The Law of Data Gravity: Why Compute Eventually Moves to the Data
Hybrid cloud isn’t a compromise. It’s what happens when latency, bandwidth, and economics converge.
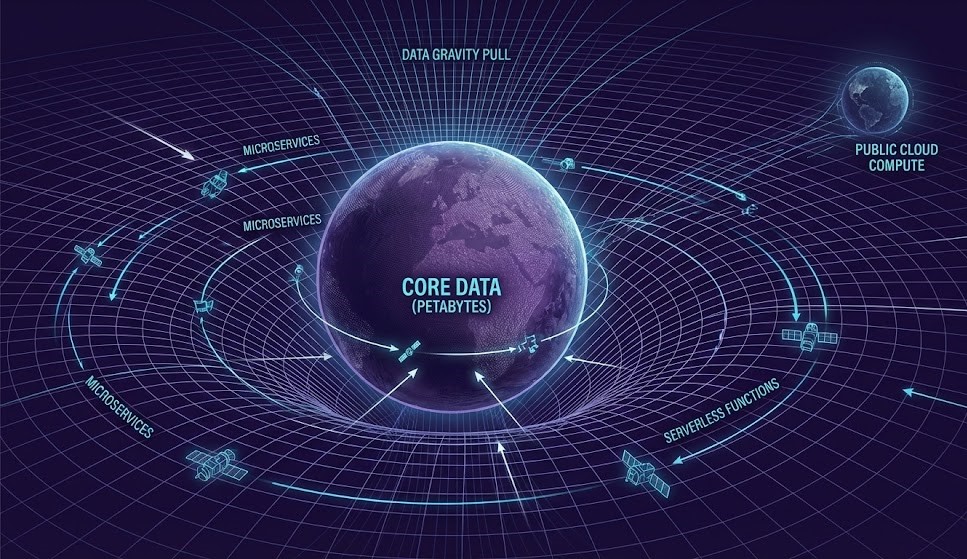
For a decade, the industry operated under a simple assumption: “Move everything to the cloud.” And for a decade, it worked.
Phase 1: The Illusion (2010–2020) We moved Stateless Workloads. Web servers, APIs, and microservices are lightweight. They are “code,” and code has no mass. You can zip it up and deploy it to us-east-1 in seconds. The cloud felt magical because we were moving feathers.
Phase 2: The Collision (2020–Present) Then we tried to move the State. Databases, Data Lakes, and AI Training Sets are not feathers; they are lead. They have Gravity.
The Definition:
Data gravity is the moment infrastructure stops being a cost decision and becomes a location decision.
When you try to lift 5PB of data into the cloud, you hit the wall of physics. Cloud succeeded because compute was scarce. Cloud struggles because data became massive.
The Alarm Bells: The “We Need to Re-Architect” Moment
You don’t need a calculator to know when you’ve crossed the gravity threshold, you just need to listen to the symptoms. You have crossed the line when:
- Daily transfers exceed backup windows. (You can’t protect what you can’t move).
- Replication never catches up. (The lag grows every hour).
- DR testing takes days instead of hours. This is the harsh Disaster Recovery Reality: “Instant Recovery” is mathematically impossible when the dataset exceeds physical IOPS limits.
- Network upgrades improve nothing. (You doubled the pipe, but latency stayed the same).
- Engineers start scheduling jobs “overnight.”
The Viral Truth:
When performance stops scaling with CPU and starts scaling with distance, your architecture is wrong.
The Rack2Cloud Data Gravity Thresholds
Stop guessing. Here is the prescriptive guide to what breaks at scale.
The Formula:
Gravity Limit = (Egress Cost + Transfer Latency) > Recompute Cost
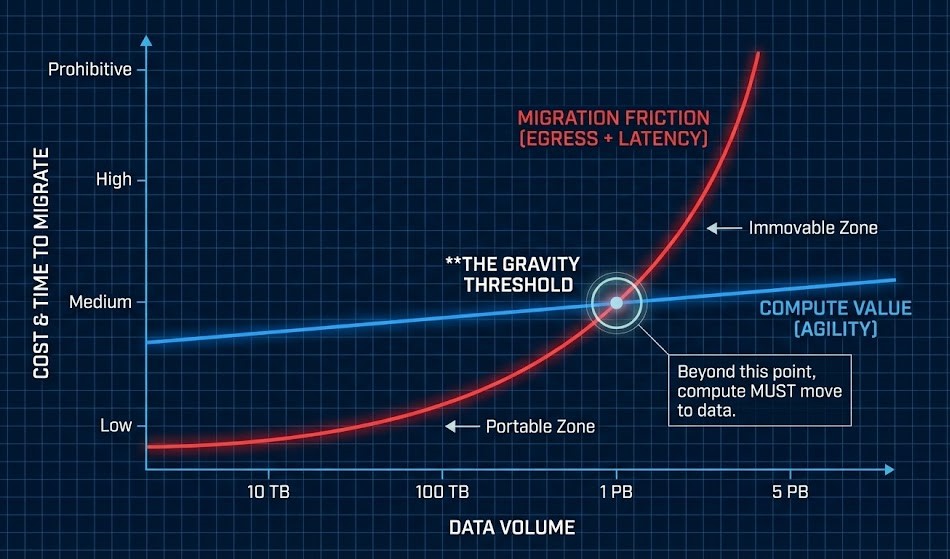
| Dataset Size | Operational Reality | What Teams Try First | What Actually Works |
| 10 TB | Weekend Project | Lift & Shift | Cloud OK (Movable) |
| 100 TB | Painful Migration | Buying a bigger pipe | Caching Layer (Anchored) |
| 1 PB | Architecture Blocker | Parallel Transfers | Local Compute (Hybrid) |
| 5 PB | Impossible | “Multi-Year Migration” | Build Around Data (Immovable) |
At Petabyte scale, migration stops being an “operation” and becomes a construction project.
