CLOUD NATIVE ARCHITECTURE
SYSTEMS, NOT SERVERS. CONTROL PLANES OVER INFRASTRUCTURE.
Cloud native architecture is not a deployment strategy. It is not a set of tools. It is not “running containers on Kubernetes.” It is a systems design philosophy built on a single premise: infrastructure should be defined as intent, and the platform should enforce it continuously.
That distinction matters architecturally. AWS abstracts infrastructure into services. GCP abstracts infrastructure into software-defined systems. Azure abstracts infrastructure into an enterprise identity fabric. Cloud native abstracts infrastructure away entirely — replacing server management with control plane logic, replacing manual operations with automated reconciliation, and replacing static topology with dynamic scheduling. It is the execution model that runs on top of all three clouds, on-premises, and at the edge — and it is the reason Kubernetes has become the standard substrate for distributed systems regardless of where they run.
The organizations that misunderstand cloud native treat it as a technology migration. They containerize their monolith, deploy it to Kubernetes, and wonder why operational complexity increased without the promised velocity gains. The mental model is wrong. Cloud native is not about where workloads run. It is about how systems are designed to change — continuously, at scale, without human intervention in the critical path.
This cloud native architecture guide covers the control plane model, the five pillars, security, platform engineering, cost physics, and the decision framework for when cloud native is the right architecture — and when it is the wrong one.
What Cloud Native Architecture Actually Is
Cloud native systems are built on continuous reconciliation — not one-time configuration.
In a traditional infrastructure model, an operator provisions a server, installs software, configures it, and monitors it. The system state is what the operator made it. Changes require human intervention. Drift from the intended configuration is invisible until something breaks.
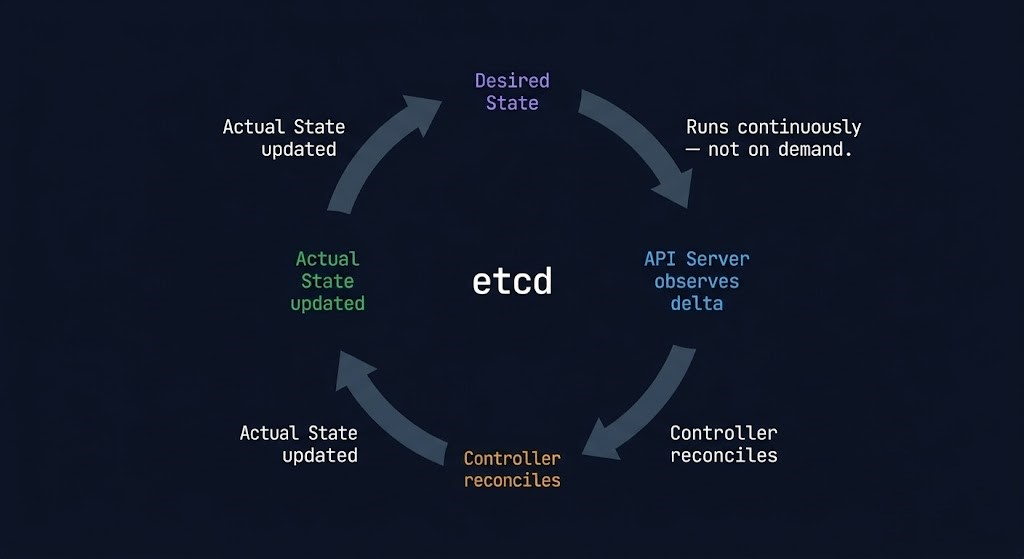
In a cloud native model, an architect declares desired state — a specification of what the system should look like. The platform continuously compares actual state against desired state and reconciles the difference. A container dies; the platform restarts it. A node fails; the platform reschedules workloads. Traffic spikes; the autoscaler adds capacity. None of these events require human intervention because the system is designed to self-correct.
This is the architectural shift that makes cloud native genuinely different from containerization. Containerizing a workload is a packaging decision. Running that workload in a system governed by continuous reconciliation is an architectural decision. The packaging is easy. The architecture is where the investment lives.
The Cloud Native Computing Foundation defines cloud native systems around four properties: containerized, dynamically scheduled, microservices-oriented, and running on shared infrastructure. But the property that underpins all four is declarative intent — the idea that operators describe what they want, not how to achieve it. That shift from imperative to declarative is what makes cloud native systems programmable, portable, and operable at scale.
