PLATFORM ENGINEERING ARCHITECTURE
DEVELOPER PLATFORMS. GOLDEN PATHS. KUBERNETES MADE USABLE AT SCALE.
Platform engineering is not a Kubernetes team with a better name. It is not a portal. It is not Backstage. It is a product discipline — one that exists because raw Kubernetes is operationally powerful and cognitively expensive, and the gap between those two realities is where developer velocity goes to die.
The premise is simple. A developer who needs to deploy a service should not need to understand PodDisruptionBudgets, HorizontalPodAutoscalers, NetworkPolicies, ResourceQuotas, and ServiceAccounts to get a workload running safely. But in most organizations running Kubernetes without a platform layer, that is exactly what they need. The result is not autonomy — it is cognitive overload dressed up as developer responsibility.
Platform engineering exists to resolve that gap. It builds and operates the internal developer platform — the abstraction layer between Kubernetes and the engineering teams consuming it. The platform team treats infrastructure as a product with internal developers as its customers. Golden paths replace runbooks. Self-service replaces ticket queues. Policy-as-code replaces manual gatekeeping. The platform enforces organizational standards by default, not by approval chain.
This pillar covers the full platform engineering architecture — the control plane model, the internal developer platform stack, golden path design, failure domains, Day 2 operational reality, cost physics, and the decision framework for when platform engineering is the right investment and when it is premature overhead. It is the layer that makes cloud native architecture usable at organizational scale.
Where This Breaks in Production
Most platform engineering initiatives fail before they deliver value — not because the technology is wrong, but because the organizational model is. The IDP gets built. The golden paths get defined. The Backstage portal goes live. And six months later the platform team is drowning in support tickets and the developers have gone back to provisioning infrastructure manually because the platform doesn’t cover their use case.
Golden paths designed for three teams don’t scale to thirty. Every exception becomes a platform ticket. The platform team becomes the bottleneck it was supposed to eliminate.
Teams route around paths that don’t fit their use case. The “paved road” becomes the road nobody uses. Adoption metrics look good. Actual usage does not.
Teams use it for discovery and ignore it for delivery. Adoption stalls. Catalog data goes stale within six months of launch.
No roadmap. No user research. No feedback loops. Engineers stop treating it as a product. Developers stop trusting it. Support tickets become the primary communication channel.
The platform enables provisioning. Finance gets the bill. Nobody can explain it. Cloud spend that no team owns compounds until it becomes a budget incident.
The pattern underneath all five is the same: platform engineering was treated as an infrastructure project rather than a product discipline. The technology was built. The organizational model was not.
The Control Plane vs Data Plane Distinction
Platform engineering operates at the control plane layer. Understanding where the control plane ends and the data plane begins is the prerequisite for designing a platform that doesn’t try to own everything — and fail at all of it.
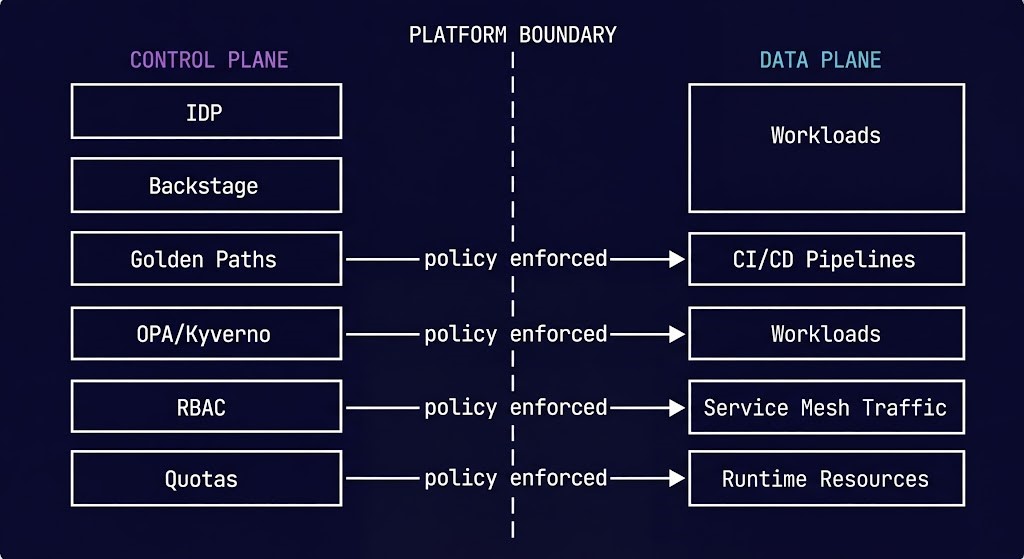
The IDP, Backstage catalog and workflows, golden path definitions, RBAC, namespace policy, resource quotas, cost attribution, and admission controllers. This is where organizational intent is encoded and enforced — without human intervention in the critical path.
