Your Cloud Provider Is a Single Point of Failure — Enterprise Resilience Beyond Provider SLAs
Cloud SLA limitations become real the moment IAM starts returning 503s. It’s always a small event at first — a blip in CloudWatch, a dashboard alert muted over lunch. Then every automation pipeline you thought would “save you” suddenly becomes inert code waiting on a dead API. I watched great engineers helplessly SSH into nothing because access tokens couldn’t refresh.
That day, the real problem wasn’t availability. It was dependency. Resilience must include control surfaces, not just compute nodes. This is a core tenet of our Cloud Strategy Pillar: Never let a vendor’s “Global Service” become your Global Failure.
We weren’t victims of poor architecture. We were victims of faith — faith that a hyperscaler’s architecture automatically equaled ours. Never again.
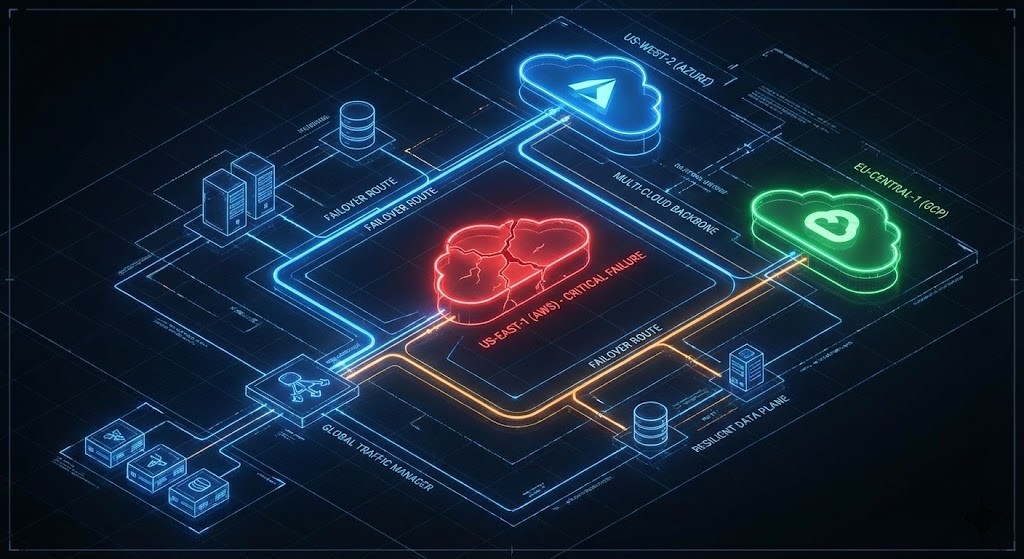
The Day the “Region” Died
It’s always a small event at first—a blip in CloudWatch, a dashboard alert muted over lunch. Then the IAM service 503s start, and every automation pipeline you thought would “save you” suddenly becomes inert code waiting on a dead API. I watched great engineers helplessly SSH into nothing because access tokens couldn’t refresh.
That day, the real problem wasn’t availability. It was dependency. Resilience must include control surfaces, not just compute nodes.
We weren’t victims of poor architecture. We were victims of faith—faith that a hyperscaler’s architecture automatically equaled ours. Never again.
Cloud SLA Limitations: The Lie of the SLA
Let’s break it down like architects, not accountants. A 99.99% SLA equals roughly 4.38 minutes of acceptable downtime per month.
If the provider misses it and gives you a 30% service credit on a $15,000 bill, you get $4,500. Meanwhile, your operational loss might exceed $2M in airline rebookings or delayed hospital transactions.
That’s not risk mitigation—it’s a discounted apology.
Cloud SLA limitations are structural, not incidental. SLAs are actuarial, not architectural. They exist to protect cloud providers’ margins, not your uptime. They are financial shock absorbers, not engineering guarantees. For the architectural response to this problem, the Multi-Region Cloud Architecture deep dive covers the engineering side of what SLAs leave unaddressed.
The Physics of Cloud Failure
Global outages are not about broken racks or lost transformers — they’re about shared dependencies:
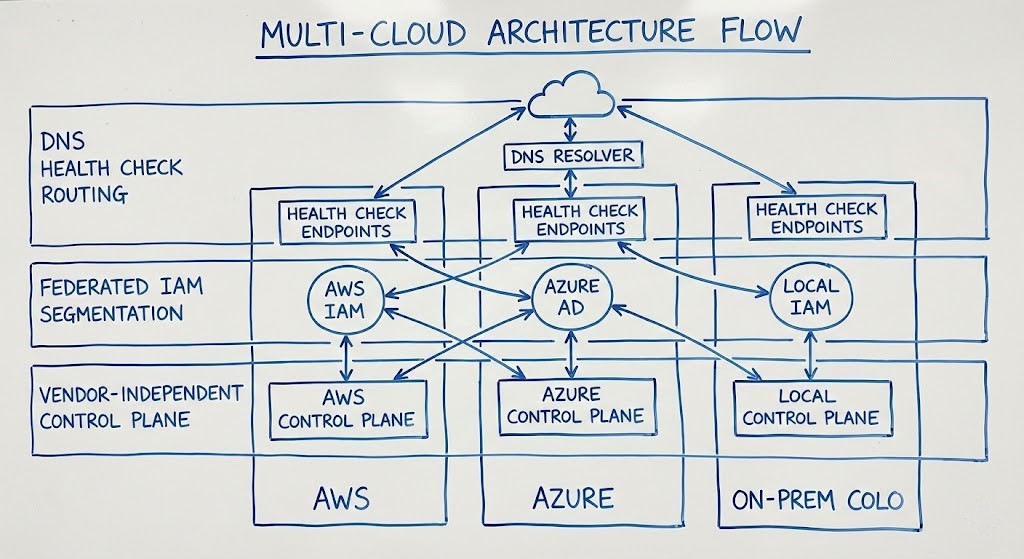
- Global Control Planes: One bad push to IAM or EC2 metadata, and all regions depend on the same poisoned configuration.