The Traditional vs Cloud Native Contrast
| Dimension | Traditional Infrastructure | Cloud Native |
|---|---|---|
| Operations model | Manage servers — provision, configure, maintain | Define desired state — platform enforces it continuously |
| Scaling model | Scale vertically — add CPU and RAM to existing machines | Scale horizontally — add instances, scheduler handles placement |
| Infrastructure model | Static topology — servers are named, persistent, handcrafted | Dynamic scheduling — workloads are placed by the control plane |
| Failure handling | Manual recovery — operator diagnoses and repairs | Automated reconciliation — platform detects and self-heals |
| Configuration model | Imperative scripts — describe how to reach a state | Declarative manifests — describe what the state should be |
| Change velocity | Deployment windows — changes are batched, tested, scheduled | Continuous delivery — changes flow through pipelines automatically |
In cloud native systems, you don’t manage infrastructure — you define intent, and the system enforces it.
The Control Plane Model
Modern infrastructure is defined by control planes. Cloud native is the purest implementation of that model.
A control plane is the component of a distributed system responsible for making decisions about the system’s state — where workloads run, how traffic routes, what configuration applies, which policies are enforced. The data plane is the component that executes those decisions — running the actual workloads, carrying the actual traffic, applying the actual configuration.
This separation is not Kubernetes-specific. AWS’s IAM is a control plane for identity. Azure’s Management Groups are a control plane for governance. GCP’s Andromeda is a control plane for networking. But Kubernetes is the most explicit and composable implementation of the control plane model available — and understanding it at the architectural level is the prerequisite for operating cloud native systems at scale.
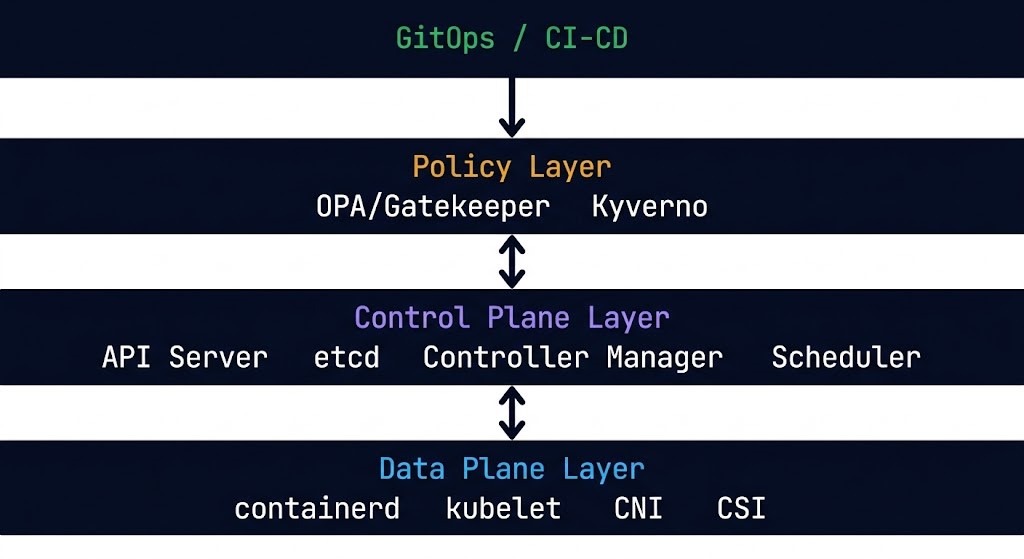
The Kubernetes Control Plane operates through four components that work together to maintain cluster state. The API server is the single source of truth — every interaction with a Kubernetes cluster is an API call against the API server. No component reads cluster state directly from another component; they all read from and write to the API server. This design makes the control plane inspectable, auditable, and extensible. Every state change is an API transaction with a complete audit trail.
etcd is the distributed key-value store that backs the API server. Every resource definition in a Kubernetes cluster — every Pod spec, every Service, every ConfigMap, every custom resource — lives in etcd. The API server is the interface; etcd is the substrate. A healthy etcd cluster is a non-negotiable prerequisite for cluster reliability. The containerd Day-2 failure patterns cover what happens when the runtime layer beneath the control plane degrades — the failure signatures propagate upward in consistent and predictable ways.
The controller manager runs a set of control loops — one per resource type — that continuously watch the API server for changes to desired state and take action to reconcile actual state against it. A Deployment controller watches for Deployment objects and ensures the correct number of Pod replicas exist. A Node controller watches for node health and marks nodes as unavailable when they stop reporting. These loops run continuously, not on demand — which is why Kubernetes is described as eventually consistent rather than immediately consistent.
The scheduler is responsible for one decision: given a new Pod with no assigned node, which node should run it? The scheduler evaluates every node against the Pod’s resource requests, affinity rules, taint tolerations, and topology constraints and selects the optimal placement. The Kubernetes scheduler fragmentation patterns cover the failure modes that emerge when the scheduler’s placement decisions compound into resource contention across the cluster.