Workloads running on Kubernetes, CI/CD pipelines executing, service mesh carrying traffic, application performance, runtime resource consumption, and business logic execution. The platform’s job is to make this layer safe and fast to provision — not to own it.
The failure mode that follows from blurring this boundary: platform teams that try to own workload behavior in addition to platform policy become the operational bottleneck for every production incident, every deployment, and every scaling decision. The control plane should enforce constraints on the data plane — not manage it. A platform team that is on-call for application performance has lost the plot.
The Kubernetes cluster orchestration layer sits at the intersection — the Kubernetes control plane is the substrate the platform control plane is built on. The platform abstracts Kubernetes; Kubernetes orchestrates the workloads. Neither layer owns the other.
What Platform Engineering Actually Is
Platform engineering is the discipline of building and operating internal developer platforms as products, with engineering teams as customers and developer experience as the primary success metric.
That definition carries three load-bearing concepts that separate mature platform engineering from infrastructure teams that renamed themselves.
The first is the product model. An IDP is not a collection of tools — it is a product with a roadmap, a user base, adoption metrics, and feedback loops. Platform teams that operate without product management discipline — without understanding what their users actually need versus what they assume users need — build platforms that developers route around. The platform becomes shelfware. The ticket queue grows. The value case collapses.
The second is the customer relationship. Internal developer teams are the platform’s customers. That framing changes what success looks like. A platform team that measures success by uptime and release cadence is measuring the wrong things. The correct metrics are developer-facing: time to first deployment for a new engineer, self-service completion rate, support ticket volume per team, golden path adoption rate. If developers are not using the platform, the platform is not working — regardless of its technical implementation.
The third is scope clarity. The platform team builds and operates the internal tooling layer. Product teams build and operate the workloads that run on it. The platform team is not responsible for application performance, business logic correctness, or product team architectural decisions. They are responsible for the reliability, security, and usability of the platform itself. Scope confusion is where platform teams burn out and where the organizational model collapses.
The Platform Engineering Architecture Stack
A mature internal developer platform is not a single tool. It is a stack of capabilities that work together to abstract Kubernetes complexity, enforce organizational policy, and give developers the self-service access they need to ship safely.
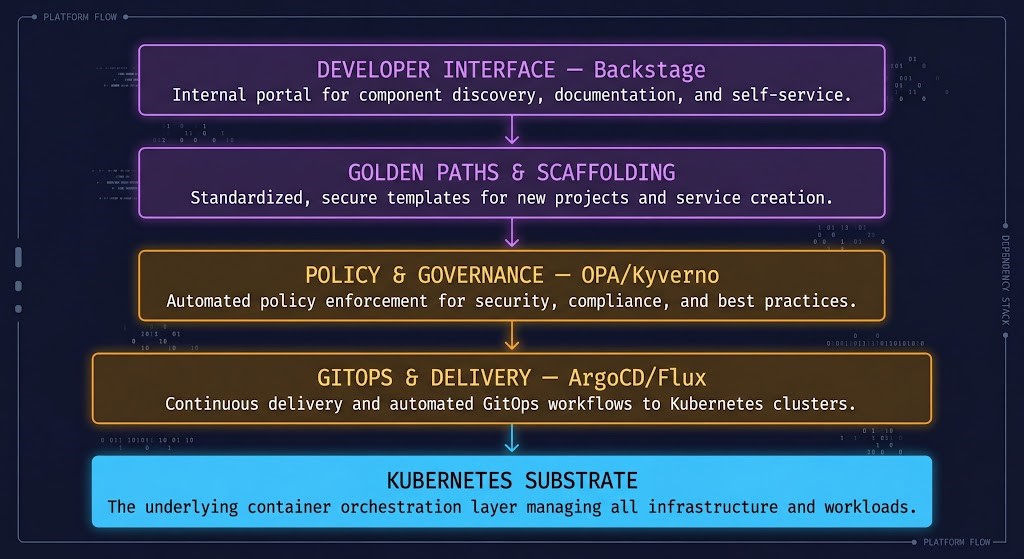
The Developer Interface is what most organizations build first and mistake for the whole platform. Backstage is a portal — a frontend for discovery, documentation, and self-service actions. It is not the platform. The platform is what Backstage connects to. An organization that deploys Backstage without the underlying golden paths, policy engine, and GitOps layer has built a catalog with no inventory and a self-service portal with no services to provision.