- Routing & DNS: A flawed BGP broadcast is a global kill switch, no matter how “regionally isolated” your workloads claim to be.
- Identity Dependencies: If cross-region services depend on a single token API, you’re one IAM failure away from a multi-region blackout.
These aren’t theoretical. AWS (Dec 2023), Azure (May 2024), and GCP (July 2025) all had cascading control plane incidents where the public status page read: “Increased error rates globally.” Translation: “We broke the part of the cloud you can’t design around.”
The Architecture Audit: Are You Actually Redundant?
Here’s how I audit environments now. If you see one of these anti-patterns, your Data Protection Strategy is performative:
- The Multi-Region Mirage: Deployment pipelines still originate from a single region. Your DR script dies when that region does.
- The SaaS Trap: Your “multi-cloud” setup collapses when both app and SaaS data coexist in the same hyperscaler.
- The Dormant DR Region: Cold standby sounds good until you realize you’ve hit quota limits or stale IAM policies.
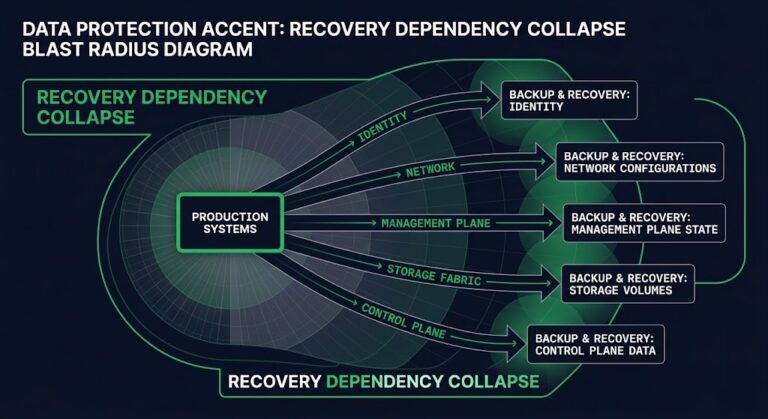
Real-world mitigation means extending your thinking beyond the provider’s plane — into multi-provider, control-plane-isolated, data-aware architectures. The identity angle specifically is explored in Your Identity System Is Your Biggest Single Point of Failure.
The Cost–Complexity Matrix
| Model | Complexity | Cost | Resilience | Use Case |
| Multi-AZ (Single Region) | Low | $ | ⭐⭐ | Standard web workloads, minimal risk appetite. |
| Multi-Region (Active-Passive) | Medium | $$ | ⭐⭐⭐ | Mission-critical workloads needing geo-redundancy. |
| Multi-Cloud (Active-Active) | High | $$$$ | ⭐⭐⭐⭐⭐ | Regulated or high criticality workloads (finance, healthcare). |
| Hybrid (Colo + Cloud) | High | $$$ | ⭐⭐⭐⭐ | Performance isolation or data sovereignty compliance. |
There’s no free lunch here. You pay either in complexity or downtime. My rule:
“If your TCO model doesn’t include outage cost, it’s not a TCO model. It’s a budget excuse.”
The Multi-Cloud Tax vs. The Outage Cost
CFOs detest redundancy that doesn’t show direct ROI. Let’s reframe it in language they respect.
- Single Cloud: Low cost, high operational dependency (OpEx efficient, risk blind).
- Multi-Cloud Active-Passive: Medium OpEx, moderate complexity.
- Multi-Cloud Active-Active: Highest OpEx, but near-zero downtime probability.
Multi-cloud isn’t a trend — it’s actuarial risk management. The “multi-cloud tax” is your resilience premium. If an airline, hospital, or financial exchange can lose millions per hour, that premium is a bargain. For how multi-cloud specifically creates its own failure modes, see Multi-Cloud Doesn’t Prevent Outages — It Makes Them Cascade.
Day 2 Thinking: Beyond Infrastructure
Resilience isn’t technology—it’s discipline. Systems rot, IAM permissions expire, DNS TTLs linger longer than memory recall. You need habits, not hopes.
My checklist for every enterprise:
- SaaS Lineage Audit: Vendor transparency first. If your identity provider and your infrastructure share the same backend, you’ve doubled your exposure.
- Kill Switch Drills: Simulate region isolation quarterly. Don’t ask if your app survives—measure how long your engineers take to notice.
- Neutral Data Replication: Replicate at least one immutable data copy outside your cloud provider’s backbone via a colocation edge or vendor-neutral storage.
- Terraform Independence: Code that only runs with one provider’s API is vendor property, not enterprise IP.
The Mindset Shift: Design for 100% Failure
I design as if every provider control plane is already compromised. That’s not paranoia. It’s architectural hygiene.
I design as if every provider control plane is already compromised. That’s not paranoia. It’s architectural hygiene. We previously wrote about fixing the transport layer. This article fixes the endpoint. Together, they form a guiding principle:
“Don’t just route around the outage. Route around the vendor.”
Architect’s Verdict
Cloud SLA limitations aren’t a vendor complaint — they’re an architectural constraint you have to design around. SLAs protect vendor margins, not your uptime. The engineers who survived the worst outages of 2023–2025 weren’t the ones with the best SLA paperwork. They were the ones who had already assumed the control plane would fail and built accordingly.
Build for the failure you can’t see on the status page.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session