Service mesh control planes — Istio, Linkerd, Cilium — extend the control plane model to the network layer. Where Kubernetes manages workload placement, a service mesh control plane manages traffic policy — routing rules, circuit breakers, retries, mTLS configuration, and observability instrumentation. The service mesh vs eBPF architecture decision covers the tradeoffs between sidecar-based service mesh implementations and eBPF-based alternatives that push policy enforcement into the kernel rather than the application layer.
Policy engines like OPA/Gatekeeper and Kyverno extend the control plane model to governance — enforcing organizational policies at admission time, before resources are created. A policy engine that rejects non-compliant resource definitions at the API server level prevents configuration debt from entering the cluster in the first place.
The control plane model matters architecturally because it changes how you think about operations. In a traditional infrastructure model, operational knowledge lives in runbooks and operators. In a control plane model, operational knowledge lives in code — in controller logic, in policy definitions, in scheduling constraints. The system enforces what the code specifies. This is what makes cloud native systems auditable, reproducible, and operable at the scale where human operators cannot keep up with the rate of change.
The Five Pillars of Cloud Native Architecture
Cloud native architecture rests on five interdependent pillars. Each is independently valuable. Together they form the complete operational model.
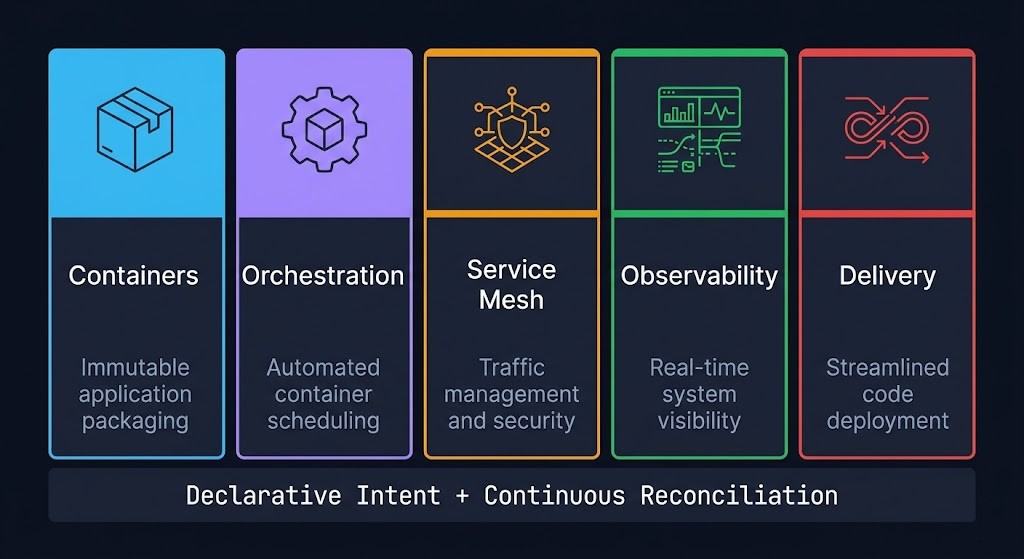
Containers — The Packaging Primitive
Containers provide workload portability by packaging an application and its dependencies into a single, immutable artifact. The container image is the unit of deployment — the same image runs in development, staging, and production without environment-specific configuration embedded in the artifact. This immutability is what enables cloud native’s automated scheduling model: the platform can place, restart, and reschedule containers without understanding what is inside them, because the container itself guarantees consistent behavior regardless of where it runs.
The container runtime — containerd being the dominant implementation after Docker’s removal from Kubernetes — manages the actual lifecycle of containers on each node. Runtime health is a foundational dependency for cluster stability. The containerd Day-2 failure patterns cover the operational failure modes that surface at the runtime layer and propagate upward to affect workload availability.
Orchestration — The Scheduling and Lifecycle Layer
Container orchestration — Kubernetes in the overwhelming majority of production environments — manages the lifecycle of containerized workloads across a cluster of nodes. Scheduling, scaling, rolling updates, health checking, and service discovery are all handled by the orchestration layer without operator intervention for individual workload events. The Kubernetes Cluster Orchestration guide covers the operational architecture of production Kubernetes environments in full.
Service Mesh — The Network Policy Layer
A service mesh provides traffic management, observability, and security at the network layer without requiring application code changes. mTLS between services, circuit breakers, traffic splitting, and distributed tracing are all implemented at the mesh layer — below the application, above the raw network. The mesh control plane manages policy; the data plane enforces it. The full architectural framework is covered in the Service Mesh Architecture pillar — including the data plane decision between sidecar, ambient, and eBPF, the cost physics, and when a mesh is the wrong abstraction entirely. The service mesh vs eBPF analysis covers the specific tradeoffs between sidecar-based implementations and kernel-level alternatives.