Golden Paths are the core value delivery mechanism. A golden path is a pre-configured, opinionated deployment blueprint that satisfies organizational security, compliance, and operational requirements by default. A developer following the golden path gets logging, monitoring, security policies, resource limits, and RBAC applied automatically — without reading documentation about how to configure each. The path enforces the standards. Deviation requires explicit justification.
Policy and Governance at the admission controller layer is what gives the platform its teeth. OPA/Gatekeeper and Kyverno enforce constraints at the Kubernetes API level — before resources are created. A workload without resource limits, a container running as root, an image from an untrusted registry — all can be rejected before they run. The container security architecture covers the full runtime security model that policy enforcement plugs into.
GitOps and Delivery closes the loop between the developer interface and the running cluster. ArgoCD or Flux watch a Git repository and continuously reconcile cluster state against it. Every change is a pull request. Every deployment is automatic. The audit trail is the Git history. The resource configuration model the platform enforces is covered in Kubernetes resource requests vs limits.
The Kubernetes Substrate is what the entire stack is built on. The platform abstracts this layer — product teams should rarely need to touch it directly. The full operational architecture of this substrate is covered in the Kubernetes cluster orchestration pillar.
Failure Domains — Where the Blast Radius Actually Lives
Platform engineering failure domains are different from application failure domains. When the platform fails, it doesn’t take down one service — it takes down the ability to deploy, observe, or recover from incidents across every team consuming it.
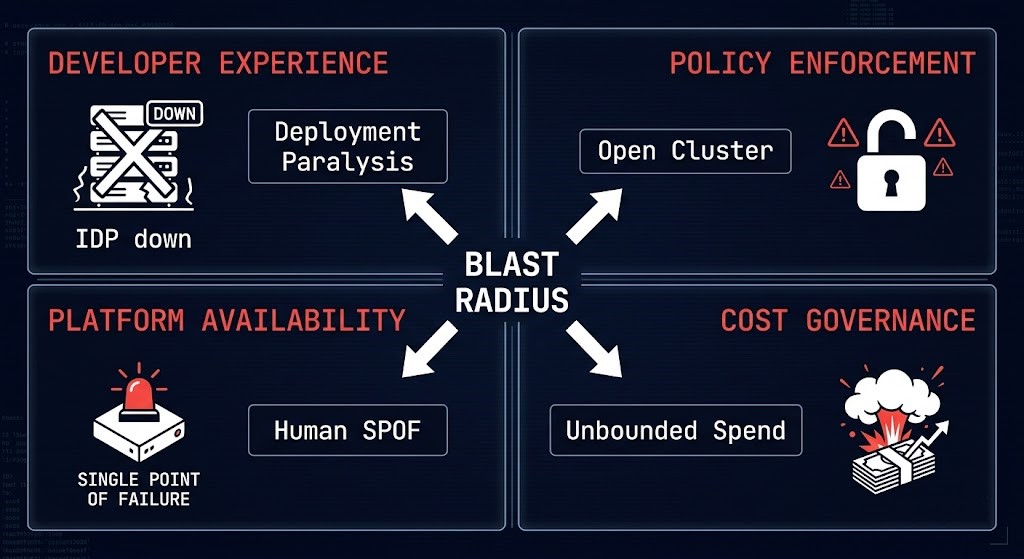
When the portal is down or golden paths are broken, developers fall back to manual processes. Manual processes bypass policy. Policy bypasses create security and compliance debt that accumulates invisibly until an audit or incident surfaces it.
