AI Infrastructure Repatriation: Why On-Prem Is Now the Strategic Call for Enterprise AI

AI infrastructure repatriation is not a retreat from the cloud era. It is the architectural correction that follows when the economics of production AI diverge sharply from the economics of a proof of concept. For a decade, “Cloud First” was the correct default. For enterprise AI at production scale in 2026, it increasingly is not — and the organizations discovering this the hard way are doing so at $180,000-per-month moments that could have been modeled in advance.
As we settle into 2026, enterprises are facing an “AI Infrastructure Reckoning.” CIOs and Architects are realizing that the architecture designed for a successful 3-month Proof of Concept (POC) becomes economically and operationally lethal at production scale—because inference is always-on, data is immovable, and GPUs are never idle. Bringing workloads back on-premises—specifically for AI—is no longer an act of nostalgia for the data center era. It is a calculated, strategic move forced by the need to regain control over margins, latency, and data sovereignty.
The “POC Trap” and the Scaling Cliff
The current stalling of AI ROI across the enterprise isn’t usually a failure of the models; it’s a failure of the economics.
We need to be honest about how these projects start. It is incredibly easy to swipe a corporate credit card, spin up a powerful H100 instance in AWS or Azure, and test a new model. It’s fast, it’s impressive, and for a few weeks, the bill is negligible. This is the Proof of Concept (POC) Trap.
The trap snaps shut when you move from “innovation” to “production.”
Architects often assume AI workloads behave like traditional web applications—bursty, stateless, and elastic. They don’t. AI workloads—specifically training and high-volume RAG (Retrieval-Augmented Generation) inference—are insatiable compute-hogs that run hot 24/7.
The Economic Reality Check
You can rent a Ferrari for a weekend road trip. It’s fun, and for 48 hours, it makes financial sense. But you do not rent a Ferrari to commute to work every single day. If your workload is baseload, your infrastructure must be owned — not rented.
Yet, that is exactly what I see enterprises doing. They use premium, elastic rental infrastructure for baseload, always-on demand. As the FinOps Foundation recently noted, unit cost visibility — not performance — is now the primary barrier to cloud sustainability.
The AI Infrastructure Repatriation Tipping Point
This is the moment when architects stop optimizing for velocity and start optimizing for survivability.
- Month 1 (Dev): $2,000. (One engineer experimenting). Status: Hero.
- Month 3 (Pilot): $15,000. (Small internal user group). Status: Optimistic.
- Month 6 (Production): $180,000/month. (Public rollout, constant inference). Status: CFO Emergency Meeting.
Architectural Decision Point: Before you commit to a hyperscaler for a production rollout, you need to calculate the “break-even point”—the month where owning the hardware becomes cheaper than renting.
Data Gravity is Undefeated
Beyond the financials, there is the stubborn reality of physics.
For the last ten years of the “Cloud Era,” the paradigm was simple: Code was heavy. Data was light. We moved the data to the cloud because that’s where the compute lived, and the datasets were manageable.
AI reverses this paradigm. Data Gravity has won.
Deep Learning models and Vector Databases require massive, localized context to function. We are talking about Petabytes of training data.
The Latency Tax: I recently reviewed an architecture for a manufacturing client. They had 5 Petabytes of proprietary machine logs, high-res images, and historical sensor data sitting in a secure on-prem object store. Their initial plan? Pipe that data over a WAN link to OpenAI’s public API for every single inference request to detect defects.
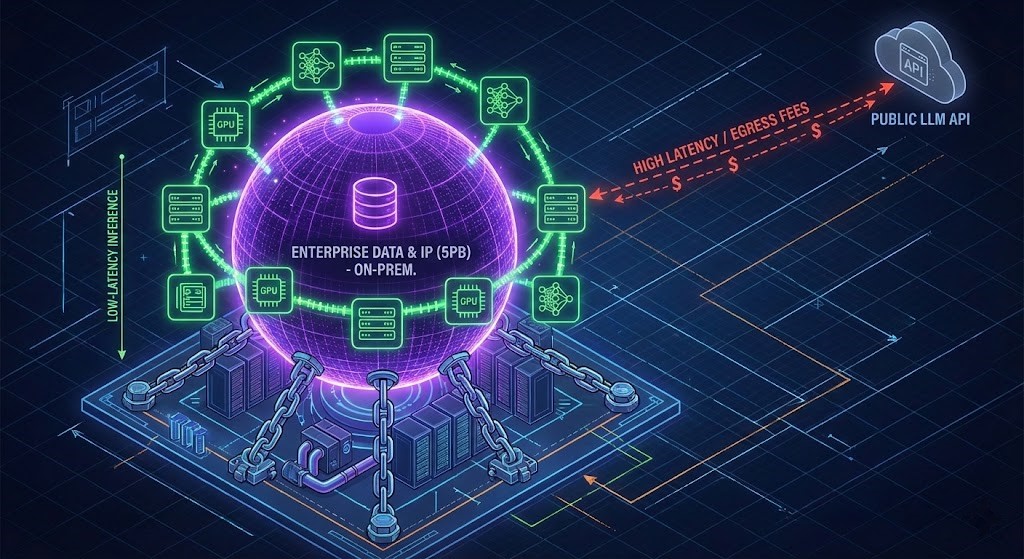
This is technical insanity.
