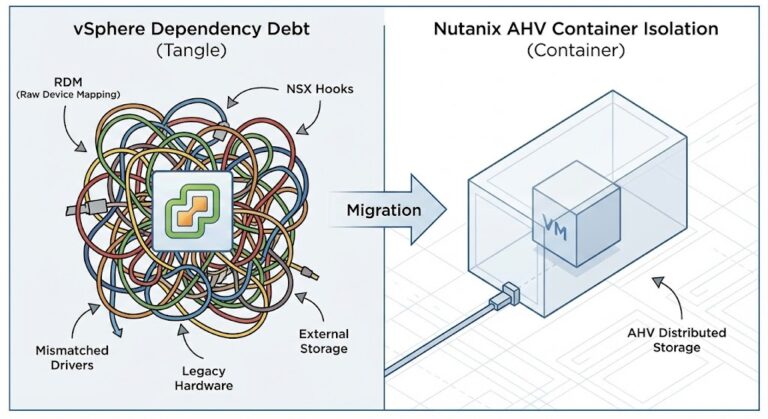
Nutanix vs VMware: Availability vs Authority in the Post-Broadcom Datacenter (2026)
Executive Summary
The nutanix vs vmware 2026 comparison starts in the wrong place when it focuses on features.
Today, that framing is obsolete.
Modern outages rarely originate from hardware failure—they originate from control-plane failure: identity providers, automation systems, API trust chains, orchestration layers, and update propagation.
This guide reframes the Nutanix vs VMware decision around operational survivability—a core pillar of any resilient Virtualization Architecture Strategy—rather than raw hypervisor capability.
The real question is no longer: Which platform keeps workloads running?
It is now: Which platform still works when the control plane breaks?
TL;DR — Quick Decision Matrix
| If your priority is… | Choose | Why |
| Lowest operational overhead | Nutanix | Unified lifecycle + data locality |
| Escape licensing volatility | Nutanix | Hardware growth does not multiply software cost |
| Ecosystem depth | VMware | Largest enterprise tooling ecosystem |
| Advanced microsegmentation | VMware | Mature NSX policy framework |
| Small IT team manageability | Nutanix | Single operational interface |
| Complex multi-vendor environments | VMware | Integration flexibility |
Is Nutanix Replacing VMware?
No — and that’s the wrong question.
In the nutanix vs vmware 2026 landscape, organizations are not replacing a hypervisor. They are choosing an operational model.
VMware optimizes for ecosystem flexibility and layered integrations. Nutanix optimizes for localized authority and operational independence.
Both platforms run enterprise workloads reliably. They diverge when external dependencies fail.
The architectural decision is therefore not about uptime — it is about recoverability. For a constraint-based breakdown of all three platform options — including where Proxmox fits for teams with the engineering depth to consider it — see Proxmox vs Nutanix vs VMware: The Post-Broadcom Constraints No One Explains.
Side-by-Side Platform Comparison
| Category | VMware Stack | Nutanix Stack | Operational Impact |
| Hypervisor | ESXi | AHV (included) | Licensing vs included runtime |
| Storage | vSAN | AOS | Network dependent vs locality driven |
| Networking | NSX | Flow | Specialized vs integrated |
| Management | vCenter + Aria | Prism | Multi-tool vs unified |
| Disaster Recovery | SRM | Leap / NearSync | External orchestration vs native |
| Automation | Aria Automation | Built-in | Separate platform vs platform capability |
| Licensing | Core-based bundles | Capacity-based | Hardware density cost multiplier |
Quantifying the Risk: CPU Density & Licensing Economics
The Broadcom transition fundamentally changed virtualization procurement. VMware licensing is now tied directly to silicon density.
