SERVICE MESH ARCHITECTURE
EAST-WEST TRAFFIC HAS NO PERIMETER. THE MESH BUILDS ONE.
East-west traffic in a microservices cluster is the most dangerous network surface most teams never think about. North-south traffic — requests arriving from the internet, responses returning to users — is where security investment concentrates. Load balancers, WAFs, TLS termination, rate limiting. The boundary between inside and outside gets substantial architectural attention.
The traffic between services inside the cluster gets almost none. In a default Kubernetes environment, every pod can reach every other pod on every port. No identity. No encryption. No policy. No audit trail. A service that handles payment data and a service that renders marketing pages are on the same flat network, with unrestricted access to each other. At five services, this is a manageable risk. At fifty, it is invisible. At five hundred, it is unauditable — and the attack surface that threat actors increasingly target first.
A service mesh exists because this problem does not have a good solution at the application layer. Mutual TLS between services sounds straightforward until you are managing certificate rotation for five hundred services across three clusters. Traffic policy — retries, circuit breaking, weighted routing — sounds like a library choice until you need to enforce it uniformly without touching two dozen codebases. Observability across service boundaries sounds like an instrumentation problem until you need distributed traces without requiring every team to adopt the same SDK. The mesh solves all four — not by changing the application, but by placing an enforcement layer around every request.
This is the mental model reset the page is built on: a service mesh is not a networking tool. It is an identity and policy enforcement layer for east-west traffic. That distinction determines when a mesh is the right architecture — and when it is the wrong abstraction entirely. This page sits within the Cloud Native Architecture pillar and the broader Cloud Architecture Strategy hub. The identity model it enforces connects directly to the Container Security Architecture principle that identity is the real perimeter — applied here at the network layer between every service.
The Problem a Service Mesh Exists to Solve
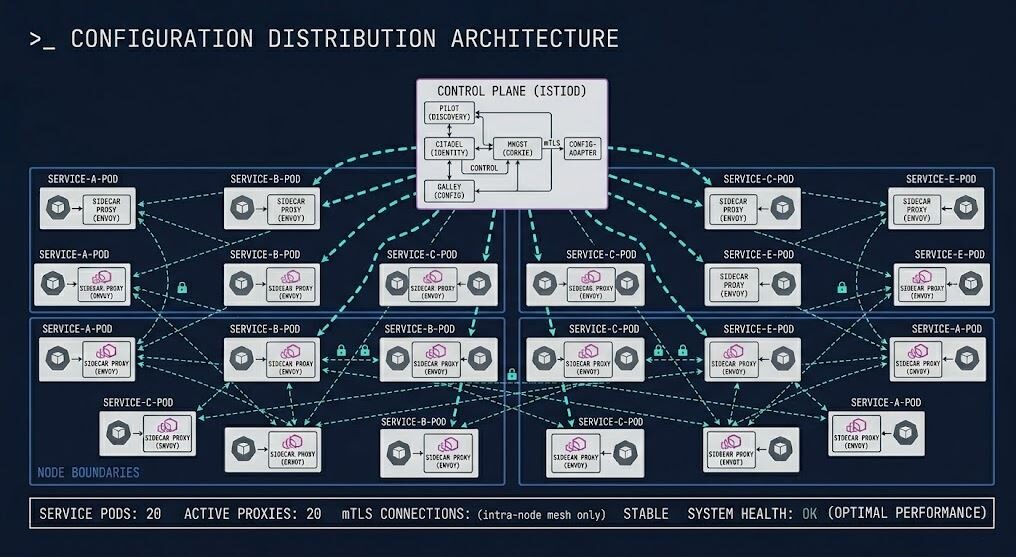
Kubernetes manages infrastructure. The mesh manages communication behavior. That distinction is the reason the mesh exists as a separate architectural layer rather than a Kubernetes feature.
In a microservices architecture, services communicate constantly — dozens to hundreds of calls per second, across dozens to hundreds of service pairs. Each of those calls crosses a network boundary inside the cluster. Each of those boundaries is, by default, unprotected. No service knows for certain who it is talking to. No call is encrypted in transit. No policy governs who is allowed to call what. No trace follows a request across the full call chain. These are not edge-case risks. They are the default operating conditions of every Kubernetes cluster that has not explicitly addressed them.
