The GKE “Zombie” Feature: Why gcloud Hides What the API Knows

When a Kubernetes founder tells you that you might be wrong about a platform limitation, you don’t argue with them. You open a terminal and try to break something.
This week, following my autopsy of a GKE IP Exhaustion Outage, I entered a debate with Tim Hockin (thockin), one of the original creators of Kubernetes. The contention was simple: Is the Service CIDR in GKE Standard immutable, or does the managed control plane just pretend it is?
Vendor documentation says “No.” The CLI says “Error.” But the architectural intuition says, “Upstream Kubernetes can do this, so why can’t GKE?”
I spent the morning in the lab proving that sometimes, the “Impossible” is just “Hidden.” This is the story of a Zombie Feature—a capability that is alive in the kernel but dead in the dashboard—and why knowing the difference can save your architecture during an outage.
The Decision Framework: Tooling Trust Levels
As architects, we often treat the vendor CLI (gcloud, aws, az) as the single source of truth. This is a mistake. When debugging edge cases or resource constraints, you must decide which layer of the stack to interrogate.
| Tooling Layer | Trust Level | Best Use Case | The Trap |
| Vendor Console (GUI) | Low | Quick visualization, billing checks. | Hides 80% of configuration options to “simplify” UX. |
Vendor CLI (gcloud) | Medium | Day 1 provisioning, standard CRUD ops. | Enforces “Guardrails” that may not exist in the engine. |
Native API (kubectl) | High | Debugging, state validation, granular edits. | Shows raw state, including “unsupported” or beta objects. |
Architect’s Rule: When the CLI says “No,” but the upstream docs say “Yes,” always verify with the Native API.
The Experiment: The “Thockin Challenge”
To test the theory, I spun up a disposable GKE Standard cluster (1.31+) and attempted to force-feed it a new Service CIDR range. The goal was to expand the Service network without rebuilding the cluster—a critical requirement during a live outage.
Test 1: The Front Door (gcloud)
The Google Cloud CLI is the curated path. It applies the “safe” defaults Google wants you to use. I attempted to update the cluster using standard secondary range flags.
Bash
gcloud container clusters update $CLUSTER_NAME \
--update-service-secondary-range="new-service-range=10.99.0.0/20"
The Result: unrecognized arguments.
The CLI didn’t just fail; it gaslighted me. It threw an error claiming the argument doesn’t exist. If you were an engineer troubleshooting an outage at 3 AM, this is where you would stop. You would assume the platform physically cannot support the request.
Test 2: The Back Door (kubectl)
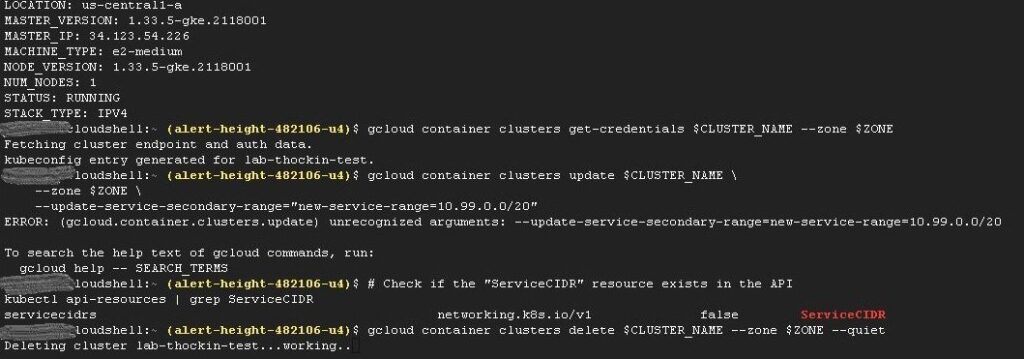
If the CLI is the menu, the API is the kitchen. I bypassed the vendor tooling and queried the API server directly to see if it recognized the upstream ServiceCIDR resource.
Bash
kubectl api-resources | grep ServiceCIDR
The Result:
Plaintext
NAME APIGROUP NAMESPACED KIND
servicecidrs networking.k8s.io/v1 false ServiceCIDR
The Verdict: The resource is right there. It is false (cluster-scoped), it is v1 (stable), and the API server is actively listening for it. The feature isn’t missing; the door handle is just removed.