Observability — The Instrumentation Layer
Cloud native observability is not monitoring. Monitoring tells you when something is wrong. Observability tells you why. The three pillars of observability — metrics, logs, and traces — must be instrumented at every layer of the stack and correlated across service boundaries to enable the kind of root cause analysis that distributed systems require. The Kubernetes Day-2 failure patterns are the operational proof of why observability is a first-class architectural requirement, not an afterthought. Five specific production failure signatures — all invisible to conventional monitoring — become diagnosable only with proper observability instrumentation.
Delivery — CI/CD and GitOps
Cloud native without continuous delivery is incomplete. The platform can schedule, scale, and self-heal workloads — but if changes still flow through manual deployment processes, the operational velocity advantage of cloud native is only partially realized.
GitOps is the delivery model that cloud native systems converge toward: Git as the single source of truth for the entire system state, with automated pipelines that reconcile the live cluster state against the repository state on every commit. The same declarative, reconciliation-based model that governs Kubernetes workload scheduling governs the delivery pipeline. ArgoCD and Flux are the dominant GitOps operators — both watch a Git repository and continuously apply its contents to the cluster, creating a self-healing delivery pipeline where the desired system state is always the repository state.
CI/CD at the pipeline level — build, test, scan, push — feeds the GitOps operator. The image build is automated, the security scan is automated, the registry push is automated, and the GitOps operator handles the deployment. Human operators approve changes through pull requests; the platform handles execution.
Kubernetes as the Control Plane
Kubernetes is not a scheduler. Describing it as a container orchestration system understates what it actually is.
Kubernetes is a distributed systems control plane — a general-purpose platform for building systems that manage their own state through continuous reconciliation. The workload scheduling and container orchestration are the most visible capabilities, but the architectural significance of Kubernetes is broader: it is an extensible API that allows any resource type to be managed through the same declarative model that manages Pods and Services.
Custom Resource Definitions (CRDs) allow organizations to extend the Kubernetes API with their own resource types — and controllers to manage them through the same control loop model as built-in resources. This extensibility is what makes the Kubernetes ecosystem so broad. Operators for databases, message queues, certificate management, DNS, cloud infrastructure provisioning — all implemented as Kubernetes controllers that manage custom resources through the standard declarative API. The platform provides the reconciliation engine; the operator provides the domain-specific logic.
The operational implication is significant: an organization that builds operational knowledge as Kubernetes controllers builds it in a form that is auditable, testable, version-controlled, and portable. An organization that builds operational knowledge as runbooks builds it in a form that is fragile, inconsistent, and human-dependent.
For production Kubernetes operational patterns — Day-2 failures, diagnostic methods, and the four control loops — the Kubernetes Day-2 Operations series covers the full operational architecture. The five real-world failure signatures document the specific patterns that surface most consistently in production clusters.
Security — Zero Trust at Runtime
In cloud native systems, the network is assumed hostile — every service call is authenticated and authorized, regardless of network position.
This is the BeyondCorp model applied to distributed systems. Traditional security models treat the internal network as trusted — anything inside the perimeter can communicate freely with anything else inside the perimeter. Cloud native security inverts this assumption. Every workload has a cryptographic identity. Every service-to-service call is authenticated against that identity. Every network policy is enforced at the workload level, not the network perimeter.
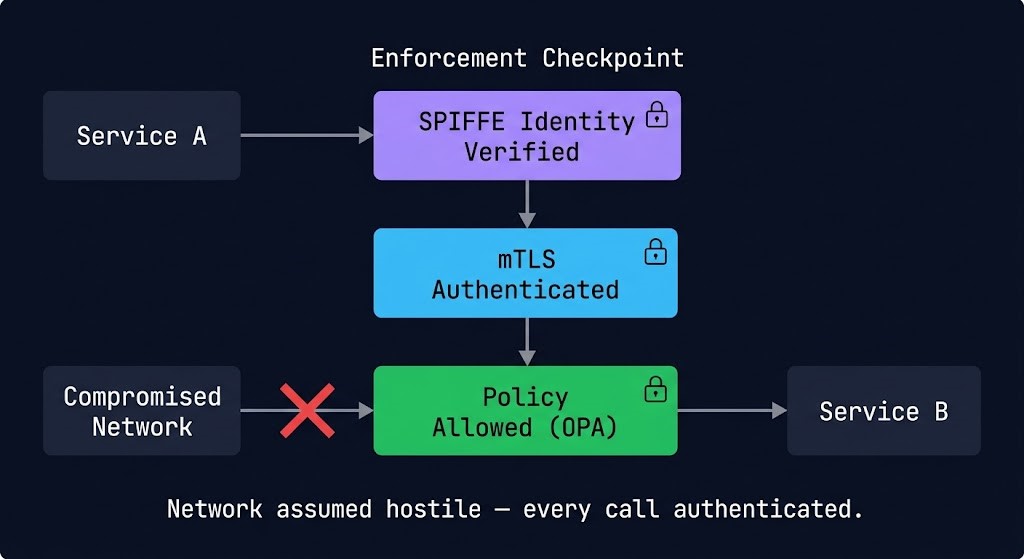
Service identity is the foundation. In cloud native environments, workloads authenticate using short-lived cryptographic certificates issued against their Kubernetes service account — not IP addresses, not network positions, not long-lived credentials. SPIFFE (Secure Production Identity Framework for Everyone) and its implementation SPIRE provide the identity framework that service meshes and policy engines build on.