- Latency: The round-trip time (RTT) alone killed the “real-time” requirement.
- Egress Fees: Moving that volume of data out of their data center would have cost more than the engineering team’s combined salaries.
- Security: Expanding the attack surface by exposing proprietary IP to the public internet.
The Rule of Proximity: If you want AI to be responsive, secure, and cost-effective, the compute must come to the data, not the other way around.
If your “Crown Jewel” data lives on a mainframe or a secure on-prem SAN, your AI inference engine needs to live in the rack next to it. We explored the specific architecture for this in our AI Infrastructure Strategy Guide, detailing the “Data-First” topology.
Decision Framework: Where Does This Workload Belong?
| Variable | Public Cloud AI | On-Prem / Edge AI |
| Data Volume | Low / Cached (TB scale) | Massive / Dynamic (PB scale) |
| Data Sensitivity | Public / Low Risk | PII / HIPAA / Trade Secrets |
| Connection State | Tolerant of Jitter/Disconnects | Requires <5ms Deterministic Latency |
| Throughput | Bursty (Scale to Zero) | Constant (Baseload) |
The New “Strategic” On-Prem Stack
The biggest misconception hindering the repatriation discussion is the idea that “going back on-prem” means returning to the brittle, monolithic architectures of 2010.
Repatriation without modernization is not strategy — it’s regression.
I’ve sat in meetings where the mere mention of on-premises infrastructure conjures up nightmares of waiting six weeks for a LUN to be provisioned on a SAN. If that is your definition of on-prem, stay in the cloud. You aren’t ready.
But strategic repatriation is not about nostalgia. It is about modernization. The new on-prem AI stack is fundamentally different. It is “Cloud Native, Locally Hosted.”
1. Kubernetes is the New Hypervisor
In the legacy stack, the atomic unit of compute was the Virtual Machine (VM). In the AI stack, the atomic unit is the Container. While you might still run VMs for isolation, the orchestration layer must be Kubernetes. This allows your data science teams to deploy training jobs using the same Helm charts and pipelines they used in the cloud.
2. The Death of the SAN / The Rise of High-Performance Object
Traditional block storage (SAN) struggles with the massive, unstructured datasets required for AI training. The new stack relies on high-performance, S3-compatible object storage (like MinIO or Nutanix Objects) running over 100GbE or InfiniBand.
The War Story: I recently audited a firm trying to run RAG off a legacy NAS. The latency killed the project. By switching to a local NVMe-based Object store, they reduced query times from 4 seconds to 300ms — the difference between “interesting” and “usable.”
3. Sliced Compute (NVIDIA MIG)
In the cloud, you pay a premium for flexibility. On-prem, you used to pay for idle capacity. That changed with technologies like NVIDIA’s Multi-Instance GPU (MIG). We can now slice a massive H100 GPU into seven smaller, isolated instances. This mimics the “T-shirt sizing” of cloud instances.
The Architect’s Note: MIG solves utilization — not thermal density or power draw. That math still matters.
Licensing Warning: If you are retrofitting existing virtualized environments (VCF/VVF), Broadcom’s new subscription model punishes inefficiency. Before you order hardware, verify your licensing density.
Table: Modernizing the Stack – This table summarizes why “on-prem” in 2026 does not resemble “on-prem” in 2016.
| Feature | Legacy On-Prem (The “Nostalgia” Stack) | AI-Ready On-Prem (The “Strategic” Stack) |
| Compute Unit | Static Virtual Machines (VMs) | Containers & GPU Slices (MIG) |
| Storage Access | Block/File (SAN/NAS) via Fiber Channel | S3-Compatible Object Store via 100GbE |
| Provisioning | Manual Tickets (Days/Weeks) | API-Driven / IaC (Seconds) |
| Scale Model | Scale-Up (Bigger Servers) | Scale-Out (HCI / Linear Nodes) |
| Primary Cost | Maintenance & Power | GPU Density & Cooling Efficiency |
Architect’s Verdict
AI infrastructure repatriation is not a philosophical position on cloud vs on-premises. It is a math problem — and in 2026, the math is breaking against the cloud for a specific class of workload: always-on, data-heavy, latency-sensitive inference at scale.
The three conditions that make repatriation the correct architectural call are compounding simultaneously for more enterprise AI deployments than the hyperscalers want to acknowledge. Data gravity anchors the training corpus on-premises. Inference economics make baseload GPU rental structurally more expensive than ownership past a calculable threshold. And data sovereignty requirements are increasingly removing the cloud as a legal option for the most valuable workloads. That sovereignty condition is no longer AI-specific — it’s the same control wave now driving repatriation decisions broadly, as The New Cloud Repatriation Strategy Isn’t About Cost lays out.
The strategic on-prem stack covered above is not the data center of 2016. It is Kubernetes-orchestrated, object-storage-native, GPU-sliced infrastructure that runs the same workloads as the cloud — without the egress tax, the idle GPU cost, or the jurisdictional exposure. The repatriation decision is not whether to return to legacy infrastructure. It is whether to build modern infrastructure on hardware you own. At production AI scale, that question answers itself.
Additional Resources
This post is the economic and architectural case. These are the deeper dives.
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session




