Why Serverless Isn’t Dead for GenAI — It’s Just Misunderstood
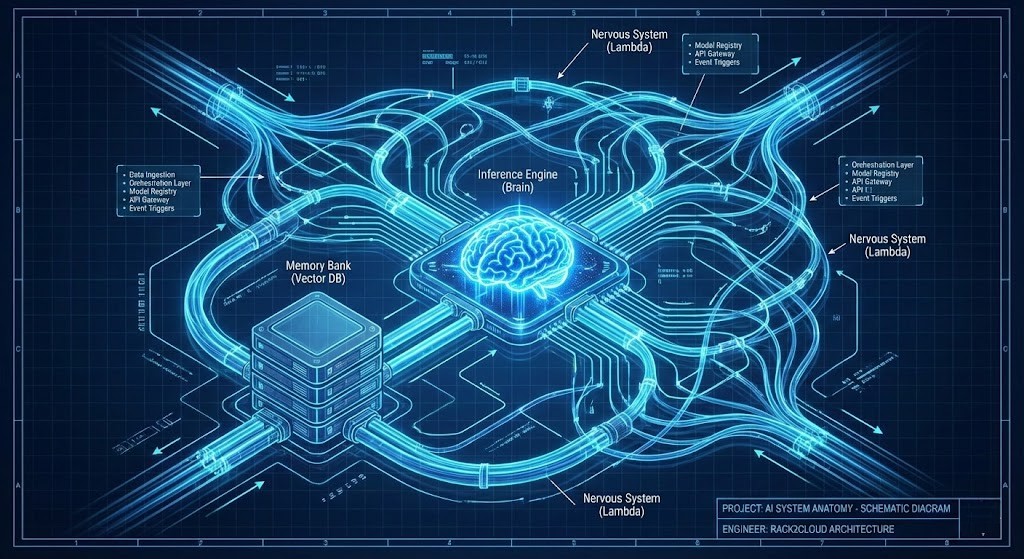
Serverless GenAI architecture doesn’t fail because Lambda is too slow — it fails because teams assign Lambda the wrong job. Debunking that myth requires redefining one boundary. Not technology — anatomy. The difference between the Brain and the Nerves.
I recently ignited a firestorm on Reddit with a post titled “Serverless is Dead for GenAI” (you might have seen the viral discussion here).
The reaction was immediate and polarized. Half the comments dismissed Lambda as a toy; the other half claimed I was using it incorrectly. But as the dust settled on that thread, I realized something important. We weren’t arguing about technology; we were arguing about context.
I wrote that post because I was watching teams—including my own—burn $12,000 a month on idle GPU clusters. We were building “AI Agents” that spent 90% of their time waiting for API responses, yet we provisioned heavy iron as if they were training a model 24/7.
We swung the pendulum from “Serverless First” to “Heavy Iron Only” based on the fear that Lambda couldn’t handle the load. That fear stems from a fundamental misunderstanding of Compute Physics and where the processing actually happens in a modern AI stack.
The Anatomy of Modern AI: Brain vs. Nerves
To build cost-effective AI at scale, we must decouple the components. We need to treat the architecture like biological anatomy.
1. The Brain (Inference)
- Role: Heavy lifting, stateful, expensive.
- Tech: SageMaker, Bedrock, persistent ECS clusters.
- Reference: See our AI Architecture Path for handling LLM Ops.
- Why SageMaker/Bedrock/ECS: Inference is computationally dense and stateful — it needs persistent memory, CUDA cores, and low-latency access to model weights. Spinning this up per-request in a stateless function would add 10-30 seconds of cold start overhead per inference call. The Brain needs to stay warm, stay loaded, and stay resident.
2. The Memory (Context)
- Role: Where state lives.
- Tech: Vector Databases (Pinecone, OpenSearch), Redis.
- Why Vector Databases/Redis: Context isn’t compute — it’s retrieval. The Memory layer needs to answer one question fast: “what does this agent already know?” Vector databases and in-memory caches are purpose-built for sub-millisecond semantic retrieval at scale — the Vector Databases & RAG architecture guide covers the embedding pipeline and ANN search patterns that make this work in production. Putting context management in a GPU cluster is like storing your filing cabinet inside the server rack. Wrong layer, wrong cost profile.
3. The Nervous System (Orchestration)
- Role: Senses, routes, decides, triggers.