mTLS between services enforces mutual authentication at the transport layer — both sides of every service call present certificates and verify each other’s identity before data is exchanged. A service mesh handles mTLS transparently, without application code changes. The result is that lateral movement within a compromised cluster requires compromising cryptographic identities, not just network access.
Policy enforcement at runtime through admission controllers and policy engines — OPA/Gatekeeper, Kyverno — ensures that only compliant workload configurations can enter the cluster. Privileged containers, containers running as root, images from untrusted registries, missing resource limits — all can be rejected at the API server before they run. The Container Security Architecture guide covers the full runtime security model for production container environments.
Supply chain security — signing images, verifying provenance, scanning for vulnerabilities at build time — closes the gap between what the policy engine expects and what actually runs. Cosign, Sigstore, and admission webhooks that verify image signatures before allowing deployment are the current standard for production supply chain integrity.
The Platform Engineering Model
Cloud native at scale requires a layer between Kubernetes and the engineering teams consuming it. That layer is the internal developer platform — and building it is the discipline of platform engineering.
Raw Kubernetes is operationally powerful and cognitively expensive. A developer who needs to deploy a service should not need to understand PodDisruptionBudgets, HorizontalPodAutoscalers, NetworkPolicies, and ServiceAccounts to get a workload running safely. Platform engineering exists to abstract that complexity — providing a curated, opinionated interface to Kubernetes that enforces organizational standards while reducing the cognitive overhead for product teams.
The internal developer platform (IDP) is the product that platform engineering builds and operates. Backstage is the most widely adopted open-source framework for IDPs — providing a service catalog, documentation portal, and plugin architecture that integrates with CI/CD pipelines, Kubernetes clusters, cloud provider APIs, and monitoring systems into a single pane of glass for engineering teams.
The golden path is the platform engineering concept that most directly reduces cognitive load: a pre-configured, opinionated deployment path that satisfies organizational security, compliance, and operational requirements by default. A team following the golden path does not configure network policies, resource quotas, or observability instrumentation — the platform applies them automatically. Deviation from the golden path requires explicit justification, creating a natural governance checkpoint without a manual approval process.
Abstraction layers over Kubernetes — Crossplane, Helm, Kustomize — provide the configuration management layer that makes Kubernetes environments reproducible across clusters, environments, and cloud providers. Building a portable control plane with Crossplane covers the architecture for managing cloud resources through Kubernetes-native tooling, extending the control plane model to infrastructure provisioning.
Platform engineering exists to make cloud native usable at scale — by product teams who should not need to be Kubernetes experts, and by organizations that need to enforce consistent security and operational standards across dozens of teams and hundreds of services.
Cost Physics
Cloud native trades infrastructure efficiency for engineering complexity — and only pays off at scale.
This is the honest version of the cloud native cost story, and it is the version most architecture guides avoid.

Where cloud native reduces cost:
Bin-packing efficiency is the primary cost mechanism. Kubernetes schedules workloads across nodes based on actual resource requests, filling available capacity more efficiently than static VM allocation. A cluster running 50 microservices can achieve significantly higher CPU and memory utilization than 50 individual VMs with headroom pre-allocated for peak demand. The AI inference cost architecture covers the same bin-packing economics applied to GPU workloads — the same principles compound more dramatically at inference scale.
Autoscaling eliminates idle capacity cost. Horizontal Pod Autoscaler scales workload replicas based on CPU, memory, or custom metrics. Cluster Autoscaler scales node count based on pending pod demand. Together they mean that a correctly configured cloud native environment pays for capacity proportional to demand rather than peak demand. The delta between peak and average demand — which can be 3-5x for many workload types — is the cost that autoscaling eliminates.
Spot and preemptible instances become operationally viable. Cloud native’s scheduling model makes it practical to run workloads on spot instances that can be terminated with 30-120 seconds notice — because the platform handles rescheduling automatically. For fault-tolerant batch workloads, spot discounts of 60-90% represent significant cost reduction without operational overhead.