A misconfigured or unavailable admission controller either blocks all deployments (fail-closed) or allows all deployments (fail-open). Fail-open is the silent failure — workloads that should be rejected get deployed. The enforcement gap is invisible until something runs that shouldn’t.
A platform team of three engineers supporting forty product teams creates a single point of failure at the human layer. Platform team burnout, key person dependency, and on-call overload are the most underestimated failure domains in platform engineering organizations.
Developer self-service that provisions cloud resources without namespace quotas, cost attribution labels, or budget alerts creates spend that no team owns. The platform enabled the provisioning. Nobody owns the cost. Finance gets a bill. Engineering gets an incident.
The failure domain that most organizations discover last is the platform team itself as a single point of failure. The Kubernetes Day-2 operations patterns apply directly to platform operations — runbook documentation, on-call rotation design, and escalation paths must be treated as platform infrastructure, not afterthoughts.
Day 2 Is Where Platform Engineering Fails
Most platform engineering content stops at deployment. The IDP is launched. The golden paths are published. The Backstage catalog is populated. The launch post goes out. And then Day 2 begins — and this is where most platforms quietly fail over the following 12-18 months.
Platform drift is the first failure. Golden paths that were accurate at launch diverge from actual cluster configuration as Kubernetes versions change, security policies evolve, and organizational standards are updated. A developer using a golden path from 18 months ago is using organizational knowledge from 18 months ago. If the platform team has no mechanism for propagating updates to existing services, the platform becomes less accurate over time rather than more.
Backstage catalog rot is the second failure. A service catalog is only valuable if its data is current. Services get renamed. Teams change. Ownership shifts. APIs evolve. Without automated catalog population from live cluster data and CI/CD pipelines, the catalog becomes a historical artifact rather than a live operational view. Teams stop trusting it. They build their own documentation. The catalog becomes a ghost town.
Policy exception accumulation is the third failure. Every organization that runs admission controllers has exceptions. A workload needs elevated privileges. A team has a legacy service that doesn’t meet the resource limit policy. An exception is granted — temporarily. The temporary exception becomes permanent. The exception list grows. The policy enforcement model is now a policy with a growing list of exemptions, which means the blast radius of a security incident grows with every exemption added.
Platform team burnout is the fourth failure and the one that terminates platform engineering programs. A small platform team supporting a large engineering organization cannot sustain a model where every developer question, every golden path gap, and every policy exception flows through the same three engineers. Without self-service that actually covers the common cases, without documentation that developers trust, and without escalation paths that don’t terminate at the same people — the platform team burns out and the program collapses.
The Kubernetes Day-2 failures document the cluster-level failure patterns. Platform Day 2 failures are the organizational layer above those — they are the patterns that emerge when the platform’s human and process infrastructure doesn’t match its technical ambition.
Myth vs Reality
Backstage is a portal — the developer-facing interface layer. The platform is everything it connects to: the golden paths, the policy engine, the GitOps layer, the Kubernetes substrate. Deploying Backstage without the underlying platform is deploying a dashboard with nothing behind it.
Golden paths reduce cognitive load — not capability. A developer following a golden path gets observability, security, and resource management configured correctly by default. They can still deviate when their use case requires it. The path is an accelerator, not a fence.
Platform engineering is a product team that owns infrastructure tooling. Kubernetes expertise is a prerequisite. Product management discipline — roadmap, user research, adoption metrics, feedback loops — is the competency that determines whether the platform succeeds.
Self-service without governance is ungated provisioning. The platform enforces policy at the point of self-service — not after. Admission controllers, resource quotas, and cost attribution are the governance layer that makes self-service safe at scale.
Cost Physics
Platform engineering has a cost structure that most organizations model incorrectly — they measure the cost of building the platform and miss the cost of not having one.

The cost of building a platform engineering function is real and visible: platform team salaries, tooling licenses, Backstage hosting, observability infrastructure, GitOps operator overhead. These costs show up in headcount and infrastructure bills. They are easy to measure and easy to challenge in a budget conversation.
