Your Identity System Is Your Biggest Single Point of Failure

Part 2 of the Rack2Cloud’s Cloud Fragility Series
The Skeleton Key Problem
Over the last ten years, companies poured everything into Zero Trust — and quietly traded identity resilience for identity convenience. Apps moved behind SSO, conditional access rules kept multiplying, and suddenly, multi-factor authentication was everywhere. Security shot up.
But resilience quietly slipped away.
Companies started funneling all authentication through a single source—usually a SaaS identity provider like Okta or Microsoft Entra ID. Then they spread that authority everywhere: every cloud, every tool. This made things simple. One place to grant access, yank privileges, and check what’s going on.
But now everything depends on that one spot.
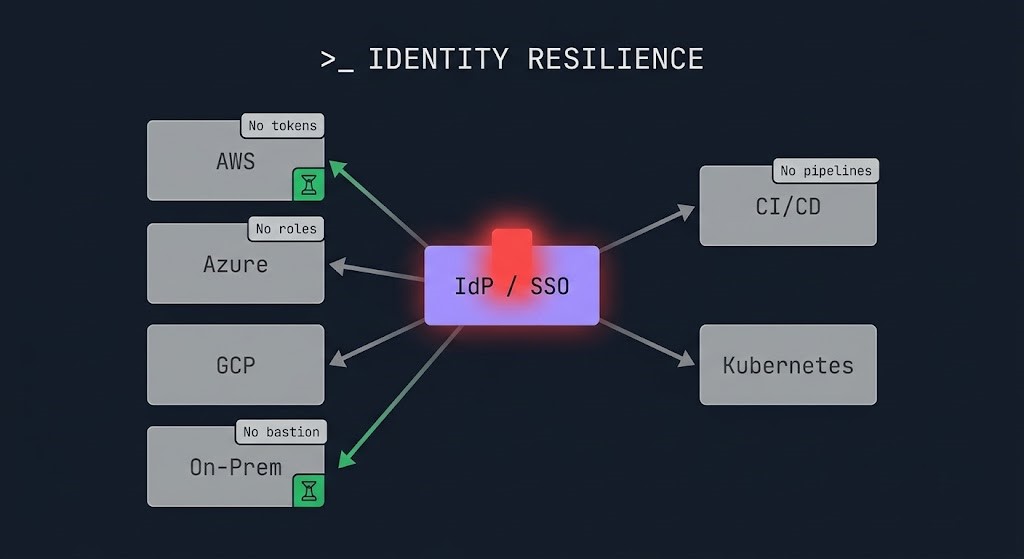
Right now, the same identity engine decides who gets into your AWS, Azure, Google Cloud, and anything you’ve got running on-prem. Build pipelines, monitoring dashboards, finance apps, incident consoles, Kubernetes clusters—they all trust that outside authority to hand out tokens before anything happens.
From a security angle, it looks clean. From a resilience angle, it’s brittle. We locked down every door but swapped every key for a single master—and then left that key outside the building.
The Blind and Bound Scenario
Earlier in this series, we looked at how failures ripple through multi-cloud setups. Identity is the invisible thread that lets those ripples turn into full-on cascades.
When the identity provider hiccups, the obvious problem is that users can’t log in. But that’s just the surface. Engineers are locked out too. Automation can’t run. Recovery plans don’t even get off the ground.
The systems themselves? Still humming. Dashboards stay green. Infra keeps running. But the people who run everything are locked out of the controls.
You end up with a Blind and Bound state. You know something’s broken, but you can’t do anything about it.
- Terraform can’t assume roles.
- CI/CD can’t push fixes.
- Bastion hosts just say no.
- Privilege escalation? Forget it.
It all depends on the same authority that’s now missing.
It’s not like a compute outage—nothing’s obviously broken. It’s not like losing storage—no data’s gone. What you get is paralysis. Every fix needs authentication, and now, authentication doesn’t exist.
Identity failures just hit differently. Database down? That’s one service. Network down? That’s one region. Identity down? That’s operations itself.
Identity isn’t just another layer inside your stack. It’s the layer that lets you run everything else.
The Hidden Dependency Stack
Logging in looks simple enough, but there’s a whole chain of systems working together behind the scenes. The console kicks you to an external provider. That provider signs off. The cloud swaps that for a session. Every tool after that trusts the session.
If the identity provider can’t issue tokens, everything downstream fails at once—across all clouds. Multi-cloud still means one authority, so it’s one giant point of failure.
That’s why identity outages spread so fast. They’re not limited by region or network. They float above all that.
You spread your compute risk, but you stacked your trust risk in one place.
Caption: Centralized IdP—one failure, everything stops, no matter how “diverse” your infrastructure really is.
Architecting for Identity Resilience
If you treat identity as just a convenience, you’ll hit dead ends. When you treat it like critical infrastructure, you start thinking differently. Redundancy, isolation, and failover can’t just live in your data plane—they have to live in your trust plane too.