Where cloud native increases cost:
Observability infrastructure is expensive. A production-grade observability stack — Prometheus, Grafana, distributed tracing, log aggregation — runs continuously and consumes meaningful cluster resources. The operational visibility this provides is worth the cost at scale; at small scale it is overhead without proportional value.
Over-provisioned clusters are the most common cloud native cost trap. Teams provision clusters for peak load plus headroom, autoscaling is not configured correctly, and the cluster runs at 20-30% utilization while billing at 100%. The cluster autoscaler must be correctly configured — with appropriate scale-down thresholds, node group sizing, and workload disruption budgets — to capture the utilization efficiency cloud native promises.
Engineering complexity has a real cost. Cloud native requires Kubernetes expertise, platform engineering investment, and operational tooling that traditional infrastructure does not. For small teams or stable workloads, this investment does not return proportional value. The operational cost model only becomes favorable at the scale where automation replaces manual operations at a rate that exceeds the investment in the platform.
Stateful Workloads — Where Cloud Native Gets Hard
The cloud native operational model was designed for stateless workloads. Stateful workloads — databases, message queues, caches, anything with persistence requirements — expose the gaps.
Stateless services are trivially rescheduled. When a node fails or a pod is evicted, the scheduler places a new instance anywhere in the cluster with no data migration required. The new instance is identical to the old one because state lives outside the compute layer.
Stateful services cannot be rescheduled arbitrarily. A database pod evicted from one node cannot simply restart on another node without its data. StatefulSets provide ordered deployment, stable network identities, and persistent volume claims that follow pods across rescheduling events — but they introduce operational complexity that Deployments do not have. Scale-down of a StatefulSet requires careful consideration of quorum, replication state, and data availability before the last replica is removed.
The PVC stuck and volume node affinity failure patterns document the specific failure signatures that emerge when stateful workload scheduling intersects with zone-aware storage provisioning. Block storage is zonal. Pods are scheduled across zones. When a pod is rescheduled to a zone where its persistent volume does not exist, the pod enters ContainerCreating indefinitely — a silent failure that requires understanding the storage topology to diagnose.
The operational decision for stateful workloads in cloud native environments: managed database services (RDS, Cloud SQL, Azure SQL) eliminate the Kubernetes stateful workload complexity entirely at the cost of cloud provider lock-in. Running stateful workloads natively in Kubernetes with operators (PostgreSQL Operator, Vitess, TiDB Operator) preserves portability at the cost of operational overhead. Neither is universally correct — the decision is a function of team expertise, portability requirements, and operational capacity.
Compute and Workload Decision Tree
| Workload Type | Cloud Native Fit | Why | Watch For |
|---|---|---|---|
| Stateless APIs and services | Strong fit | Horizontal scaling, zero-downtime rolling updates, autoscaling aligned to traffic | Resource request sizing — under-provisioned requests cause scheduler fragmentation |
| Event-driven systems | Strong fit | KEDA-based autoscaling on queue depth, scale-to-zero between bursts, Pub/Sub native integration | Cold start latency for scale-from-zero workloads with strict SLA requirements |
| Stateful databases | Conditional fit | Possible with StatefulSets and operators — but operational overhead is significant | Zone-aware storage scheduling, PVC node affinity conflicts, StatefulSet scale-down quorum |
| Batch and HPC workloads | Strong fit | Spot instance tolerance, Job and CronJob primitives, cluster autoscaler handles burst provisioning | Checkpoint state before preemption — stateless batch is trivial, stateful batch requires design |
| Legacy monoliths | Weak fit | Containerizing a monolith adds operational overhead without the scaling or resilience benefits | Lift-and-shift to containers is not cloud native — it is the lift-and-shift lie in container form |
| Low-scale stable applications | Overkill | Platform engineering overhead exceeds the operational benefit for small, infrequently changed systems | The cost model only improves at scale — a 3-replica stateless app on a managed VM is simpler |
| AI inference workloads | Strong fit | GPU resource scheduling, model serving autoscaling, multi-tenant model isolation via namespaces | GPU node affinity, model loading latency, inference cost architecture must be modeled explicitly |
When Cloud Native Is the Right Call
Systems that change more often than they scale are the primary cloud native use case. If your deployment frequency is measured in days rather than months, and your workload count is measured in dozens rather than single digits, the automation investment returns measurable operational value. If your system changes more often than it scales, cloud native is usually the right model.
Organizations where multiple product teams share infrastructure benefit directly from the platform engineering model. Kubernetes provides the isolation boundaries — namespaces, RBAC, network policies, resource quotas — that allow teams to operate independently on shared infrastructure without stepping on each other. The platform team builds the platform; product teams consume it.
Workloads that must run across multiple cloud providers, on-premises, and at the edge — without re-platforming for each environment — are the canonical cloud native use case. Kubernetes provides the consistent API surface that makes portability real rather than theoretical. The same manifest that runs in EKS runs in GKE and AKS with minimal modification.
