Infrastructure that scales, recovers, and evolves—deterministically.
Modern infrastructure doesn’t fail because hardware breaks. It fails because the people managing it never agreed on what it was supposed to look like.
Snowflake servers. Manual provisioning. Tribal knowledge encoded in runbooks nobody reads until the incident is already active. Configuration that drifted six months ago and nobody noticed until a security audit or a 2 AM outage surfaced it. Staging environments that are “almost the same” as production — until they’re not.
The infrastructure that fails isn’t the infrastructure that broke. It’s the infrastructure that was never designed to fail deterministically.
Modern infrastructure is defined by one question: when something goes wrong, does the system recover predictably — or does it require a senior engineer who remembers how it was originally built?
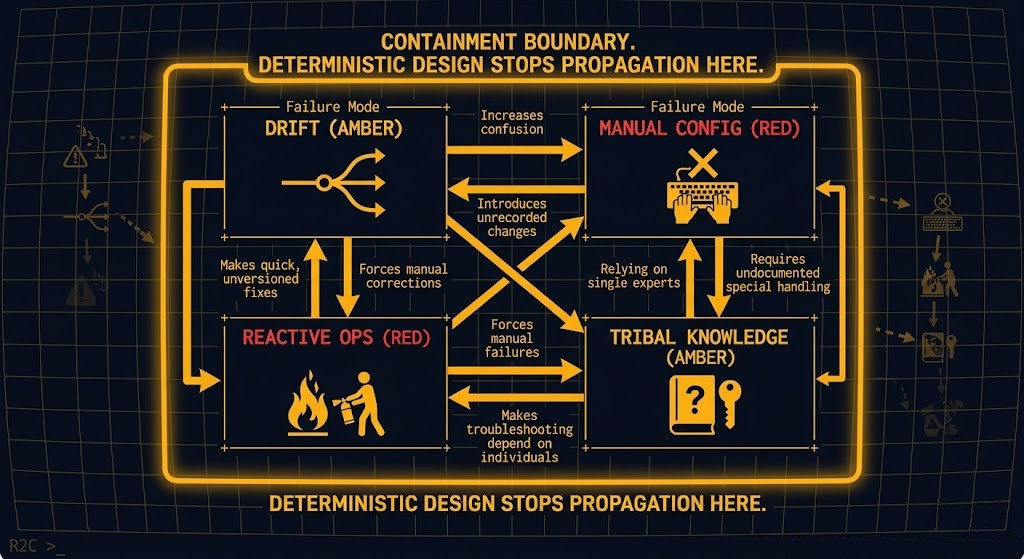
Why Modern Infrastructure Fails
Infrastructure failures have a consistent taxonomy. The hardware is rarely the problem. The architecture almost always is.
| Failure Mode | Root Cause | Why It Compounds |
|---|---|---|
| Configuration Drift | Declared state diverges from actual state silently | Each drift event makes the next one harder to detect |
| Manual Provisioning | Human decisions encoded in runbooks, not code | Knowledge lives in people, not systems — people leave |
| Reactive Operations | Day-2 is treated as a separate concern from design | Patching and scaling become incidents, not scheduled events |
| Silo Architecture | Networking, compute, and storage managed independently | Changes in one domain produce undocumented failures in another |
| Untested Recovery | Failure scenarios are designed for but never validated | Recovery plans work in theory and fail at 2 AM |
The pattern is consistent across on-premises, cloud, and hybrid estates. The technology changes. The failure modes don’t.
The Kubernetes scheduler fragmentation failure is a canonical example — the infrastructure appeared healthy by every dashboard metric while pods accumulated in pending state. The failure wasn’t the cluster. It was the absence of deterministic placement policy. The CPU ready vs CPU wait diagnostic covers the same pattern at the hypervisor layer — infrastructure that looks fine but feels slow, because the metrics being watched are the wrong metrics. The service mesh vs eBPF decision is where networking control plane determinism plays out at the Kubernetes layer — policy enforcement that either holds under failure or silently degrades.
The Four Laws of Deterministic Infrastructure
Modern infrastructure is not a tool selection problem. It is an architecture philosophy. These four laws define whether an infrastructure estate is deterministic or probabilistic.