The problem compounds with scale. At five services, an engineer can hold the full communication topology in their head. At fifty, critical paths are invisible without tooling. At five hundred, the cluster’s internal network is effectively unauditable — and any one compromised service has unrestricted lateral reach to every service it can route to. This is the distributed systems reality that forces the mesh to exist: not a feature request, but an architectural gap that grows in severity as the system grows in scale.
Kubernetes manages infrastructure. The mesh manages communication behavior. The Kubernetes control plane schedules workloads, enforces resource policy, and maintains cluster state through continuous reconciliation. None of that touches what happens between services once they are running. The mesh fills that gap — sitting between services at the network layer, enforcing policy without requiring the application to implement it.
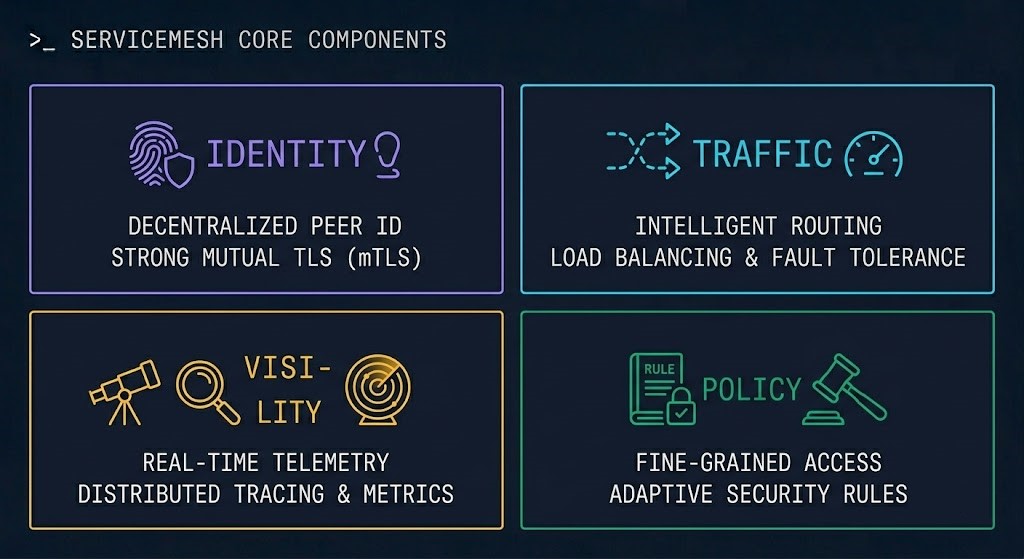
The Four Control Surfaces
Every service gets a cryptographic identity. Every connection is mutually authenticated before data is exchanged. IP addresses are not identity. Certificates are. The mesh issues, rotates, and enforces those certificates without application involvement.
Traffic policy — retries, timeouts, circuit breakers, weighted routing, canary splits — enforced uniformly at the proxy layer without modifying application code. The mesh is the control surface for how traffic moves between services at Layer 7.
Latency, error rates, request volume, and saturation — instrumented at every service boundary without a single line of application telemetry code. Distributed traces that follow a request across the full call chain. The service map that makes the invisible communication topology visible.
Who is allowed to call what — enforced at Layer 7 based on service identity, not IP address or port. Authorization policies that define which services can reach which endpoints, which HTTP methods are allowed, and which paths require elevated identity verification.
These four surfaces are uncontrolled in a default Kubernetes cluster. NetworkPolicy addresses part of the identity and policy surface — at Layer 3 and 4, based on IP and port. The mesh extends that to Layer 7, adds cryptographic identity, and instruments every boundary for observability. It does not replace NetworkPolicy. It extends it into territory NetworkPolicy cannot reach.
The network topology class the cluster runs on — CNI model, control plane blast radius, east-west enforcement mechanism — determines the upper bound of what the mesh can enforce. The Modern Networking Logic strategy guide covers the topology layer the mesh sits on top of.