1. Native, Non-Federated Emergency Access
First, you need real, non-federated emergency access. Every cloud should have at least two admin accounts that don’t rely on SAML or OIDC federation. These are for disaster scenarios. Protect them with hardware-based MFA, keep their credentials offline, and only touch them under strict procedures.
Audit, rotate, and—most importantly—test them. An untested break-glass account is just for show.
2. Session Survivability
Second, think about session survivability. Security teams love to set super-short sessions, but when identity goes down, those sessions kick everyone out mid-fix. Let privileged engineering sessions last through hours of instability so people can keep working while the provider recovers. You still stay secure with privilege elevation workflows, instead of just kicking everyone out when the timer runs out.
3. Independent Trust Capability
Let’s talk about independent trust capability. Critical systems—think banks, hospitals, or production AI—work best when they have a backup authentication authority that runs separately from the main directory. You don’t toss out centralized identity, but you do give yourself another way to keep things running if something breaks. If you do this right, you shrink the fallout from identity outages, and you don’t lose control or oversight.
4. Simulated Identity Failure
Now, here’s something most companies don’t do: simulate identity failure. Disaster recovery drills usually cover things like regional blackouts, ransomware, or a corrupted database. Almost nobody tests, “What if our identity provider just gives up and returns HTTP 503 everywhere?”
But that’s the nightmare scenario. Suddenly, your operators can’t log in or fix things—even though the infrastructure’s fine. It’s a different kind of outage, and honestly, a scarier one.
Identity in Machine-Driven Environments
As automation takes over, identity resilience matters more than ever. These days, most workloads are machines talking to machines. AI pipelines hit storage again and again during training. Inference engines need tokens to reach feature stores. FinOps tools pull cost data through service accounts.
When identity breaks, machines can’t work around it. They just stop.
It’s not a user access issue anymore—it’s about keeping workloads alive. Outages don’t just keep employees out; they shut down your automated systems.
The Economic Impact of Identity Failure
Here’s the thing: identity outages rarely show up on public dashboards because the servers and networks are still up. The pain hits behind the scenes—delayed launches, stuck pipelines, missed SLAs, frantic manual fixes, and urgent calls to leadership.
You won’t log this as downtime, but it chips away at productivity and trust. Over time, these little hits wear down your reliability culture, even if your uptime stats look good.
Availability isn’t just about security or blocking hackers. It’s about making sure the right people and systems always get in when they need to.
Identity Is Core Infrastructure
Nobody would launch a global database without backup or power a hospital from a single plug. Yet, a lot of companies trust one SaaS identity provider for everything.
That’s not just a tool choice—it’s a big architectural bet.
Centralizing identity makes oversight easier. Building in redundancy keeps you alive when things go wrong. You need both if you want a mature architecture.
From Single Key to Distributed Trust
Most organizations follow a familiar path.
- First, identity is centralized—it’s easy.
- Then you toughen it up with MFA and conditional access.
- Later, you add emergency access and polish session policies.
- Eventually, you set up independent trust authorities for your most critical systems.
At the top, the best setups spread trust so no single identity service can freeze everything. You have to treat identity like a control plane, not just another app.
If you look across the whole series, there’s a pattern: Most modern outages don’t start with compute or storage. They start in the shared control layers.
And identity? It’s the one people underestimate the most.
The Control Plane Nobody Audits
Identity resilience audits almost never happen because identity never appears on the infrastructure monitoring dashboard. Servers are up. Networks are healthy. Databases are responding. The identity provider returns 503 and none of those signals change — until engineers try to act and discover they cannot.
The audit question is simple: if your primary identity provider became unreachable for four hours right now, which systems could your team still access, which automated workloads would keep running, and which recovery actions would be completely blocked? Most teams cannot answer this without running the scenario. Most teams have never run the scenario.
That is the audit. Run it before an incident forces it. The identity system single point of failure post covers the architectural patterns — break-glass accounts, session survivability, independent trust authorities — but the patterns only matter if you have tested them under simulated failure conditions. Untested identity resilience is documentation, not capability.
Architect’s Verdict
Identity resilience is the most consistently under-engineered capability in enterprise cloud architecture. Not because teams don’t understand the risk — most security architects can articulate exactly what happens when the IdP goes down. It’s because identity resilience work produces no visible capability improvement until the failure happens. There is no performance gain, no feature shipped, no cost saved. There is only the absence of a very bad day.
The organizations that have invested in break-glass access, session survivability, and independent trust authorities are not more paranoid than the ones that haven’t. They are the ones that have experienced an identity outage — or that have a decision-maker who has. The pattern is consistent across the industry: identity resilience gets funded after the first significant incident, not before.
Don’t wait for the incident. The four architectural controls in this post — non-federated emergency access, session survivability, independent trust capability, and simulated failure testing — are not a complete identity resilience program. They are the minimum viable version. Build them, test them, and treat the identity layer with the same operational discipline you apply to your most critical databases. If every action in your operation requires permission from a single external authority, you don’t have high availability. You have conditional availability — and the condition can fail.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session