GPU scheduling, model serving autoscaling, multi-tenant isolation, and the inference cost architecture all benefit from Kubernetes’s resource management model. Cloud native is the correct substrate for AI infrastructure at scale — not because containers are required for AI, but because the scheduling, isolation, and operational patterns cloud native provides are exactly what production AI systems need.
When to Consider Alternatives
A team of three running two services that deploy once a month does not need Kubernetes. The platform engineering overhead — cluster operations, observability stack, security hardening, RBAC configuration — costs more in engineering time than it returns in operational efficiency. Cloud native is not a starting point. It is an optimization model for teams and systems that have grown beyond what simpler approaches can handle.
Cloud native amplifies operational capability — it does not create it. Organizations without established CI/CD practices, without observability culture, and without platform engineering expertise will find that cloud native adds complexity faster than it adds velocity. The prerequisite for cloud native success is not Kubernetes knowledge — it is operational discipline that cloud native can then automate and scale.
Workloads with sub-millisecond latency requirements or strict data residency constraints may require dedicated hardware and fixed network topology that cloud native’s dynamic scheduling model does not naturally provide. Kubernetes can be configured for these constraints — but the configuration complexity approaches that of traditional infrastructure, eliminating the operational simplicity advantage.
Containerizing a monolith and running it on Kubernetes is not cloud native — it is a lift-and-shift with additional operational overhead. The cloud native benefits require designing for horizontal scaling, statelessness, and independent deployability. A monolith that cannot be horizontally scaled does not benefit from Kubernetes scheduling. Decompose first, containerize after.
Decision Framework
| Scenario | Cloud Native Verdict | Why |
|---|---|---|
| High deployment frequency, multi-service architecture | Strong Fit | Automation investment returns directly — each deployment cycle that requires no human intervention compounds the operational advantage |
| Multi-team platform organization on shared infrastructure | Strong Fit | Kubernetes isolation boundaries — namespaces, RBAC, network policies, resource quotas — enable team independence without infrastructure duplication |
| Stateless APIs and services requiring elastic scaling | Strong Fit | Native scheduling model, HPA autoscaling, and rolling updates align precisely with stateless workload requirements — minimum operational overhead for maximum benefit |
| AI/GPU inference workloads at production scale | Strong Fit | GPU resource scheduling, multi-tenant model isolation, and autoscaling on inference demand are native Kubernetes capabilities — the platform is built for this workload class |
| Event-driven pipelines with variable throughput | Strong Fit | KEDA-based event-driven autoscaling, scale-to-zero between bursts, and native message broker integration eliminate idle capacity cost for bursty workloads |
| Workloads requiring portability across clouds and on-premises | Strong Fit | The same Kubernetes manifest runs on EKS, GKE, AKS, and on-premises clusters — portability is real, not theoretical, when the abstraction layer is the Kubernetes API |
| Small team, stable workload, infrequent changes | Evaluate Alternatives | Platform engineering overhead — cluster operations, observability stack, RBAC configuration — costs more in engineering time than it returns for low-change environments |
| Legacy monolith without decomposition plan | Evaluate Alternatives | Containerizing a monolith adds operational overhead without the scaling or resilience benefits — the cloud native model requires workloads designed for horizontal scale, not just packaged for portability |
| Sub-millisecond latency, fixed network topology required | Evaluate Alternatives | Dynamic scheduling conflicts with fixed-topology requirements — configuring Kubernetes for these constraints approaches the complexity of traditional infrastructure without the operational simplicity advantage |
| No CI/CD practice, no observability culture, first cloud deployment | Not Yet | Cloud native amplifies operational capability — it does not create it. The prerequisite is operational discipline: automated testing, deployment pipelines, and observability practice. Build those first, then cloud native scales them |
You’ve seen how cloud native systems are architected. The pages below cover the pillars beneath it — the orchestration layer, the security model, the distributed system patterns, and the cloud platforms that run it all.
Architect’s Verdict
Cloud native is overkill for most workloads — and the only viable model for the ones that matter at scale.
The honest version of the cloud native argument is not that it makes everything simpler. It makes the right things simpler — automated scheduling, self-healing infrastructure, continuous delivery, policy-as-code governance — and makes other things harder — stateful workloads, observability at depth, platform engineering overhead, and the cognitive cost of a system that is always reconciling rather than always settled.
The teams that succeed with cloud native are not the ones with the most Kubernetes expertise. They are the ones who understand what the platform automates and design their systems to take advantage of that automation. The teams that struggle are the ones who bring traditional infrastructure mental models into a control-plane-governed environment and wonder why the operations are different.
Define intent. Let the platform enforce it. Start with the audit — understand what you are building before you decide how to build it.