Request Path With and Without a Mesh
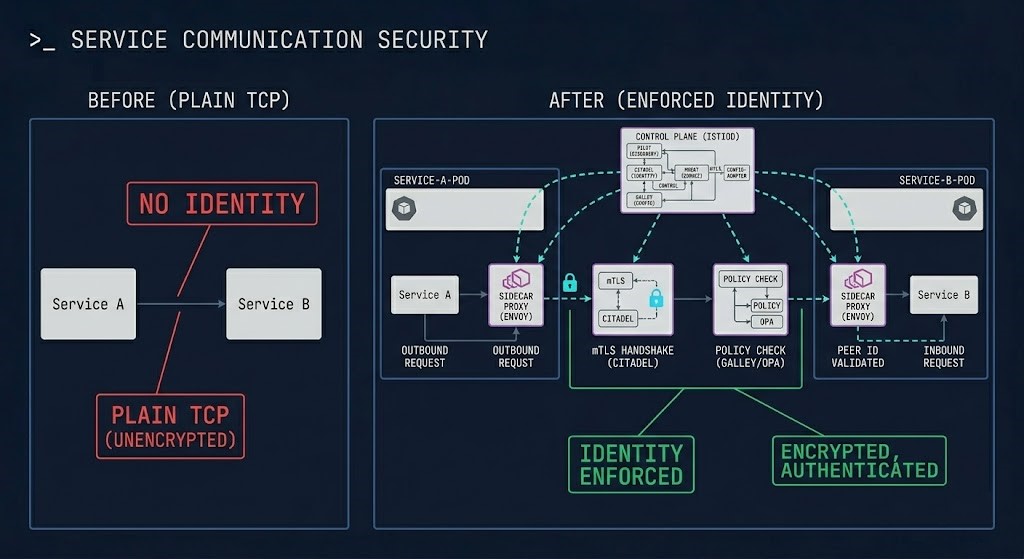
The mesh does not change the application. It changes everything that happens around every request. The same code, the same deployment, the same Kubernetes manifests — with a mesh installed, every east-west call is authenticated, encrypted, policy-checked, and traced. Without one, none of that is true.
Sidecar vs Ambient vs eBPF — A Data Plane Architecture Decision
This is not a tooling choice. It is a data plane architecture decision — with permanent operational consequences that scale with the cluster.
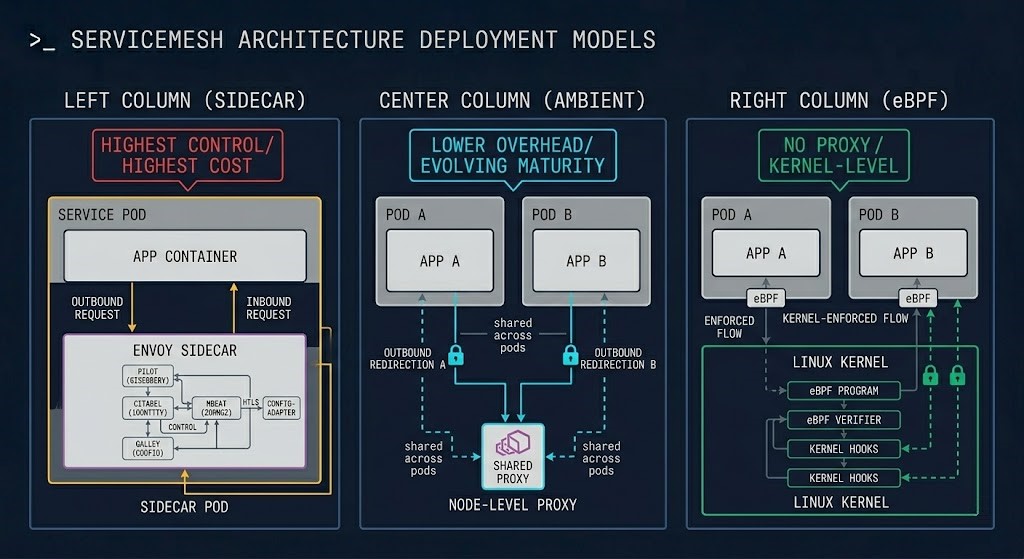
An Envoy or Linkerd proxy is injected as a sidecar container into every pod. Every inbound and outbound call transits the proxy — giving the mesh complete visibility and control at the pod level. The tradeoff is resource overhead that scales linearly with pod count and operational complexity that scales with cluster size.
Rather than a sidecar per pod, ambient mesh runs a shared ztunnel (zero-trust tunnel) proxy at the node level, handling L4 mTLS for all pods on the node. L7 policy is handled by waypoint proxies deployed per namespace or service. Reached production readiness in 2025 — significantly lower resource overhead than sidecar mode.
eBPF-based networking enforces policy, captures telemetry, and provides mTLS via SPIFFE identity directly in the Linux kernel — without sidecar proxies or a second control plane. If Cilium covers your requirements, adding Istio introduces complexity without proportional benefit. The Service Mesh vs eBPF analysis covers this decision in full.
