$ parity fragments, dispersing them across nodes.
The Developer’s View: Calculating RTO
When a node fails, the cluster detects missing shards. Every other node in the cluster participates in regenerating those shards and writing them to any available space in the cluster.
The RTO Formula:
Scenario: You lose a node holding 40TB of data in a 16-node All-Flash cluster.
- RAID: Writes to a single spare. Capped at drive write speed ($\approx$ 2GB/s). Time: ~5.5 Hours.
- EC: Re-replicates across 15 remaining nodes via 100GbE fabric.
- Throughput: 15 nodes $\times$ 10GB/s (conservative) = 150GB/s.
- Time: < 5 Minutes.
Architect’s Warning: This massive burst of recovery traffic (East-West) can saturate your spine-leaf architecture if you haven’t calculated your oversubscription ratios correctly. Before deploying EC at scale, I use theRack2Cloud V2N Mapperto visualize the topology and ensure the underlay can handle a “rebuild storm” without crushing the AI inference workloads running on the same pipes.
Decision Framework: The Trade-off Matrix
EC is not free. It is computationally heavy (Reed-Solomon math) and latency-inducing compared to RAID 10. Do not use EC for everything.
| Feature | RAID 10 (Mirroring) | RAID 6 | Erasure Coding (4+2) | Erasure Coding (8+3) |
| Best Workload | Boot Volumes, High-Write SQL/Oracle | Legacy Archives (<50TB) | General AI/Object Store | Deep Archive / Cold Data |
| Storage Overhead | 100% (2x raw required) | ~20-30% | 50% (1.5x raw required) | 37.5% (1.375x raw required) |
| Write Penalty | Low (2 writes) | High (6 I/Os) | Medium (CPU Intensive) | High (CPU Intensive) |
| Rebuild Geometry | One-to-One (Slow) | Many-to-One (Slowest) | Many-to-Many (Fast) | Many-to-Many (Fast) |
| Failure Tolerance | 1 Drive per span | 2 Drives total | 2 Full Nodes/Drives | 3 Full Nodes/Drives |
Mandatory Cost Analysis: CapEx Savings vs. Licensing Tax
This is the section you take to your CFO. EC looks cheaper on the hardware quote, but you must account for the “Compute Tax.”
1. The CapEx Win (Hardware)
For a 5PB raw capacity project:
- RAID 10: 50% usable. You get 2.5PB effective.
- EC (4+2): 66% usable. You get 3.3PB effective.
- Result: To get 3.3PB usable with RAID 10, you’d need to buy 6.6PB of raw flash. EC saves you 1.6PB of NVMe drives. That is easily a $250k+ CapEx saving.
2. The OpEx & Licensing Hit (Software)
Here is the catch. Calculating parity for EC requires CPU cycles. In a hyper-converged environment (like VCF or Nutanix), this steals cycles from your VMs.
- The Consequence: You may need higher core-count CPUs to maintain performance.
- The Licensing Trap: Broadcom (VMware) and others now license by Core. If EC forces you to move from 32-core to 48-core processors, your annual software subscription costs skyrocket.
Recommendation: Don’t guess. Run the numbers. I use our VMware VVF/VCF Core Calculator to model exactly how a CPU upgrade to support EC impacts the 3-year TCO. Often, the software cost increase eats 40% of the hardware savings—but EC is still worth it for the data durability alone.
Migration Considerations
Moving from a legacy SAN (RAID) to an Object Store (EC) is not a simple “vMotion.” It involves a shift in how data is accessed (Block vs. API/S3). If you are currently running NSX-T and looking to modernize the underlying storage for a new private cloud build, review the NSX-T to Nutanix Flow Migration Guide to understand how network micro-segmentation policies must adapt to distributed storage traffic.
Conclusion: Deterministic Survival
In 15 years of designing systems, I have learned that “Mean Time Between Failures” (MTBF) is a marketing term. “Mean Time to Recovery” (MTTR) is an engineering metric.
RAID on 24TB drives extends your MTTR to dangerous levels where a second failure is probable. Erasure Coding compresses that MTTR into a window where data loss is mathematically improbable.
If you are building for AI, where the data is the product, you cannot afford the probabilistic risk of RAID. Pay the CPU tax. Upgrade the network spines. Switch to Erasure Coding. Because when a rack goes dark, you want to know—deterministically—that your data is safe.
Next Step
Are you evaluating the licensing impact of moving to a high-density, Erasure Coded HCI environment? Would you like me to generate a TCO Comparison Table specifically analyzing the Broadcom per-core impact vs. the hardware savings of an EC 4+2 configuration?
FAQ
Q: Is RAID still safe for enterprise storage?
A: RAID remains viable for small arrays and low-capacity workloads, but at petabyte scale and modern drive densities, rebuild failure probability becomes unacceptably high.
Q: Does Erasure Coding replace RAID?
A: Not entirely. RAID remains ideal for boot volumes and high-write transactional workloads. EC is superior for large datasets, object storage, and AI data lakes.
Q: Does EC hurt performance?
A: EC introduces CPU overhead and write amplification. Proper CPU sizing and network design are required to avoid performance degradation.
Q: Is Erasure Coding cheaper than RAID?
A: Hardware is cheaper, but licensing and CPU costs may offset some savings. TCO modeling is essential.
Additional Resources:
- Seagate: The Math Behind Large Drive URE Rates
- MinIO: Erasure Coding Primer for Object Storage
- Broadcom: VMware vSAN Space Efficiency Guide
- Nutanix: Erasure Coding and Data Locality
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
This architectural deep-dive contains affiliate links to hardware and software tools validated in our lab. If you make a purchase through these links, we may earn a commission at no additional cost to you. This support allows us to maintain our independent testing environment and continue producing ad-free strategic research. See our Full Policy.