Operational Cost Analysis (OpEx Impact)
We often talk about cloud costs in terms of licensing and compute (CapEx), but the hidden killer is Operational Expense (OpEx) during downtime.
In the outage that sparked this research, we faced a “rebuild vs. repair” decision.
- Scenario A (Trust the CLI): The CLI says we can’t add IPs. We must rebuild the cluster.
- Cost: 4 Engineers x 12 Hours + Business Downtime = High OpEx.
- Scenario B (Trust the API): The API reveals a path to patch the configuration.
- Cost: 1 Architect x 2 Hours + Zero Downtime = Low OpEx.
Knowing that ServiceCIDR exists in the API changes the risk calculation. Even if patching it is “unsupported” by Google Support, having the option to fix it in a crisis is a powerful lever. To avoid getting trapped by these vendor limitations again, review our portfolio of deterministic tools for a non-deterministic cloud to audit your environments before the outage hits.
The Architect’s Note
Would I cowboy-engineer a manual API patch for ServiceCIDR in a production cluster on a Tuesday afternoon? No. That creates “drift” between your Terraform state (which relies on the Google API) and the actual cluster state.
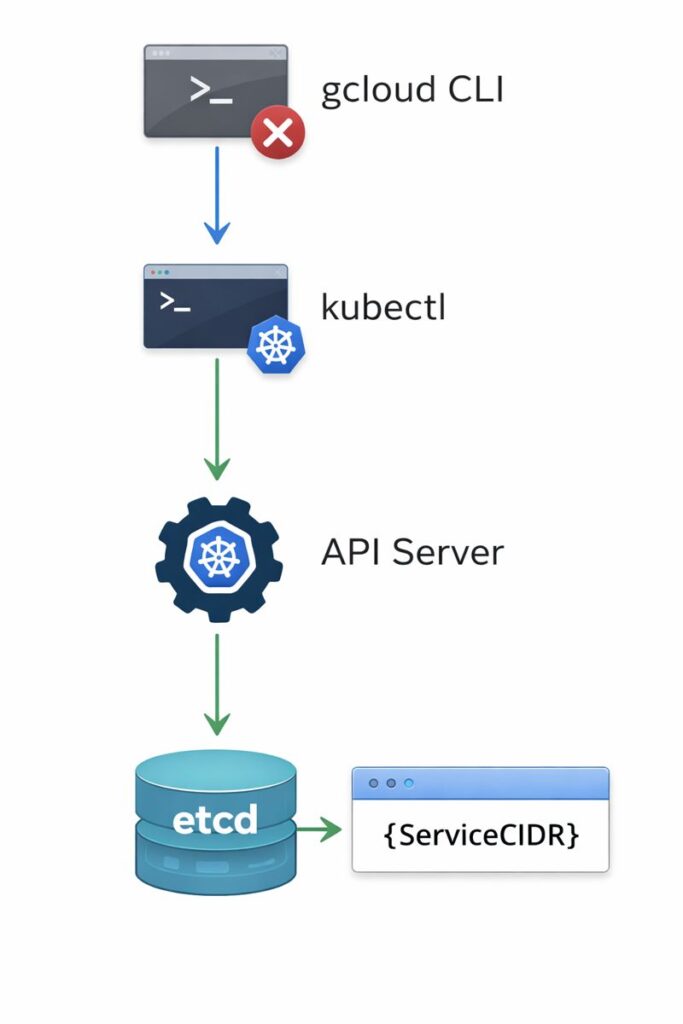
However, during a P0 outage, the rules change. Knowing the difference between a Technical Block (the kernel can’t do it) and a Tooling Block (the CLI won’t let you) is what separates a Senior Engineer from a Staff Architect.
Special thanks to Tim Hockin for sending me down this rabbit hole.
External Research
- Kubernetes Docs: ServiceCIDR (Upstream)
- Google Cloud SDK: gcloud container clusters update
- GKE Networking Best Practices
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