The framing that clarifies the decision: sidecar is EC2 — dedicated, isolated, full control, maximum overhead. Ambient is like moving toward a managed service — shared infrastructure, lower overhead, slightly less isolation granularity. eBPF is serverless — the enforcement happens below the abstraction layer entirely, invisible to the workload. Each model makes a different tradeoff between control granularity, resource overhead, and operational complexity. None is universally correct.
The Major Implementations
| Implementation | Control Plane | Data Plane Proxy | mTLS Model | Ambient Support | Operational Complexity | Best Fit Scenario |
|---|---|---|---|---|---|---|
| Istio | Istiod | Envoy | SPIFFE/X.509, automatic cert rotation | Yes — GA 2025 | High | Large clusters, regulated environments, full L7 policy requirement |
| Linkerd | Linkerd control plane | Linkerd2-proxy (Rust) | SPIFFE, automatic mTLS on by default | No | Low–Medium | Teams prioritizing simplicity, mTLS without full Istio complexity |
| Cilium | Cilium Operator | eBPF (kernel-level) | SPIFFE via mutual auth, eventual consistency | N/A — no sidecar model | Low | Teams that may not need a traditional mesh — eBPF covers most requirements |
| Consul Connect | Consul server cluster | Envoy | Consul CA, X.509 | No | Medium–High | Multi-datacenter, hybrid cloud, existing HashiCorp stack |
Service Mesh and the Control Plane Model
The mesh control plane is a policy distribution system, not a scheduler. This distinction matters architecturally because it defines what the control plane owns and what happens when it is unavailable.
Kubernetes schedules workloads, reconciles desired state, and manages the lifecycle of cluster resources. The mesh control plane does none of that. It distributes TLS certificates to proxies, pushes routing configuration to sidecars, and propagates authorization policy across the data plane. When the mesh control plane is healthy, proxies enforce current policy. When it is degraded — Istiod crashing, network partitioned, resource-starved — proxies continue enforcing the last known configuration. The cluster keeps running. Policy updates stop propagating.
This is the architectural property that defines the blast radius of a mesh control plane failure. Unlike the Kubernetes control plane — where a failure blocks all new scheduling and can cascade into workload disruption — a mesh control plane failure is survivable in a correctly configured environment. It is not invisible: certificate rotation stops, policy changes cannot be applied, and new sidecars cannot bootstrap. But existing workloads continue operating on cached configuration.
SPIFFE (Secure Production Identity Framework for Everyone) is the identity framework the mesh builds on. SPIFFE defines a standard for workload identity — short-lived X.509 certificates that encode a service’s identity as a SPIFFE ID (a URI in the form spiffe://trust-domain/path). The mesh control plane acts as a SPIFFE implementation — issuing, rotating, and distributing certificates to every proxy in the data plane. This is what makes mTLS in a mesh architecturally different from manually configured TLS: identity is automatic, rotation is continuous, and every workload has a verifiable cryptographic identity without operator involvement.
How the mesh relates to NetworkPolicy: they are complementary controls operating at different layers, not alternatives. NetworkPolicy enforces at Layer 3 and 4 — IP address and port. It does not encrypt traffic, does not provide cryptographic service identity, and cannot enforce policy based on HTTP methods or service names. The mesh enforces at Layer 7 — service identity, HTTP methods, request paths — with mutual authentication and encryption. The correct architecture uses both: NetworkPolicy for coarse-grained pod segmentation, mesh for fine-grained identity-based policy at the application layer. See how this relates to the full security model in the Container Security Architecture guide and the Service Mesh vs eBPF decision framework.
Traffic Management Architecture
Automatic retry on transient failures with configurable backoff — without application code changes. Per-route timeout enforcement that prevents slow upstream services from consuming connection pool capacity downstream. Applied uniformly across every service in the mesh.
When a downstream service is degrading, the circuit breaker opens — stopping traffic to the failing service and returning fast failures to callers rather than slow ones. Prevents cascading failures from propagating across the full service graph. Configurable per service, not per deployment.