- Tech: AWS Lambda.
- Why Lambda: Orchestration is reactive by nature — it waits for events. Paying for persistent compute that sits idle 90% of the time waiting for a trigger is the exact waste that serverless was designed to eliminate.
The mistake isn’t using Lambda; the mistake is trying to make the Nervous System do the thinking.
Deep Dive: If you want to explore the specific Step Function patterns that make this “Nervous System” possible, we break down the code in our companion piece: AWS Lambda GenAI Architecture Guide.

Decision Matrix: The Architect’s Boundary
This is the boundary I enforce in production. No guesswork.
| Workload Characteristic | Recommended Compute | The Strategic “Why” |
| Agent Orchestration | AWS Lambda | Agents are reactive. Paying for idle containers while an agent waits for a user trigger is OpEx waste. |
| Pre/Post Processing | AWS Lambda | Sanitation (PII masking) and formatting (JSON repair) are CPU tasks. Don’t waste GPU cycles on Regex. |
| Long Context Caching | ECS / EKS | If you need to keep 10GB of context hot in RAM for immediate access, stateless Lambda will fail. |
| Heavy Inference | SageMaker / EC2 | You need raw metal and CUDA cores. Lambda layers cannot support multi-gigabyte dependencies efficiently. |
| WebSockets / Streaming | ECS / Fargate | While Lambda can do WebSockets, maintaining connection state for long streams is often cheaper in a lightweight container. |
Serverless GenAI Architecture: The Financial Reality
Here is where the argument usually ends for my clients: Cost.
If you run a containerized agent fleet, you are paying for capacity availability. If you run a serverless orchestration layer, you are paying for capacity utilization.
In my own “bad old days” of that $12,000/mo GPU cluster, we eventually refactored the orchestration logic out of the cluster and into Step Functions + Lambda. The GPU cluster was downscaled to only handle raw inference calls (Bedrock).
- Previous Bill: $12,000/mo (mostly idle GPU time).
- New Bill: $4,500/mo (Bedrock tokens + minimal Lambda costs).
The savings didn’t come from cheaper models — they came from eliminating idle capacity. This aligns directly with the “Cloud Economics & Cost Physics” module in our Cloud Architecture Learning Path.
A Note on Scaling Costs
However, there is a ceiling. If your transaction volume is massive—millions of inference calls a day—public cloud inference can become prohibitively expensive. At that point, buying your own hardware (CapEx) beats the cloud OpEx.
If you are staring at a cloud bill that seems to be spiraling, it might be time to check if you’ve crossed that threshold. We use our Cloud Repatriation ROI Estimator to calculate exactly when the “Cloud Tax” exceeds the cost of owning the hardware.
The Hidden Cost: The “Refactoring Cliff”
This is where many serverless discussions break down: not cost, but complexity.
The pro-container crowd in my Reddit thread did have one valid point. Writing a monolithic Python script that runs in a container is easy. Breaking that script into 15 discrete, event-driven Lambda functions coordinated by a state machine is hard. It requires a different level of engineering maturity.
You have to ask yourself: Is the OpEx saving of Serverless worth the engineering hours required to refactor the application?
The architectural signal is straightforward: if your agent spends more than 60% of its execution time waiting — on API responses, database reads, downstream service calls — you are paying container pricing for serverless behavior. That gap is the refactoring opportunity. Before you commit to a full refactor, I recommend modeling the break-even point. We built the Refactoring Cliff Calculator for this exact scenario—to help you decide if the effort of refactoring pays off against the technical debt and operational cost of maintaining the monolith.
Architect’s Verdict: Don’t Be a Purist
The serverless GenAI architecture debate is the wrong argument. Nobody is suggesting you run Llama-3-70B in a Lambda function. The question is whether your orchestration layer — the routing logic, the pre-processing, the event triggers, the state coordination — deserves $12,000 a month in persistent GPU capacity. It doesn’t.
The Brain needs iron. The Memory needs speed. The Nervous System needs to be reactive, cheap, and invisible until it’s needed. Conflating those three things is how teams end up paying container pricing for workloads that spend 90% of their time waiting for an API response.
Deliberately compose your stack. GPUs for thinking. Vector stores for memory. Lambda for the nerves. The cost difference isn’t marginal — it’s the difference between a $12,000 bill and a $4,500 one, on identical workloads, with identical output quality.
Additional Resources:
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