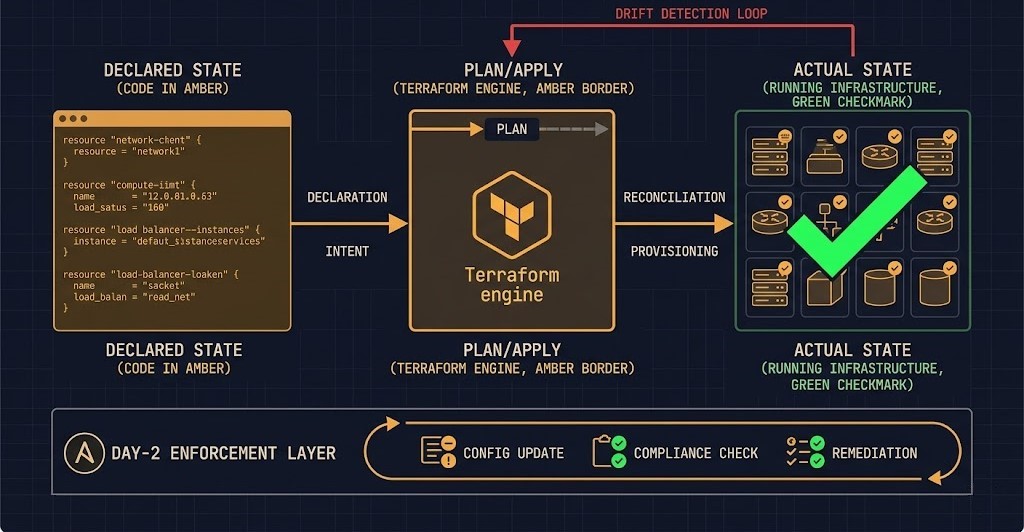
IaC as the System Lens
Infrastructure as Code is not an automation tool. It is the mechanism by which infrastructure intent becomes infrastructure reality — and the only mechanism that makes that relationship auditable, reversible, and reproducible.
The distinction between imperative and declarative is where most IaC implementations fail. Scripts describe steps. Declarative code describes outcomes. When the steps change but the outcome doesn’t, imperative scripts drift. Declarative code reconciles.
Terraform — Desired State to Actual Behavior:
hcl
# Declare what should exist
resource "aws_instance" "web" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = "t3.medium"
tags = {
Name = "web-production"
Environment = "production"
ManagedBy = "terraform"
}
}
# Terraform enforces this state on every apply
# Manual changes are detected as drift on next plan
# Recovery = terraform apply, not incident responseThe critical architectural property: Terraform’s state file is the source of truth. Any manual change made outside Terraform will surface as drift on the next terraform plan. This is not a limitation — it is the enforcement mechanism. Drift detection is built into the workflow.
The GitOps for bare metal post covers how this same declarative enforcement applies to physical hardware — the SDLC discipline that makes infrastructure changes as auditable as application code.
Ansible — Day-2 State Enforcement:
yaml
# Enforce configuration state on every run
- name: Enforce NTP configuration
hosts: all
become: true
tasks:
- name: Ensure chrony is installed and running
package:
name: chrony
state: present
notify: restart chrony
- name: Deploy chrony configuration
template:
src: chrony.conf.j2
dest: /etc/chrony.conf
notify: restart chrony
handlers:
- name: restart chrony
service:
name: chronyd
state: restarted
enabled: true
# Run this playbook on every node, every week
# Result is always the same — idempotent by design
# Drift from the desired NTP state is corrected automaticallyAnsible’s idempotency guarantee means the same playbook run against a correctly configured system produces no changes. Run against a drifted system, it corrects the drift. This is the operational equivalent of Terraform’s declarative enforcement — applied to the Day-2 layer.
The containerd Day-2 failure patterns post covers what happens when Day-2 operations are treated as manual processes — the failure modes that accumulate silently until they surface as incidents.
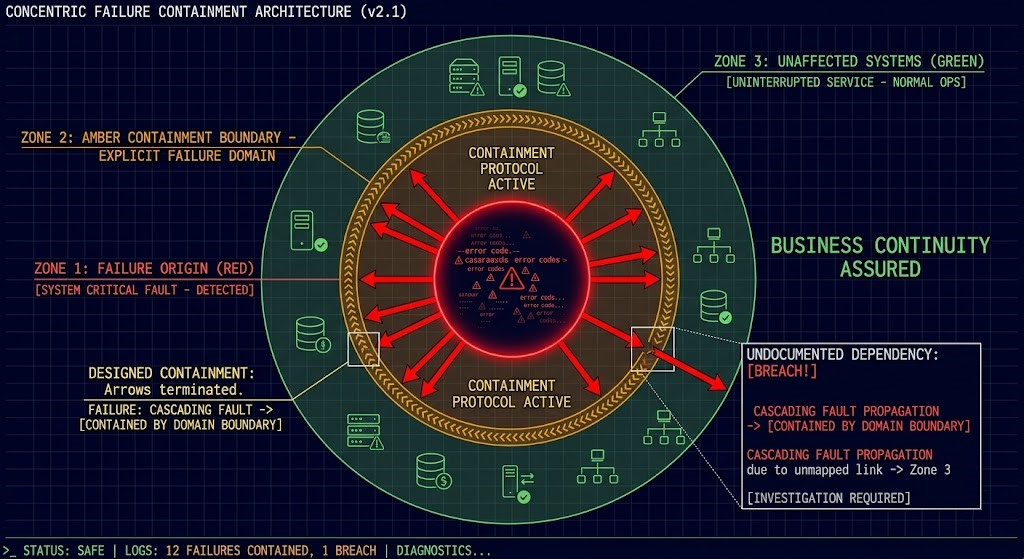
Failure Domains & Blast Radius Design
Every infrastructure failure has a propagation path. The question is whether that path was designed or discovered.