Weighted routing that splits traffic between versions — 95% to stable, 5% to canary — without DNS changes or load balancer reconfiguration. Progressive rollout controlled by VirtualService policy. The deployment mechanism for zero-downtime releases at the network layer.
Per-connection and per-request rate limiting at the proxy layer — protecting downstream services from traffic spikes without application-level implementation. Enforced before the request reaches the application container. Pairs naturally with the Kubernetes Gateway API routing model for north-south traffic.
Observability at the Mesh Layer
The observability value of a service mesh is real — and frequently overclaimed. The mesh instruments every service boundary automatically, providing the three signals distributed systems require: metrics, traces, and logs. What it does not provide is application-level visibility. The mesh sees the request envelope. It does not see the business logic inside.
What the mesh makes visible that nothing else can without code changes: the complete service communication topology, rendered as a live service map. The golden signals — latency, traffic volume, error rates, saturation — at every service boundary, without instrumentation libraries. Distributed traces that follow a request across the full call chain, correlating spans across every service the request touches.
What the mesh cannot see: what the application does with the request once it arrives. Application-level errors that return HTTP 200 with a failure payload. Business metrics — conversion rates, transaction values, domain-specific events. Logic inside the service that does not produce network traffic. This distinction matters because teams that adopt a mesh for observability sometimes discover they have excellent network-level visibility and no application-level insight. The mesh is a complement to application instrumentation, not a replacement for it.
The containerd Day-2 failure patterns and Kubernetes Day-2 failure signatures document the class of production failures that become diagnosable only when observability reaches every layer of the stack — runtime, orchestration, and network. The mesh closes the network observability gap that makes east-west failures invisible in uninstrumented clusters.
Cost Physics of Service Mesh
A service mesh does not just add control. It adds permanent overhead to every request path — multiplied across every pod, every hop, every trace, and every engineer who has to operate it.
Each Envoy sidecar consumes approximately 50MB of memory and measurable CPU at idle. In a 500-pod cluster, that is 25GB of memory consumed by proxies before a single line of application code runs. At 2,000 pods, it is 100GB. This cost is not a configuration choice — it is the architectural consequence of the per-pod isolation model. Ambient mesh addresses this directly; sidecar mode does not.
A single request that traverses eight services in a microservice architecture passes through sixteen sidecar proxies — eight on the outbound side, eight on the inbound. At 2ms per hop, that is 32ms of proxy overhead before any application processing. For latency-sensitive APIs with P99 SLAs, this is a budget item that must be accounted for before the mesh is installed, not discovered after.
A mesh that instruments every service boundary generates telemetry at a rate that can exceed the application telemetry volume by 5–10x. Distributed traces with full span data, per-service metrics for every golden signal, and access logs for every request — stored, indexed, and queried. The observability infrastructure cost is a real line item that must be budgeted before mesh adoption, not discovered on the monitoring bill six months later.
Someone owns the control plane. Someone rotates certificates when the rotation fails. Someone debugs mTLS handshake failures at 2am when services stop communicating. Someone maintains the VirtualService and AuthorizationPolicy manifests as the service topology changes. Someone upgrades Istiod across the cluster without taking down traffic. The operational headcount cost of a production service mesh is significant, continuous, and the most commonly underestimated cost in adoption planning.
Where Service Mesh Architectures Break Down
A cluster that runs 100 pods has 100 sidecars and a manageable overhead profile. A cluster that runs 2,000 pods has 2,000 sidecars consuming 100GB of memory before any application runs. Teams that adopt sidecar-mode mesh at small scale and grow the cluster without revisiting the data plane architecture model discover the overhead at the worst possible moment — when cost optimization becomes a priority and the sidecar fleet is the largest addressable item on the node resource bill.
When the Istiod control plane becomes unavailable — OOM killed, resource-starved, network-partitioned — existing sidecars continue enforcing cached configuration, but new pods cannot bootstrap their proxy. Certificate rotation stops. Policy changes cannot propagate. In strict mTLS mode, new pods that cannot receive certificates cannot join the mesh — and cannot communicate with mesh-enrolled services. The control plane is a single point of failure that requires the same operational care as the Kubernetes control plane itself.
A service that cannot reach another service in a mesh environment has multiple potential failure surfaces: application bug, NetworkPolicy, AuthorizationPolicy, VirtualService misconfiguration, mTLS certificate expiry, Envoy filter ordering, pilot-agent bootstrap failure. Diagnosing which layer is responsible requires understanding all of them simultaneously. Teams without deep mesh expertise frequently cannot distinguish a policy misconfiguration from an application failure — and the mesh’s additional abstraction layers make every debugging session longer than it would be without a mesh.