The Physics: Beyond Just Latency
Teams upgrade bandwidth and nothing improves. That’s when they discover latency wasn’t the bottleneck — coordination was.
1. Bandwidth Saturation (The Egress Tax)
Large data transfers don’t just cost money; they occupy the pipe. If your replication job saturates the Direct Connect link, your API latency spikes.
- Strategic Note: This is why mastering the Cloud Architecture Learning Path is critical—you must design control planes that function independently of data plane congestion.
2. Write Coordination (The CAP Theorem)
You can cache Reads anywhere. You cannot cache Writes. If your database is On-Prem but your App is in AWS, every INSERT creates a lock that spans the WAN. A 2ms transaction becomes 50ms. Throughput collapses.
3. Data Temperature (The Snapshot Tax)
Hot data moves differently than cold archives. Trying to replicate a rapidly changing “Hot” dataset is like trying to fill a bucket with a hole in the bottom. We analyze this phenomenon in The Physics of Data Egress, where “Change Rate” creates a gravity of its own, forcing the data to stay anchored to the source.
AI Breaks the Old Cloud Model
Traditional cloud economics assumed: Compute is expensive, Storage is cheap. Artificial Intelligence reverses this.
In the AI era, Compute (GPUs) is the scarce resource, and Data (Training Sets) is the abundant resource.
The Narrative: The GPU Idle Crisis
A team decides to train a model using Cloud GPUs while keeping their data On-Prem.
The Symptoms:
- GPU Utilization: 15–30% (Idle).
- Network Utilization: 100% (Pegged).
- Training Time: Scales with Dataset Size, not GPU Count.
The Verdict:
The GPUs weren’t slow. The architecture was remote. Training is a continuous streaming workload, not a request/response workload. If the GPU has to wait for data, you are burning money.
- Deep Dive: This inversion is central to our AI Infrastructure Path, where we discuss bringing the GPU cluster to the Data Lake.
The Architecture Inversion Test
We are witnessing a fundamental flip in how systems are designed.
- Old Model: Applications host Databases.
- New Model: Databases host Applications.
How to test your architecture: Ask this question:
“If the database disappears, does the application still exist?”
- Old Architecture: Yes. (The app is the logic).
- Modern Data Systems: No. (The logic is inside the query).
Therefore: The database is no longer a dependency. It is the platform. We see this in modern Cloud Native Architectures, where inference logic runs inside the database query or at the edge to minimize movement.
The Data Gravity Readiness Checklist
Conclusion: The Final Law
Cloud solved deployment. Scale solved compute. But mass determines architecture.
You can virtualize CPUs, abstract networks, but you cannot negotiate with physics.
At small scale, applications choose infrastructure. At large scale, data chooses architecture.
Frequently Asked Questions
Q: What is the “Data Gravity Threshold”?
A: It is the specific point where the cost or time to migrate a dataset exceeds the value of the compute. Operationally, this usually happens between 100TB and 1PB, where migration shifts from a “weekend job” to a “multi-month project.”
Q: Why is Egress Cost considered a tax?
A: Cloud providers charge to move data out of their network to discourage multi-cloud architectures. This creates a “Hotel California” effect: data is easy to ingest (free) but expensive to extract, effectively locking your architecture to one vendor.
Q: Does Hybrid Cloud actually reduce latency?
A: Yes, but only if you respect physics. By keeping the “Heavy” State (Databases) On-Prem near the users, and only pushing “Light” Stateless logic (APIs) to the cloud, you minimize the physical distance the data travels during a transaction.
Additional Resources
- Dave McCrory: Data Gravity Principles: The original foundational text on Data Gravity that defined the core physics of cloud architecture.
- Google Cloud Architecture Framework: Official design patterns for Hybrid and Multi-Cloud estates, specifically addressing data residency.
- FinOps Foundation: Data Transfer Costs: The leading authority on cloud financial management and the impact of egress fees on unit economics.
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session