The Physics of Data Egress: How to Burn $180k in a Weekend
Data gravity is a financial weapon.
In 2026, the easiest way to bankrupt a startup isn’t a security breach—it’s an unmonitored aws s3 sync command running across availability zones.
I watched a Fortune 500 client lose $180,000 in 48 hours because a data engineer treated a cloud pipe like a LAN cable. It wasn’t a hack. It was physics meeting economics.
Cloud providers market storage as “pennies per gigabyte.” They don’t mention that moving those gigabytes costs dollars. If you ignore the velocity of your data, you don’t just risk inefficiency. You risk architectural insolvency.
Here is the math they hide in the pricing calculator.
Egress Fundamentals: The Physics of “Gravity”
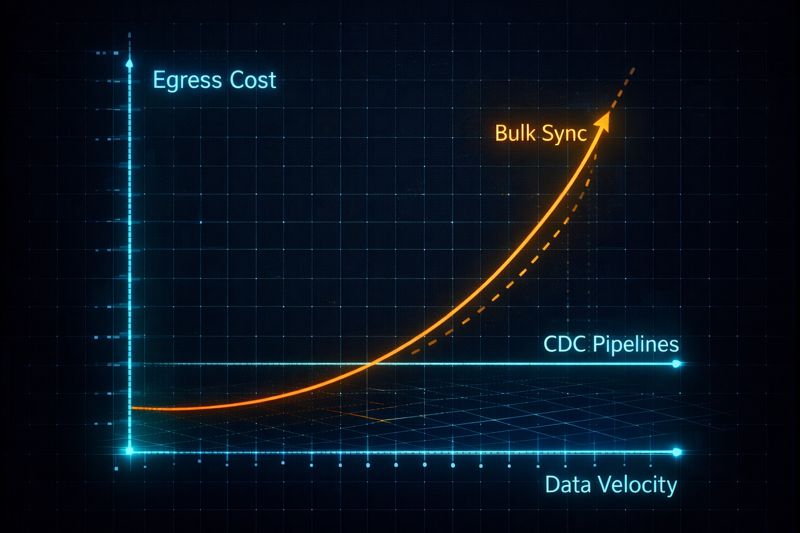
Data egress obeys physical constraints in much the same way gravity does: the more mass you accumulate, the harder it becomes to move. Cloud vendors invert this natural law by amplifying cost as distance and velocity increase. I model this using a simple heuristic:
Egress Gravity=Volume×Dependency×VelocityVolume is obvious — terabytes become petabytes faster than teams expect. Dependency is the hidden multiplier: every downstream system that requires that data increases the cost of movement and the blast radius of failure. Velocity is the real killer. Static archives are cheap to move once. Streaming systems never stop moving — and therefore never stop billing.
Vendor white papers claim compression solves this. In real-world systems, it rarely does. Compression works on bulk, low-change datasets. It fails on high-velocity streams — log ingestion, CDC replication, ML inference telemetry — where entropy is high and the batching window is low. In those environments, compression reduces size marginally but does nothing to address the physics of continuous movement.
This is why CDC architectures matter. They don’t compress the data — they eliminate unnecessary movement by transmitting only the semantic delta. Minimize cold paths, eliminate unnecessary state movement, and collapse cost into deterministic flows. The same principle governs the Modern Infrastructure & IaC architecture philosophy: eliminate waste at the design level, not the remediation level.
The Bandwidth Throttle
Even if money were no object, bandwidth remains a hard ceiling. A 10Gbps link under perfect conditions caps at roughly 1.25 GB/s. That means a 500TB dataset requires a minimum of 112 hours to transfer — assuming zero packet loss, no retries, no throttling, and no competing workloads.
In practice, real-world throughput is lower. TCP backoff, encryption overhead, NAT traversal, and transient congestion all degrade effective bandwidth. This is why we never trust vendor calculators when planning migrations. We baseline with iperf3 in isolated environments to measure actual sustained throughput under production-like conditions before committing to timelines or budgets.
Bandwidth throttles do more than slow migrations — they extend cost exposure windows. Every hour a transfer runs is another hour of metered egress. Physics doesn’t just constrain speed; it compounds financial risk. For Metro cluster environments where cross-site latency directly impacts replication cost, this bandwidth physics problem is examined in depth in The Physics of Disconnected Cloud.