A service mesh that enrolls 60% of the cluster’s services provides 60% of the security value — and 100% of the operational overhead. The 40% of services not in the mesh communicate without mTLS, without policy enforcement, and without traces. An attacker who compromises any unenrolled service has an unrestricted path to every service in the cluster. Partial adoption is the most dangerous mesh state — it creates the operational burden of a full deployment without the security guarantees that justified the investment.
Istio’s default mTLS mode is PERMISSIVE — accepting both mTLS and plaintext traffic. This is the correct starting mode for migration: it allows services to join the mesh gradually without breaking existing plaintext communication. It is also the mode that most production mesh deployments never leave. An mTLS policy in PERMISSIVE mode is not mutual authentication — it is optional mutual authentication. Any service, including a compromised one, can communicate in plaintext and bypass identity verification entirely. The move to STRICT mode — enforcing mTLS for all enrolled services — is the step that makes the mesh a real security control rather than an observability tool with optional encryption.
When You Actually Need a Service Mesh
Cryptographic identity enforcement between every service pair — not just selected ones. When compliance mandates encrypted east-west traffic or when the threat model requires mutual authentication at every service boundary, NetworkPolicy cannot satisfy the requirement. The mesh is the architectural answer.
HTTP method-level access control, service identity-based authorization, header-based routing policy. When the security requirement exceeds what port and IP can express, the mesh is the correct enforcement layer. NetworkPolicy is Layer 3 and 4. The mesh is Layer 7.
Cross-cluster traffic policy, federated service identity, and auditable communication across cluster boundaries. The mesh provides the identity and traffic management fabric that makes multi-cluster microservices architectures operationally tractable rather than manually configured.
Distributed traces, golden signals, and a live service map across every service in the cluster — without requiring every team to adopt the same instrumentation library. When observability must be enforced uniformly across dozens of services and teams, the mesh layer is the only place to instrument it consistently.
PCI, HIPAA, SOC2, and similar frameworks increasingly specify in-transit encryption between internal services — not just at the perimeter. When a compliance requirement explicitly covers east-west traffic and audit evidence is required, the mesh provides the enforcement mechanism and the audit trail.
If none of those triggers are true for your environment, a service mesh is likely unnecessary complexity. NetworkPolicy plus RBAC addresses the most common east-west security requirements. Cilium may address the rest without adding a second control plane. The question worth asking before adopting a mesh is not “which mesh should we run?” — it is “do we have a control requirement that only a mesh can satisfy?”
When a Service Mesh Is Overkill
A team of five running fifteen services that deploy twice a week does not need a service mesh. The operational overhead — control plane management, sidecar upgrades, certificate rotation, policy maintenance — costs more in engineering time than the security and observability controls return at that scale. NetworkPolicy and RBAC cover the security requirements. Application-level tracing covers the observability requirements.
A service mesh amplifies operational capability. It does not create it. Organizations without established platform engineering practices, without Kubernetes expertise, and without observability culture will find that a mesh adds abstraction layers and failure modes faster than it adds control. Get the Kubernetes operational baseline right first. The mesh is a multiplier on top of that baseline — not a replacement for it. The internal platform layer that defines and enforces that baseline is covered in the Platform Engineering Architecture pillar.
If the cluster’s CNI is Cilium, evaluate whether Cilium’s native capabilities already cover the control requirements before adding Istio. Cilium provides mTLS via SPIFFE identity, L7 traffic policy, load balancing, and observability through Hubble — without a second control plane. The complexity budget you would spend on Istio is better invested in the application layer when Cilium covers the network security requirements.
Installing a service mesh without a clear control requirement is the Kubernetes equivalent of deploying a distributed system to avoid writing a simple API. The abstraction is real. The cost is real. The benefit requires a specific architectural requirement to exist. If the team cannot articulate which of the five trigger conditions above applies, the mesh should not be installed.