The cost of not building a platform engineering function is invisible and distributed: every senior engineer who spends 40% of their time configuring infrastructure instead of shipping product. Every new hire who takes three months to become productive because there is no standardized onboarding path. Every incident caused by a manual kubectl apply that bypassed the review process. Every compliance audit finding caused by a workload that was deployed without the required security controls. These costs don’t appear on a single line item. They appear everywhere.
Costs that don’t appear in the platform engineering budget line — but are paid by the organization regardless.
70%+ of engineering time outside business logic is not a productivity metric — it is a revenue cost. Every hour a senior engineer spends configuring infrastructure is an hour not spent on the product that generates revenue.
Inconsistent deployment patterns across teams create an incident response tax — every outage requires understanding the specific configuration choices of the team that owns the failing service before diagnosis can begin. Standardization reduces this tax per incident.
Without self-service provisioning, developer work blocks on infrastructure tickets. A feature that takes two days to build takes two weeks to deploy because provisioning a database or a new namespace requires a ticket, a review, and a manual operation. The platform eliminates that queue.
Without platform-enforced isolation — namespace boundaries, network policies, resource quotas — a single team’s misconfiguration can affect the entire cluster. Platform isolation boundaries contain blast radius at the namespace level before it becomes a cluster-wide incident.
The cost model for platform engineering only becomes favorable at the scale where automation replaces manual operations at a rate that exceeds the investment in the platform. For most organizations, that threshold is somewhere between 50 and 100 engineers. Below that threshold, the platform overhead exceeds the value. Above it, the absence of a platform creates a hidden tax that compounds with every new team and every new service.
How Platform Engineering Fits the Architecture System
AWS, GCP, Azure provide the compute substrate — managed Kubernetes, storage, networking, and managed services. The platform abstracts the cloud provider API through IaC templates and self-service provisioning. Teams get cloud resources without touching cloud provider consoles.
Kubernetes, containers, service mesh, and GitOps are the execution model. Platform engineering is the organizational layer that makes this model usable at scale — abstracting its complexity without hiding its power from teams that need it.
Infrastructure
Terraform, Ansible, and IaC tooling provide the provisioning layer the platform orchestrates. The Terraform & IaC pillar covers the IaC patterns that underpin platform-managed infrastructure provisioning.
Platform-enforced backup policies, disaster recovery runbooks-as-code, and namespace-level isolation boundaries are the platform engineering contribution to the data protection architecture. The platform embeds resilience at the delivery layer rather than retrofitting it after the fact.
Platform engineering is the product layer that makes cloud, cloud native, modern infrastructure, and data protection consumable by product teams — without requiring each team to be experts in all of it.
Workload and Org-Size Decision Tree
| Scenario | Platform Engineering Fit | Why | What Breaks First Without It |
|---|---|---|---|
| <50 engineers, single product | Too early | Platform overhead exceeds value. Shared context still works. | Nothing — informal coordination still scales |
| 50–100 engineers, multiple teams | Build selectively | Golden paths + RBAC + namespace isolation. No full IDP yet. | Onboarding consistency, deployment pattern fragmentation |
| 100–200 engineers, multi-team shared cluster | Essential | Self-service without platform = ticket queue growth | Senior engineer time, deployment velocity |
| 200+ engineers, multiple clusters | Full IDP justified | Scale requires abstraction at every layer | Policy enforcement consistency, cost attribution |
| Multi-team on shared Kubernetes | Essential | Isolation requires platform-enforced namespace boundaries | Namespace sprawl, blast radius containment |
| Regulated environment (HIPAA, SOC2, PCI) | Essential | Compliance requires enforced golden paths, not optional standards | Audit trail gaps, policy exception accumulation |
| Single team, greenfield | Premature | Build the product first. Platform patterns emerge from real operational pain | Nothing — complexity doesn’t justify the investment yet |
When Platform Engineering Is the Right Investment
When multiple product teams share a Kubernetes cluster, the absence of platform-enforced isolation is where operational chaos begins. Namespace boundaries, RBAC, network policies, and resource quotas cannot be consistently applied across dozens of teams without a platform layer to enforce them. The first major incident — a noisy neighbor consuming cluster resources, a misconfigured network policy allowing cross-namespace traffic — is the moment the platform conversation becomes urgent. The correct time for that conversation is before the incident.