Economic Forces: CapEx vs. OpEx
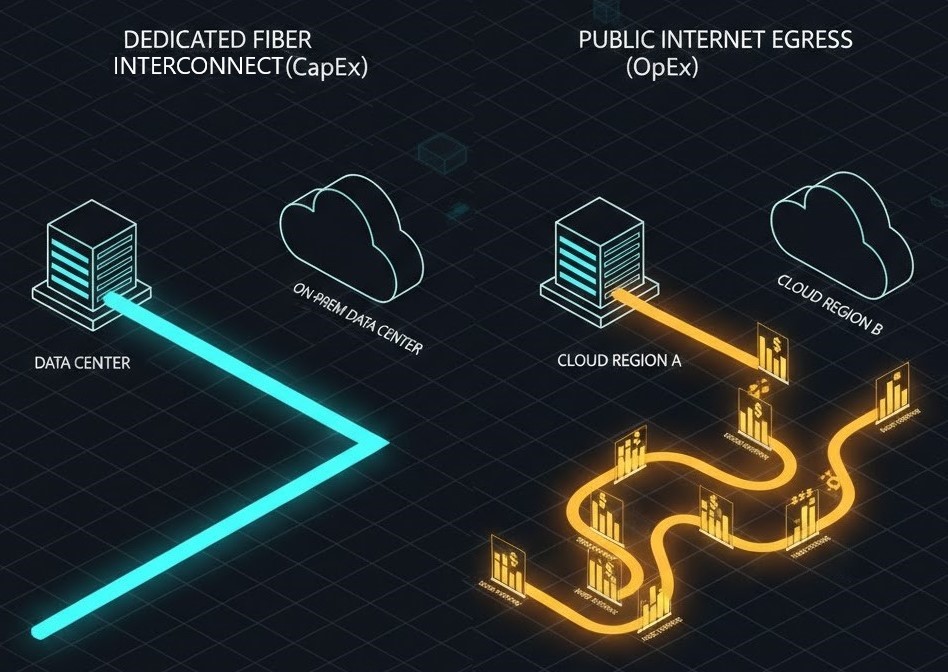
In the data center, you pay for the pipe. In the cloud, you pay for the liquid flowing through it. This inversion fundamentally alters how architects must think about infrastructure economics.
With dedicated interconnects — AWS Direct Connect, Azure ExpressRoute, or Google Cloud Interconnect — you incur upfront port fees and commit to capacity. But once provisioned, data movement becomes effectively amortized. You pay for the pipe whether you use it or not, which means marginal transfers approach zero cost.
Public internet egress flips that model. There is no upfront commitment, but every gigabyte is metered. At scale, this becomes punitive. A single petabyte of annual transfer at AWS public egress rates exceeds $90,000 — before retries, replication overhead, or multi-destination fan-out.
Architecturally, this forces a choice: predictable CapEx with bounded risk, or unbounded OpEx with unpredictable failure exposure. We treat this not as a financial decision but as a reliability one. Cost stability and failure domain containment are first-class architectural requirements — a principle covered in the Cloud Architecture Learning Path.
The Licensing Trap
Egress is not just a network problem — it’s a licensing problem disguised as one.
Many enterprise software licenses count data movement as usage. VMware vMotion charges per-VM hops across clusters. Oracle and SQL Server often require full licensing for standby replicas, even if they are passive. Some vendors treat DR replicas as production instances for billing the moment they receive write traffic.
This turns hybrid and multi-cloud architectures into legal minefields. Teams optimize network topology only to discover that the licensing model negates the savings — or worse, creates compliance risk.
The internal rule: if licensing overhead causes egress-related OpEx to exceed 5% of total system TCO, the architecture must be rewritten. That usually means replacing proprietary platforms with open formats and open-source runtimes in secondary regions — PostgreSQL instead of Oracle, Parquet instead of proprietary storage, Linux instead of commercial UNIX. This philosophy aligns directly with the Broadcom Exit Strategy — where exit cost, not feature richness, determines platform viability.
Architecture Decisions & Real-World Migrations
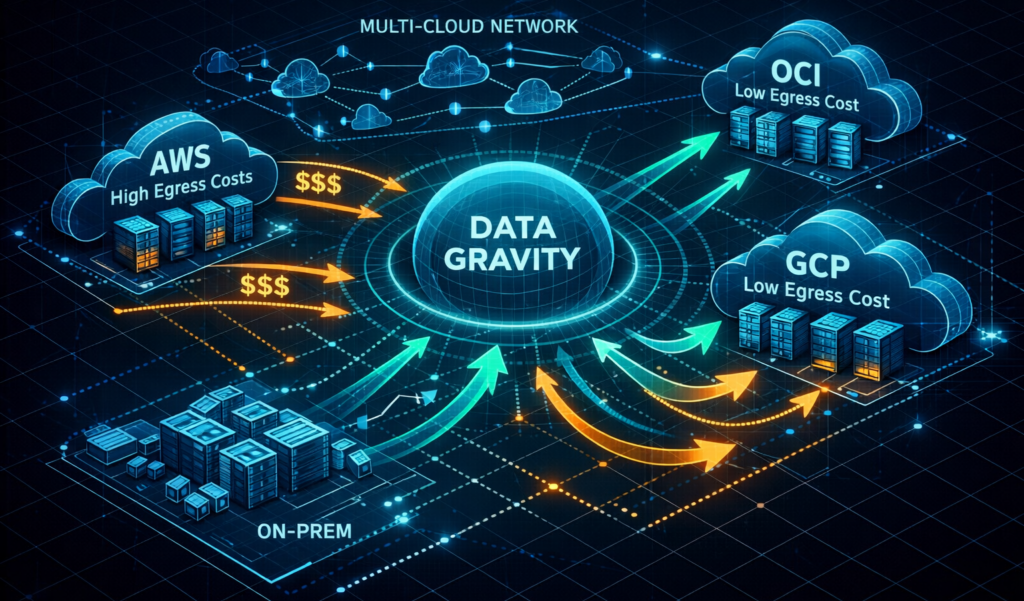
When designing for Day-2 operations, features matter far less than the cost of exit. The most dangerous architectures are not the ones that fail loudly — they are the ones that succeed expensively.