Decision Framework
| Scenario | Verdict | Recommended Approach | Team Maturity Required | Watch For |
|---|---|---|---|---|
| Regulated environment, mTLS compliance requirement, 50+ services | Strong Fit | Istio in STRICT mTLS mode — full enrollment, no partial adoption | High — dedicated platform team | Never leave PERMISSIVE mode — audit and enforce STRICT before declaring compliance |
| Multi-cluster microservices, cross-cluster traffic policy required | Strong Fit | Istio multi-cluster or Consul Connect for existing HashiCorp environments | High | Trust domain federation — cross-cluster mTLS requires explicit trust configuration |
| mTLS needed, simplicity priority, single cluster | Good Fit | Linkerd — automatic mTLS, lower operational complexity than Istio | Medium | No ambient mode — sidecar overhead at scale, limited L7 policy vs Istio |
| Cilium CNI, evaluating mesh from scratch | Evaluate First | Audit Cilium’s native capabilities before adding Istio — may not need a mesh | Medium | Cilium mTLS uses eventual consistency — if synchronous policy enforcement is required, Istio may be necessary |
| Large cluster, sidecar cost becoming significant | Consider Ambient | Istio ambient mesh — evaluate migration path from sidecar mode | High | Ambient is GA but younger than sidecar mode — validate against your specific workload patterns |
| Small team, <20 services, no compliance driver | Not Yet | NetworkPolicy + RBAC — covers security requirements without mesh overhead | Low–Medium | Revisit when scale or compliance requirements change the trigger list |
| No established platform engineering practice | Not Ready | Build Kubernetes operational baseline first — mesh amplifies capability it does not create it | High required, not present | A mesh installed without operational maturity adds failure modes faster than it adds controls |
| Mesh installed but no clear control requirement identified | Re-evaluate | Audit against the five trigger list — if none apply, evaluate removal or replacement with simpler controls | N/A | Sunk cost is not a reason to keep a mesh — operational overhead is ongoing and compounds |
Service mesh architecture sits at the intersection of orchestration, security, and network policy. The pages below cover the layers it enforces against, the platform it runs on, and the security model it implements.
You’ve Chosen the Mesh.
Now Validate It Isn’t the Bottleneck.
mTLS enforcement, sidecar proxy overhead, traffic policy scope, and observability coverage — service mesh deployments that look correct in testing become latency sources and operational complexity multipliers in production. The audit validates whether your mesh is earning its overhead.
Service Mesh Architecture Audit
Vendor-agnostic review of your service mesh deployment — mTLS enforcement coverage, sidecar proxy resource overhead, traffic policy completeness, observability pipeline integration, and whether a sidecar-based mesh is the right architecture versus eBPF-based alternatives for your specific workload profile.
- > mTLS enforcement scope and certificate management
- > Sidecar overhead and data plane resource model
- > Traffic policy coverage and authorization rules
- > Mesh vs eBPF decision validation for your environment
Architecture Playbooks. Every Week.
Field-tested blueprints from real service mesh deployments — Istio vs Cilium decision analysis, mTLS policy drift case studies, sidecar overhead profiling, and the traffic management patterns that separate a production-grade mesh from one that adds latency without adding value.
- > Service Mesh vs eBPF Architecture Decisions
- > mTLS Policy & Zero Trust Enforcement
- > Traffic Management & Observability Patterns
- > Real Failure-Mode Case Studies
Zero spam. Unsubscribe anytime.
Architect’s Verdict
The mesh is not a default. It is a commitment.
Every team that installs a service mesh owns the control plane, the sidecar fleet, the certificate rotation pipeline, the VirtualService and AuthorizationPolicy manifests, and the debugging surface — permanently. That is not a reason to avoid the mesh. It is the honest cost model that determines whether the investment is justified.
The teams that succeed with a service mesh are the ones who installed it to satisfy a specific control requirement — mTLS enforcement, L7 policy, multi-cluster observability — and built the operational capability to run it before they installed it. The teams that struggle are the ones who installed Istio because the architecture diagram called for a service mesh, discovered the operational surface area six months later, and spent the next year maintaining infrastructure that does not directly serve a business requirement.
The control requirement comes first. If you need default-on mTLS across every service, encrypted east-west traffic, and L7 authorization policy without application code changes — the mesh is the right architecture. If you need better observability, consider application instrumentation first. If you need network segmentation, configure NetworkPolicy first. If you are running Cilium, evaluate whether it already covers what you need.
East-west traffic has no perimeter by default. The mesh builds one — at a real and permanent cost. Know what you are buying before you buy it.
Frequently Asked Questions
Q: What is a service mesh and do I actually need one?