Organizations subject to HIPAA, SOC2, PCI-DSS, or similar compliance frameworks have a governance requirement that aligns directly with platform engineering’s core value proposition. Policy-as-code admission controllers, immutable audit trails from GitOps delivery, and enforced golden paths that embed compliance controls at service creation time are not nice-to-haves in regulated environments — they are audit requirements.
When the time for a new engineer to make their first production deployment is measured in weeks rather than hours, the absence of a platform is a revenue constraint. Every week a senior engineer spends onboarding a new hire on deployment processes and Kubernetes configuration is a week not spent on the product. Golden paths reduce the onboarding surface to the product domain — not the infrastructure domain.
When to Consider Alternatives
Platform engineering investment returns value at scale. For teams under 50 engineers with shared context and manageable complexity, informal coordination still works. The platform overhead — building and maintaining the IDP, operating the GitOps layer, managing Backstage — costs more in engineering time than it returns in productivity at this scale. Build the product first. Platform patterns emerge from real operational pain.
Platform engineering sits on top of a Kubernetes operational foundation. An organization that has not yet established reliable cluster operations, consistent deployment practices, and basic observability is not ready for platform engineering — it is ready for Kubernetes operations. The Kubernetes cluster orchestration and Day-2 operations foundations must exist before the platform layer is built on top.
A platform team of one supporting a product team of one is not platform engineering — it is DevOps. The value of platform engineering is the leverage it provides across multiple teams. For single-team environments, a well-designed CI/CD pipeline and documented runbooks deliver the same outcomes with significantly less infrastructure overhead.
Decision Framework
| Scenario | Recommendation | Why | What Breaks First |
|---|---|---|---|
| Multi-team, shared Kubernetes cluster | Build platform layer | Isolation, RBAC, and policy consistency require enforcement at the platform level | Namespace sprawl, noisy neighbor incidents, policy drift |
| Regulated environment requiring compliance audit trail | Essential | Policy-as-code + GitOps audit trail is the compliance architecture | Audit trail gaps, manual review bottlenecks |
| 100+ engineers, multiple products | Full IDP investment | Scale requires abstraction. Ticket queues replace self-service without it | Senior engineer utilization, onboarding time, deployment consistency |
| Fast onboarding requirement | Golden paths first | Reduce onboarding surface to product domain, not infra domain | New hire ramp time, inconsistent first-deployment experiences |
| Cost attribution across teams | Platform-enforced quotas | Self-service without cost governance creates unbounded spend | Cloud cost ownership gaps, budget overruns with no clear owner |
| <50 engineers, single product | Defer | Overhead exceeds value at this scale | Nothing yet — don’t build abstractions before the pain |
| No Kubernetes operational baseline | Build K8s ops first | Platform engineering requires a stable Kubernetes foundation | Cluster reliability incidents that cascade to the platform layer |
| Single team, greenfield | Skip IDP, use CI/CD | Platform leverage requires multiple teams consuming the platform | Nothing — wrong tool for the scale |
Platform engineering sits at the intersection of every other pillar. The pages below cover the layers the platform abstracts, enforces, and connects.
Architect’s Verdict
Platform engineering is overkill for most organizations — and the only viable operational model for the ones that have grown past the point where informal coordination scales.
The honest version of the platform engineering argument is not that it eliminates complexity. It relocates complexity — from distributed across every product team to centralized in a platform team with the expertise and tooling to manage it efficiently. The complexity doesn’t disappear. It gets owned by the people best positioned to handle it, and abstracted away from the people who shouldn’t need to care about it.
The teams that succeed with platform engineering treat it as a product discipline, not an infrastructure project. They instrument adoption, not just uptime. They measure developer experience, not just policy compliance. They build feedback loops with their internal customers and evolve the platform based on real usage data. The teams that fail deploy Backstage, publish some golden paths, and declare victory before Day 2 begins. The difference between those two outcomes is not technical. It is organizational. Build the platform for the scale you have, not the scale you aspire to — and measure the cost of not having it before measuring the cost of building it.
You’ve Got the Framework.
Now Validate the Platform Beneath It.
IDP architecture, golden path coverage, policy enforcement posture, and Day-2 operational maturity — platform engineering programs that look correct at launch become bottlenecks and compliance gaps in production. The triage session audits the gap between the design intent and the running environment.