Example: Upgrading a 3-node cluster
| CPU | Performance Increase | VMware Cost Increase |
| 16 → 64 core | ~1.8× compute | ~4× subscription cost |
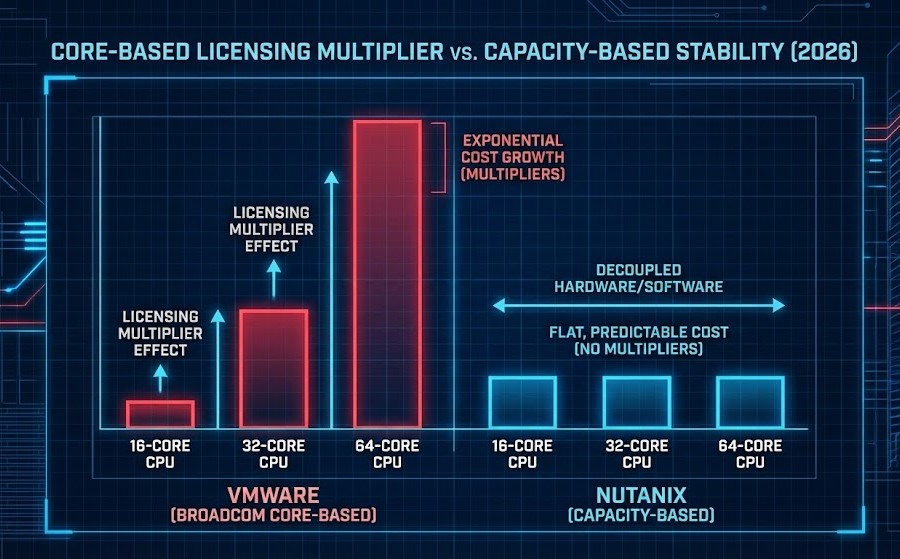
This means modernization increases operating cost faster than performance. Use the VMware Core Calculator to model your exact licensing exposure before committing to a hardware refresh cycle.
Capacity-based platforms behave differently: They track usable infrastructure footprint — not transistor count. One model penalizes hardware evolution. The other decouples it.
The Real Architectural Difference: Availability vs Authority
Traditional infrastructure resilience focused on availability:
- Redundant hosts
- Redundant storage paths
- Redundant networking
Modern failures look different:
- Identity outage
- Automation corruption
- API compromise
- Privilege escalation
- Snapshot deletion propagation
When these occur, systems may still be running—but administrators cannot control them. This creates two fundamentally different resilience philosophies:
| Model | Design Goal | Outcome During Dependency Failure |
| Availability Platform | Keep workloads online | Running but unrecoverable |
| Authority Platform | Preserve operational control | Degraded but recoverable |
Control Plane Dependency Depth
The VMware Pattern
A layered dependency architecture:
Identity → vCenter → APIs → Backup → DR → Automation
- Strength: ecosystem flexibility
- Tradeoff: cascading failure domains
If the identity or vCenter layer fails, administrators may lose the ability to authenticate, restore workloads, run automation, or initiate recovery. The environment continues running—but recovery authority disappears.
