Client’s GKE Cluster Ate Their Entire VPC: The IP Math I Uncovered During Triage
The Triage: GKE Pod Address Exhaustion
IP_SPACE_EXHAUSTED is often a terminal diagnosis for a production cluster. I recently stepped into a war room where a client’s primary scaling group had flatlined. Workloads were cordoned, deployments were stuck in Pending, and the estimated cost of the stall was nearing $15k per hour in lost transaction volume.
The culprit wasn’t traffic—it was GKE pod IP exhaustion. In the world of Deterministic Engineering, relying on defaults is technical debt you haven’t paid yet. The client assumed a /20 subnet (4,096 IPs) provided ample runway for their growth.
Physics and GKE’s allocation math disagreed.
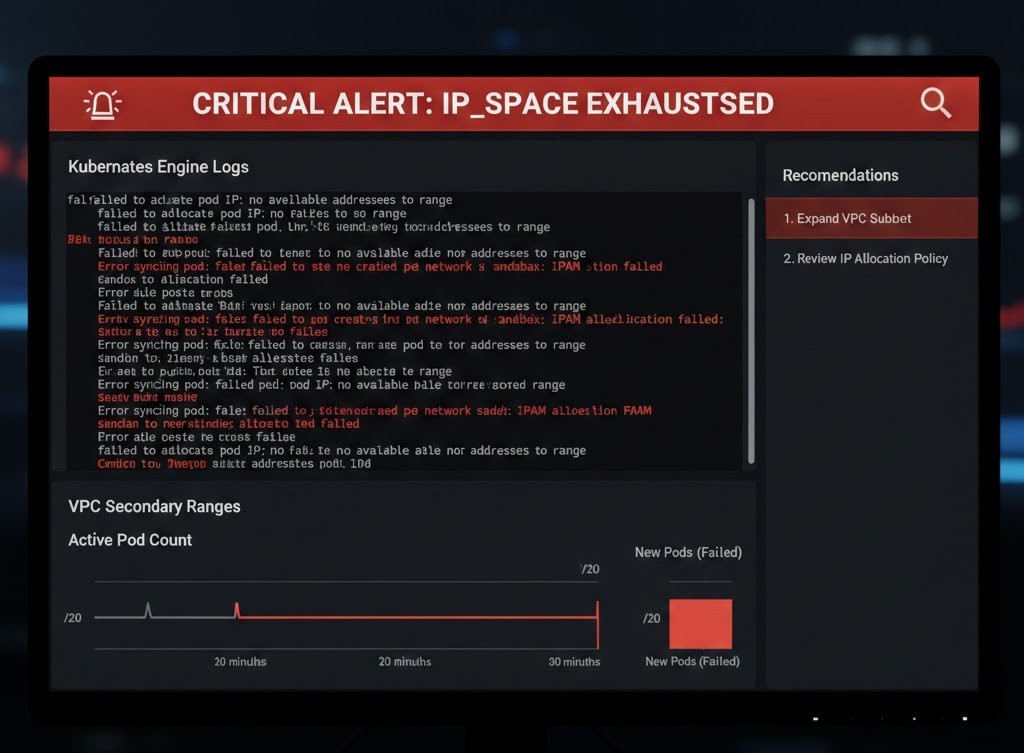
The Math of the “Hidden Killer”
This is where the Cloud Strategy usually falls apart: improper VPC sizing. GKE reserves a static alias IP range for pods per node. By default, it anticipates 110 pods per node. To satisfy that without fragmentation, GKE allocates a /24 (256 IPs) to every single node, regardless of whether that node runs 100 pods or just one.
Here is the breakdown of why that /20 evaporated:
| Waste Type | IPs/Node (Default) | /20 Capacity (4,096 IPs) | Reality Check |
| Pod Reservations | 256 (/24) | 16 Nodes Max | Hard ceiling for the entire VPC. |
| Services (ClusterIP) | 50 (Static) | 2-3% of total | Reserved upfront. |
| Buffer/Fragmentation | ~100 | N/A | The “invisible” cost of bin-packing. |

16 nodes. That’s the hard limit.
In a modern Modern Infra & IaC environment, hitting 16 nodes during a traffic spike is trivial. Once you request the 17th node, GKE cannot provision the underlying Compute Engine instance. The VPC-native alias range is dry.
Taxonomy of Waste
Most engineers check kubectl top nodes, see 40% CPU utilization, and assume they have runway. They don’t. In cloud networking, Address Space is a Hard Constraint, just like IOPS or thermal limits.
- Overprovisioning: The client kept 3 empty nodes for “fast scaling.” Total cost? 768 IPs locked up, doing absolutely nothing. (This specific type of “idle tax” is a primary driver behind our K8s Exit Strategy framework).
- CIDR Fragmentation: Because the secondary ranges weren’t sized for non-contiguous growth, we couldn’t simply append a new range to the existing subnet.
- The “Shadow” Nodes: Abandoned node pools that hadn’t been fully purged still held onto their
/24leases.
The Impact
The result wasn’t just “no new pods.” It was a cascading failure:
- HPA (Horizontal Pod Autoscaler) triggered scale-up events that failed immediately.
- Critical Patches couldn’t deploy because there was no “surge” space for rolling updates.
- Service Instability: Standard Kubernetes Services began to flap as
kube-proxystruggled with the incomplete endpoint sets.
The “Nuclear Option” vs. Actual Engineering
The standard playbook for GKE pod IP exhaustion suggests a full VPC rebuild: tear it down, provision a /16, and migrate the data. While that guarantees a fix, it’s a brute-force approach that introduces massive risk—DNS propagation issues, downtime, and weeks of testing.
We didn’t rebuild the VPC. We didn’t nuke the project. We utilized Class E space (240.0.0.0/4)—a “reserved” and largely forgotten corner of the IPv4 map that most vendors pretend doesn’t exist. We unlocked millions of IPs without moving a single workload offline.
I’m finalizing the documentation on the exact gcloud commands and routing adjustments we used.
Part 2: The Class E Rescue Guide [Coming Soon]
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