Service boundaries, decomposition patterns, event-driven design, and the operational model for distributed systems at scale.
Production Kubernetes architecture — scheduling, scaling, Day-2 operations, and the control plane model in practice.
Zero Trust at the pod, image, and network layer — supply chain security, runtime policy, and identity-based access control.
East-west traffic policy, mTLS enforcement, traffic management, and the architectural decision between sidecar, ambient, and eBPF.
Internal developer platforms, golden paths, Backstage, and the abstraction layer that makes cloud native usable at organizational scale.
You’ve Got the Framework.
Now Validate the Platform Beneath It.
Declarative state, immutability, loose coupling — the principles are clear. The harder question is whether your Kubernetes platform, service mesh, container security posture, and Day-2 operations actually reflect them in production. The triage session audits the gap between the design intent and the running environment.
Cloud Native Platform Audit
Vendor-agnostic review of your cloud native platform — Kubernetes cluster configuration, service mesh deployment, container security posture, GitOps implementation, and Day-2 operational maturity. Covers the full stack from container image supply chain to production incident response.
- > Kubernetes cluster and workload configuration review
- > Container security posture and image supply chain
- > Service mesh and network policy architecture
- > GitOps maturity and Day-2 operations assessment
Architecture Playbooks. Every Week.
Field-tested blueprints from real cloud native environments — Kubernetes Day-2 failure diagnostics, container breakout case studies, service mesh vs eBPF decisions, and the platform engineering patterns that separate production-grade cloud native from fragile prototype infrastructure.
- > Kubernetes Day-2 Failure Diagnostics
- > Container Security & Zero Trust Patterns
- > Service Mesh & eBPF Architecture
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What is cloud native architecture and how does it differ from traditional infrastructure?
A: Cloud native architecture is a systems design philosophy built on declarative intent and continuous reconciliation — operators define desired state, and the platform enforces it automatically. Traditional infrastructure requires operators to manage servers, apply configurations imperatively, and respond manually to failures. Cloud native replaces that operational model with control plane logic: the platform handles scheduling, scaling, and self-healing, while architects focus on defining policy rather than managing state. The distinction is not containers — it is the operating model.
Q: Does cloud native require Kubernetes?
A: Kubernetes is the de facto standard for cloud native orchestration and the platform that most cloud native tooling assumes. The core principles — declarative state, continuous reconciliation, immutable workloads — can be implemented on other platforms. But in practice, the cloud native ecosystem is built around the Kubernetes API. Choosing a non-Kubernetes cloud native platform means accepting significantly reduced ecosystem compatibility. For most organizations the practical answer is: cloud native means Kubernetes, and the question is which Kubernetes distribution — EKS, GKE, AKS, OpenShift, or self-managed.
Q: When does cloud native actually reduce costs?
A: Cloud native reduces costs at scale, through specific mechanisms: bin-packing efficiency from dynamic scheduling, autoscaling that eliminates idle capacity, and spot instance viability from automated rescheduling. These benefits require correct configuration — autoscaling must be tuned, cluster autoscaler must be enabled, workloads must define accurate resource requests. An incorrectly configured cloud native environment frequently costs more than the traditional infrastructure it replaced. The cost reduction is real but not automatic.
Q: What is the biggest operational mistake teams make with cloud native?
A: Containerizing existing applications without redesigning for horizontal scaling. A monolith in a container is not cloud native — it is a monolith with a different packaging format and additional operational overhead. The cloud native operational model requires stateless workloads that can be scaled horizontally, restarted without data loss, and scheduled anywhere in the cluster. Workloads that cannot satisfy these requirements do not benefit from cloud native scheduling — they are degraded by it.
Q: How does cloud native relate to the specific cloud providers — AWS, GCP, and Azure?
A: Cloud native architecture runs on all three and is not specific to any. AWS EKS, GCP GKE, and Azure AKS all provide managed Kubernetes that satisfies the cloud native substrate requirement. The choice of cloud provider affects the managed services available alongside Kubernetes — storage classes, load balancers, identity integration, GPU availability — but the Kubernetes-level architecture is portable across all three. Cloud native is the execution model that sits above the provider layer; the provider pages cover the specific integrations available on each platform.
Q: What is GitOps and why does it matter for cloud native?
A: GitOps is the operational model where a Git repository is the single source of truth for the entire system state — including infrastructure configuration, application manifests, and policy definitions. A GitOps operator (ArgoCD, Flux) continuously reconciles the live cluster state against the repository state, applying changes automatically on commit. GitOps extends the cloud native reconciliation model to the delivery pipeline: the same eventual-consistency model that governs Kubernetes workload scheduling governs how changes reach production. The result is an auditable, self-documenting, self-healing delivery system where every change is a pull request and every deployment is automatic.