Blast radius is an architectural decision made before the incident. If it isn’t made deliberately, it defaults to “everything” — which is how a single misconfigured load balancer takes down an entire application tier, or a failed storage node cascades into compute unavailability.
The blast radius design principle:
A failure in Domain A should not propagate to Domain B unless Domain B explicitly depends on Domain A and that dependency has been designed with a graceful degradation path.
This requires three architectural decisions made at design time:
Explicit failure domains — network segments, power zones, availability zones, or logical boundaries that define the maximum propagation surface of any single failure. The Kubernetes PVC stuck volume node affinity post is a concrete example of what happens when storage failure domains aren’t designed explicitly — a volume pinned to a failed node takes the workload with it.
Tested recovery paths — every failure domain must have a documented and tested recovery sequence. Untested recovery is theory. The ingress 502 debug post covers the diagnostic methodology for failure scenarios that cross multiple domains — MTU, DNS, and routing failures that appear as a single symptom.
Chaos validation — failure scenarios must be exercised before incidents force them. Running chaos experiments against a staging environment that shares no infrastructure with production validates nothing. The failure domains in production are the ones that need testing.
Modern Infra in Action
These are production failure patterns — not hypotheticals. Each one illustrates a specific failure mode that deterministic infrastructure design prevents.
InPlaceOrRecreate mode showed pods cycling through pending → running → pending on a 4-minute interval. Dashboard metrics showed healthy node utilization. No alerts fired.Infrastructure Maturity Model
Maturity is measured by one metric: how much human intervention is required to maintain the production state.
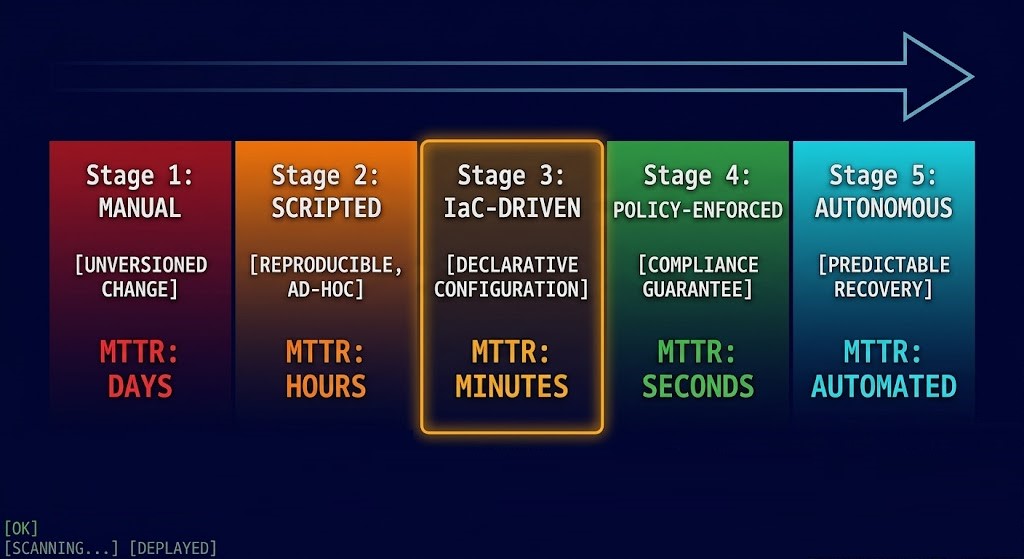
Decision Framework — Red Flags vs Right Patterns
This is the section AWS and GCP don’t provide. Most infrastructure guidance tells you what to build. This tells you whether what you’ve built is working.
You’ve seen how modern infrastructure is architected. The pages below cover the execution domains — the operational layers where declarative intent becomes running infrastructure — and the adjacent pillars that define where modern infra fits in your broader environment.