A: A service mesh is an identity and policy enforcement layer for east-west traffic in a microservices cluster — not a networking tool. It solves four problems that have no good application-layer solution at scale: mutual TLS between services, traffic management (retries, circuit breaking, weighted routing), Layer 7 observability without code changes, and authorization policy based on service identity rather than IP address. Whether you need one depends on whether any of those problems exist at your scale. If you require default-on mTLS, L7 policy enforcement, multi-cluster traffic management, or uniform observability without instrumentation — a mesh is likely the right architecture. If none of those triggers apply, NetworkPolicy plus RBAC covers most security requirements without the operational overhead of a full mesh deployment.
Q: What is the difference between a service mesh and NetworkPolicy?
A: They operate at different layers and solve different problems — they are complementary, not alternatives. NetworkPolicy operates at Layer 3 and 4: it controls which pods can communicate with which other pods based on IP addresses and ports. It does not encrypt traffic, does not provide cryptographic service identity, and cannot enforce policy based on HTTP methods, request paths, or service names. A service mesh operates at Layer 7: it enforces mTLS between services using cryptographic certificates, controls traffic based on service identity and HTTP attributes, and provides distributed observability across service boundaries. The correct production architecture uses both: NetworkPolicy for coarse-grained pod segmentation, service mesh for fine-grained identity-based policy where the requirements justify the overhead.
Q: Istio vs Linkerd vs Cilium — how do I choose?
A: Start with whether you need a traditional mesh at all. If your CNI is Cilium, audit its native capabilities first — Cilium provides mTLS via SPIFFE identity, L7 policy, and observability through Hubble without a second control plane. If you need a traditional sidecar mesh and simplicity is the priority, Linkerd provides automatic mTLS with significantly lower operational complexity than Istio. If you need the full feature surface — ambient mesh support, advanced L7 traffic policy, multi-cluster federation, extensive ecosystem tooling — Istio is the correct choice with a mature team to operate it. Consul Connect is the right choice when the environment already runs HashiCorp tooling and multi-datacenter mesh federation is a requirement.
Q: What is ambient mesh and is it production ready in 2026?
A: Ambient mesh is Istio’s sidecar-free data plane model. Instead of injecting an Envoy proxy into every pod, ambient mesh runs a shared ztunnel (zero-trust tunnel) proxy at the node level for L4 mTLS, and optional waypoint proxies per namespace or service for L7 policy. It reached production readiness with Istio 1.22 in 2025 and is GA as of this writing. The primary advantage is resource overhead — eliminating per-pod sidecars reduces memory consumption by 60–80% compared to sidecar mode at equivalent pod counts. The operational model is also simpler: no sidecar injection configuration, no proxy version alignment across thousands of pods. For new cluster deployments evaluating Istio, ambient mode is worth choosing as the default data plane model. For existing sidecar deployments, migration is supported but requires planning.
Q: What is mTLS and why does it require a service mesh?
A: Mutual TLS (mTLS) is a variant of TLS where both sides of a connection present certificates and verify each other’s identity before data is exchanged — not just the server presenting a certificate to the client as in standard TLS. In a microservices cluster, mTLS means that when Service A calls Service B, both services cryptographically prove their identity before the call proceeds. This eliminates IP-based trust — a compromised service cannot impersonate another service by spoofing its IP, because the certificate is the identity. mTLS does not technically require a service mesh — you can implement it at the application layer with TLS libraries. The reason a mesh is the practical answer at scale is certificate management: issuing, rotating, and distributing certificates for hundreds of services, maintaining consistent policy across all of them, and doing it without application code changes is the operational problem the mesh control plane was built to solve.
Q: What is the real operational cost of running a service mesh at scale?
A: The financial costs are measurable: ~50MB of memory per pod for Envoy sidecars, 1–5ms of added latency per service hop, and 5–10x observability data volume increase. The operational costs are harder to budget but larger in practice: someone must own the control plane availability, certificate rotation failures, proxy version upgrades across the cluster, AuthorizationPolicy and VirtualService manifest maintenance as services evolve, and mTLS debugging when services stop communicating. At 500 pods, this is a part-time platform engineering responsibility. At 2,000 pods in a regulated environment, it is a full-time role or team. The most common mistake in mesh adoption planning is budgeting for the tooling and not for the engineering hours required to operate it continuously.