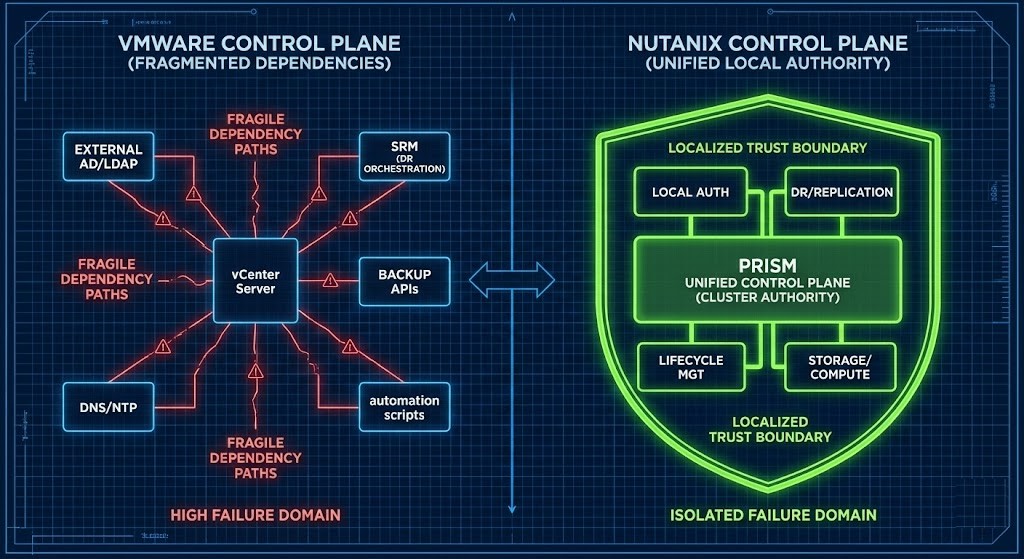
The Nutanix Pattern
A localized authority architecture: Cluster → Prism → Storage → Compute → Recovery
- Strength: operational survivability
- Tradeoff: smaller ecosystem surface area
Administrative control remains available natively within the cluster even when upstream services fail — a non-negotiable architectural requirement for establishing true disconnected cloud operations.
Failure Scenario Walkthrough: Identity Provider Outage
Assume the external directory becomes unavailable.
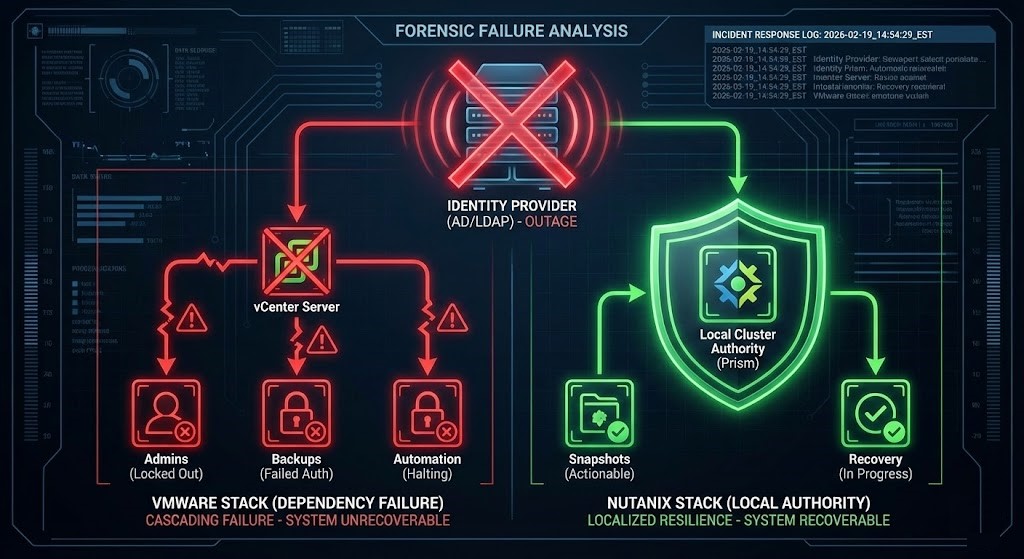
| Event | VMware Result | Nutanix Result |
|---|---|---|
| Admin login | Blocked | Local access available |
| Backup restore | Authentication failure | Fully executable |
| DR failover | Cannot start orchestration | Native execution |
| Snapshot rollback | API dependent | Local operation |
| Recovery authority | Lost | Retained |
Operational Overhead Reality
Performance differences between hypervisors are negligible for most workloads. Operational complexity is not.
| Operational Task | VMware | Nutanix |
| Upgrades | Multi-component coordination | Atomic lifecycle |
| Troubleshooting | Cross-tool correlation | Single interface |
| Staffing | Specialists required | Generalists sufficient |
| Change windows | Planned downtime common | Business-hours upgrades |
The fastest platform is not the one with the best benchmark. It is the one administrators can safely operate under pressure.