Platform Engineering Audit
Vendor-agnostic review of your internal developer platform — IDP architecture, golden path coverage and adoption, policy enforcement posture, GitOps maturity, and Day-2 operational readiness. Covers the full platform stack from developer interface down to Kubernetes substrate.
- > IDP architecture and golden path coverage
- > Policy enforcement and admission controller posture
- > GitOps maturity and delivery pipeline review
- > Day-2 operational maturity assessment
Architecture Playbooks. Every Week.
Field-tested blueprints from real platform engineering environments — IDP architecture decisions, golden path design patterns, Backstage implementation case studies, and the Day-2 operational patterns that separate production-grade platform engineering from fragile prototype infrastructure.
- > IDP Architecture & Golden Path Design
- > Policy Enforcement & Compliance Patterns
- > GitOps & Day-2 Operational Maturity
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Frequently Asked Questions
Q: What is platform engineering and how is it different from DevOps?
A: DevOps is a cultural and organizational model that breaks down silos between development and operations teams — “you build it, you run it.” Platform engineering takes that model a step further by building internal products that give development teams self-service infrastructure capabilities while maintaining the governance and operational standards the organization requires. Where DevOps requires every developer to develop operational expertise, platform engineering centralizes that expertise in a platform team and exposes it through golden paths and self-service tooling that abstracts the complexity. The distinction matters operationally: DevOps scales with headcount, platform engineering scales with automation.
Q: What is an internal developer platform and what should it include?
A: An internal developer platform is the product layer between Kubernetes and the engineering teams consuming it. At minimum it should include a developer interface (Backstage or equivalent), golden paths that embed security and operational standards at service creation time, a policy enforcement layer (OPA/Gatekeeper or Kyverno) that enforces those standards at the Kubernetes API, and a GitOps delivery layer (ArgoCD or Flux) that makes deployments declarative and auditable. Cost attribution and quota management round out the governance layer. The IDP is not Backstage — Backstage is the portal. The platform is everything it connects to.
Q: What is a golden path and why does it matter?
A: A golden path is a pre-configured, opinionated deployment blueprint that satisfies organizational security, compliance, and operational requirements by default. When a developer follows the golden path to create a new service, they automatically get logging, monitoring, security policies, resource limits, RBAC, and namespace isolation applied — without reading documentation about how to configure each. The path encodes organizational knowledge into repeatable process rather than tribal knowledge and runbooks. The name comes from the idea of a paved road: you can still go off-road, but the path makes the right way the easy way.
Q: When is platform engineering worth the investment?
A: The cost model becomes favorable at the scale where automation replaces manual operations at a rate that exceeds the investment in the platform — typically between 50 and 100 engineers for most organizations. Below that threshold, the platform overhead exceeds the value and informal coordination still works. The clearer triggers are organizational rather than headcount: multiple product teams sharing a Kubernetes cluster, compliance requirements that mandate enforced security standards, or onboarding friction that is measurably slowing delivery. If developers are spending significant time on infrastructure configuration instead of product work, that is the signal.
Q: What is Backstage and is it the right choice for every organization?
A: Backstage is an open-source developer portal framework built by Spotify that provides a service catalog, software templates, and a plugin architecture for integrating with CI/CD pipelines, Kubernetes, cloud providers, and monitoring systems. It is the most widely adopted foundation for internal developer platforms, but it is not the right choice for every organization. Backstage requires significant investment to configure, customize, and maintain — it is a framework, not a product. Organizations under 100 engineers are often better served by simpler tooling. The more important question is not which portal to use, but what the portal connects to — golden paths, policy enforcement, and GitOps delivery are the value layer, not the interface on top of them.
Q: What are the most common platform engineering failures in production?
A: The five patterns that repeat most consistently: building the IDP for current team scale without designing for growth (the platform becomes the bottleneck as teams multiply), defining golden paths without developer input (paths that don’t match developer workflows get routed around), deploying Backstage as a catalog without workflow integration (adoption stalls, data goes stale), treating the platform team as infrastructure rather than a product team (no roadmap, no feedback loops, no user research), and enabling self-service without cost governance (unbounded spend that no team owns). The pattern underneath all five is the same: the technology was built, the organizational model was not.