In multi-cloud environments, provider selection must be driven by data movement economics, not marketing. OCI and GCP offer near-zero egress for intra-region and inter-service movement, making them structurally superior for data gravity workloads — analytics, AI pipelines, and backup fabrics. AWS remains indispensable for latency-sensitive workloads and service breadth, but is rarely the optimal home for high-volume data mobility.
This creates a natural hybrid pattern: compute where latency matters, data where gravity dominates. The mistake teams make is allowing vendors to offer “free egress” as a lure — only to trap data inside proprietary storage formats or managed services that eliminate portability. Egress is only free if your data can actually leave.
This is why open formats — Parquet, ORC, Avro — and open replication protocols — CDC, Kafka, Debezium — are non-negotiable architectural guardrails. Portability is not an afterthought. It is the foundation of economic resilience. These principles are codified in the Modern Infrastructure & IaC Learning Path.
Case Study: The 2PB Escape
A financial services client was exiting AWS for OCI with 2 petabytes of data. Their original architecture relied on nightly S3 exports and batch syncs to downstream systems, creating massive egress spikes during quarterly close cycles.
We replaced bulk replication with CDC using Debezium, reducing transfer volume by 92%. High-velocity transactional changes were streamed in near real-time, while cold historical data was migrated via dedicated fiber.
The result: the entire migration completed in under 48 hours and avoided approximately $250,000 in transfer fees compared to direct public egress.
In contrast, a retailer attempting an unoptimized S3-to-Azure lift burned over $60,000 per week until the replication layer was re-architected. The difference between those outcomes was not tooling. It was physics awareness.
Cost Optimization Framework
If your organization is bleeding money today, you need a triage protocol — not a strategy deck.
Step 1 — Audit velocity, not volume. Use CloudWatch Logs Insights, VPC Flow Logs, or equivalent telemetry to identify any data movement exceeding 1TB per day. These are your economic hemorrhages.
Step 2 — Enforce Day-2 observability. Your monitoring must scrape egress metrics — not just network throughput, but billable transfer. Alerts should trigger on cost deltas, not bandwidth deltas. Embed these guardrails directly into Terraform modules. This approach is documented in the Infrastructure Drift Detection Guide.
Step 3 — Model total cost of ownership using a realistic formula:
Total Egress Cost = (Volume × Rate × Frequency) × Retry Factor (≈1.2)Retries, partial failures, and backoffs are not edge cases — they are the steady-state behavior of distributed systems.
Step 4 — Negotiate. If you hold an Enterprise Agreement, egress caps are often available but never advertised. Approach the vendor with empirical usage models and a credible exit plan. We have successfully negotiated AWS egress rates to $0.05/GB post-100PB — but only with data to back the ask.
To model a large-scale recovery event specifically, use the Cloud Restore Calculator — which estimates egress fees and transfer times across AWS, Azure, and GCP for multi-TB recovery scenarios.
The Strategic Truth
High availability is not achieved by redundancy alone. It is achieved by minimizing the economic friction of failure.
When your system fails, data must move — to another region, another provider, another environment. If that movement is slow, expensive, or legally constrained, recovery becomes not just delayed but economically irrational. At that point, your architecture has failed before your servers have.
Cloud providers build data centers. You build physics-aware systems.
Architect’s Verdict
Cloud cost overruns rarely come from bad engineers — they come from bad assumptions. The most dangerous assumption in modern architecture is that data movement is cheap, reversible, or operationally trivial. It is none of those.
Data has mass. Movement has friction. Dependencies have gravity. When failure occurs — and it always does — your recovery speed is bounded not by your redundancy but by your ability to move state across domains.
Architects must design for economic survivability under failure. That means:
- Data must be portable before it is replicated
- Recovery paths must be affordable before they are automated
- Exit must be possible before entry is approved
High availability is not a topology. It is an economic property of your system under stress. If your architecture cannot afford to fail, it cannot be trusted to succeed.
Physics always wins. Design accordingly.
Additional Resources
For deeper technical context and vendor-specific pricing data:
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