Architect’s Verdict
Modern infrastructure is boring when it’s working correctly. That’s not a limitation — it’s the design goal.
The teams that achieve deterministic infrastructure aren’t the ones with the most sophisticated tooling. They’re the ones who made the unglamorous decisions first: defining failure domains before deploying workloads, enforcing IaC before the first exception, testing recovery before the first incident.
Do this:
- Declare state before deploying infrastructure — never the reverse
- Enforce drift detection in every environment, including staging
- Test recovery paths on the same cadence you test features
- Treat Day-2 operations as a design constraint, not an operational afterthought
- Set blast radius boundaries explicitly — undocumented dependencies become incident scope
Avoid this:
- Deploying workloads before governance and policy layers exist
- Treating Ansible or Terraform as deployment tools rather than state enforcement engines
- Accepting “almost the same” between staging and production as good enough
- Discovering failure domains during incidents instead of during design
- Measuring infrastructure health by uptime instead of MTTR
The infrastructure that scales, recovers, and evolves deterministically isn’t the infrastructure that never fails. It’s the infrastructure that was designed to fail predictably — and built to recover faster than anyone needs to intervene.
You’ve Adopted the Tooling.
Now Validate the State Management Beneath It.
Terraform state drift, Ansible idempotency failures, GitOps pipeline gaps — IaC implementations that look clean in version control accumulate configuration debt in production. The triage session validates whether your infrastructure code actually reflects what’s running and where the drift is hiding.
IaC Architecture Audit
Vendor-agnostic review of your infrastructure-as-code implementation — Terraform state management, module structure, drift detection coverage, Ansible playbook idempotency, GitOps pipeline completeness, and the manual change patterns that are eroding your declared state over time.
- > Terraform state architecture and drift detection
- > Module structure and reuse patterns review
- > GitOps pipeline completeness and secret management
- > Configuration drift inventory and remediation plan
Architecture Playbooks. Every Week.
Field-tested blueprints from real IaC environments — Terraform state corruption incidents, OpenTofu migration case studies, GitOps pipeline failure post-mortems, and the drift management patterns that keep declared infrastructure state accurate over multi-year operational lifetimes.
- > Terraform State & Drift Management
- > GitOps Pipeline Architecture & Failures
- > OpenTofu Migration & IaC Modernization
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: Is IaC only relevant for cloud infrastructure?
A: No — IaC is more critical for on-premises and sovereign infrastructure than for cloud. Cloud providers give you API-driven control planes by default. On-premises environments require IaC to impose the same discipline on hardware that resists it. The GitOps for bare metal post covers exactly this — applying software development lifecycle discipline to physical infrastructure.
Q: AWS has Config and Control Tower for drift detection. What’s the IaC equivalent for on-premises?
A: AWS Config detects drift within AWS. Terraform’s state file detects drift across any infrastructure — cloud, hybrid, or on-premises. The architectural pattern is the same: declare desired state, compare against actual state, surface divergence. Terraform’s plan output is functionally equivalent to an AWS Config drift report — but it works regardless of where the infrastructure lives.
Q: Does automation increase the risk of large-scale outages?
A: Automation surfaces existing risks faster and at larger scale — which is not the same as creating new risk. Manual infrastructure accumulates hidden failures that compound until they produce catastrophic incidents. Automated infrastructure surfaces failures earlier, at smaller scope, with faster recovery. The Kubernetes Day-2 failures post covers the specific failure modes that accumulate in manually managed container infrastructure.
Q: What’s the difference between Terraform and Ansible — when do I use each?
A: Terraform provisions infrastructure — it creates, modifies, and destroys resources. Ansible enforces configuration state on running infrastructure — it ensures the OS, services, and application configuration match the declared state. Terraform handles the provisioning layer. Ansible handles the Day-2 layer. They’re complementary, not competing. Most production environments need both.
Q: How do I know if my blast radius is too large?
A: If a single component failure affects systems that don’t directly depend on it, your blast radius is too large. Undocumented dependencies are the primary blast radius expander — a storage node failure that takes down networking because both share a management plane that was never explicitly scoped as a dependency. The resource pooling physics post covers how shared resource pools silently expand blast radius at the hypervisor layer.
Q: Can legacy systems be migrated into a modern infrastructure pattern?
A: Yes — but incrementally. Start by placing the networking and storage layers under software-defined control planes before attempting full IaC provisioning. The migration sequence matters: networking → compute → storage → application tier. Attempting full IaC on a legacy estate simultaneously produces the same governance debt as deploying workloads before the landing zone exists.