Migration Reality
Most failed migrations are not technical failures—they are operational model failures. Organizations attempt to recreate old workflows inside a new platform.
There is also a phase most migration frameworks omit entirely: the coexistence window. The period where VMware and the destination platform run simultaneously is not a transition state — it is a distinct operational mode with its own failure patterns. The Fragmented Control Plane that emerges during hybrid operation creates management plane gaps and security boundary ambiguities that compound with each migration wave. The VMware Exit Has Entered the Coexistence Era maps the architecture of that window.
Successful migrations change operational behavior, not just hypervisors. This requires teams to adapt and upskill through a structured Modern Virtualization Learning Path.
For the kernel-level physics of what actually changes when you move from ESXi to AHV — scheduler semantics, NUMA locality, and CVM arbitration — see Part 1 of the Post-Broadcom Deterministic Migration Series.
If your environment includes Metro cluster deployments, Part 2: The Physics of Disconnected Cloud covers RTT variance modeling and pre-flight validation before enabling Metro replication.
Strategic Decision Framework
Choose VMware when:
- Deep third-party integrations required
- Existing NSX microsegmentation dependency
- Dedicated platform engineering teams
- Large multi-tool enterprise automation
Choose Nutanix when:
- Operational simplicity matters
- Licensing predictability matters
- Smaller teams manage large environments
- Recovery authority is prioritized
The Strategic Reality
The virtualization industry is shifting from uptime engineering to recoverability engineering. The winning platform is not the one that prevents failure. It is the one that preserves control after failure.
Modern outages do not ask: “Did the VM stay running?”
They ask: “Could the operator still recover the environment?”
Architect’s Verdict
You are not choosing a hypervisor. You are choosing an operational philosophy — and the distinction matters most when something breaks.
VMware’s architecture maximizes ecosystem flexibility. The depth of third-party integrations, the maturity of NSX, and the breadth of ISV certification coverage are genuine advantages for organizations whose environments depend on them. The cost is a layered dependency chain that can strip administrative control precisely when you need it most. The Nutanix Bible documents how AHV’s localized authority model was explicitly designed to invert that trade-off — cluster-level control that persists independent of upstream service availability.
Nutanix’s architecture maximizes recoverability. The unified operational plane, localized authority, and capacity-based licensing model remove the failure vectors that VMware’s component stack introduces. The cost is a smaller ecosystem surface area and, for organizations with deep NSX dependencies, a non-trivial re-engineering effort before the switch is safe to execute.
The decision reduces to one question: which failure do you fear more — downtime, or loss of control? For most enterprise environments in 2026, loss of control is the more dangerous answer. Modern outages don’t ask whether your VMs are running. They ask whether your operators can still reach them, restore them, and recover the environment. That is an authority problem, not an availability problem.
Use the VMware Exit Toolkit to model the operational and cost implications of both paths against your specific environment before committing to either.
Additional Resources
Editorial Integrity & Security Protocol
This technical deep-dive adheres to the Rack2Cloud Deterministic Integrity Standard. All benchmarks and security audits are derived from zero-trust validation protocols within our isolated lab environments. No vendor influence.
R.M.
Senior Solutions Architect with 25+ years of experience in HCI, cloud strategy, and data resilience. As the lead behind Rack2Cloud, I focus on lab-verified guidance for complex enterprise transitions. View Credentials →
Get the Playbooks Vendors Won’t Publish
Field-tested blueprints for migration, HCI, sovereign infrastructure, and AI architecture. Real failure-mode analysis. No marketing filler. Delivered weekly.
Select your infrastructure paths. Receive field-tested blueprints direct to your inbox.
- > Virtualization & Migration Physics
- > Cloud Strategy & Egress Math
- > Data Protection & RTO Reality
- > AI Infrastructure & GPU Fabric
Zero spam. Includes The Dispatch weekly drop.
Need Architectural Guidance?
Unbiased infrastructure audit for your migration, cloud strategy, or HCI transition.
>_ Request Triage Session